- Décomposition en valeurs singulières
-
En mathématiques, le procédé d'algèbre linéaire de décomposition en valeurs singulières (ou SVD, de l'anglais : Singular Value Decomposition) d'une matrice est un outil important de factorisation des matrices rectangulaires réelles ou complexes. Ses applications s'étendent du traitement du signal aux statistiques, en passant par la météorologie.
Le théorème spectral énonce qu'une matrice normale peut être diagonalisée par une base orthonormée de vecteurs propres. On peut voir cette décomposition comme une généralisation du théorème spectral à des matrices arbitraires, qui ne sont pas nécessairement carrées.
Sommaire
Contexte mathématique
Énoncé du théorème
Soit M une matrice m×n dont les coefficients appartiennent au corps K, où K = R ou K = C. Alors il existe une factorisation de la forme :
 ,
,
avec U une matrice unitaire m×m sur K, Σ une matrice m×n dont les coefficients diagonaux sont des réels positifs ou nuls et tous les autres sont nuls, et V* est la matrice adjointe à V, matrice unitaire n×n sur K. On appelle cette factorisation la décomposition en valeurs singulières de M.
- La matrice V contient un ensemble de vecteurs de base orthonormés pour M, dits « d'entrée » ou « d'analyse » ;
- La matrice U contient un ensemble de vecteurs de base orthonormés pour M, dits « de sortie » ;
- La matrice Σ contient les valeurs singulières de la matrice M.
Une convention courante est de ranger les valeurs Σi,i par ordre décroissant. Alors, la matrice Σ est déterminée de façon unique par M (mais U et V ne le sont pas).
Existence
Une valeur propre λ d'une matrice est caractérisée par la relation M u = λ u. Quand M est hermitienne, une autre caractérisation différente est envisageable. Soit M une matrice n × n symétrique réelle. On pose f: Rn → R telle que f(x) = xT M x. Cette fonction est continue et atteint son maximum en un certain vecteur u quand elle est restreinte à la boule unité fermée {||x|| ≤ 1}. D'après le théorème des multiplicateurs de Lagrange, u vérifie :
On montre facilement que la relation ci-dessus donne M u = λ u. Ainsi, λ est la plus grande valeur propre de M. Les mêmes opérations sur le complément orthogonal de u donne la seconde plus grande valeur, et ainsi de suite. Le cas d'une matrice complexe hermitienne est similaire, avec f(x) = x* M x une fonction de 2n variables à valeurs réelles.
Les valeurs singulières sont similaires, en tant qu'elles peuvent être décrites de façon algébrique ou à partir de principes variationnels. En revanche, au contraire du cas des valeurs propres, l'hermiticité et la symétrie de M ne sont plus nécessaires.
Preuve utilisant l'algèbre
Soit M une matrice complexe m×n. Alors M*M est positive semi-définie, donc hermitienne. D'après le théorème spectral, il existe une matrice unitaire carrée de côté n, notée V, telle que :
 ,
,
où D est diagonale et définie positive. En écrivant V de façon appropriée :
Ainsi, V*1M*MV1 = D, et MV2 = 0. On pose :
Alors on a :
On constate que c'est presque le résultat attendu, à ceci près que U1 et V1 ne sont pas unitaires dans le cas général. U1 est une isométrie partielle (U1U*1 = I ) alors que V1 est une isométrie (V*1V1 = I ). Pour achever la démonstration, on doit en quelque sorte « compléter » ces matrices pour les rendre unitaires.
V2 convient pour V1. De même, on peut choisir U2 tel que :
soit unitaire. Un calcul montre que :
ce qui correspond au résultat attendu.
On aurait également pu commencer la démonstration en diagonalisant MM* au lieu de M*M, on aurait alors montré directement que MM* et M*M ont même valeurs propres non-nulles.
Caractérisation alternative
Les valeurs singulières peuvent également être caractérisées comme maxima de uTMv, considérée comme une fonction de u et v, sur des sous-espaces particuliers. Les vecteurs singuliers sont les valeurs de u et v pour lesquelles ces maxima sont atteints.
Soit M une matrice réelle m × n. Soit Sm − 1 et Sn − 1 l'ensemble des vecteurs unitaires (selon la norme 2) de Rm et Rn respectivement. On pose la fonction :
 ,
,
pour les vecteurs u ∈ Sm − 1 et v ∈ Sn − 1.
On considère la fonction σ restreinte à Sm − 1 × Sn − 1. Puisqu'à la fois Sm − 1 et Sn − 1 sont des ensembles compacts, leur produit est également compact. En outre, puisque σ est continue, elle atteint son maximum pour au moins une paire de vecteurs u ∈ Sm − 1 et v ∈ Sn − 1. Ce maximum est noté σ1, et les vecteurs correspondants sont notés u1 et v1. Puisque σ1 est la plus grande valeur de σ(u,v), elle est positive : si elle était négative, en changeant le signe de u1 ou de v1, on la rendrait positive - et donc plus grande.
Lemme — u1 et v1 sont respectivement vecteurs singuliers à gauche et à droite pour M associés à σ1.
Démonstration — De même que pour le cas des valeurs propres, en supposant que les deux vecteurs vérifient l'équation de Lagrange :
 .
.
On montre que cela donne :
- Mv1 = 2λ1u1 + 0, et
- MTu1 = 0 + 2λ2v1.
En multipliant la première équation à gauche par
 , et la seconde à gauche par
, et la seconde à gauche par  , en prenant
, en prenant  , on a :
, on a : ,
, .
.
Ainsi, σ1 = 2 λ1 = 2 λ2. Par les propriétés de la fonction Φ définie par
 , on a :
, on a : , et de même,
, et de même,  .
.
D'autres vecteurs singuliers et valeurs singulières peuvent être obtenus en maximisant σ(u, v) sur u, v, qui sont orthogonaux à u1 et v1, respectivement.
On peut de même traiter le cas de matrices complexes.
Valeurs singulières et vecteurs singuliers
Un réel positif σ est appelé valeur singulière de M si et seulement s'il existe un vecteur unitaire u dans Km et un vecteur unitaire v dans Kn tel que :
 et
et 
Les vecteurs u et v sont appelés vecteur singulier à gauche et vecteur singulier à droite pour σ, respectivement.
Dans toute décomposition en valeurs singulières,
 ,
,
les coefficients diagonaux de Σ sont égaux aux valeurs singulières de M. Les colonnes de U et de V sont, respectivement, vecteur singulier à gauche et à droite pour les valeurs singulières correspondantes.
Par conséquent, le théorème ci-dessus énonce que :
- Une matrice M m × n possède au moins 1 et au plus p = min(m,n) valeurs singulières distinctes ;
- Il est toujours possible de trouver une base unitaire pour Km constituée des vecteurs singuliers à gauche de M ;
- Il est toujours possible de trouver une base unitaire pour Kn constituée des vecteurs singuliers à droite de M ;
Une valeur singulière pour laquelle on peut trouver deux vecteurs singuliers à gauche (respectivement, à droite) qui ne sont pas linéairements indépendants est dite dégénérée.
Les valeurs singulières non-dégénérées ont toujours un unique vecteur singulier à gauche et à droite, à un déphasage près, c’est-à-dire à une multiplication par un facteur de la forme eiφ près (pour des réels, à un signe près). Par conséquent, si toutes les valeurs singulières de M sont non-dégénérées et non-nulles, alors sa décomposition en valeurs singulières est unique, à une multiplication d'une colonne de U et de la colonne de V correspondante par un même de déphasage.
Les valeurs singulières dégénérées, par définition, possèdent plusieurs vecteurs singuliers. De plus, si u1 et u2 sont deux vecteurs singuliers à gauche qui correspondent à une même valeur singulière σ, alors tout vecteur unitaire obtenu par combinaison linéaire de ces deux vecteurs est également un vecteur singulier à gauche pour σ. Il en est de même pour les vecteurs singuliers à droites. Ainsi, si M possède des valeurs singulières dégénérées, alors sa décomposition en valeurs singulières n'est pas unique.
Lien avec la décomposition en valeurs propres
La décomposition en valeurs singulières est très générale, dans le sens où elle s'applique à toute matrice rectangulaire m × n. La décomposition en valeurs propres, en revanche, ne fonctionne que pour certaines matrices carrées. Néanmoins, quand elles sont toutes les deux définies, elles sont liées.
Dans le cas d'une matrice M hermitienne semi-définie positive, c'est-à-dire dont toutes les valeurs propres sont des réels positifs, alors les valeurs singulières et vecteurs singuliers correspondent aux valeurs propres et vecteurs propres de M :
Plus généralement, étant donnée une décomposition en valeurs singulières de M, alors on a :
 et
et 
Le côté droit de ces relations décrit la décomposition en valeurs propres du côté gauche. Ainsi, le carré du module de chaque valeur singulière non-nulle de M est égal au module de la valeur propre non-nulle correspondante de M * M et de MM * . En outre, les colonnes de U (vecteurs singuliers à gauche) sont vecteurs propres pour MM * , et les colonnes de V (vecteurs singuliers à droite) sont vecteurs propres de M * M.
Interprétation géométrique
Puisque U et V sont unitaires, on sait que les colonnes u1,...,um de U forment une base orthonormée de Km et que les colonnes v1,...,vn de V forment une base orthonormée de Kn (par rapport au produit scalaire sur ces espaces).
La transformation linéaire T: Kn → Km, qui à chaque vecteur x associe Mx, a une expression relativement simple dans ces bases orthonormées : T(vi) = σi ui, pour i = 1,...,min(m,n), où σi est le i-ème coefficient diagonal de Σ, et T(vi) = 0 pour i > min(m,n).
Le contenu géométrique du théorème de décomposition en valeurs singulières peut être résumé ainsi : pour toute application linéaire T : Kn → Km, on peut trouver une base orthonormale pour Kn et une base orthonormale pour Km telles que T associe au i-ème vecteur de base de Kn un multiple positif du i-ème vecteur de base de Km, les vecteurs restants ayant pour image 0. Dans ces bases, l'application T est ainsi représentée par une matrice diagonale dont les coefficients sont des réels positifs.
Interprétation statistique
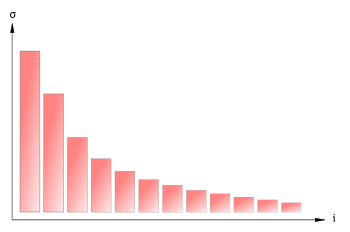 Les valeurs de la diagonale de la matrice Σ, rapidement décroissantes, peuvent être comprises comme des coefficients d'énergie. En sélectionnant uniquement les premières, on peut construire un modèle simplifié, empirique, décrivant les données.
Les valeurs de la diagonale de la matrice Σ, rapidement décroissantes, peuvent être comprises comme des coefficients d'énergie. En sélectionnant uniquement les premières, on peut construire un modèle simplifié, empirique, décrivant les données.
On peut également interpréter cette décomposition dans l'esprit de l'étude statistique d'un ensemble de données. Alors, les principales colonnes de U représentent les tendances de l'ensemble d'étude (les vecteurs de U représentent les « directions de plus grande variation » de l'ensemble). Les valeurs diagonales de Σ sont alors analogues à l' « énergie » ou la « représentativité » qui va pondérer ces comportements ; elles décroissent d'autant plus vite que l'ensemble statistique est ordonné.
On peut considérer, par exemple dans l'optique du data mining, que les informations « importantes » de l'ensemble sont celles qui présentent une structure plus marquée. Alors, en annulant la diagonale de Σ au-delà d'un certain indice, puis en reconstituant la matrice de départ, on obtient des données filtrées, représentant l'information dominante de l'ensemble de départ. De façon équivalente, on peut considérer nulles des données d'énergie inférieure à un certain seuil.
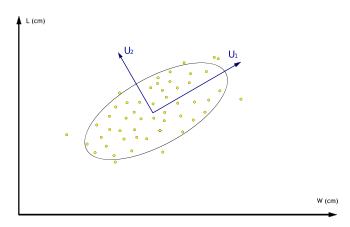 Effet de la décomposition SVD sur un ensemble de données, ici la largeur (W) et la hauteur (L) de visages humains. Les vecteurs U1 et U2 sont les deux premiers de la matrice U.
Effet de la décomposition SVD sur un ensemble de données, ici la largeur (W) et la hauteur (L) de visages humains. Les vecteurs U1 et U2 sont les deux premiers de la matrice U.Ainsi, la SVD permet de construire un modèle empirique, sans théorie sous-jacente, d'autant plus précis qu'on y injecte de termes.
Il est par ailleurs possible de reconstruire, en utilisant une base de vecteurs singuliers d'un premier jeu de données, un autre jeu de données avec plus ou moins de précision, afin de déterminer la similarité entre les deux. Selon ce principe, des systèmes de décomposition, de reconnaissance et de reconstruction faciale ont été développés[1].
L'efficacité de la méthode dépend en particulier de la manière dont on lui présente les informations. Dans l'exemple d'un visage, si on utilise « bêtement » la luminosité des différents pixels d'une photographie pour construire une base de vecteurs singuliers, alors il sera difficile de reconstruire le même visage dans une pose légèrement différente (ou si l'éclairement du visage a varié) : les pixels ont changé - parfois beaucoup - mais pas l'information implicite (à savoir le visage). On préfère, dans ces domaines d'application, traiter les données dans l'espace, d'où l'ajout d'un système de reconnaissance en 3D, qui permet d'« expliquer » les variations observées en reliant celles-ci, et de les relier aux données connues[1].
Histoire
La décomposition en valeurs singulières fut développée à l'origine par les mathématiciens étudiant la géométrie différentielle, qui désiraient déterminer si une forme bilinéaire réelle pouvait en égaler une autre par des transformations orthogonales indépendantes des deux espaces concernés.
Eugenio Beltrami et Camille Jordan ont découvert indépendamment, en 1873 et 1874 respectivement[2] , que les valeurs singulières des formes bilinéaires, représentées sous forme matricielle, constituaient un ensemble complet d'invariants pour les formes bilinéaires subissant des substitutions orthogonales.
James Joseph Sylvester s'intéressa également à la décomposition en valeurs singulières en 1889[2] pour les matrices réelles carrées, apparemment indépendamment des travaux de Beltrami et Jordan. Sylvester donna aux valeurs singulières le nom de « multiplicateurs canoniques » d'une matrice A.
Le quatrième mathématicien à l'origine de la découverte de cette décomposition est Autonne[3], en 1915. Il aboutit à ce résultat au travers de la décomposition polaire.
La première preuve de la décomposition en valeurs singulières pour les matrices rectangulaires et complexes est attribuée à Eckart et à Young, en 1936.
En 1907, Erhard Schmidt définit l'analogue des valeurs singulières pour les opérateurs intégraux[2] (qui, à certaines conditions près, sont compacts) ; il semble qu'il ne connaissait pas les travaux parallèles sur les valeurs singulières des matrices de dimension finie. Cette théorie fut développée encore par le mathématicien français Émile Picard en 1910, qui est à l'origine du terme moderne de « valeurs singulières » qu'il notait σk[2],[4].
Avant 1965, aucune méthode efficace de calcul de cette décomposition n'était connue. Gene H. Golub (de) et William Kahan (en) proposèrent un premier algorithme cette année[5], puis, en 1970, Golub et Christian Reinsch publièrent une variante de l'algorithme Golub-Kahan qui demeure aujourd'hui le plus utilisé[6].
La généralisation de cette décomposition à deux, trois ou N dimensions est encore un sujet de recherche active, puisqu'elle se révèle d'un intérêt majeur dans de nombreux domaines.
Exemple
Soit la matrice :
La décomposition en valeurs singulières de M est alors :
Ainsi, on a :
On vérifie que Σ ne possède des valeurs non nulles que sur sa diagonale. De plus, comme montré ci-dessous, en multipliant les matrices U et V * par leurs transposées, on obtient la matrice identité :
Et de même :
Variantes
SVD/ICA
Il est courant d'associer les résultats de la décomposition en valeurs singulières à ceux de l'analyse en composantes indépendantes (ou ICA)[7]. Les algorithmes qui exploitent une combinaison des deux sont couramment appelés SVD/ICA. En effet, l'analyse en composantes indépendantes tient compte des termes d'ordre supérieurs ou égaux à 2 négligés par la décomposition en valeurs singulières.
Décomposition généralisée
Le procédé de décomposition en valeurs singulières généralisée, ou GSVD, étend le concept de la décomposition en valeurs singulières en utilisant des seminormes quadratiques et s'applique aux systèmes linéaires.
Une matrice A m × n et une matrice B p × n réelles ou complexes étant données, leur décomposition généralisée est :
- A = UΣ1[0,R]Q *
et
- B = VΣ2[0,R]Q *
avec U,V et Q des matrices unitaires et R une matrice triangulaire supérieure, non-singulière, carrée r × r, en notant
 le rang de [A * ,B * ].
le rang de [A * ,B * ].Par ailleurs, Σ1 et Σ2 sont des matrices m × r et p × r respectivement, nulles partout sauf sur leur diagonale principale, qui contient les réels αi et βi respectivement, tels que :
 et
et  .
.
Les rapports σi = αi / βi sont analogues aux valeurs singulières. Dans le cas particulier, mais important, où B est carrée et inversible, elles sont les valeurs singulières, U U et V sont alors les vecteurs singuliers de la matrice AB − 1.
Décomposition 2D
 On peut généraliser la décomposition en valeurs singulières à plusieurs dimensions, en particulier pour traiter les images. Ici, une image puis ses valeurs singulières (3DSVD). Ici encore, elles décroissent rapidement.
On peut généraliser la décomposition en valeurs singulières à plusieurs dimensions, en particulier pour traiter les images. Ici, une image puis ses valeurs singulières (3DSVD). Ici encore, elles décroissent rapidement.Il est possible d'étendre le concept de décomposition en valeurs singulières à des matrices complexes, ou, de manière équivalente à des matrices constituées de vecteurs 2D. Le calcul est proche de celui de la décomposition en valeurs singulières simple. On parle de décomposition en valeurs singulières 2D, ou 2DSVD.
De même que pour le cas simple, il existe des algorithmes spécialisés qui donnent une approximation d'un ensemble de matrices de rang faible, par exemple des images ou des cartes météorologiques.
Soit X = (x1,...,xn) un ensemble de réels (c'est-à-dire de vecteurs 1D). Pour la décomposition en valeurs singulières, on construit la matrice de covariance et la matrice de Gram :
- F = XXT , G = XTX.
En calcule ensuite leurs vecteurs propres U = (u1,...,un) et V = (v1,...,vn). Puisque VVT = I,UUT = I, on a :
- X = UUTXVVT = U(UTXV)VT = UΣVT.
En ne gardant que les K vecteurs propres principaux de U et V, on obtient ainsi une approximation de rang faible de la matrice X. Pour les algorithmes de 2DSVD, on travaille avec des matrices 2D, c'est-à-dire un ensemble de matrices (X1,...,Xn) . On construit les matrices de covariance ligne-ligne et colonne-colonne :
 ,
,  .
.
Pour ce faire, on agit de la même façon que pour la décomposition classique, et on calcule leurs vecteurs propres U et V. On approche les Xi :
- Xi = UUTXiVVT = U(UTXiV)VT = UMiVT
par une méthode identique à celle de la décomposition en valeurs singulières.
On obtient ainsi une approximation de (X1,...,Xn) par la fonction :
Les algorithmes de 2DSVD sont principalement utilisés en compression et représentation d'images. L'utilisation de la SVD pour la compression d'images a toutefois été montrée comme étant sous-optimale par rapport à une DCT, notamment à cause de l'obligation de transmettre la transformée elle-même, en plus des données image[8]. Son rôle dans le domaine de la compression est de fait marginal.
Décomposition 3D
En considérant l'utilisation de matrices dépliées, on peut étendre la décomposition en valeurs singulières aux cas tridimensionnels, ou 3DSVD. De tels algorithmes sont utilisés en sismologie, en météorologie et en acoustique, où l'analyse de données 3D (ou 2D dépendant du temps) est souvent nécessaire.
Décompositions réduites
Dans les utilisations, il est assez rare de devoir utiliser la forme complète de la décomposition en valeurs singulières, y compris la décomposition complète du noyau sous forme unitaire. Il est en effet courant, plus rapide, et moins coûteux en termes de mémoire, d'utiliser des versions réduites de la SVD. Les décompositions suivantes sont valables pour les matrices m × n de rang r.
SVD « fine »
Seuls les n vecteurs colonnes de U correspondant aux vecteurs lignes de V* sont calculés. Les vecteurs colonnes restant de U ne sont pas calculés, ce qui économise une quantité importante de calculs si
 . La matrice Un est ainsi m × n, Σn est diagonale n × n et V est n × n.
. La matrice Un est ainsi m × n, Σn est diagonale n × n et V est n × n.La première étape du calcul d'une SVD « fine » est la décomposition QR de M, qui peut être optimisée pour
.SVD « compacte »
Seuls les r vecteurs colonnes de U et les r vecteurs lignes de V* correspondants aux valeurs singulières non-nulles Σr sont calculés. On obtient un résultat plus rapidement qu'avec la SVD « fine » si
 . La matrice Ur est ainsi m × r, Σr est diagonale r × r et Vr* est r × n.
. La matrice Ur est ainsi m × r, Σr est diagonale r × r et Vr* est r × n.SVD « tronquée »
Seuls les t vecteurs colonnes de U et les t vecteurs lignes de V* correspondants aux t plus grandes valeurs singulières Σr sont calculées. C'est un calcul encore plus rapide que la SVD « fine » si
 . La matrice Ut est ainsi m×t, Σt est diagonale t × t et Vt* est t × n.
. La matrice Ut est ainsi m×t, Σt est diagonale t × t et Vt* est t × n.Cependant, cette décomposition « tronquée » n'est plus une décomposition exacte de la matrice d'origine M, mais la matrice obtenue,
 , est la meilleure approximation de M obtenue par une matrice de rang t, pour la norme d'opérateur subordonnée aux normes euclidiennes de Rn et Rm.
, est la meilleure approximation de M obtenue par une matrice de rang t, pour la norme d'opérateur subordonnée aux normes euclidiennes de Rn et Rm.Normes
Normes de Ky Fan
La somme des k plus grandes valeurs singulières de M est une norme sur l'espace vectoriel des matrices, appelée norme de Ky Fan ou norme k de M.
La première des normes de Ky Fan, la norme 1 de Ky Fan, est la même que la norme d'opérateur de M en tant qu'opérateur linéaire, selon les normes euclidiennes de Km et Kn. En d'autres termes, la norme 1 de Ky Fan est la norme d'opérateur induite par le produit intérieur euclidien standard l2. Pour cette raison, on l'appelle également norme 2 d'opérateur. On peut facilement vérifier la relation en la norme 1 de Ky Fan et les valeurs singulières. C'est vrai en général, pour un opérateur borné M sur un espace de Hilbert (potentiellement infini) :
Cependant, dans le cas des matrices, M*M½ est une matrice normale, donc ||M*M||½ est la plus grande valeur propre de M*M½, donc la plus grande valeur singulière de M.
La dernière norme de Ky Fan, qui est égale à la somme de toutes les valeurs singulières, est la norme de trace définie par ||M|| = Tr (M*M)½.
On considère la forme linéaire définie dans l'algèbre des matrices d'ordre n par:
On considère la norme spectrale
 des matrices et l'on définit la norme duale de uX par:
des matrices et l'on définit la norme duale de uX par:On vérifie alors aisément que cette norme duale est en fait la norme trace de X définie ci-dessus. De plus, cette norme est une norme d'algèbre.
Norme de Hilbert-Schmidt
Les valeurs singulières sont liées à une autre norme sur l'espace des opérateurs. On considère le produit intérieur de Hilbert-Schmidt sur les matrices n × n, défini par <M, N> = Tr N*M. Alors la norme induite est ||M|| = <M, M>½ = (Tr M*M)½. La trace étant un invariant d'équivalence unitaire, cela implique que :
 ,
,
où les si sont les valeurs singulières de M. On l'appelle norme de Frobenius, norme 2 de Schatten ou norme de Hilbert-Schmidt de M. On montre également que si :
 ,
,
alors cette norme coïncide avec :
 .
.
Opérateurs bornés sur les espaces de Hilbert
La factorisation M = UΣV * peut être étendue comme opérateur borné M sur un espace de Hilbert H. D'une façon générale, pour tout opérateur borné M, il existe une isométrie partielle U, un vecteur unitaire V, un espace de mesure (X, μ) et f mesurable positive telle que :
où Tf est la mutliplication par f sur L2(X, μ).
On peut le montrer en travaillant l'argument d'algèbre linéaire utilisé pour le cas matriciel. VTf V* est l'unique racine positive de M*M, donnée par l'analyse fonctionnelle de Borel, pour les opérateurs auto-adjoints. La raison pour laquelle U n'a pas besoin d'être unitaire est liée au fait que, contrairement au cas de dimension finie, étant donnée une isométrie U1 avec un noyau non trivial, une isométrie U2 existe telle que :
est un opérateur unitaire.
Puisque, pour les matrices, la décomposition en valeurs singulières est équivalente à la décomposition polaire pour les opérateurs, on peut réécrire cela sous la forme :
et remarquer que U V* est encore une isométrie partielle tant que VTf V* est positif.
Valeurs singulières et opérateurs compacts
Pour étendre la notion de valeur singulière et de vecteurs singuliers au cas des opérateurs, on doit se restreindre aux opérateurs compacts sur les espaces de Hilbert. On rappelle certaines propriétés utiles :
- Les opérateurs compacts sur les espaces de Banach, donc de Hilbert, possèdent un spectre discret ;
- Si T est compact, tout λ de son spectre, non-nul, est une valeur propre ;
- Un opérateur compact auto-adjoint peut être diagonalisé par ses vecteurs propres ;
- Si M est compact, alors M*M l'est également.
En utilisant la diagonalisation, l'image unitaire de la racine carrée positive de M, notée Tf, possède une famille orthonormale de vecteurs propres {ei}, correspondants aux valeurs propres strictement positives {σi}. Pour tout ψ ∈ H,
quand la série converge normalement dans H. On remarque que cette expression est proche de celle dans le cas de dimension finie.
Les σi sont appelées valeurs singulières de M. {U ei} et {V ei} sont analogues aux vecteurs singuliers à gauche et à droite respectivement pour M.
Utilisations
Calcul du pseudo-inverse
La décomposition en valeurs singulières permet de calculer le pseudo-inverse d'une matrice. En effet, le pseudo-inverse d'une matrice M connaissant sa décomposition en valeurs singulières M = UΣV * , est donné par :
avec Σ+ la transposée de Σ où tout coefficient non-nul est remplacé par son inverse. Le pseudo-inverse lui-même permet de résoudre la méthode des moindres carrés.
Image, rang et noyau
Une autre utilisation de la décomposition en valeurs singulières est la représentation explicite de l'image et du noyau d'une matrice M. Les vecteurs singuliers à droite correspondant aux valeurs singulières nulles de M engendrent le noyau de M. Les vecteurs singuliers à gauche correspondant aux valeurs singulières non-nulles de M engendrent son image.
Par conséquent, le rang de M est égal au nombre de valeurs singulières non-nulles de M. De plus, les rangs de M, de M * M et de MM * sont égaux. M * M et MM * ont les mêmes valeurs propres non-nulles.
En algèbre linéaire, on peut prévoir numériquement le rang effectif d'une matrice, puisque les erreurs d'arrondi pourraient autrement engendrer des valeurs petites mais non-nulles, faussant le calcul du rang de la matrice.
Approximations de matrices, le théorème d'Eckart Young
 Approximations successives d'une image, avec 1, 2, 4, 8, 16, 32, 64, 128 puis toutes les valeurs singulières (original à gauche).
Approximations successives d'une image, avec 1, 2, 4, 8, 16, 32, 64, 128 puis toutes les valeurs singulières (original à gauche).Certaines applications pratiques ont besoin de résoudre un problème d'approximation de matrices M à partir d'une matrice
ayant un rang donné, égal à r. Dans le cas où on tente de minimiser la distance au sens de la norme spectrale (ou aussi de Frœbenius) entre M et , en gardant  , on constate que la solution est la décomposition en valeurs singulières de M, c'est-à-dire :
, on constate que la solution est la décomposition en valeurs singulières de M, c'est-à-dire :avec
 égale à Σ, si ce n'est qu'elle ne contient que les r plus grandes valeurs singulières, les autres étant remplacées par 0. Voici une démonstration :Démonstration
égale à Σ, si ce n'est qu'elle ne contient que les r plus grandes valeurs singulières, les autres étant remplacées par 0. Voici une démonstration :DémonstrationOn se limite aux matrices carrées par souci de simplification. On utilise le symbole norme triple pour représenter la norme spectrale. On prouve le théorème d'Eckart Young tout d'abord pour la norme spectrale. Sans perte de généralité, on peut supposer que A est une matrice diagonale et donc que U et V sont la matrice identité. On pose donc A = Σ. Les termes diagonaux de A sont notés σi. Ils sont triés par ordre décroissant. On a donc
On considère une matrice B quelconque de rang r. On considère le sous-espace vectoriel E de
 engendrés par les vecteurs
engendrés par les vecteurs  où chacun des ei est le vecteur
où chacun des ei est le vecteur  non nul au rang i. Ce sous-espace vectoriel est de dimension r+1. Comme la matrice B est de rang r, le noyau de B est de rang n-r. Par un argument simple aux dimensions, l'intersection de E et du noyau de B n'est pas nulle. On considère un vecteur normalisé x appartenant à cette intersection. On définit
non nul au rang i. Ce sous-espace vectoriel est de dimension r+1. Comme la matrice B est de rang r, le noyau de B est de rang n-r. Par un argument simple aux dimensions, l'intersection de E et du noyau de B n'est pas nulle. On considère un vecteur normalisé x appartenant à cette intersection. On définit  On a alors
On a alorsComme les vecteurs ei sont orthogonaux et normés, on obtient:
Par définition de la norme spectrale, on déduit donc que quelle que soit la matrice B, on a
On conclut la preuve en choisissant
 . n constate alors aisément que
. n constate alors aisément que  .
.Donc B = Σ' est la matrice de rang r qui minimise la norme spectrale de A - B.
En ce qui concerne la preuve pour la norme de Frœbenius, on garde les mêmes notations et on remarque que
La preuve est alors similaire.
Ainsi,
 , matrice de rang r, est la meilleure approximation de M au sens de la norme de Frobenius (ou spectrale) quand
, matrice de rang r, est la meilleure approximation de M au sens de la norme de Frobenius (ou spectrale) quand  . De plus, ses valeurs singulières sont les mêmes que celles de M.
. De plus, ses valeurs singulières sont les mêmes que celles de M.Application aux langues naturelles
Une des principales utilisation de la décomposition en valeurs singulières dans l'étude des langues naturelles est l'analyse sémantique latente (ou LSA, de l'anglais latent semantic analysis), une méthode de la sémantique vectorielle. Ce procédé a pour but l'analyse des relations entre un ensemble de documents et des termes ou expressions qu'on y trouve, en établissant des « concepts » communs à ces différents éléments.
Brevetée en 1988[9], on parle également d'indexation sémantique latente (LSI). Voici une description sommaire du principe de cet algorithme.
Dans un premier temps, on construit une matrice représentant les différentes occurrences des termes (d'un dictionnaire prédéterminé, ou extraits des documents), en fonction des documents. Par exemple, prenons trois œuvres littéraires :
- Document 1 : « J'adore Wikipédia »
- Document 2 : « J'adore le chocolat »
- Document 3 : « Je déteste le chocolat »
Alors la matrice M associée à ces documents sera :
-
J' Je adore déteste le Wikipédia chocolat Document 1 1 0 1 0 0 1 0 Document 2 1 0 1 0 1 0 1 Document 3 0 1 0 1 1 0 1
Éventuellement, on peut réduire certains mots à leur radical ou à un mot équivalent, ou même négliger certains termes trop courts pour avoir un sens ; la matrice contient alors Je, adorer, détester, Wikipédia, chocolat. Les coefficients (ici 1 ou 0) sont en général non pas un décompte mais une valeur proportionnelle au nombre d'occurrences du terme dans le document, on parle de pondération « tf-id » (term frequency — inverse document frequency).
Alors M sera de la forme :
On peut également travailler avec la transposée de M, que l'on note N. Alors les vecteurs lignes de N correspondent à un terme donné, et donnent accès à leur « relation » à chaque document :
Et de même, une colonne de la matrice N représente un document donné, et donne accès à sa relation à chaque terme :
On accède à la corrélation entre les termes de deux documents en effectuant leur produit scalaire. La matrice symétrique obtenue en calculant le produit S = NNT contient tous ces produits scalaires. L'élément de S d'indice (i,p) contient le produit :
 .
.
De même, la matrice symétrique Z = NTN contient les produits scalaires entre tous les documents, qui donne leur corrélation selon les termes :
 .
.
On calcule maintenant la décomposition en valeurs singulières de la matrice N, qui donne les matrices telles que :
- M = UΣVT
Alors les matrices de corrélation deviennent :
La matrice U contient les vecteurs propres de S, la matrice V contient ceux de Z. On a alors :
Les valeurs singulières,
 peuvent alors être sélectionnées, pour obtenir une « approximation » de la matrice à un rang k arbitraire, qui permet une analyse plus ou moins précise des données.
peuvent alors être sélectionnées, pour obtenir une « approximation » de la matrice à un rang k arbitraire, qui permet une analyse plus ou moins précise des données.Cinématique inverse
En robotique, le problème de la cinématique inverse, qui consiste essentiellement à savoir « comment bouger pour atteindre un point, » peut être abordé par la décomposition en valeurs singulières.
Énoncé du problème
On peut considérer — c'est un modèle très général — un robot constitué de bras articulés, indicés i, formant un angle θi entre eux, dans un plan. On note X le vecteur représentant la position du « bout » de cette chaine de bras, qui en pratique est une pince, une aiguille, un aimant… Le problème va être de déterminer le vecteur θ, contenant tous les θi, de sorte que X soit égal à une valeur donnée X0.
Résolution
On définit le jacobien de X par :
 .
.
On a alors :
 .
.
Si J est inversible (ce qui est, en pratique, toujours le cas), on peut alors accéder à la dérivée de θ :
 .
.
Si J n'est pas inversible, on peut de toute façon utiliser la notion de pseudo-inverse. Néanmoins, son utilisation ne garantit pas que l'algorithme converge, il faut donc que le jacobien soit nul en un nombre réduit de points. En notant (U,Σ,V) la décomposition en valeurs singulières de J, l'inverse (le pseudo-inverse si J n'est pas inversible) de J est donné par :
 (cas inversible) ;
(cas inversible) ; (cas pseudo-inversible).
(cas pseudo-inversible).
On a noté Σ+ la matrice diagonale comportant l'inverse des valeurs singulières non-nulles. Dans la suite, la notation J-1 renverra sans distinction à l'inverse ou au pseudo-inverse de J.
Le calcul des vecteurs colonne de J peut être effectué de la manière qui suit :
- On note Xi la position de l'articulation i ;
- On note ez le vecteur unitaire de même direction que l'axe de rotation de l'articulation ;
Alors
 .
.On peut alors discrétiser l'équation, en posant :
Et en ajoutant Δθ à θ à chaque itération, puis en recalculant ΔX et Δθ, on atteint peu à peu la solution désirée.
Résolution alternative
Il est également possible d'utiliser la décomposition en valeurs singulières de J autrement pour obtenir Δθ :
En multipliant successivement à gauche par J puis par sa transposée, pour enfin utiliser la décomposition en valeurs singulières de JTJ, on a :
Soit en conclusion :
 .
.
Autres exemples
Une utilisation courante de la décomposition en valeurs singulières est la séparation d'un signal sur deux sous-espaces supplémentaires, par exemple un sous-espace « signal » et un sous-espace de bruit. La décomposition en valeurs singulières est beaucoup utilisée dans l'étude de l'inversion de matrices, très pratique dans les méthodes de régularisation. On l'emploie également massivement en statistiques, en traitement du signal, en reconnaissance de formes et dans le traitement informatique des langues naturelles.
De grandes matrices sont décomposées au travers de cet algorithme en météorologie, pour l'algorithme de Lanczos par exemple.
L'étude géologique et sismique, qui a souvent à faire avec des données bruitées, fait également usage de cette décomposition - et de ses variantes multidimensionnelles - pour « nettoyer » les spectres obtenus. Étant donnés un certain nombre d'échantillons connus, certains algorithmes peuvent, au moyen d'une décomposition en valeurs singulières, opérer une déconvolution sur un jeu de données.
Calcul de la SVD
Le calcul explicite, analytique, de la décomposition en valeurs singulières d'une matrice est difficile dans le cas général. On utilise, en particulier dans les applications, des algorithmes spécialisés.
La procédure DGESVD[10] de la librairie LAPACK propose une approche courante pour le calcul de la décomposition en valeurs singulières d'une matrice. Si la matrice possède plus de lignes que de colonnes, on effectue tout d'abord une décomposition QR. Le facteur R est ensuite réduit sous forme bidiagonale. Pour ceci, on peut effectuer des transformations de Householder alternativement sur les colonnes et sur les lignes de la matrice. Les valeurs singulières et vecteurs singuliers sont alors trouvés en effectuant une itération de type QR bidiagonale avec la procédure DBDSQR[11].
GNU Scientific Library propose trois alternatives : l'algorithme de Golub-Reinsch, l'algorithme de Golub-Reinsch modifié (plus rapide pour les matrices possédant bien plus de lignes que de colonnes) et l'orthogonalisation de Jacobi[12].
Voir aussi
Bibliographie
- (en) Abdi, H. « Décomposition en valeurs singulières (SVD) et décomposition généralisée (GSVD) », Encyclopedia of Measurement and Statistics. Thousand Oaks (CA) ;
- (en) Demmel, J. and Kahan, W. (1990). « Calcul de petites valeurs singulières de matrices bidiagonales avec précision garantie », SIAM J. Sci. Statist. Comput., 11 (5), 873-912 ;
- (en) Golub, G. H. et Van Loan, C. F. (1996). « Calculs matriciels », 3e ed., Johns Hopkins University Press, Baltimore. ISBN 0-8018-5414-8 ;
- (en) Eckart C. et Young G. (1936). « Approximations d'une matrice par une autre de rang inférieur », Psychometrika, I, 211-218 ;
- (en) Halldor, Bjornsson et Venegas, Silvia A. (1997). « Manuel d'études des données climatiques par la SVD », McGill University, CCGCR Report No. 97-1, Montréal, Québec, 52pp ;
- (en) Hansen P. C. (1987). « SVD tronquée comme méthode de régularisation », BIT, 27, 534-553 ;
- (en) Horn, Roger A. et Johnson, Charles R (1985). « Analyse matricielle », Section 7.3. Cambridge University Press. ISBN 0-521-38632-2 ;
- (en) Horn, Roger A. et Johnson, Charles R (1991). « Analyse matricielle », Chapter 3. Cambridge University Press. ISBN 0-521-46713-6 ;
- (en) Strang G (1998). « Introduction à l'algèbre linéaire », Section 6.7. 3e ed., Wellesley-Cambridge Press. ISBN 0-9614088-5-5 ;
- (en) Chris Ding et Jieping Ye. « Décomposition 2D (2DSVD) pour cartes et images », Proc. SIAM Int'l Conf. Data Mining (SDM'05), pp:32-43, April 2005 ;
- (en) Jieping Ye. « Approximations de faible rang de matrices généralisées », Machine Learning Journal. Vol. 61, pp. 167—191, 2005 ;
- (de) Günter Gramlich : « Applications en algèbre linéaire avec MATLAB® », Carl Hanser Verlag, 2004. ISBN 3-446-22655-9.
Articles connexes
- Analyse en composantes principales ;
- Analyse en composantes indépendantes ;
- Théorème spectral ;
- Algèbre linéaire.
Liens externes
Implémentations
- (en) ALGLIB propose une adaptation de LAPACK dans différents langages ;
- (en) Librairie Java SVD ;
- (en) Opencv : librairie d'analyse d'images en C/C++ ;
- (en) PROPACK : programme de calcul de la SVD ;
- (en) Script Java calculant la SVD ;
- (en) SVDPACK : librairie ANSI FORTRAN 77 qui propose 4 implémentations intératives de la SVD ;
- (en) SVDLIBC : adaptation de SVDPACK en C ;
- (en) BlueBit propose une librairie .NET capable de calculer la SVD.
- Calcul de SVD pour le langage Python :
- (en) NumPy : gère les matrices réelles ou complexes
- (en) SciPy : gère les matrices réelles ou complexes
- (en) Gensim, implémentation basée sur NumPy : permet une SVD tronquée sur des matrices creuses plus grandes que la mémoire vive
- (en) SVDLIBC : ré-écriture de SVDPACK, avec des bogues réparés
- (en) sparsesvd : wrapper autour de SVDLIBC
- (en) SVD-Python : en Python pur, sous GNU GPL.
Cours et conférences
- Cours sur la SVD, ses variantes et ses applications ;
- SVD, 2DSVD, 3DSVD et applications ;
- Décomposition en valeurs singulières ;
- (en) La SVD et ses applications ;
- (en) Conférence vidéo au MIT, par Gilbert Strang. La Lecture #29 porte sur la SVD ;
- (en) Introduction à la décomposition en valeurs singulières par Todd Will, Université du Wisconsin-La Crosse ;
- (de) Preuve de l'existence.
Explications et applications
- SVD : application à la restauration d'images ;
- Utilisations de la SVD ;
- INRIA : Applications de la SVD aux ondes sismiques ;
- (en) Applications de la SVD ;
- (en) « SVD for genome-wide expression data processing and modeling », université Stanford : analyse des gènes avec la SVD ;
- (en) université Stanford : analyse de l'influence de certains gènes sur le cancer, au moyen de la SVD ;
- (en) Los Alamos group : analyse de données génétiques ;
- (en) LSA : applications, explications et possibilité de l'utiliser ;
- (en) Présentation et exemple d'utilisation ;
- (en) SVD, explications supplémentaires;
- (en) Manuel LAPACK : détails sur les procédures de calculs ;
- (en) Plus d'informations sur les implémentations en C de la SVD.
Notes et références
- (en) Muller, Magaia, Herbst : « Singular Value Decomposition, Eigenfaces, and 3D reconstructions, » 2004.
- (en) G.W. Stewart : « Histoire des débuts de la décomposition en valeurs singulières », Université du Maryland, 1992.
- L. Autonne, « Sur les matrices hypohermitiennes et sur les matrices unitaires », 1915.
- E. Schmidt, « Zur Theorie der linearen und nichtlinearen Integralgleichungen », 1907.
- G.H. Golub, W. Kahan, « Calculating the singular values and peusoinverse of a matrix », 1965.
- G.H. Golub, C.Reinsch : « Singular value decomposition and least squares solution », 1970.
- Il n'est également pas rare de les opposer, puisqu'elles peuvent donner des résultats contradictoires. On peut lire à ce sujet, au sujet des EEG, en anglais : Drozd, Husar, Nowakowski, Henning : « Detecting evoked potentials with SVD- and ICA-based statistical models, Engineering in Medicine and Biology Magazine, IEEE, 2005.
- Sven Ole Aase, John Håkon Husøy, P. Waldemar, « A critique of SVD-based image coding systems ».IEEE International Symposium on Circuits and Systems, 1999.
- (en) Dépôt de brevet par Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landauer, Karen Lochbaum et Lynn Streeter.
- Code source (fortran 77)
- Code source (fortran 77)
- Voir le manuel de la GSL concernant la SVD.
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Singular Value Decomposition » (voir la liste des auteurs)

La version du 1er mai 2007 de cet article a été reconnue comme « bon article », c'est-à-dire qu'elle répond à des critères de qualité concernant le style, la clarté, la pertinence, la citation des sources et l'illustration.











































Wikimedia Foundation. 2010.