- Loi de probabilité
-
En théorie des probabilités et en statistique, une loi de probabilité décrit soit les probabilités de chaque valeur d'une variable aléatoire (quand la variable aléatoire est discrète), soit la probabilité que la variable aléatoire appartienne à un intervalle arbitraire (quand la variable est continue)[1]. La loi de probabilité décrit l'ensemble des valeurs qu'une variable aléatoire peut atteindre et la probabilité que la valeur de la variable aléatoire soit dans n'importe quel sous ensemble (mesurable) de cet ensemble.
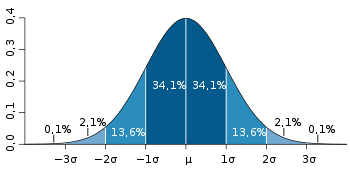 La loi normale, souvent appelée la « courbe en cloche »
La loi normale, souvent appelée la « courbe en cloche »
Quand la variable aléatoire prend ses valeurs dans
 la loi de probabilité est complètement déterminée par sa fonction de répartition, dont la valeur en chaque réel x est la probabilité que la variable aléatoire soit inférieure ou égale à x.
la loi de probabilité est complètement déterminée par sa fonction de répartition, dont la valeur en chaque réel x est la probabilité que la variable aléatoire soit inférieure ou égale à x.Le concept de loi de probabilité (et le concept de variable aléatoire) sont les fondements des disciplines mathématiques appelées théorie des probabilités, et statistique. Il y a de la fluctuation ou de la variabilité dans presque toute valeur qui peut être mesurée dans une population (par exemple la taille des individus, la durabilité d'une pièce de métal, etc.) ; presque toutes les mesures ont une part d'erreur intrinsèque ; en physique, de nombreux processus ont une description probabiliste, de la théorie cinétique des gaz à la description quantique des particules élémentaires. Pour ces raisons en particulier, et pour beaucoup d'autres raisons, de simples nombres sont souvent inadéquats pour décrire une quantité, alors qu'une loi de probabilité est plus appropriée.
Bien des lois de probabilités apparaissent dans les applications. Une des plus importantes est la loi normale, qui est aussi connue sous le nom de distribution gaussienne ou de courbe en cloche et qui approxime de nombreuses lois de probabilités apparaissant dans les applications. Le jet d'une pièce donne lieu à une autre loi de probabilité naturelle, dont les valeurs possibles sont pile ou face, chacune avec probabilité 1/2.
Définition informelle
Une loi de probabilité se caractérise de différentes manières. Le plus souvent, on utilise la fonction de répartition pour caractériser une loi. Cela présente l'avantage d'être valable aussi bien pour les lois discrètes que continues. Dans le cas d'une loi continue, on utilise très souvent la densité, alors que dans le cas discret, la donnée des probabilités élémentaires suffit à caractériser la loi en question.
Exemples de lois discrètes
Une variable aléatoire X est discrète si l'ensemble de ses valeurs possibles est fini ou dénombrable. On dit alors que sa loi est discrète. Pour une définition plus formelle, voir la section "Classification des lois de probabilités sur la droite réelle". Pour la plupart des lois discrètes classiques, les valeurs possibles de X sont des entiers naturels. On définit alors la loi discrète en donnant la probabilité que X prenne chaque valeur entière possible n, soit
 ou
ou 
Loi uniforme discrète
Article détaillé : Loi uniforme discrète.La loi uniforme discrète correspond à des événements équiprobables (exemple : lancer de dés, n=6 ) :
Loi de Bernoulli
Article détaillé : Loi de Bernoulli.La loi de Bernoulli correspond à une expérience à deux issues (succès - échec), codées resp. par les valeurs 1, 0, et en général non équiprobables :
 où p est la probabilité de succès
où p est la probabilité de succès où q = 1-p est la probabilité d'échec
où q = 1-p est la probabilité d'échec

Loi binomiale
Article détaillé : Loi binomiale.C'est la loi du nombre de succès obtenus à l'issue de n épreuves de Bernoulli indépendantes de paramètre p.
 pour tout k de 0 à n, p étant un réel compris entre 0 et 1
pour tout k de 0 à n, p étant un réel compris entre 0 et 1
 où q = 1 − p
où q = 1 − p
Loi hypergéométrique
Article détaillé : Loi hypergéométrique.On tire simultanément n boules dans une urne contenant pA boules gagnantes et qA boules perdantes (avec q = 1 - p, soit un nombre total de boules valant pA + qA = A). On compte alors le nombre de boules gagnantes extraites et on appelle X la variable aléatoire donnant le nombre de boules gagnantes.
 où A est un entier, pA et n des entiers inférieurs à A
où A est un entier, pA et n des entiers inférieurs à A
Loi de Poisson
Article détaillé : Loi de Poisson.Loi géométrique
Article détaillé : Loi géométrique.On considère une épreuve de Bernoulli dont la probabilité de succès est p et celle d'échec q = 1 - p.
On renouvelle cette épreuve de manière indépendante jusqu'au premier succès. On appelle X la variable aléatoire donnant le rang du premier succès.
Exemples de lois à densité
Article détaillé : Densité de probabilité.Une variable aléatoire réelle
 possède une densité de probabilité
possède une densité de probabilité  , si pour tous nombres réels
, si pour tous nombres réels  on a
on aOn dit aussi alors que la loi
 de possède une densité, ou bien est à densité. D'une manière équivalente, on dit que est absolument continue par rapport à la mesure de Lebesgue.
de possède une densité, ou bien est à densité. D'une manière équivalente, on dit que est absolument continue par rapport à la mesure de Lebesgue.En conséquence,
 pour tout nombre réel
pour tout nombre réel  et la fonction de répartition
et la fonction de répartition  de est continue. On a plus précisément
de est continue. On a plus précisémentLes variables aléatoires à densité sont parfois appelées variables continues.
Loi uniforme
Article détaillé : Loi uniforme continue.Loi uniforme continue sur un intervalle borné [a; b] :
Loi normale
Article détaillé : Loi normale.Loi exponentielle
Article détaillé : Loi exponentielle.Loi logistique
Article détaillé : Loi logistique.Loi de Cauchy
Article détaillé : Loi de Cauchy.
La loi de Cauchy n'admet aucun moment (donc ni moyenne ni variance, entre autres).
Loi de Tukey-Lambda
La Loi de Tukey-Lambda est connue de façon implicite par la distribution de ses quantiles :

elle a par la suite été généralisée.
Définition mathématique
En théorie des probabilités, une loi (ou mesure) de probabilité est une mesure positive
 sur un espace mesurable
sur un espace mesurable  , telle que
, telle que  . Le triplet
. Le triplet  est appelé espace probabilisé.
est appelé espace probabilisé.Définition — Soit une variable aléatoire réelle sur l'espace probabilisé
 , c'est-à-dire une fonction mesurable
, c'est-à-dire une fonction mesurable  (l'ensemble
(l'ensemble  étant muni de sa tribu borélienne
étant muni de sa tribu borélienne  ). On appelle loi (de probabilité) de la variable aléatoire la mesure de probabilité
). On appelle loi (de probabilité) de la variable aléatoire la mesure de probabilité  définie sur l'espace mesurable
définie sur l'espace mesurable  par :
par :pour tout borélien
 de
de  Autrement dit, est la mesure image de par .
Autrement dit, est la mesure image de par .Deux variables aléatoires réelles
et  ont même loi si
ont même loi si  (égalité de fonctions). Cela se réécrit
(égalité de fonctions). Cela se réécritou bien encore
Plus généralement, deux variables aléatoires réelles
et ont même loi sipour toute fonction
 de
de  dans telle qu'au moins un des deux termes de l'égalité ait un sens. Cela est dû au théorème de transfert, d'après lequel
dans telle qu'au moins un des deux termes de l'égalité ait un sens. Cela est dû au théorème de transfert, d'après lequelThéorème de transfert — Soit une variable aléatoire réelle
 Alors,
Alors,pour toute fonction
de dans telle qu'au moins un des deux termes de l'égalité ait un sens.L'intégrale apparaissant dans le deuxième terme est l'intégrale, au sens de la théorie de la mesure, de la fonction φ par rapport à la mesure
 Cette intégrale prend la forme d'une somme ou d'une intégrale dans les deux cas classiques où X est discrète et où X est à densité, voir ci-dessous.
Cette intégrale prend la forme d'une somme ou d'une intégrale dans les deux cas classiques où X est discrète et où X est à densité, voir ci-dessous.Caractérisation de la loi de probabilité d'une variable aléatoire réelle
En probabilité, il est crucial de pouvoir vérifier que deux variables aléatoires (réelles ou pas) ont la même loi de manière la plus économique possible, or les caractérisations ci-dessus exigent de vérifier des familles d'identités beaucoup trop riches (pour tout borélien B, pour toute fonction borélienne φ ...). Une solution plus ergonomique est fournie par les notions de fonction de répartition, ou de fonction caractéristique.
Caractérisation à l'aide de la fonction de répartition
La loi d'une variable aléatoire réelle est caractérisée par sa fonction de répartition : deux variables aléatoires réelles
et ont même loi si elles ont même fonctions de répartition, i.e. siAinsi il suffit de vérifier l'égalité caractéristique pour une famille réduite de boréliens
 très particuliers, les boréliens de la forme
très particuliers, les boréliens de la forme ![\scriptstyle\ ]-\infty,x],\](1/1711bb012e78b43510de09326a6dd123.png) pour démontrer les égalités
pour démontrer les égalités  et
et ![\scriptstyle\ \mathbb{E}\left[\phi(X)\right]\ =\ \mathbb{E}\left[\phi(Y)\right]](3/453c5f5c4cbd1b8e6c6d49f9756053a6.png) en toute généralité. Ce résultat crucial est une conséquence du Lemme de classe monotone dû à Wacław Sierpiński.
en toute généralité. Ce résultat crucial est une conséquence du Lemme de classe monotone dû à Wacław Sierpiński.Caractérisation à l'aide de la fonction caractéristique
La loi d'une variable aléatoire réelle est caractérisée par sa fonction caractéristique : deux variables aléatoires réelles
et ont même loi si elles ont même fonction caractéristique, i.e. siAinsi il suffit de vérifier l'égalité caractéristique pour une famille réduite de fonctions
très particulières, les fonctions de la forme  et
et  pour démontrer que et ont même loi.
pour démontrer que et ont même loi.Caractérisation à l'aide de la transformée de Laplace
La loi d'une variable aléatoire réelle positive ou nulle est caractérisée par sa transformée de Laplace : deux variables aléatoires réelles positives ou nulles
et ont même loi si elles ont même transformée de Laplace, i.e. siCaractérisation à l'aide de la fonction génératrice
La loi d'une variable aléatoire à valeurs entières positives ou nulles est caractérisée par sa fonction génératrice : deux variables aléatoires à valeurs entières positives ou nulles
et ont même loi si elles ont même fonction génératrice, i.e. siClassification des lois de probabilité sur la droite réelle
Les lois énumérées dans cet article sont des mesures de probabilités sur
 . Ces lois apparaissent en général dans les applications comme les lois de probabilité de certaines variables aléatoires réelles. Les lois énumérées dans cet article sont de deux types :
. Ces lois apparaissent en général dans les applications comme les lois de probabilité de certaines variables aléatoires réelles. Les lois énumérées dans cet article sont de deux types :- lorsque la loi de la variable aléatoire X est portée par un ensemble S

- tel que S est fini ou dénombrable, on parle de loi de probabilité discrète.
- D'un point de vue pratique, les calculs de probabilités ou bien d'espérances liées à font alors intervenir des calculs de sommes finies ou de séries:
![\mathbb{P}\left(X\in A\right)=\sum_{x\in A\cap S}\ \mathbb{P}\left(X=x\right),\qquad\mathbb{E}\left[\phi(X)\right]=\sum_{x\in S}\ \phi(x)\mathbb{P}\left(X=x\right).](8/588f4ca74cf9542b5db63246918e8616.png)
- Pour une variable discrète, on peut choisir comme ensemble
 l'ensemble des réels
l'ensemble des réels  tels que
tels que 
- La deuxième égalité ci-dessus est la spécialisation du théorème de transfert au cas particulier des variables discrètes, puisque dans ce cas particulier, on a

- lorsque la loi de est absolument continue par rapport à la mesure de Lebesgue sur
 , ou bien, d'une manière équivalente, lorsque la fonction de répartition de est localement absolument continue, on parle de variable ou de loi absolument continue, ou bien de variable ou de loi à densité. Dans ce cas, en vertu du Théorème de Radon-Nikodym, la mesure (ou la variable ) possède une densité de probabilité (notons-la ) par rapport à la mesure de Lebesgue. D'un point de vue pratique, les calculs de probabilités ou bien d'espérances liées à font alors intervenir des calculs d'intégrales :
, ou bien, d'une manière équivalente, lorsque la fonction de répartition de est localement absolument continue, on parle de variable ou de loi absolument continue, ou bien de variable ou de loi à densité. Dans ce cas, en vertu du Théorème de Radon-Nikodym, la mesure (ou la variable ) possède une densité de probabilité (notons-la ) par rapport à la mesure de Lebesgue. D'un point de vue pratique, les calculs de probabilités ou bien d'espérances liées à font alors intervenir des calculs d'intégrales :
![\mathbb{P}\left(X\in A\right)=\int_{A}\ f_X(x)\,dx,\qquad\mathbb{E}\left[\phi(X)\right]=\int_{\mathbb{R}}\ \phi(x)\ f_X(x)\,dx.](0/2f07ae48e32f4099d122c4651df0cf62.png)
- Là encore, la deuxième égalité ci-dessus est la spécialisation du théorème de transfert, mais cette fois, au cas particulier des variables à densité, puisque dans ce cas particulier, on a

- Une variable à densité vérifie
 pour tout nombre réel
pour tout nombre réel  Toutefois, cette dernière propriété, qui oppose les variables à densité aux variables discrètes, n'est pas caractéristique des variables à densité.
Toutefois, cette dernière propriété, qui oppose les variables à densité aux variables discrètes, n'est pas caractéristique des variables à densité.
Il existe d'autres types de variables aléatoires réelles :
- la loi d'une variable aléatoire peut très bien n'être ni discrète ni absolument continue. Elle peut, par exemple, être un mélange des deux : si la loi de la durée de vie (avant panne) d'un composant d'un certain type suit la loi exponentielle d'espérance 1 (an), et si par mesure de sécurité, on décide de remplacer chaque composant en cas de panne, mais aussi dès que le composant atteint l'age d'un an, même s'il n'est pas encore tombé en panne, alors la durée d'utilisation du composant (
 ) n'est ni discrète ni absolument continue. En effet les calculs de probabilités ou bien d'espérances liées à font alors intervenir des calculs d'intégrales et de sommes :
) n'est ni discrète ni absolument continue. En effet les calculs de probabilités ou bien d'espérances liées à font alors intervenir des calculs d'intégrales et de sommes :
- dans le cas précédent, la fonction de répartition de la durée d'utilisation est discontinue en 1. C'est une propriété générale : la fonction de répartition d'une variable aléatoire réelle est discontinue en
 si et seulement si
si et seulement si  On voit que les variables à densité ont des fonctions de répartitions localement absolument continues, donc, a fortiori, continues sur alors que les fonctions de répartition des variables discrètes et du mélange évoqué précédemment possèdent des discontinuités sur la droite réelle. Le tableau est encore compliqué par l'existence de variables aléatoires dont la fonction de répartition est continue sur mais pas absolument continue, et qui ne sont donc pas à densité. C'est le cas, par exemple, de
On voit que les variables à densité ont des fonctions de répartitions localement absolument continues, donc, a fortiori, continues sur alors que les fonctions de répartition des variables discrètes et du mélange évoqué précédemment possèdent des discontinuités sur la droite réelle. Le tableau est encore compliqué par l'existence de variables aléatoires dont la fonction de répartition est continue sur mais pas absolument continue, et qui ne sont donc pas à densité. C'est le cas, par exemple, de

- où les
 désignent une suite de variables de Bernoulli indépendantes de paramètre 0,5. est un nombre dont on tire le développement triadique à pile ou face : à chaque pile on ajoute le chiffre 2, et à chaque face le chiffre 0, excluant ainsi le chiffre 1. La fonction de répartition de est l'escalier de Cantor. Une telle variable doit-elle être appelée continue (sa fonction de répartition l'est), ou pas (elle n'a pas de densité de probabilité) ? Le débat n'est pas très aigu, car ce type de variables apparait rarement dans les applications.
désignent une suite de variables de Bernoulli indépendantes de paramètre 0,5. est un nombre dont on tire le développement triadique à pile ou face : à chaque pile on ajoute le chiffre 2, et à chaque face le chiffre 0, excluant ainsi le chiffre 1. La fonction de répartition de est l'escalier de Cantor. Une telle variable doit-elle être appelée continue (sa fonction de répartition l'est), ou pas (elle n'a pas de densité de probabilité) ? Le débat n'est pas très aigu, car ce type de variables apparait rarement dans les applications.
Histoire
L'allure générale des lois de probabilité usuelles fut au début observée empiriquement, puis on en formalisa la définition dans le cadre de la théorie des probabilités en mathématiques.
Maximum d'entropie
Les lois de probabilité usuelles sont souvent classées par familles dépendant d'un paramètre. La loi normale par exemple est paramétrée par sa moyenne et son écart type. La plupart des familles usuelles de lois de probabilités sont celles offrant le maximum d'entropie (l'entropie est une mesure de l'information moyenne d'une source, au sens de Claude Shannon, donc le plus d'information) sous contraintes, par exemple :
- La distribution uniforme est celle d'entropie maximale parmi les lois à support borné.
- La distribution normale est celle d'entropie maximale parmi toutes les lois possibles ayant même moyenne et même écart type.
- La distribution exponentielle est celle d'entropie maximale parmi les lois portées par
 et ayant la même moyenne.
et ayant la même moyenne. - Les lois scalantes comme celle de Zipf ou de Mandelbrot sont d'entropie maximale parmi celles auxquelles on impose la valeur du logarithme d'une moyenne, c'est-à-dire un ordre de grandeur.
En quelque sorte, ces lois ne contiennent pas plus d'information que ce qui est obligatoire. Ce sont les moins prévenues de toutes les lois compatibles avec les observations ou les contraintes, et donc les seules admissibles objectivement comme distributions de probabilités a priori lorsque ces valeurs sont imposées et seules connues. Cette propriété joue un grand rôle dans les méthodes bayésiennes.
Voir aussi
Exemples de distribution
- Distribution de Gauss
- Distribution de Poisson
- Distribution de Lévy
- Distribution de Lévy tronquée
- Distribution de Dirac
- Distribution de Gumbel
- Distribution de Boltzmann
- Distribution de Bose-Einstein
- Distribution de Weibull
- Distribution de Dirichlet
- Distribution de Pareto
- Distribution Zeta
Références
- B.S. Everitt. 2006. The Cambridge Dictionary of Statistics, Third Edition. pp. 313–314. Cambridge University Press, Cambridge. ISBN 0-521-69027-7
Liens connexes
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques












![f_X (x) = \left\{\begin{matrix} \frac{1}{b-a}& \mathrm{si}\ x \in [a;b] \\ 0& \mathrm{sinon} \end{matrix}\right.](a/66a0d2505018eaef9eec431be7216c17.png)














![\mathbb{E}\left[\phi(X)\right]\ = \mathbb{E}\left[\phi(Y)\right]](d/63d69abfd17934b604d4802ad50a36df.png)
![\mathbb{E}\left[\phi(X)\right] = \int_\R~\phi(x)~\mathbb{P}_X(dx),](4/7f4da5639f83f625f7753536d35f1539.png)

![\forall t\in\mathbb{R},\qquad\mathbb{E}\left[e^{itX}\right]\ = \mathbb{E}\left[e^{itY}\right].](7/f17bd6b58277336f948a8975bfb13df0.png)
![\forall \lambda>0,\qquad\mathbb{E}\left[e^{-\lambda X}\right]\ = \mathbb{E}\left[e^{-\lambda Y}\right].](2/6821ca54feafb53ded646fa581e3b341.png)
![\forall s\in\mathbb{R},\qquad\mathbb{E}\left[s^{X}\right]\ = \mathbb{E}\left[s^{Y}\right].](0/000fa9ff5c212c80f26a4243ed2532fb.png)
![\mathbb{P}\left(X\in A\right)=e^{-1}1_A(1)+\int_{A}\ e^{-x}\,1_{[0,1]}(x)\,dx,\qquad\mathbb{E}\left[\phi(X)\right]=e^{-1}\phi(1)+\int_{0}^1\ \phi(x)\ e^{-x}\,dx.](e/fee9bc7ef9e73d1e9c5851f392563420.png)
Wikimedia Foundation. 2010.