- Inference bayesienne
-
Inférence bayésienne
On nomme inférence bayésienne la démarche logique permettant de calculer ou réviser la probabilité d'une hypothèse. Cette démarche est régie par l'utilisation de règles strictes de combinaison des probabilités, desquelles dérive le théorème de Bayes. Dans la perspective bayésienne, une probabilité n'est pas interprétée comme le passage à la limite d'une fréquence, mais plutôt comme la traduction numérique d'un état de connaissance (le degré de confiance accordé à une hypothèse, par exemple ; voir théorème de Cox-Jaynes).
Jaynes utilisait à ce sujet avec ses étudiants la métaphore d'un robot à logique inductive. On trouvera un lien vers un de ses écrits dans l'article Intelligence artificielle.
Sommaire
La manipulation des probabilités : notation et règles logiques
L'inférence bayésienne est fondée sur la manipulation d'énoncés probabilistes. Ces énoncés doivent être clairs et concis afin d'éviter toute confusion. L'inférence bayésienne est particulièrement utile dans les problèmes d'induction. Les méthodes bayésiennes se distinguent des méthodes dites standard par l'application systématique de règles formelles de transformation des probabilités. Avant de passer à la description de ces règles, familiarisons-nous avec la notation employée.
Notation des probabilités
Prenons l'exemple d'une femme cherchant à savoir si elle est enceinte. On définira d'abord une hypothèse E : elle est enceinte, dont on cherche la probabilité p(E). Le calcul de cette probabilité passe évidemment par l'analyse du test de grossesse. Supposons que des études aient démontré que pour des femmes enceintes, le test indique positif 9 fois sur 10. Pour les femmes non-enceintes, le test indique négatif dans un ratio de 19/20. Si l'on définit les hypothèses :
- TP : le test est positif,
- TN : le test est négatif,
on peut interpréter les résultats précédents de manière probabiliste :
La probabilité de l'hypothèse TP sachant que la femme est enceinte est de 0,9.
En langage des probabilités, cet énoncé sera décrit par l'expression p(TP | E) = 0,9. De la même manière
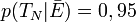 signifie que la probabilité que le test soit négatif pour une femme qui n'est pas enceinte (
signifie que la probabilité que le test soit négatif pour une femme qui n'est pas enceinte (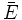 ) est de 0,95. Remarquez que l'on suit ici la convention selon laquelle un énoncé ou une hypothèse certainement vraie a une probabilité de 1. Inversement, un énoncé certainement faux a une probabilité de 0.
) est de 0,95. Remarquez que l'on suit ici la convention selon laquelle un énoncé ou une hypothèse certainement vraie a une probabilité de 1. Inversement, un énoncé certainement faux a une probabilité de 0.En plus de l'opérateur conditionnel |, les opérateurs logiques ET et OU ont leur notation particulière. Ainsi, la probabilité simultanée de deux hypothèses est notée par le signe
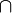 . L'expression
. L'expression 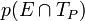 décrit donc la probabilité d'être enceinte ET d'obtenir un test positif. Enfin, pour l'opérateur logique OU, un signe
décrit donc la probabilité d'être enceinte ET d'obtenir un test positif. Enfin, pour l'opérateur logique OU, un signe 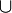 est généralement utilisé. L'expression
est généralement utilisé. L'expression 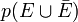 signifie donc la probabilité que la femme soit enceinte ou non. Clairement, selon la convention précédente, cette probabilité doit être de 1, puisque qu'il est impossible d'être dans un état autre qu'enceinte ou pas enceinte.
signifie donc la probabilité que la femme soit enceinte ou non. Clairement, selon la convention précédente, cette probabilité doit être de 1, puisque qu'il est impossible d'être dans un état autre qu'enceinte ou pas enceinte.Les règles de la logique des probabilités
Il existe seulement deux règles pour combiner les probabilités, et à partir desquelles est bâtie toute la théorie de l'analyse bayésienne. Ces règles sont les règles d'addition et de multiplication.
La règle d'addition
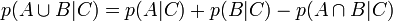
La règle de multiplication
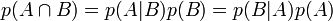
Le théorème de Bayes peut être dérivé simplement en mettant à profit la symétrie de la règle de multiplication
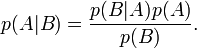
Le théorème de Bayes permet d'inverser les probabilités. C'est-à-dire que si l'on connaît les conséquences d'une cause, l'observation des effets permet de remonter aux causes.
Dans le cas précédent de la femme enceinte, sachant le résultat du test, il est possible de calculer la probabilité que la femme soit enceinte en utilisant le théorème de Bayes. En effet, dans le cas d'un test positif,
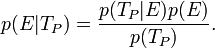 Remarquez que l'inversion de la probabilité introduit le terme p(E), la probabilité a priori d'être enceinte, souvent appelé le prior. Le prior décrit la probabilité de l'hypothèse, indépendamment du résultat du test. Une femme qui utilise des moyens de contraception choisirait un p(E) très faible, puisqu'elle n'a pas de raison de croire qu'elle est enceinte. Par contre, une femme ayant eue récemment des relations sexuelles non-protégées et souffrant de vomissements fréquents adopterait un prior plus élevé. Le résultat du test est donc pesé, ou nuancé, par cette estimation indépendante de la probabilité d'être enceinte.
Remarquez que l'inversion de la probabilité introduit le terme p(E), la probabilité a priori d'être enceinte, souvent appelé le prior. Le prior décrit la probabilité de l'hypothèse, indépendamment du résultat du test. Une femme qui utilise des moyens de contraception choisirait un p(E) très faible, puisqu'elle n'a pas de raison de croire qu'elle est enceinte. Par contre, une femme ayant eue récemment des relations sexuelles non-protégées et souffrant de vomissements fréquents adopterait un prior plus élevé. Le résultat du test est donc pesé, ou nuancé, par cette estimation indépendante de la probabilité d'être enceinte.- C'est cette estimation a priori qui est systématiquement ignorée par les méthodes statistiques standard.
Notation d'évidence
Cette notation est souvent attribuée à I. J. Good. Ce dernier en attribuait cependant la paternité à Alan Turing et, indépendamment, à d'autres chercheurs dont Jeffreys.
Dans la pratique, quand une probabilité est très proche de 0 ou de 1, il faut observer des éléments considérés eux-mêmes comme très improbables pour la voir se modifier. On définit l'évidence par :
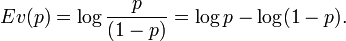 Pour mieux fixer les choses, on travaille souvent en décibels (dB), avec l'équivalence suivante :
Pour mieux fixer les choses, on travaille souvent en décibels (dB), avec l'équivalence suivante : 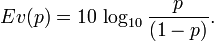 Une évidence de -40 dB correspond à une probabilité de 10-4, etc. Si on prend le logarithme en base 2,
Une évidence de -40 dB correspond à une probabilité de 10-4, etc. Si on prend le logarithme en base 2, 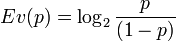 , l'évidence est exprimée en bits. On a
, l'évidence est exprimée en bits. On a 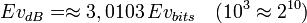 . L'intérêt de cette notation, outre qu'elle évite de cette manière d'avoir trop de décimales au voisinage de 0 et de 1, est qu'elle permet aussi de présenter la règle de Bayes sous forme additive : il faut le même poids de témoignage (weight of evidence) pour faire passer un évènement d'une plausibilité de -40 dB (10-4) à -30 dB (10-3) que pour le faire passer de -10 dB (0,1) à 0 dB (0,5), ce qui n'était pas évident en gardant la représentation en probabilités. La table suivante présente quelques équivalences :
. L'intérêt de cette notation, outre qu'elle évite de cette manière d'avoir trop de décimales au voisinage de 0 et de 1, est qu'elle permet aussi de présenter la règle de Bayes sous forme additive : il faut le même poids de témoignage (weight of evidence) pour faire passer un évènement d'une plausibilité de -40 dB (10-4) à -30 dB (10-3) que pour le faire passer de -10 dB (0,1) à 0 dB (0,5), ce qui n'était pas évident en gardant la représentation en probabilités. La table suivante présente quelques équivalences :Table d'équivalence Probabilité Évidence (dB) Évidence (bits) 0,0001 -40,0 -13,3 0.0010 -30,0 -10,0 0,0100 -20,0 -6,6 0,1000 -9,5 -3,2 0,2000 -6,0 -2,0 0,3000 -3,7 -1,2 0,4000 -1,8 -0,6 0,5000 0,0 0,0 0,6000 1,8 0,6 0,7000 3,7 1,2 0,8000 6.0 2.0 0,9000 9,5 3,2 0,9900 20,0 6,6 0,9990 30,0 10,0 0,9999 40,0 13,3 Ev est une abréviation pour weight of evidence, parfois traduit en français par le mot évidence ; la formulation la plus conforme à l'expression anglaise d'origine serait le mot à mot poids de témoignage, mais par une coïncidence amusante « évidence » se montre très approprié en français pour cet usage précis.
C'est peu après les publications de Jeffreys qu'on découvrit qu'Alan Turing avait déjà travaillé sur cette question en nommant les quantités correspondantes log-odds dans ses travaux personnels.
Comparaison avec la statistique classique
Différence d'esprit
Une différence entre l'inférence bayésienne et les statistiques classiques, dites aussi fréquentistes, indiquée par Myron Tribus, est que
- les méthodes bayésiennes utilisent des méthodes impersonnelles pour mettre à jour des probabilités personnelles, dites aussi subjectives (une probabilité est en fait toujours subjective, lorsqu'on analyse ses fondements),
- les méthodes statistiques utilisent des méthodes personnelles pour traiter des fréquences impersonnelles.
Les bayésiens font donc le choix de modéliser leurs attentes en début de processus (quitte à réviser ce premier jugement à l'aune de l'expérience au fur et à mesure des observations), tandis que les statisticiens classiques se fixaient a priori une méthode et une hypothèse arbitraires et ne traitaient les données qu'ensuite (ce qui avait tout de même le mérite de bien alléger les calculs).
Les méthodes bayésiennes, parce qu'elles n'exigeaient pas qu'on se fixe d'hypothèse préalable, ont ouvert la voie au data mining automatique; il n'y a en effet plus lieu avec elles d'avoir recours à une intuition humaine préalable pour imaginer des hypothèses avant de pouvoir commencer à travailler.
Quand utiliser l'une ou l'autre ?
Les deux approches se complètent, la statistique étant en général préférable lorsque les informations sont abondantes et d'un faible coût de collecte, la bayésienne dans le cas où elles sont rares et/ou onéreuses à rassembler. En cas de grande abondance de données, les résultats sont asymptotiquement les mêmes dans chaque méthode, la bayésienne étant simplement plus coûteuse en calcul. En revanche, la bayésienne permet de traiter des cas où la statistique ne disposerait pas suffisamment de données pour qu'on puisse en appliquer les théorèmes limites.
Le psi-test bayésien (qui est utilisé pour déterminer la plausibilité d'une distribution par rapport à des observations) est asymptotiquement convergent avec le χ² des statistiques classiques à mesure que le nombre d'observations devient grand. Le choix apparemment arbitraire d'une distance euclidienne dans le χ² est ainsi parfaitement justifié a posteriori par le raisonnement bayésien (source : Myron Tribus, op. cit.)
Exemples d'inférence bayésienne : d'où vient ce biscuit ?
Imaginons deux boîtes de biscuits.
- L'une, A, comporte 30 biscuits au chocolat et 10 ordinaires.
- L'autre, B, en comporte 20 de chaque sorte.
On choisit les yeux fermés une boîte au hasard, puis dans cette boîte un biscuit au hasard. Il se trouve être au chocolat. De quelle boîte a-t-il le plus de chances d'être issu, et avec quelle probabilité ? Intuitivement, on se doute que la boîte A a plus de chances d'être la bonne, mais de combien ?
La réponse exacte est donnée par le théorème de Bayes :
Notons HA la proposition « le gâteau vient de la boîte A » et HB la proposition « le gâteau vient de la boîte B ».
Si lorsqu'on a les yeux bandés les boîtes ne se distinguent que par leur nom, nous avons P(HA) = P(HB), et la somme fait 1, puisque nous avons bien choisi une boîte, soit une probabilité de 0,5 pour chaque proposition.
Notons D l'événement désigné par la phrase « le gâteau est au chocolat ». Connaissant le contenu des boîtes, nous savons que :
- P(D | HA) = 30/40 = 0,75 (évidence 4,77 dB, soit 1,44 bit)
- P(D | HB) = 20/40 = 0,5 (évidence 0 dB, soit 0 bit)
Note: « P(A | B) » se dit « la probabilité de A sachant B ».
Résolution
La formule de Bayes nous donne donc :
P(HA|D) représente la probabilité d'avoir choisi la boîte A sachant que le gâteau est au chocolat.
Avant de regarder le gâteau, notre probabilité d'avoir choisi la boîte A était P(HA), soit 0,5.Après l'avoir regardé, nous révisons cette probabilité à P(HA|D), qui est 0,6 (1,76 dB ou 0,53 bit).
L'observation nous a donc apporté 1,76 dB (0,53 bit).
Et puisque P(HA|D) + P(HB|D) = 1 (pas d'autre possibilité que d'avoir choisi la boîte A ou la boîte B sachant que le gâteau est au chocolat), la probabilité d'avoir choisi la boîte B sachant que le gâteau est au chocolat est donc de 1 - 0,6 = 0,4
Si nous imposons une probabilité a priori quelconque de suspecter une boîte particulière plutôt que l'autre, le même calcul effectué avec cette probabilité a priori fournit également 0,53 bit. C'est là une manifestation de la régle de cohérence qui constituait l'un des desiderata de Cox.
Références
Enseignement de l'outil
- Bernardo, J. and Smith, A.F.M. (1994) Bayesian Theory. John Wiley, New York (LA référence de l'approche formelle de la théorie bayésienne via les fonctions de perte et la théorie de la décision)
- Tribus, Myron (1974) Décisions rationnelles dans l'incertain, trad. de Jacques Pézier, Masson (épuisé, mais lisible à la Bibliothèque publique d'information)
- Robert, C.P. (1992) L'Analyse Statistique Bayésienne. Economica, Paris
- Documentation et programmes à télécharger
- Robert, C.P. (1994). The Bayesian Choice: A Decision Theoretic Motivation. New York: Springer Verlag (première édition, en français : L'Analyse Statistique Bayésienne, Paris: Economica, 1992, mais typographie moins soignée et donc lisibilité moins grande. Traduit en français en 2006 par Springer-Verlag, Paris)
- Jaynes, E.T. (2003) Probability Theory : The Logic of Science (en anglais).
Utilisation de l'outil
- David Bellot (2002) Inférence bayésienne en pratique
- Good, I.J. (1963) Speculations Concerning the First Ultraintelligent Machine (voir aussi Intelligence artificielle)
- Travaux de l'ERIS à l'Université de Rouen
- Myron Tribus (1974) Décisions rationnelles dans l'incertain (épuisé, mais librement consultable à la bibliothèque de Beaubourg, comportant beaucoup d'exemples et de programmes BASIC les résolvant de façon pratique)
Les ouvrages relatifs à l'utilisation sont plus rares pour la raison suivante : on utilise les méthodes bayésiennes là où l'information coûte cher à obtenir (prospection pétrolière, recherche de médicaments...). Ce sont dans les deux cas cités des sociétés privées (pétroliers, laboratoires pharmaceutiques...) qui les financent, et celles-ci n'ont pas vocation à donner à leurs concurrents des informations qui ont coûté cher à leurs actionnaires.
Cependant, des analyses bayéesiennes de problèmes concrets apparaissent dans la plupart des numéros des grands journaux de statistiques, comme Journal of the Royal Statistical Society, Journal of the American Statistical Association, Biometrika, Technometrics ou Statistics in Medicine.
Annexe historique
L'usage de probabilités a priori a entraîné quelques reproches récurrents aux méthodes bayésiennes lors de leur introduction. On devait alors rappeler systématiquement les quatre points suivants :
- L'effet de la distribution a priori s'estompe à mesure que les observations sont prises en compte
- Il existe des lois impersonnelles, comme la maximisation d'entropie ou l'invariance de groupe indiquant l'unique distribution possible sans ajouter d'information propre à l'expérimentateur.
- Les probabilités a priori sont souvent dans d'autres méthodes utilisées inconsciemment (critère de Wald, critère du minimax...)
- Comme pour tout autre modèle, les effets de différents choix a priori peuvent être considérés de front.
Ces méthodes sont aujourd'hui passées dans les mœurs.
Voir aussi
- Rasoir d'Occam
- Théorème de Bayes
- Plan d'expérience
- Data mining
- Intelligence artificielle
- Odds ratio
- Réseau bayésien
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Probabilités | Apprentissage automatique
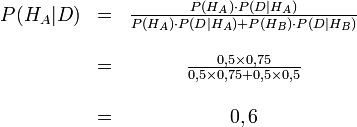
Wikimedia Foundation. 2010.