- Probabilité et statistique
-
Probabilité
La probabilité (du latin probabilitas) est une évaluation du caractère probable d'un évènement. En mathématiques, l'étude des probabilités est un sujet de grande importance donnant lieu à de nombreuses applications.
La probabilité d'un événement est un nombre réel compris entre 0 et 1. Plus ce nombre est grand, plus le risque (ou la chance, selon le point de vue) que l'événement se produise est grand. Si on considère que la probabilité qu'un lancer de pièce donne pile est égale à 1/2, cela signifie que, si on lance un très grand nombre de fois cette pièce, la fréquence des piles va tendre vers 1/2, sans préjuger de la régularité de leur répartition. Cette notion empirique sera définie plus rigoureusement dans le corps de cet article.
Contrairement à ce que l'on pourrait penser de prime abord l'étude scientifique des probabilités est relativement récente dans l'histoire des mathématiques. D'autres domaines tels que la géométrie, l'arithmétique, l'algèbre ou l'astronomie faisaient l'objet d'étude mathématique durant l'Antiquité mais on ne trouve pas de trace de textes mathématiques sur les probabilités. L'étude des probabilités a connu de nombreux développements au cours des trois derniers siècles en partie grâce à l'étude de l'aspect aléatoire et en partie imprévisible de certains phénomènes, en particulier les jeux de hasard. Ceux-ci ont conduit les mathématiciens à développer une théorie qui a ensuite eu des implications dans des domaines aussi variés que la météorologie, la finance ou la chimie. Cet article est une approche simplifiée des concepts et résultats d'importance en probabilité ainsi qu'un historique de l'usage du terme "probabilité" qui a eu de nombreux autres sens avant celui qu'on lui connait aujourd'hui.
Sommaire
Histoire
A l'origine, dans les traductions d'Aristote, le mot "probabilité" ne désigne pas une quantification du caractère aléatoire d'un fait mais l'idée qu'une idée est communément admise par tous. Ce n'est que au cours du Moyen Âge puis de la Renaissance autour des commentaires successifs et des imprécisions de traduction de l'œuvre d'Aristote que ce terme connaitra un glissement sémantique pour finir par désigner la vraisemblance d'une idée. Au XVIe siècle puis au XVIIe siècle c'est ce sens qui prévaut en particulier dans le probabilisme en théologie morale. Il faudra attendre le milieu du XVIIe siècle pour que ce mot prenne son sens actuel avec le début du traitement mathématique du sujet par Blaise Pascal et Pierre de Fermat. Ce n'est alors qu'au XIXe siècle qu'apparait ce qui peut être considéré comme la théorie moderne des probabilités en mathématiques.
La notion de probabilité chez Aristote
Le premier usage du mot probabilité apparait en 1370 avec la traduction de l'éthique à Nicomaque d'Aristote par Oresme et désigne alors « le caractère de ce qui est probable »[1]. Le concept de probable chez Aristote (ενδοξον, en grec) est ainsi défini dans les Topiques[2]:
"Sont probables les opinions qui sont reçues par tous les hommes, ou par la plupart d’entre eux, ou par les sages, et parmi ces derniers, soit par tous, soit par la plupart, soit enfin par les plus notables et les plus illustres"
Ce qui rend une opinion probable chez Aristote est son caractère généralement admis [3]; ce n'est qu'avec la traduction de Cicéron des Topiques d'Aristote, qui traduit par probabilis ou par verisimilis, que la notion de vraisemblance est associée à celle de "probabilité" ce qui aura un impact au cours du Moyen Âge puis de la Renaissance avec les commentaires successifs de l'œuvre d'Aristote.[4]
La doctrine de la probabilité au XVIe siècle et XVIIe siècle
La doctrine de la probabilité, autrement appelée probabilisme, est une théologie morale catholique qui s'est développée au cours du XVIe siècle sous l'influence entre autres de Bartolomé de Medina et des jésuites. Avec l'apparition de la doctrine de la probabilité, ce terme connaîtra un glissement sémantique pour finir par désigner au milieu du XVIIe siècle le caractère vraisemblable d'une idée.
Cette théologie morale considère que "si une opinion est probable, il est permis de la suivre, quand bien même est plus probable l’opinion opposée" selon la formulation de Bartolomé de Medina en 1527. Cette théologie morale cherche alors à définir quelle action entreprendre quand il existe un doute sur la meilleure action à entreprendre. Cette théologie morale a été très critiquée à partir du milieu du XVIIe siècle[5] comme introduisant le relativisme moral, en particulier par les jansénistes et par Blaise Pascal, qui sera l'un des fondateurs du traitement mathématique des probabilités[6].
La probabilité d'une opinion désigne alors au milieu du XVIIe siècle la probabilité qu'une opinion soit vraie. Ce n'est qu'à partir de la fin du XVIIe siècle avec l'émergence de la probabilité mathématique que la notion de probabilité ne concernera plus seulement les opinions et les idées mais aussi les faits et se rapprochera de la notion de hasard que l'on connaît aujourd'hui [2].
La notion moderne de probabilité
L'apparition de la notion de "risque", préalable à l'étude des probabilités, n'est apparue qu'au XIIe siècle pour l'évaluation de contrats commerciaux avec le Traité des contrats de Pierre de Jean Olivi, [7] et s'est développée au XVIe siècle avec la généralisation des contrats d'assurance maritime[8]. À part quelques considérations élémentaires par Gerolamo Cardano [9]au début du XVIe siècle et par Galilée au début du XVIIe siècle, le véritable début de la théorie des probabilités date de la correspondance entre Pierre de Fermat et Blaise Pascal en 1654.
Ce n'est qu'à partir du milieu du XVIIe siècle avec l'émergence du traitement mathématique du sujet qu'est apparu l'usage moderne du terme probabilité. [2]
Les probabilités du XVIIe au XIXe siècle
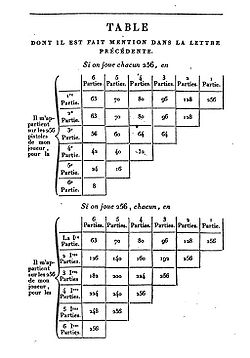 Une page de la correspondance entre Pascal et Fermat, 1654 [10]
Une page de la correspondance entre Pascal et Fermat, 1654 [10]
Le véritable début de la théorie des probabilités date de la correspondance entre Pierre de Fermat et Blaise Pascal en 1654. Ceux-ci commencent à élaborer les bases du traitement mathématique des probabilités autour de l'étude de jeux de hasard proposés, entre autres, par le chevalier de Méré. (voir ci-contre une page de la correspondance entre Pascal et Fermat). Même s'ils sont considérés comme les fondateurs du traitement des probabilités, ils n'ont rien publié de leurs travaux, et il faudra attendre Huygens pour avoir un premier ouvrage sur le sujet.
Encouragé par Pascal, Christiaan Huygens publie De ratiociniis in ludo aleae (raisonnements sur les jeux de dés) en 1657. Ce livre est le premier ouvrage important sur les probabilités. Il y définit la notion d'espérance et y développe plusieurs problèmes de partages de gains lors de jeux ou de tirages dans des urnes.[11] Deux ouvrages fondateurs sont également à noter : Ars Conjectandi de Jacques Bernoulli (posthume, 1713) qui définit la notion de variable aléatoire et donne la première version de la loi des grands nombres[12], et Théorie de la probabilité d' Abraham de Moivre (1718) qui généralise l'usage de la combinatoire.[13]
La Théorie des erreurs, qui cherche à quantifier l'écart entre la mesure que l'on fait d'une variable et sa vraie valeur et qui est une préfiguration des théorèmes central limite, voit le jour avec Opera Miscellanea de Roger Cotes (posthume, 1722). Le premier à l'appliquer aux erreurs sur les observations est Thomas Simpson en 1755.
Pierre-Simon Laplace donne une première version du théorème central limite en 1812 qui ne s'applique alors que pour une variable à deux états, par exemple pile ou face mais pas un dé a 6 faces.
Sous l'impulsion de Quételet, qui ouvre en 1841 le premier bureau statistique le Conseil Supérieur de Statistique [14], les statistiques se développent et deviennent un domaine à part entière des mathématiques qui s'appuie sur les probabilités mais n'en font plus partie.
Naissance de la théorie classique des probabilités
La théorie de la probabilité classique ne prend réellement son essor qu'avec les notions de mesure et d'ensembles mesurables qu'Emile Borel introduit en 1897. Cette notion de mesure est complétée par Henri Léon Lebesgue et sa théorie de l'intégration[15]. La première version moderne du théorème de la limite centrale est donné par Alexandre Liapounov en 1901[16] et la première preuve du théorème moderne est donnée par Paul Lévy en 1910. En 1902, Andrei Markov introduit les chaînes de Markov[17] pour entreprendre une généralisation de la loi des grands nombres pour une suite d'expériences dépendant les unes des autres. Ces chaînes de Markov connaîtront de nombreuses applications entre autres pour modéliser la diffusion ou pour l'indexation de sites internet sur google.
Il faudra attendre 1933 pour que la théorie des probabilités sorte d'un ensemble de méthodes et d'exemples divers et devienne une véritable théorie, axiomatisée par Kolmogorov[18].
Kiyoshi Itô met en place une théorie et un lemme qui porte son nom dans les années 1940[19]. Ceux-ci permettent de relier le calcul stochastique et les équations aux dérivées partielles faisant ainsi le lien entre analyse et probabilités. Le mathématicien Wolfgang Doeblin avait de son côté ébauché une théorie similaire avant de se suicider à la défaite de son bataillon en juin 1940. Ses travaux furent envoyés à l'Académie des sciences dans un pli cacheté qui ne fut ouvert qu'en 2000[20].
Applications
Les jeux de hasard sont l'application la plus naturelle des probabilités mais de nombreux autres domaines s'appuient ou se servent des probabilités. Citons entre autres:
- les statistiques, sont un vaste domaine qui s'appuie sur les probabilités pour le traitement et l'interprétation des données.
- La théorie des jeux s'appuie fortement sur la probabilité et est utile en économie et plus précisément en micro-économie.
- l'estimation optimale par usage de la loi de Bayes, qui sert de fondement à une grande partie des applications de décision automatique (imagerie médicale, astronomie, reconnaissance de caractères, filtres anti-pourriel).
- En physique ainsi qu'en biologie moléculaire l'étude du mouvement brownien pour de petites particules ainsi que les Équation de Fokker-Planck font intervenir des concepts s'appuyant sur le calcul stochastique et la marche aléatoire
- les mathématiques financières font un large usage de la théorie des probabilités pour l'étude des cours de la bourse et des produits dérivés. Citons par exemple le Modèle de Black-Scholes pour déterminer le prix de certains actifs financiers (notamment les options).
- les Etudes Probabilistes de Sûreté où l'on évalue la probabilité d'occurrence d'un événement indésirable. C'est devenu un outil d'évaluation des risques dans bon nombre d'installations industrielles.
Principes fondamentaux
La probabilité d'un certain évènement A,
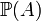 , est représenté par un nombre compris entre 0 et 1. Un évènement en probabilité peut être à peu près n'importe quoi pouvant se produire ou non. L'évènement A peut par exemple être le fait qu'il fasse beau demain, le fait d'obtenir un 6 avec un dé, voire même le fait que le théorème de Pythagore soit vrai. Le seul impératif que l'on se fixe c'est de pouvoir vérifier si cet évènement se vérifie ou pas. On peut par exemple vérifier s'il fera beau demain, si on obtient un 6 ou si le théorème de Pythagore est vrai.
, est représenté par un nombre compris entre 0 et 1. Un évènement en probabilité peut être à peu près n'importe quoi pouvant se produire ou non. L'évènement A peut par exemple être le fait qu'il fasse beau demain, le fait d'obtenir un 6 avec un dé, voire même le fait que le théorème de Pythagore soit vrai. Le seul impératif que l'on se fixe c'est de pouvoir vérifier si cet évènement se vérifie ou pas. On peut par exemple vérifier s'il fera beau demain, si on obtient un 6 ou si le théorème de Pythagore est vrai.Un évènement impossible a une probabilité de 0 et un évènement certain a une probabilité de 1. Il faut savoir que le contraire n'est pas forcément vrai. Un évènement qui a une probabilité 0 peut très bien se produire dans le cas où un nombre infini d'évènements différents peut se produire. Ceci est détaillé dans l'article Ensemble négligeable et un exemple d'évènement de probabilité 0 et pouvant se produire est (rapidement) esquissé dans la partie loi des grands nombres. De même un évènement de probabilité 1 peut "exceptionnellement" ne pas se produire.
Probabilité et Réalité
Même si l'essence de la probabilité est la prédiction d'évènements du monde réel, la probabilité, n'étant qu'une théorie, ne peut pas nous renseigner sur la réalité. Comme dirait René Thom, prédire n'est pas expliquer...
Dans les faits, la probabilité s'occupe d'ensembles et de la mesure de ces ensembles. Dans un ensemble Oméga des possibles la probabilité du sous-ensemble A est sa mesure divisée par celle de Oméga. Pour l'exemple du dé ci-dessus, on a créé un ensemble Oméga ={1,2,3,4,5,6} de mesure 6, et avec A ={6}, la probabilité de A est 1/6. Le fait de créer ces objets mathématiques et de les relier à la réalité s'appelle modéliser, et toutes les vérités que l'on produit ne sont vraies qu'à l'intérieur du modèle. Seule l'expérimentation s'intéresse au lien entre la réalité et le modèle (les vérités mathématiques restent confinées au sein du modèle).
Ainsi, même si des pléthores d'expérimentations valident ou non chaque jour des myriades de modèles, rigoureusement, on ne peut affirmer que la probabilité qu'une pièce jetée en l'air retombe sur pile soit 1/2. Tout au plus, on peut faire cette hypothèse de modélisation. Mais cette hypothèse peut avoir diverses conséquences selon, par exemple, que l'on accepte ou non l'existence de l'infini. (Bien sûr, on peut imaginer l'infini en mathématique, la question qui reste ouverte est : cet infini a-t-il une existence concrète ? et peut-on envisager des modèles dans lequel il n'intervient pas ?) Supposons qu'une pièce a la probabilité 1/2 de faire pile, et 1/2 de faire face. Supposons de plus que l'on vient d'assister à 10 lancer de cette pièce sur pile. Oméga est l'ensemble des lancer possibles de cette pièce et A est l'ensemble des lancer possibles donnant un face. On sait que la mesure de A divisée par celle de Oméga vaut 1/2. La probabilité de faire face, après avoir assisté aux 10 lancer de pile est alors la mesure de A divisée par : la mesure de Oméga moins la mesure de l'ensemble B correspondant aux 10 lancer ayant donné pile. La probabilité dépend du choix de la mesure, mais si l'on n'accepte pas l'hypothèse de l'existence réel de l'infini, la mesure qui s'impose dans un modèle est celle du dénombrement, on obtient alors que l'on a un peu plus de chance de faire un face qu'un pile si l'on vient d'assister à 10 réalisations de piles. (Cette probabilité est (M /2) / (M -10), où M est le nombre, que l'on ne connait pas, des lancer possibles de la pièce). Ce modèle, bien sûr, n'est pas utilisable en pratique, et on pense communément qu'il est possible de lancer un pièce une infinité de fois. ("Possible" étant à prendre au sens le plus large, c'est-à-dire ici cela pourrait donner qu'il est possible que la pièce survive à la destruction de la Terre et continue d'être lancée par des extra-terrestres...) Avec cette hypothèse commune, il s'ensuit que la mesure de B devient négligeable (car c'est 10 devant l'infini) et que l'on a autant de chance de faire un face qu'un pile, même si l'on vient d'assister à 10 réalisations de piles. (C'est l'indépendance des évènements traitée ci-dessous.)
Finalement, penser que l'on a autant de chance de faire un face qu'un pile, même si l'on vient d'assister à 10 réalisations de piles, est donc une croyance et n'a aucun caractère de vérité en dehors d'un modèle probabiliste. Par-ailleurs, c'est le bon sens communément partagé, en l'occurrence celui qui nous fait penser que des lancer de pièces sont indépendants, qui impulse la théorie et qui rend le concept mathématique de l'infini pertinent. Et non l'inverse : on ne peut donc pas démontrer que, dans la réalité, les lancer de pièces sont indépendants. Ce sont en fait les probabilités qui sont conçues pour coller à cette hypothèse.
En dehors de tout considération métaphysique, l'infini et le continu doivent être considérés comme des concepts utiles en pratique. Ils aident à obtenir des modèles simples et pertinent face à la réalité. Par-exemple, chaque jour les professionnels de la bourse utilise un modèle continu (le modèle Black-Scholes) alors que la réalité de la bourse appellerait une modélisation discrète mais trop compliquée, ou encore, en théorie des jeux certains modèles (de l'économie/sciences sociales), pour être suffisamment simples et réalistes, utilisent la notion de continuum de joueurs qui parait à première vue très loin de la réalité (au sein de laquelle le nombre de joueurs est fini). De même que pour modéliser notre lancer de pièce, l'infini est indispensable pour obtenir dans un cadre formel l'indépendance de deux lancer.
La notion d'indépendance
Article détaillé : Indépendance (probabilités).On dit que deux évènements sont indépendants lorsque le fait de connaitre le résultat du premier évènement ne nous aide pas pour prévoir le second et inversement. C'est le cas lorsque la réalisation d'un évènement n'influence pas la probabilité que l'autre se réalise.
Par exemple lorsque l'on lance deux dés à la suite le résultat obtenu au premier dé ne va pas influencer le deuxième dé. Le fait de connaître le résultat du premier dé ne nous aide en rien pour prévoir le résultat du deuxième. On a toujours une chance sur 6 d'obtenir un 6 au deuxième jet de dé quel que soit le résultat du premier dé. Ce n'est pas parce que l'on a obtenu un 6 au premier jet de dé que cela change la probabilité d'obtenir un 6 au deuxième. Souvent si on mène deux expériences séparément (par exemple lancer un dé) le résultat de la première expérience n'influe pas sur la deuxième et on a alors une indépendance des résultats de la première expérience par rapport à la deuxième.
Cette notion d'indépendance intervient dans de nombreux théorèmes par exemple dans la loi des grands nombres et le théorème central limite exposés plus bas. En terme mathématique, deux évènements A et B sont indépendants si et seulement s'ils vérifient
où
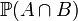 est la probabilité d'avoir à la fois A et B. On pourrait montrer grâce aux probabilités conditionnelles que cette définition recoupe bien l'idée que l'on se fait de l'indépendance.
est la probabilité d'avoir à la fois A et B. On pourrait montrer grâce aux probabilités conditionnelles que cette définition recoupe bien l'idée que l'on se fait de l'indépendance.On peut par exemple vérifier que la probabilité d'obtenir un 6 à un premier jet de dé est indépendante de celle d'obtenir un 6 à un deuxième lancer avec cette définition . La probabilité d'obtenir un 6 au premier dé vaut 1/6 (A), celle d'obtenir un 6 au deuxième dé vaut 1/6 (B). On peut grâce aux combinatoires montrer que la probabilité d'obtenir un double 6 vaut 1/36. On a alors:
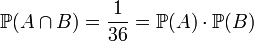
Le fait d'obtenir un 6 au premier dé est donc bien indépendant du fait d'obtenir un 6 au deuxième dé.
Variable aléatoire
Article détaillé : Variable aléatoire.Une notion importante en probabilité est celle de variable aléatoire.
Les variables aléatoires furent introduites à l'origine pour représenter un gain. Par exemple effectuons l'expérience suivante, lançons une pièce de monnaie et suivant que le résultat est pile nous gagnons dix euros, ou face nous perdons un euro. On considère alors X, la variable aléatoire qui prend la valeur 10 lorsque nous obtenons pile et la valeur -1 lorsque nous obtenons face. X représente le gain à l'issue d'un lancer de la pièce.
De façon plus générale une variable aléatoire est une certaine fonction, qui dépend du résultat d'une expérience aléatoire par exemple dans ce cas le résultat du pile ou face. Cette fonction associe une certaine valeur au résultat d'une expérience. Dans notre exemple plus haut la variable aléatoire associe 10 à "pile" et -1 à "face". Cela permet d'associer des nombres à des résultats d'expériences qui ne sont pas numériques.
Le terme de variable aléatoire peut parfois être trompeur, en effet, ce n'est pas la valeur qu'elle prend une fois que l'on connait le résultat de l'expérience qui est aléatoire, mais la valeur qu'elle va prendre avant d'avoir effectué l'expérience. Une fois que l'on connaît le résultat du pile ou face on connaît la valeur de X, notre gain, avec certitude et celle-ci ne dépend pas du hasard. Par contre, avant de jeter la pièce on ne sait pas quelle valeur va prendre X car on ne sait pas encore si l'on va obtenir pile ou face.
On ne considèrera ici que des variables aléatoires qui sont des nombres réels. De façon encore plus générale une variable aléatoire peut soit être un vecteur avec des coordonnées réelles soit un nombre réel. Il faut alors définir la loi jointe ainsi qu'une mesure sur un espace à plusieurs dimensions ce qui entraine des complications supplémentaires. Néanmoins pour des cas concrets on peut souvent se contenter de considérer plusieurs variables aléatoires qui dépendent de la même expérience. La restriction au cas de variables réelles n'est donc pas forcément aussi réducteur que l'on pourrait le penser.
Fonction de répartition et densité
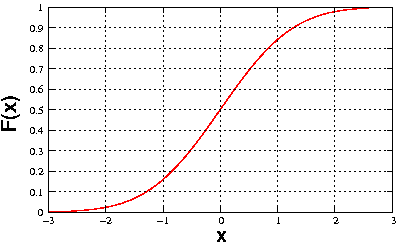
Article détaillé : Fonction de répartition.Article détaillé : Densité de probabilité.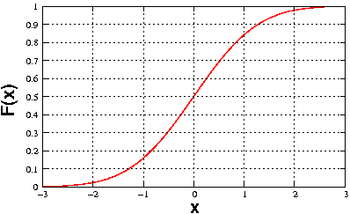 Fonction de répartition de la loi normale centrée réduite
Fonction de répartition de la loi normale centrée réduiteEn probabilité, la fonction de répartition d'une variable aléatoire X est la fonction
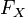 qui à tout réel x associe la probabilité que la variable X soit plus petite que x :
qui à tout réel x associe la probabilité que la variable X soit plus petite que x :C'est une fonction croissante, allant de 0 à 1.
Pour les variables dont la fonction de répartition est absolument continue, on définit alors la densité de probabilité, qui est la dérivée de F par rapport à x :
La connaissance de la densité de probabilité permet notamment, en intégrant, de calculer la probabilité que X soit, par exemple, compris entre a et b.
L'espérance
Article détaillé : Espérance mathématique.L'espérance est un nombre qui se confond souvent avec la moyenne d'une variable, voir à ce sujet la loi des grands nombres ou le prochain paragraphe. On la définit par:
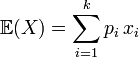 pour une variable avec un nombre fini de réalisations possibles.
pour une variable avec un nombre fini de réalisations possibles.- Par exemple, pour un dé à 6 faces, chaque face à une probabilité 1/6 d'apparaitre et l'espérance vaut alors
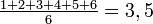 .
. 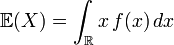 pour une variable continue de densité f.
pour une variable continue de densité f.
Deux théorèmes de base des probabilités
Deux théorèmes mathématiques ont une place particulière en probabilité. Ces deux théorèmes sont la loi des grands nombres et le théorème central limite et sont présentés ici succinctement pour en faire comprendre l'intérêt et l'usage.
Loi des grands nombres
Article détaillé : Loi des grands nombres.On ne présente ici que la loi forte des grands nombres mais il faut savoir que d'autre versions de lois des grands nombres existent.
Pour des variables aléatoires indépendantes, de même loi Xi et dont l'espérance existe:
Concrètement cette loi nous dit que la moyenne empirique d'une variable tend vers son espérance. Par exemple, pour un dé à 6 faces que l'on jetterait plusieurs fois de suite, la moyenne des lancers tend vers l'espérance 3,5.
Tendre vers est pris au sens presque sûrement, comme bien souvent en probabilité, c'est-à-dire que la probabilité que cela arrive est égale à 1. Comme esquissé dans les principes fondamentaux il peut très bien se faire que "exceptionnellement" cette moyenne ne tende pas vers l'espérance. On pourrait très bien, par exemple, ne tirer que des 1 lors des lancers de dés et que la moyenne soit alors 1 mais cela n'arrive "jamais". En général, si on lance des dés suffisamment de fois on tombera autant de fois sur chacune des 6 faces. Ce théorème formalise cette remarque de bon sens.
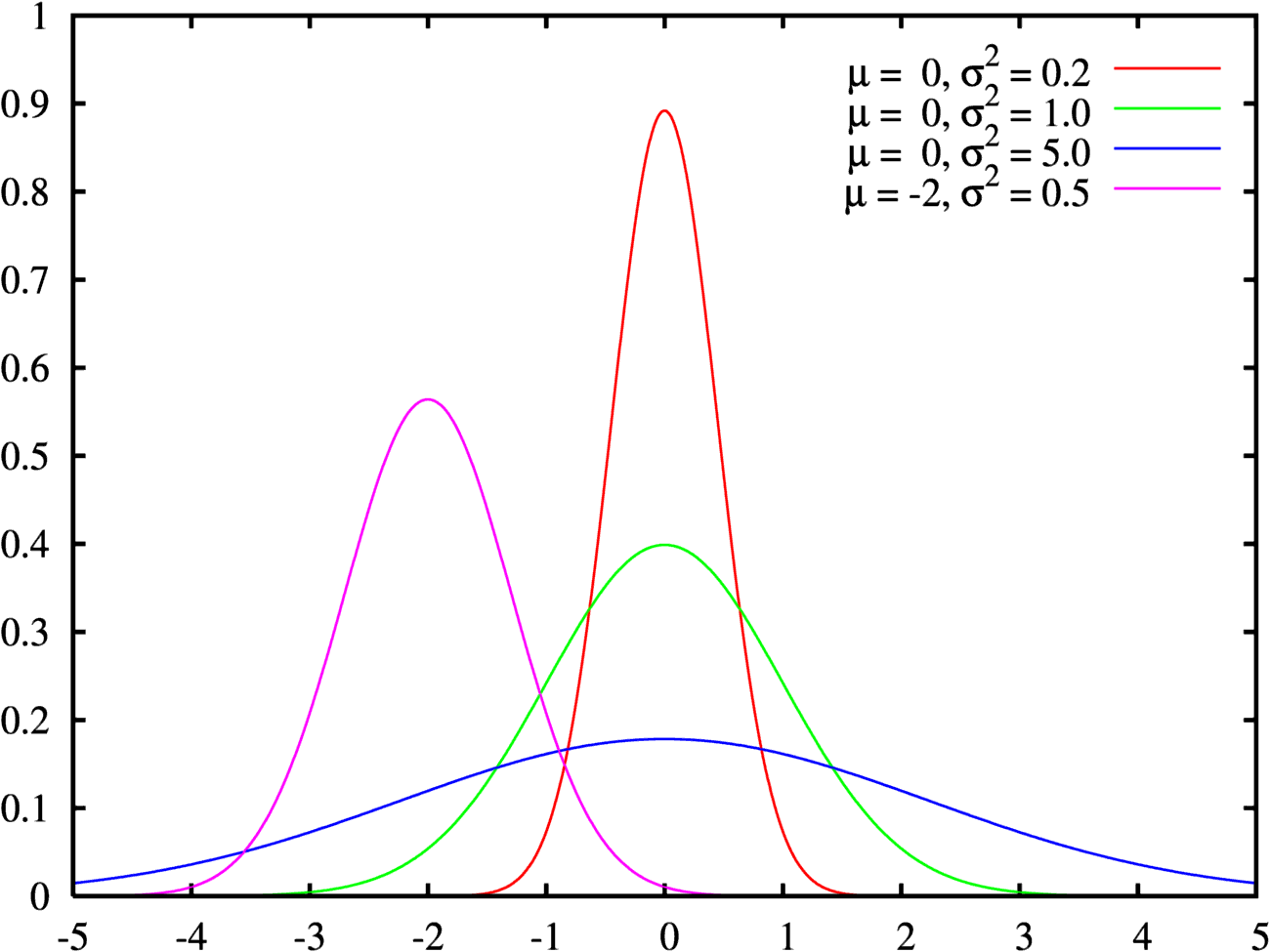
Théorème central limite
Article détaillé : théorème de la limite centrale.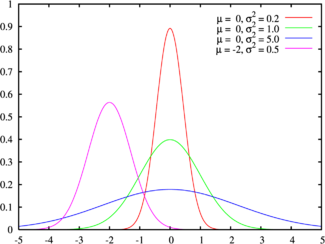
Ce théorème central limite est utile pour savoir comment une somme entre une réalisation d'une variable et la valeur moyenne se comporte. La loi des grands nombres montre que la moyenne des réalisations tend vers l'espérance. Quant au théorème central limite, il montre de quelle façon cette moyenne tend vers l'espérance. Une façon simple, mais pas très rigoureuse, d'écrire ce théorème permet de mieux comprendre son utilité:
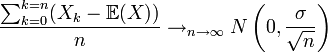
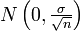 est la loi normale de variance
est la loi normale de variance 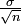 , autrement appelée gaussienne et représentée ci-contre. Ce théorème a une très grande utilité en physique par exemple. Il peut se comprendre par « La moyenne des erreurs observées tend vers une loi normale. » La somme d'un grand nombre d'erreurs sur des observations par exemple est presque gaussienne. Elle serait gaussienne si on sommait une infinité d'erreurs mais en pratique cela n'est pas souvent le cas. La loi gaussienne fournit alors une approximation pour la loi de l'erreur souvent plus facilement utilisable que la loi exacte qui n'est pas tout le temps connue. De plus bon nombre de phénomènes naturels sont dus à la superposition de causes nombreuses, plus ou moins indépendantes qui se somment entre elles. Il en résulte que la loi normale les représente de manière raisonnablement efficace.
, autrement appelée gaussienne et représentée ci-contre. Ce théorème a une très grande utilité en physique par exemple. Il peut se comprendre par « La moyenne des erreurs observées tend vers une loi normale. » La somme d'un grand nombre d'erreurs sur des observations par exemple est presque gaussienne. Elle serait gaussienne si on sommait une infinité d'erreurs mais en pratique cela n'est pas souvent le cas. La loi gaussienne fournit alors une approximation pour la loi de l'erreur souvent plus facilement utilisable que la loi exacte qui n'est pas tout le temps connue. De plus bon nombre de phénomènes naturels sont dus à la superposition de causes nombreuses, plus ou moins indépendantes qui se somment entre elles. Il en résulte que la loi normale les représente de manière raisonnablement efficace.Pour être plus correct, il faudrait écrire le théorème central limite de la façon suivante:
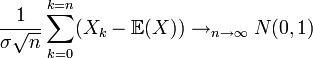
où la limite est prise au sens de tendre en loi, c'est-à-dire que la distribution de terme de gauche tend vers la distribution d'une gaussienne.
Il faut également savoir qu'il existe de nombreuses généralisations de ce théorème, entre autres pour des variables qui ne seraient pas identiquement distribuées (conditions de Liapounov ou conditions de Lindeberg [21]) ou pour des variables de variance infinie (due à Gnedenko et Kolmogorov[22])
Le calcul des probabilités
Il existe deux façons de calculer les probabilités en mathématiques: le calcul a priori et le calcul a posteriori.
La première méthode, aussi appelée probabilité mathématique, part d'un calcul mathématique pour obtenir les probabilités. C'est le cas en particulier de la combinatoire, mais également des caractérisations de la loi exponentielle ou de la modélisation par une loi normale grâce à l'usage du théorème central limite. Ces méthodes ont en commun le fait qu'aucune expérience ne soit nécessaire pour déterminer les probabilités qui sont déterminées a priori.
La deuxième méthode est le calcul a posteriori, autrement appelé probabilité statistique, ces méthodes partent des résultats d'expériences pour déduire les probabilités. C'est le cas par exemple pour l'utilisation de la fréquence comme estimateur de la probabilité, du maximum de vraisemblance ou de l'Inférence bayésienne. Ces méthodes ont en commun le fait qu'une expérience soit nécessaire pour déterminer les probabilités qui sont déterminées a posteriori.
Nous présentons ici les principales méthodes permettant le calcul des probabilités.
L'usage de la combinatoire en probabilité
Article détaillé : Combinatoire.Certains problèmes de calcul de probabilité peuvent se ramener à un calcul de dénombrement, en particulier ceux pour lesquels il y a un nombre fini d'issues possibles à l'expérience et où la probabilité de chaque issue est la même. Cette méthode consiste à compter (dénombrer) le nombre total de cas possibles et le nombre de cas favorables à la réalisation d'un évènement.
Cette méthode permet par exemple de calculer la probabilité d'obtenir un 6 avec un dé équitable ou la probabilité d'obtenir un nombre pair, elle ne permet pas de calculer les probabilités avec un dé biaisé par exemple car alors la probabilité d'obtenir chaque face n'est plus la même. Cette méthode ne permet pas non plus de calculer la probabilité lorsqu'il y a un nombre infini de résultats possibles à l'expérience.
Estimateurs statistiques
Article détaillé : Estimateur (statistique).Les estimateurs statistiques sont des valeurs calculées à partir d'un échantillon de la population totale ou d'un certain nombre de résultats de l'expérience aléatoires. Ces estimateurs sont souvent construits sur le principe du maximum de vraisemblance qui permet de construire tout une série d'estimateurs.
Parmi ceux ci l'estimation par la fréquence d'apparition permet de déterminer la probabilité d'un évènement lorsqu'il y a un nombre fini d'évènements possibles et que l'on peut reproduire un grand nombre de fois et de façon indépendante l'expérience. Cet estimation peut, par exemple, servir pour obtenir la probabilité d'obtenir face ou un 6 avec un dé qu'il soit biaisé ou non. Il consiste à estimer la probabilité d'un évènement par sa fréquence d'apparition quand on répète un très grand nombre de fois l'expérience:
Par exemple si nous effectuons N lancers d'une pièce et que NF représente le nombre de fois où la pièce tombe sur face, à mesure que N devient de plus en plus grand, nous nous attendons à ce que le rapport NF/N devienne de plus en plus proche de 1/2. Cela nous suggère de définir la probabilité P(F) d'obtenir face comme étant la limite, quand N tend vers l'infini, de la suite des proportions :
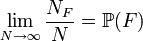
Cet estimateur pour la probabilité d'un évènement est, entre autres, un cas particulier de la loi des grands nombres en prenant par exemple la variable aléatoire X qui vaut 1 quand on obtient face et 0 sinon. Cette variable s'appelle la fonction caractéristique de F.
Des généralisations pour des variables continues existent par exemple la distribution empirique ou les estimateurs à noyaux. Ces estimateurs statistiques ont tous pour principal défaut le fait qu'il faut pouvoir répéter un grand nombre de fois l'expérience aléatoire ce qu'il n'est pas toujours possible de faire. Par exemple dans la pratique, nous ne pouvons pas lancer une pièce une infinité de fois.
Révision Bayésienne
Article détaillé : inférence bayésienne.La révision bayésienne est une autre méthode pour le calcul des probabilités. Elle est utilisée entre autres en théorie des jeux ou en intelligence artificielle pour créer des processus d'apprentissage. Elle se base sur la révision au fur et à mesure des expériences d'une croyance initiale (autrement appelée "probabilité a priori" quand cela n'entraine pas de confusion avec les probabilités a priori décrites dans l'introduction de cette section). Le choix de cette croyance initiale dépend des contraintes imposées à la distribution de probabilité. On choisit de toutes les distributions compatibles avec les contraintes celle d'entropie maximale, car c'est celle qui contient le moins d'information ajoutée[23] Nous présentons seulement ici le mécanisme qui permet de réviser cette croyance initiale. Celle-ci se fait grâce au théorème de Bayes:
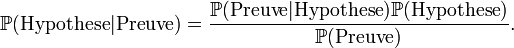
Dans cette version la croyance initiale est P(hypothèse). C'est la probabilité qu'une certaine hypothèse se vérifie. Cette croyance initiale est alors révisée grâce à une preuve que l'on peut observer. On en déduit une nouvelle probabilité que l'hypothèse initiale soit vérifiée en tenant compte de la preuve que l'on a observée. Ce processus s'appelle la "révision des croyances".
Notons ici que les termes Preuve et Hypothèse ont été choisis pour exprimer le lien qui devrait exister entre les deux événements et ainsi que le caractère asymétrique de ces deux événements. On aurait très bien pu prendre deux événements A et B par exemple. Dans la pratique il faut que l'événement "preuve" s'il se réalise rende plus probable (ou moins probable) la réalisation de l'événement "hypothèse" pour que cette méthode aboutisse. Ces deux événements ne doivent pas par exemple être indépendants.
Par exemple:
- On se demande quel temps il fera demain. On regarde pour cela la météo. On connaît la probabilité que la météo a d'annoncer qu'il fera beau sachant qu'il fera effectivement beau: p(M|Beau)=0.9 et la probabilité que la météo annonce qu'il fait beau sachant qu'il pleuvra: P(M|Pleut)=0.2. Ces probabilités ont par exemple été estimées par d'autres méthodes sur l'année écoulée. L'événement M dénote ici le fait que la météo annonce du beau temps.
- On part d'une croyance a priori sur le fait qu'il fera beau ou pas demain. Par exemple: P(Beau)=1/2 on croit a priori qu'il y a une chance sur deux qu'il fera beau demain. Ici notre hypothèse est le fait qu'il fera beau demain.
- On estime P(M) la probabilité que la météo annonce qu'il fasse beau grâce à notre croyance initiale: P(M)=p(M|Beau)P(Beau)+p(M|pleut)P(pleut)=0.9*1/2+0.2*1/2=0.55 la météo annonce qu'il fait beau dans 55% des cas. La probabilité qu'il fera beau demain sachant que la météo a annoncé beau temps est alors donnée par:
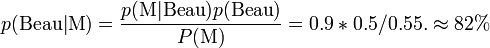
On pourrait alors, par exemple, réviser une deuxième fois l'hypothèse qu'il fera beau en regardant un deuxième bulletin météo d'une source différente. On prendrait alors comme croyance initiale la probabilité qu'il fasse beau que l'on vient de calculer.
Cette méthode permet de réviser la croyance que l'on a dans le fait qu'un événement futur va se passer. Cette méthode n'est employable que lorsque l'on a la possibilité d'estimer les probabilités conditionnelles p(M|Beau) p(M|pleut)
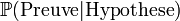 dans la formule donnée plus haut ainsi que
dans la formule donnée plus haut ainsi que 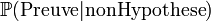 pour calculer
pour calculer 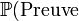 ) Cette méthode peut être utile car il est souvent plus simple de calculer les probabilités des observables conditionnées aux paramètres que de faire le contraire.
) Cette méthode peut être utile car il est souvent plus simple de calculer les probabilités des observables conditionnées aux paramètres que de faire le contraire.Interprétation des probabilités
Il existe deux façons de considérer les probabilités. La première historiquement a consisté à effectuer des calculs combinatoires dans le cas de jeux de hasard (Pascal, Bernoulli, Pólya…) cette approche peut se qualifier d'objective. La seconde, qui a commencé à se répandre vers 1974, est fondée sur le Théorème de Cox-Jaynes, qui démontre sous des hypothèses raisonnables que tout mécanisme d'apprentissage est soit isomorphe à la théorie des probabilités, soit inconsistant. Dans cette seconde approche, la probabilité est considérée comme la traduction numérique d'un état de connaissance et donc une valeur subjective (mais néanmoins obtenue par un processus rationnel); la subjectivité s'explique par le fait que le contexte d'interprétation d'un événement diffère chez chacun. C'est l'école bayésienne.[24]
L'idée de probabilité est le plus souvent séparée en deux concepts:
- la probabilité de l'aléatoire, qui représente la probabilité d'événements futurs dont la réalisation dépend de quelques phénomènes physiques aléatoires, comme obtenir un as en lançant un dé ou obtenir un certain nombre en tournant une roue ;
- la probabilité de l'épistémé, qui représente l'incertitude que nous avons devant des affirmations, lorsque nous ne disposons pas de la connaissance complète des circonstances et des causalités. De telles propositions peuvent avoir été vérifiées sur des événements passés ou seront peut-être vraies dans le futur. Quelques exemples de probabilités de l'épistémé sont, par exemple, assigner une probabilité à l'affirmation qu'une loi proposée de la physique est vraie, ou déterminer comment il est «probable» qu'un suspect ait commis un crime, en se basant sur les preuves présentées.
Une probabilité est-elle réductible à notre incapacité à prédire précisément quelles sont les forces qui pourraient affecter un phénomène, ou fait-elle partie de la nature de la réalité elle-même ainsi que le suggère la mécanique quantique ? La question reste à ce jour ouverte (voir aussi Principe d'incertitude).
Bien que les mêmes règles mathématiques s'appliquent indépendamment de l'interprétation choisie, le choix a des implications philosophiques importantes : parlons-nous jamais du monde réel (et a-t-on le droit d'en parler ?) ou bien simplement des représentations que nous en avons ? Ne pouvant par définition différencier le monde réel de ce que nous connaissons, il est bien entendu impossible de trancher de notre point de vue : la question est pour nous, par nature, subjective (voir aussi libre arbitre).
Des descriptions mathématiques rigoureuses de ce type de problèmes ne virent le jour que récemment, en particulier depuis
- Blaise Pascal au XVIIe siècle pour le déductif,
- Thomas Bayes et Pierre-Simon Laplace au XVIIIe siècle pour l'inductif.
Pour donner un sens mathématique possible, et par ailleurs réducteur, à une probabilité, considérez une pièce de monnaie que vous lancez. Intuitivement, nous considérons la probabilité d'obtenir face à n'importe quel lancer de la pièce égale à 1/2 ; mais que signifie opérationnellement cette phrase ? Si nous lançons la pièce 9 fois de suite, la pièce ne pourra évidemment pas tomber « quatre fois et demie » de chaque côté; il est même possible d'obtenir 6 face et 3 pile, voire 9 face de suite. Que signifie dans ce cas le rapport 1/2 dans ce contexte et que pouvons-nous exactement en faire ?
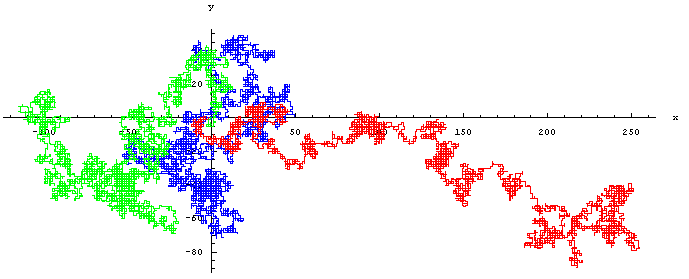
Le calcul stochastique
Article détaillé : calcul stochastique.Un processus stochastique, est un processus aléatoire qui dépend du temps. Un processus stochastique est donc une fonction de deux variables: le temps et la réalisation ω d'une certaine expérience aléatoire.
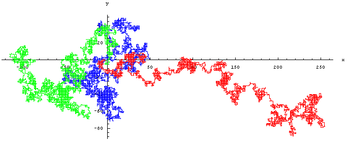 Un exemple de processus stochastique: la marche aléatoire. Ici on a représenté trois marches aléatoires indépendantes
Un exemple de processus stochastique: la marche aléatoire. Ici on a représenté trois marches aléatoires indépendantesParmi les processus stochastiques les chaînes de Markov constituent sans doute celui avec le plus d'applications pratiques. Ce sont des processus pour lesquels la prédiction du futur à partir du présent ne nécessite pas la connaissance du passé. Ces chaînes de Markov permettent de modéliser des phénomènes pour lesquels il suffit de connaître l'état présent pour pouvoir prévoir ce qui va se passer.
Ceci s'oppose, par exemple, à la notion d'hystérésis en physique où l'état actuel dépend de l'histoire et non seulement de l'état actuel. Les chaînes de Markov sont, entre autres, liées au mouvement brownien et à l'hypothèse ergodique, deux sujets de physique statistique qui ont été très importants au début du XXe siècle. Ils ont depuis connu d'autres utilisations pour étudier, par exemple, les fluctuations du marché boursier, ou pour la reconnaissance vocale. En temps discret, les processus stochastiques sont aussi connus sous le nom de Séries temporelles et servent entre autres en économétrie où ils ont une importance particulière.
Références
- ↑ voir l'entrée probabilité du dictionnaire TLFI
- ↑ a , b et c [1] 'De la doctrine de la probabilité à la théorie des probabilités' thèse de philosophie de Anne-Sophie Godfroy-Genin sur
- ↑ [2] étude philosophique sur Aristote
- ↑ [3] analyse du sens de "probabilité" au XVIe siècle dans les commentaires des Topiques
- ↑ [4] Catholic encyclopeida, 1911, article sur le probabilisme.
- ↑ [5] un site sur la pensée de Pascal
- ↑ http://www.jehps.net/Juin2007/Piron_incertitude.pdf, Journ@l Electronique d’Histoire des Probabilités et de la Statistique
- ↑ http://www.jehps.net/Juin2007/Ceccarelli_Risk.pdf, Journ@l Electronique d’Histoire des Probabilités et de la Statistique
- ↑ http://www.cict.fr/~stpierre/histoire/node1.html site sur l'histoire des probabilités
- ↑ copie de la lettre
- ↑ Les probabilités : Approche historique et définition.
- ↑ http://www.cict.fr/~stpierre/histoire/node3.html, une histoire de la probabilité jusqu'à Laplace
- ↑ Ian Hacking L'emergence des probabilitées
- ↑ http://statbel.fgov.be/info/quetelet_fr.asp, une biographie de quételet
- ↑ http://www.cict.fr/~stpierre/histoire/node4.html histoire des probabilités de Borel à la seconde guerre mondiale
- ↑ Entre De Moivre et Laplace
- ↑ DicoMaths : Chaine de Markov
- ↑ [6]un article sur la mise en place de l'axiomatisation des probabilités.
- ↑ Biographie d'Itô sur le site de Mac Tutor
- ↑ Bernard Bru et Marc Yor (éd.), « Sur l'équation de Kolmogoroff, par W Doeblin », C. R. Acad. Sci. Paris, Série I 331 (2000). Sur la vie de Doeblin, voir Bernard Bru, « La vie et l'œuvre de W. Doeblin (1915-1940) d'après les archives parisiennes », Math. Inform. Sci. Humaines 119 (1992), 5-51 et, en anglais, Biographie de Doeblin sur le site de Mac Tutor
- ↑ versions du théorème central limite
- ↑ Gnedenko-Kolmogorov, Limit distributions for sums of independant random variables. Nouvelle édition. Addison Wesley, 1968
- ↑ [7] publication de l'Insee sur l'analyse statistique bayésienne, mais les méthodes bayésiennes ne concernent pas que les statistiques
- ↑ [8] pour plus de détails sur l'objectivité et la subjectivité en probabilité
Voir aussi
Articles connexes
- Théorie des probabilités
- Calcul stochastique
- Variable aléatoire
- Loi de probabilité
- Cindynique
- Loi des grands nombres
- Théorème de la limite centrale
- Probabilité (mathématiques élémentaires) pour une première approche de la notion
Liens externes
- Journal sur l'histoire des probabilités et des statistiques et site associé (articles, bibliographie, biographies)
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de la finance
Portail de la finance
Catégorie : Probabilités
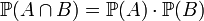
![F_X(x) = \mathbb{P}[X\leq x].](/pictures/frwiki/102/f7b8f14a5349644d0451f57a02cdff02.png)
![f_X(x) = \frac{d \mathbb{P}[X\leq x]}{d x}.](/pictures/frwiki/54/6aae3cddc45a6bcbc286472780cefe36.png)
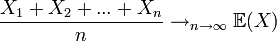
Wikimedia Foundation. 2010.