- Estimateur (Statistique)
-
Estimateur (statistique)
 Pour les articles homonymes, voir Estimateur.
Pour les articles homonymes, voir Estimateur.En statistique inférentielle, un estimateur est une valeur calculée sur un échantillon et que l'on espère être une bonne évaluation de la valeur que l'on aurait calculée sur la population totale. On cherche à ce qu'un estimateur soit sans biais, convergent, efficace et robuste.
Sommaire
Exemple d'estimateurs
Si l'on cherche à évaluer la taille moyenne des enfants de 10 ans, on peut effectuer un sondage sur un échantillon de la population des enfants de 10 ans (par exemple en s'adressant à des écoles réparties dans plusieurs milieux différents). La taille moyenne calculée sur cet échantillon, appelée moyenne empirique, sera un estimateur de la taille moyenne des enfants de 10 ans.
Si l'on cherche à évaluer la surface totale occupée par la jachère dans un pays donné, on peut effectuer un sondage sur plusieurs portions du territoire de même taille, calculer la surface moyenne occupée par la jachère et appliquer une règle de proportionnalité.
Si l'on cherche à déterminer le pourcentage d'électeurs décidés à voter pour le candidat A, on peut effectuer un sondage sur un échantillon représentatif. Le pourcentage de votes favorables à A dans l'échantillon est un estimateur du pourcentage d'électeurs décidés à voter pour A dans la population totale.
Si l'on cherche à évaluer la population totale de poissons dans un lac, on peut commencer par ramasser n poissons, les baguer pour pouvoir les identifier ultérieurement, les relâcher, les laisser se mélanger aux autres poissons. On tire alors un échantillon de poissons du lac, on calcule la proportion p de poissons bagués. La valeur n/p est un estimateur de la population totale de poissons dans le lac. S'il n'y a aucun poisson bagué dans l'échantillon, on procède à un autre tirage.
Un estimateur est très souvent une moyenne, une population totale, une proportion ou une variance.
Définition formelle
Un estimateur du paramètre inconnu θ d'un modèle ou loi de probabilité est une fonction qui fait correspondre à une suite d'observations issues du modèle ou loi de probabilité la valeur
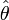 , que l'on nomme estimé ou estimation.
, que l'on nomme estimé ou estimation.Définition —
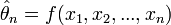
Qualité d'un estimateur
Un estimateur est une valeur
calculée sur un échantillon tiré au hasard, la valeur est donc une variable aléatoire possédant une espérance 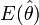 et une variance
et une variance 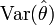 . On comprend alors que la valeur x puisse fluctuer selon l'échantillon. Elle a de très faibles chances de coïncider exactement avec la valeur θ qu'elle est censée représenter. L'objectif est donc de maîtriser l'erreur commise en prenant la valeur x pour la valeur X.
. On comprend alors que la valeur x puisse fluctuer selon l'échantillon. Elle a de très faibles chances de coïncider exactement avec la valeur θ qu'elle est censée représenter. L'objectif est donc de maîtriser l'erreur commise en prenant la valeur x pour la valeur X.Biais
Article détaillé : Biais (statistique).Une variable aléatoire fluctue autour de son espérance. On souhaite donc que l'espérance de
soit égale à θ, soit qu'en "moyenne" l'estimateur ne se trompe pas.Définition —
![\operatorname{Biais}(\hat\theta)\equiv E[\hat\theta]-\theta](/pictures/frwiki/55/77c4c1655115d2f0ad5662cf3c3dfd2f.png)
Lorsque l'espérance de l'estimateur
égale θ, i.e. le biais est égal à zéro, l'estimateur est dit sans biais.L'estimateur choisi précédemment sur la taille moyenne des enfants de 10 ans est un estimateur sans biais mais celui des poissons comporte un biais: le nombre de poissons estimé est en moyenne supérieur au nombre de poissons réels.
Erreur quadratique moyenne
Article détaillé : Erreur quadratique moyenne.L'erreur quadratique moyenne est l'espérance du carré de l'erreur entre la vraie valeur et sa valeur estimée.
Définition —
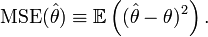
Convergence
On souhaite aussi pouvoir, en augmentant la taille de l'échantillon, diminuer l'erreur commise en prenant
à la place de θ. Si c'est le cas, on dit que l'estimateur est convergent, c'est-à-dire qu'il converge vers sa vraie valeur. La définition précise en mathématique est la suivante :Définition — L'estimateur
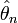 est convergent s'il converge en probabilité vers θ, soit:
est convergent s'il converge en probabilité vers θ, soit: 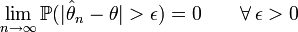 .
.On l'interprète comme le fait que la probabilité de s'éloigner de la valeur à estimer de plus de ε tend vers 0 quand la taille de l'échantillon augmente.
Cette définition est parfois écrite de manière inverse:
Définition — L'estimateur
est convergent s'il converge en probabilité vers θ, soit: 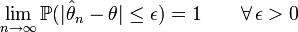 .
.Il existe enfin un type de convergence plus forte, la convergence presque sûre, définie ainsi pour un estimateur:
Définition — L'estimateur
est fortement convergent s'il converge presque sûrement vers θ, soit: 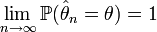
Exemple: La moyenne empirique est un estimateur convergent de l'espérance d'une variable aléatoire. La loi des grands nombres dans sa version "faible" assure que la moyenne converge en probabilité vers l'espérance et la loi forte des grands nombres qu'elle converge presque sûrement.Taux de convergence
Efficacité
La variable aléatoire fluctue autour de son espérance. Plus la variance
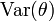 est faible, moins les variations sont importantes. On cherche donc à ce que la variance soit la plus faible possible. C'est ce qu'on appelle l’efficacité d'un estimateur.
est faible, moins les variations sont importantes. On cherche donc à ce que la variance soit la plus faible possible. C'est ce qu'on appelle l’efficacité d'un estimateur.Robustesse
Il arrive que lors du sondage, une valeur extrême et rare apparaisse (par exemple un enfant de 10 ans mesurant 1,80 m). On cherche à ce que ce genre de valeur change de manière très faible la valeur de l'estimateur. On dit alors que l'estimateur est robuste.
Exemple: En reprenant l'exemple de l'enfant, la moyenne n'est pas un estimateur robuste car rajouter l'enfant très grand modifiera beaucoup notre estimateur. La médiane par contre est souvent présentée comme un estimateur de tendance centrale robuste.
Estimateurs classiques
On se placera dans le cas simple d'un tirage aléatoire de n individus dans une population en comportant N. On s'intéresse au caractère quantitatif Y de moyenne
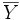 et de variance V(Y). Dans l'échantillon tiré, le caractère quantitatif est y, sa moyenne est
et de variance V(Y). Dans l'échantillon tiré, le caractère quantitatif est y, sa moyenne est 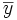 et sa variance est
et sa variance est 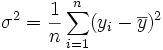 . Les valeurs et σ2 varient selon l'échantillon et sont donc des variables aléatoires possédant chacune une espérance, une variance et un écart type.
. Les valeurs et σ2 varient selon l'échantillon et sont donc des variables aléatoires possédant chacune une espérance, une variance et un écart type.Estimateur de la moyenne de Y
On prend en général comme estimateur de
la valeur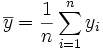 .
.
appelée moyenne empirique de Y. On démontre que c'est un estimateur sans biais, c’est-à-dire que
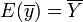
Estimateur de la variance de Y
On pourrait penser que σ2 est un bon estimateur de V(Y). Cependant des calculs (voir écart type) prouvent que cet estimateur est biaisé, l'espérance de σ2 est toujours inférieure à V(Y). On prouve qu'un estimateur sans biais de V(Y) est :
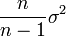 dans le cas de tirage avec remise
dans le cas de tirage avec remise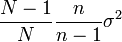 dans le cas de tirage sans remise (qui vaut bien σ2 lorque n = N).
dans le cas de tirage sans remise (qui vaut bien σ2 lorque n = N).
On peut remarquer que, pour N grand, le calcul avec remise et le calcul sans remise donnent des résultats presque équivalents. (le quotient
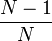 est alors proche de 1). On prend donc en général, pour estimateur sans biais de V(Y) la valeur :
est alors proche de 1). On prend donc en général, pour estimateur sans biais de V(Y) la valeur :appelée variance empirique de Y.
Efficacité, convergence et intervalle de confiance
La manière dont
fluctue autour de son espérance Y dépend de sa variance 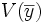 . Cette variance se calcule grâce à V(Y).
. Cette variance se calcule grâce à V(Y).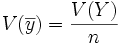 dans le cas d'un tirage avec remise
dans le cas d'un tirage avec remise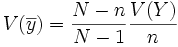 dans le cas d'un tirage sans remise
dans le cas d'un tirage sans remise
On peut remarquer que, pour N très grand devant n, les deux valeurs sont très voisines. Par la suite, on ne s'intéressera donc qu'au cas du tirage avec remise en considérant que N est très grand.
On s'aperçoit que plus n est grand, plus
est petit. Donc, plus la taille de l'échantillon est grande, plus l'estimateur est efficace.L'inégalité de Bienaymé-Tchebychev précise que, pour tout réel strictement positif ε,
donc que
Or
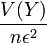 converge vers 0 quand n tend vers l'infini. Il en est de même de
converge vers 0 quand n tend vers l'infini. Il en est de même de 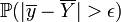 : l'estimateur est convergent.
: l'estimateur est convergent.Enfin, il résulte du théorème de la limite centrale que pour n relativement grand, la variable aléatoire
suit (approximativement) une loi normale d'espérance Y et de variance 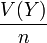 , variance que l'on peut estimer être voisine de
, variance que l'on peut estimer être voisine de 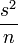 . Pour toute loi normale, dans 95% des cas, la variable aléatoire s'éloigne de son espérance de moins de deux fois son écart type. Dans le cas du sondage, cela signifie qu'il y a 95% de chance que l'estimateur s'éloigne de de moins de
. Pour toute loi normale, dans 95% des cas, la variable aléatoire s'éloigne de son espérance de moins de deux fois son écart type. Dans le cas du sondage, cela signifie qu'il y a 95% de chance que l'estimateur s'éloigne de de moins de 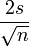 . L'intervalle
. L'intervalle ![\left[\overline Y - \frac{2\sigma(Y)}{\sqrt n}, \overline Y +\frac{2\sigma(Y)}{\sqrt n}\right]](/pictures/frwiki/97/abda8357d48b0497cd2f2dee0354b2ce.png) est appelé intervalle de confiance à 95%. On peut remarquer que, pour diviser par 10 la longueur de l'intervalle de confiance, ce qui consiste à augmenter la précision de l'estimateur, il faut multiplier par 102 = 100 la taille de l'échantillon.
est appelé intervalle de confiance à 95%. On peut remarquer que, pour diviser par 10 la longueur de l'intervalle de confiance, ce qui consiste à augmenter la précision de l'estimateur, il faut multiplier par 102 = 100 la taille de l'échantillon.On parle souvent de la précision d'une enquête : c'est le rapport
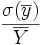 entre l'écart type et la moyenne de la variable aléatoire . Si l'enquête est précise à 2% par exemple, c'est que ce rapport est de 2 %. Cela signifie que l'intervalle de confiance à 95% est de
entre l'écart type et la moyenne de la variable aléatoire . Si l'enquête est précise à 2% par exemple, c'est que ce rapport est de 2 %. Cela signifie que l'intervalle de confiance à 95% est de ![[0,96 \overline Y, 1,04 \overline Y]](/pictures/frwiki/100/d9d22c603d9c4fdd05ba2beadeaa8084.png)
Influence des techniques de sondages sur les estimateurs
Découper la population en strates homogènes peut réduire de manière significative la valeur de la variance de l'estimateur et donc le rendre plus efficace.
Utiliser un tirage aléatoire à probabilités inégales, procéder à un sondage en plusieurs étapes ou par grappe change évidemment les formules calculées précédemment.
Enfin, l'utilisation d'informations auxilaires permet parfois d'effectuer une correction sur l'estimateur pour le rapprocher de la valeur réelle.
Construction d'estimateurs
Méthode du maximum de vraisemblance
Article détaillé : Maximum de vraisemblance.Comme son nom l'indique, cette méthode consiste à maximiser une fonction appelée fonction de vraisemblance, contenant le paramètre que l'on souhaite estimer. Elle aura ainsi de fortes chances d'être très proche de ce paramètre.
Fonction de vraisemblance, au vu d'un n-échantillon (x1,...,xi,...,xn) :
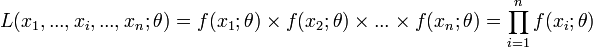
L'estimateur obtenu par cette méthode est généralement le meilleur possible, mais cela peut être fastidieux et surtout nécessite de maîtriser des règles mathématiques plus difficiles que la méthode des moments (voir ci-dessous).
Méthode des moments
Article détaillé : Méthode des moments (statistiques).La méthode des moments permet d'estimer des paramètres : pour cela, on pose l'égalité entre moments théoriques et empiriques correspondants puis, en résolvant les équations écrites, on exprime les paramètres en fonction de ces moments.
Estimateurs et loi de probabilité
Le fait de pouvoir estimer une espérance et une variance permet alors d'estimer les paramètres d'une distribution (loi normale, loi de Poisson etc.).
En probabilité, on cherche parfois à valider une loi de probabilité théorique à l'aide d'une expérience statistique. Dans le cas d'une variable discrète finie, on prend comme estimateur de chaque probabilité pk, la fréquence fk dans l'échantillon. Les valeurs fk étant des variables aléatoires, il est normal que ces estimateurs ne coïncident pas complètement avec les valeurs pk. Pour vérifier si les différences trouvées sont significatives ou non, on effectue des tests d'adéquations dont le plus connu est le test du χ².
Voir aussi
Liens internes
- Variance
- Biais (statistique)
- Inférence statistique
- Statistique mathématique
- Sondage
- Variable indépendante et identiquement distribuée
Bibliographie
- (fr) DAGNELIE P. (2007) Statistique théorique et appliquée. Tome 1 : Statistique descriptive et base de l'inférence statistique. Paris et Bruxelles, De Boeck et Larcier.
- (fr) DAGNELIE P. (2006) Statistique théorique et appliquée. Tome 2 : Inférence statistique à une et à deux dimensions. Paris et Bruxelles, De Boeck et Larcier.
- (fr) DROESBECKE J.-J. (2001) Éléments de statistique. Paris, Ellipses.
- (fr) ESCOFIER B., PAGES J. (1997) Initiation au traitement statistique : Méthodes, méthodologie. PUR, Rennes.
- (fr) FALISSARD B., MONGA (1993) Statistique : concepts et méthodes. Paris, Masson.
- (fr) ROUANET H., BERNARD J.-M., LE ROUX B. (1990) : Statistique en sciences humaines : analyse inductive des données. Paris, Dunod.
- (fr) Gilbert Saporta, Probabilités, Analyse des données et Statistique, 2006 [détail des éditions]
- (fr) VEYSSEYRE R. (2002) Statistique et probabilité pour l'ingénieur. Paris, Dunod.
- (en) LEHMANN, E.L. (1983) "THEORY OF POINT ESTIMATION". John Wiley and Sons, New York.
Sources
- estimateur cours de Bernart Ycart
- Estimation cours de l'INSA de Lyon
- Glossaire sur l'estimation
- Rémy Clairin et Philippe Brion, Manuel de sondages. Application aux pays en développement. Paris, Centre français sur la population et le développement, 1996.
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégorie : Statistiques
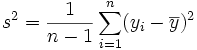
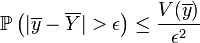
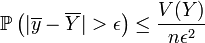
Wikimedia Foundation. 2010.