- Distribution gaussienne
-
Loi normale
Distribution gaussienne Densité de probabilité / Fonction de masse
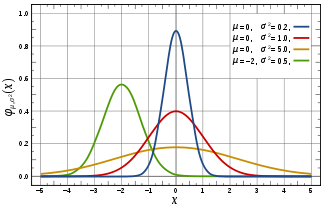
La courbe rouge représente la fonction φ (voir texte), densité de probabilité d'une variable suivant une loi normale centrée réduiteFonction de répartition
Paramètres μ moyenne (nombre réel)
σ2 > 0 variance (nombre réel)Support ![x \in\, ]-\infty;+\infty[\!](/pictures/frwiki/51/3eb0804398728ee2cfdc3385ba9e57d7.png)
Densité de probabilité (fonction de masse) 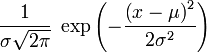
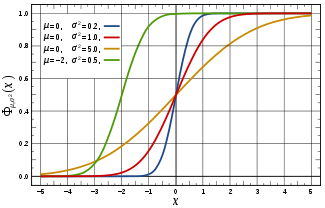
Fonction de répartition 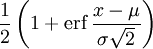
Espérance μ Médiane (centre) μ Mode μ Variance σ2 Asymétrie (statistique) 0 Kurtosis (non-normalisé) 3 (0 si normalisé) Entropie 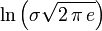
Fonction génératrice des moments 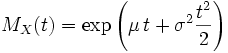
Fonction caractéristique 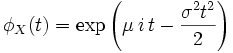
En probabilité, on dit qu'une variable aléatoire réelle X suit une loi normale (ou loi normale gaussienne, loi de Laplace-Gauss) d'espérance μ et d'écart type σ strictement positif (donc de variance σ2) si cette variable aléatoire réelle X admet pour densité de probabilité la fonction f définie, pour tout nombre réel x, par :
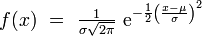
Une telle variable aléatoire est alors dite variable gaussienne.
On note habituellement cela de la manière suivante :
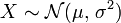 [1]
[1]La loi normale est une des principales distributions de probabilité. Elle a été introduite par le mathématicien Abraham de Moivre en 1733 et utilisée par lui afin d'approcher des probabilités associées à des variables aléatoires binomiales possédant un paramètre n très grand. Cette loi a été mise en évidence par Gauss au XIXe siècle et permet de modéliser de nombreuses études biométriques. Sa densité de probabilité dessine une courbe dite courbe en cloche ou courbe de Gauss.
La loi normale centrée réduite
Définition
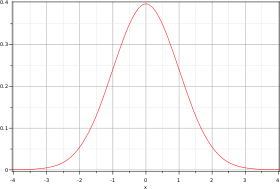 Représentation graphique d'une loi normale centrée réduite (dite courbe de Gauss ou courbe en cloche).
Représentation graphique d'une loi normale centrée réduite (dite courbe de Gauss ou courbe en cloche).
On appelle loi normale (ou gaussienne) centrée réduite la loi définie par la densité de probabilité
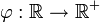 définie par :
définie par :On vérifie qu'elle est continue et que son intégrale sur
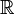 est égale à 1.
est égale à 1.On sait en effet que
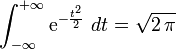 (intégrale de Gauss).
(intégrale de Gauss).On démontre (voir plus bas) que la loi définie par cette densité de probabilité admet une espérance nulle et une variance égale à 1.
Remarques :
- la densité
 est paire ;
est paire ; - elle est indéfiniment dérivable et vérifie, pour tout
 , l'identité
, l'identité  .
.
La représentation graphique de cette densité est une courbe en cloche (ou courbe de Gauss).
Moments
Les moments de cette loi existent tous. Pour tout
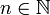 , le moment d'ordre n par rapport à l'origine est :
, le moment d'ordre n par rapport à l'origine est :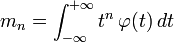 .
.
Pour la suite on supposera μ = 0 et σ2 = 1.
- En raison de la parité de l'intégrande, tous les moments d'ordre impair sont nuls :
- Supposons à présent n pair :
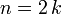 , où
, où 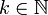 .
.
- Si
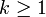 , une intégration par parties (non détaillée ici) donne :
, une intégration par parties (non détaillée ici) donne :
- ce qui fournit la relation de récurrence :
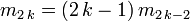 .
.
- De cette relation, on déduit, comme
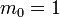 , que :
, que : 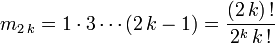
- En particulier,
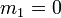 (l'espérance est nulle : la loi est donc dite centrée) et
(l'espérance est nulle : la loi est donc dite centrée) et 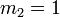 (la variance vaut
(la variance vaut 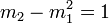 : la loi est donc dite réduite).
: la loi est donc dite réduite).
- Ceci justifie l'appellation de loi normale centrée réduite.
- Des formules précédentes, on déduit encore :
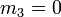 et
et 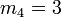
- La loi étant réduite, les moments centrés sont tous égaux aux moments par rapport à l'origine de même rang ; en particulier :
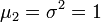 ,
, 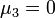 et
et 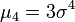 .
.- On en déduit l'asymétrie (skewness) :
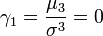 et l'aplatissement (kurtosis) :
et l'aplatissement (kurtosis) : 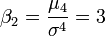 .
.
Fonction de répartition
Article détaillé : fonction d'erreur.On note Φ la fonction de répartition de la loi normale centrée réduite. Elle est définie, pour tout réel x, par :
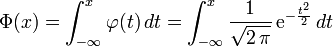 .
.C'est la primitive de
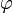 qui tend vers 0 en
qui tend vers 0 en 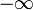 ; elle ne s'exprime pas à l'aide des fonctions usuelles (exponentielle, etc.) mais devient elle-même une fonction usuelle, importante, pour quiconque pratique le calcul des probabilités ou les statistiques ; elle s'exprime à l'aide de la fonction d'erreur.
; elle ne s'exprime pas à l'aide des fonctions usuelles (exponentielle, etc.) mais devient elle-même une fonction usuelle, importante, pour quiconque pratique le calcul des probabilités ou les statistiques ; elle s'exprime à l'aide de la fonction d'erreur.Citons les propriétés suivantes de la fonction Φ :
- Elle est indéfiniment dérivable, et
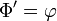
- Elle est strictement croissante, tend vers 0 en et vers 1 en
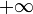
- (c'est donc une bijection
![\R \to\, ]0,\, 1[\,](/pictures/frwiki/53/57e1b51edc83a9645ee6f7baea82c185.png) : pour tout
: pour tout ![p \in\, ]0,\, 1[\,](/pictures/frwiki/102/ffcce36c227a3b4d9dac45ad5299069e.png) , il existe
, il existe 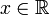 unique, noté
unique, noté 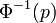 , tel que
, tel que 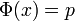 )
)
- Pour tout
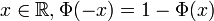 (ceci résulte de ce que la densité est paire) ; en particulier,
(ceci résulte de ce que la densité est paire) ; en particulier, 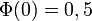
Remarque : les notations
et 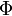 pour désigner « la » densité et la fonction de répartition de la loi normale centrée réduite sont usuelles.
pour désigner « la » densité et la fonction de répartition de la loi normale centrée réduite sont usuelles.Approximation de la fonction de répartition
Il n'existe pas d'expression pour Φ mais on peut exploiter avec profit son aspect régulier pour en donner une approximation grâce à un développement en série de Taylor. Par exemple, voici une approximation (à l'ordre 5) autour de 0:
![\Phi(x) \approx \frac{1}{2} + \frac{1}{\sqrt{2 \pi}} \left[x-\frac{x^3}{6}+\frac{x^5}{40}\right]](/pictures/frwiki/50/27e358ffbf8ef911d0285e69b13a70b9.png) . Cette approximation est performante pour | x | < 2.
. Cette approximation est performante pour | x | < 2.Une approximation pour les grandes valeurs de x est donnée, pour x positif, par la formule
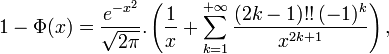
série divergente pour tout x positif, mais dont les sommes partielles encadrent 1-Φ(x) de manière efficace lorsque x est grand. Par exemple,
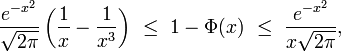
d'où une erreur relative inférieure à 25% pour x supérieur à 2 ou bien inférieure à 11% pour x supérieur à 3. Ou bien encore :
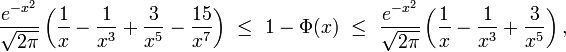
d'où une erreur relative inférieure à 25% pour x supérieur à 2 ou bien inférieure à 2% pour x supérieur à 3.
Tables numériques
Il existe des tables de la fonction de répartition, donnant des valeurs approchées de
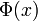 ; on se limite à des x positifs ou nuls : en effet, si par exemple on connaît l'approximation
; on se limite à des x positifs ou nuls : en effet, si par exemple on connaît l'approximation  , on en déduit
, on en déduit 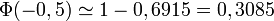 .
.Au lieu des précédentes, on utilise souvent des tables de la fonction qu'on notera ici
 , définie sur
, définie sur  par :
par :La table suivante donne pour tout x de 0 jusqu'à 3,9 par pas de 0,01, la valeur de 105 Φ(x). Ces valeurs sont arrondies à l'unité la plus proche.
L'entrée en ligne donne les deux premiers chiffres de x, c'est-à-dire le chiffre des unités et celui des dixièmes, et l'entrée en colonne le chiffre des centièmes.
Par exemple : Φ(1,73) = 0,95818.
0,00 0,01 0,02 0,03 0,04 0,05 0,06 0,07 0,08 0,09 0,0 50000 50399 50798 51197 51595 51994 52392 52790 53188 53586 0,1 53983 54380 54776 55172 55567 55962 56356 56749 57142 57535 0,2 57926 58317 58706 59095 59483 59871 60257 60642 61026 61409 0,3 61791 62172 62552 62930 63307 63683 64058 64431 64803 65173 0,4 65542 65910 66276 66640 67003 67364 67724 68082 68439 68793 0,5 69146 69497 69847 70194 70540 70884 71226 71566 71904 72240 0,6 72575 72907 73237 73565 73891 74215 74537 74857 75175 75490 0,7 75804 76115 76424 76730 77035 77337 77637 77935 78230 78524 0,8 78814 79103 79389 79673 79955 80234 80511 80785 81057 81327 0,9 81594 81859 82121 82381 82639 82894 83147 83398 83646 83891 1,0 84134 84375 84614 84849 85083 85314 85543 85769 85993 86214 1,1 86433 86650 86864 87076 87286 87493 87698 87900 88100 88298 1,2 88493 88686 88877 89065 89251 89435 89617 89796 89973 90147 1,3 90320 90490 90658 90824 90988 91149 91309 91466 91621 91774 1,4 91924 92073 92220 92364 92507 92647 92785 92922 93056 93189 1,5 93319 93448 93574 93699 93822 93943 94062 94179 94295 94408 1,6 94520 94630 94738 94845 94950 95053 95154 95254 95352 95449 1,7 95543 95637 95728 95818 95907 95994 96080 96164 96246 96327 1,8 96407 96485 96562 96638 96712 96784 96856 96926 96995 97062 1,9 97128 97193 97257 97320 97381 97441 97500 97558 97615 97670 2,0 97725 97778 97831 97882 97932 97982 98030 98077 98124 98169 2,1 98214 98257 98300 98341 98382 98422 98461 98500 98537 98574 2,2 98610 98645 98679 98713 98745 98778 98809 98840 98870 98899 2,3 98928 98956 98983 99010 99036 99061 99086 99111 99134 99158 2,4 99180 99202 99224 99245 99266 99286 99305 99324 99343 99361 2,5 99379 99396 99413 99430 99446 99461 99477 99492 99506 99520 2,6 99534 99547 99560 99573 99585 99598 99609 99621 99632 99643 2,7 99653 99664 99674 99683 99693 99702 99711 99720 99728 99736 2,8 99744 99752 99760 99767 99774 99781 99788 99795 99801 99807 2,9 99813 99819 99825 99831 99836 99841 99846 99851 99856 99861 3,0 99865 99869 99874 99878 99882 99886 99889 99893 99896 99900 3,1 99903 99906 99910 99913 99916 99918 99921 99924 99926 99929 3,2 99931 99934 99936 99938 99940 99942 99944 99946 99948 99950 3,3 99952 99953 99955 99957 99958 99960 99961 99962 99964 99965 3,4 99966 99968 99969 99970 99971 99972 99973 99974 99975 99976 3,5 99977 99978 99978 99979 99980 99981 99981 99982 99983 99983 3,6 99984 99985 99985 99986 99986 99987 99987 99988 99988 99989 3,7 99999 99999 99999 99999 99999 99999 99999 99999 99999 99999 3,8 99999 99999 99999 99999 99999 99999 99999 99999 99999 99999 3,9 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 1.0000 On dispose des relations simples suivantes entre
et (découlant de la formule de Chasles pour les intégrales) :- si
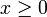 , alors
, alors 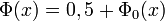
- si
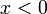 , alors
, alors 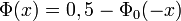
Soit T une variable aléatoire suivant la loi normale centrée réduite :
- pour tout
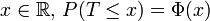 et pour tout
et pour tout 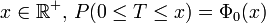
- pour tout couple
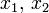 de réels tels que
de réels tels que 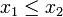 ,
, 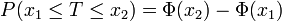 .
.
Exemples numériques
À l'aide de la table ci-dessus, on obtient, pour la variable aléatoire précédente :
La loi normale générale
Soient
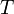 une variable aléatoire suivant la loi normale centrée réduite, et deux réels
une variable aléatoire suivant la loi normale centrée réduite, et deux réels 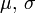 , où
, où 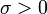 .
.On définit la variable aléatoire
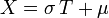 , dont on note
, dont on note 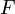 la fonction de répartition.
la fonction de répartition.On a
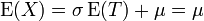 et
et 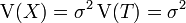 puisque
puisque 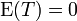 et
et 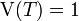 .
.Cherchons la loi de
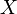 : pour tout ,
: pour tout ,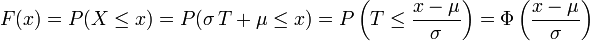 ,
,
- puisque la fonction de répartition de est .
Ainsi,
est continûment (et même indéfiniment) dérivable : suit une loi à densité, et la dérivée 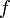 de est une densité de probabilité de cette variable aléatoire ; pour tout ,
de est une densité de probabilité de cette variable aléatoire ; pour tout ,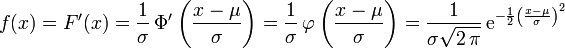 .
.
Ceci légitime la définition suivante :
Définition
On appelle loi normale (ou gaussienne, ou de Laplace-Gauss) de paramètres
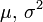 (où ) la loi de probabilité définie par la densité
(où ) la loi de probabilité définie par la densité 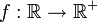 , telle que pour tout :
, telle que pour tout :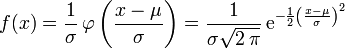 .
.
Une variable gaussienne est une variable aléatoire réelle qui suit une loi normale de paramètres
(où 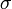 est soit positive, soit nulle). Le cas où est nul est appelé cas dégénéré et correspond aux variables aléatoires constantes. Cette convention étrange est commode, voire indispensable (par exemple pour définir les vecteurs gaussiens).
est soit positive, soit nulle). Le cas où est nul est appelé cas dégénéré et correspond aux variables aléatoires constantes. Cette convention étrange est commode, voire indispensable (par exemple pour définir les vecteurs gaussiens).Notation: cette loi est notée
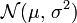 [1]
[1]
La loi normale centrée réduite est notée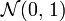 .
.On peut énoncer plusieurs propriétés, compte tenu de ce qui précède (le dernier point se démontrant de manière analogue).
Propriétés
Soit une variable aléatoire
qui suit la loi normale . Alors :- la variable aléatoire
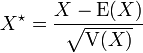 , c'est-à-dire
, c'est-à-dire 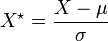 , suit la loi normale centrée réduite
, suit la loi normale centrée réduite - si
 sont deux réels (
sont deux réels ( ), alors la variable aléatoire
), alors la variable aléatoire 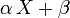 suit la loi normale
suit la loi normale 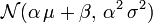
Soit une variable aléatoire
qui suit la loi normale . Alors la variable aléatoire exp(X) (de loi dite log-normale) possède les propriétés suivantes:Soit une variable aléatoire
suivant une loi normale 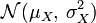 et
et  suivant une loi normale
suivant une loi normale 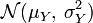 . Alors, la divergence de Kullback-Leibler entre ces deux distributions est de la forme :
. Alors, la divergence de Kullback-Leibler entre ces deux distributions est de la forme :Largeur à mi-hauteur
Lorsque l'on travaille sur une représentation graphique, on estime fréquemment la largeur de la gaussienne par sa largeur à mi-hauteur H (en anglais full width at half maximum, FWHM), qui est la largeur de la courbe à une altitude qui vaut la moitié de l'altitude du sommet. La largeur à mi-hauteur est proportionnelle à l'écart type :
Le facteur 2 sert à prendre en compte l'extension de la gaussienne dans les valeurs négatives.
Calcul de P(a ≤ X ≤ b)
Les résultats précédents permettent de ramener tout calcul de probabilité relatif à la loi normale
à un calcul de probabilité relatif à la loi normale centrée réduite. On a vu qu'on dispose de tables donnant des approximations de valeurs de la fonction , tables qu'on utilise encore fréquemment, même si certaines calculatrices ou certains tableurs peuvent maintenant les remplacer.Si la variable aléatoire
suit la loi normale , et si 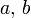 sont deux réels tels que
sont deux réels tels que 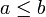 , on a :
, on a :Cas d'un intervalle centré à la moyenne, plages de normalité
- Si t est un réel positif,
- lorsque
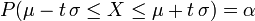 , où
, où ![\ \alpha \in\, ]0,\, 1[](/pictures/frwiki/101/ebf510469db31b72eca5620b9c1f2eb6.png) ,
,
- ce qui équivaut à
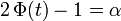 , ou
, ou 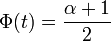 ,
,
- l'intervalle
![\ [\mu - t\, \sigma,\, \mu + t\, \sigma] = [\mathrm{E}(X) - t\, \sigma,\, \mathrm{E}(X) + t\, \sigma]](/pictures/frwiki/55/73254f7af8bf0426f9279822faf6dcd5.png) est appelé plage de normalité au niveau de confiance α
est appelé plage de normalité au niveau de confiance α
- (si par exemple, α = 0,95, on dit : "plage de normalité au niveau de confiance 95%" : en statistique, c'est un intervalle dans lequel se trouve 95% de la population lorsque la distribution est gaussienne).
Exemples numériques
Grâce à la table précédente, on obtient :
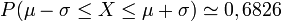 ;
;
- l'intervalle
![[\mathrm{E}(X) - \sigma,\, \mathrm{E}(X) + \sigma]](/pictures/frwiki/49/1897c506e498c1c9c7de0dc2fc0819b5.png) est la plage de normalité au niveau de confiance 68 %
est la plage de normalité au niveau de confiance 68 %
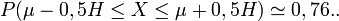 ;
;
- l'intervalle
![[\mathrm{E}(X) - 0,5H,\, \mathrm{E}(X) + 0,5H]](/pictures/frwiki/54/673ab2373f88c2a93e126c2f1b15d9bc.png) (H étant la largeur à mi-hauteur) est la plage de normalité au niveau de confiance 76 %
(H étant la largeur à mi-hauteur) est la plage de normalité au niveau de confiance 76 %
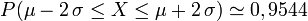 ;
;
- l'intervalle
![[\mathrm{E}(X) - 2\, \sigma,\, \mathrm{E}(X) + 2\, \sigma]](/pictures/frwiki/51/3cbacb02bf77d378a8d28a903520c815.png) est la plage de normalité au niveau de confiance 95 %
est la plage de normalité au niveau de confiance 95 %
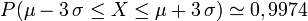 ;
;
- l'intervalle
![[\mathrm{E}(X) - 3\, \sigma,\, \mathrm{E}(X) + 3\, \sigma]](/pictures/frwiki/48/0a0ea77659ca495de15d3b31c79d44c2.png) est la plage de normalité au niveau de confiance 99 %
est la plage de normalité au niveau de confiance 99 %
Champ d'application
 Une planche de Galton nous montre que la loi binomiale tend vers la loi normale
Une planche de Galton nous montre que la loi binomiale tend vers la loi normaleLe Théorème de Moivre-Laplace affirme la convergence d'une loi binomiale vers une loi de Gauss quand le nombre d'épreuves augmente. On peut alors utiliser la loi normale comme approximation d'une loi binomiale de paramètres (n ; p) pour n grand et p, 1 - p de même ordre de grandeur ; on approche alors cette loi binomiale par la loi normale ayant même espérance np et même variance np(1 − p).
On a dessiné ci-dessous :
- la loi binomiale de paramètres (12;1 / 3) (diagramme en bâtons rouge) et la loi normale correspondante d'espérance 4 et de variance 8 / 3 (courbe verte)
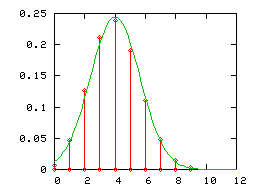
- la loi binomiale de paramètres (60;1 / 3) (diagramme en bâtons rouge) , et la loi normale correspondante d'espérance 20 et de variance 40 / 3 (courbe verte)
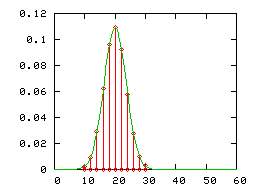
Le mathématicien Carl Friedrich Gauss a introduit cette loi pour le calcul d'erreurs.
En statistiques, de nombreux phénomènes suivent des distributions gaussiennes : données biométriques des individus (Adolphe Quételet).
Critères et tests de normalité
Critères de normalité
Le recours à une distribution gaussienne est si fréquent qu'il peut finir par être abusif. Il faut alors rechercher des critères de normalité.
Le premier critère, le plus simple, consiste à tracer l'histogramme ou le diagramme en bâtons de la distribution et à vérifier si le diagramme est en forme de « cloche ». Ce critère, subjectif, permet cependant d'éliminer une partie des distributions jugées alors non gaussiennes.
Le critère suivant consiste à utiliser les plages de normalité ou intervalles de confiance. On a vu que si une distribution est gaussienne :
- 68% de la population est dans l'intervalle
![[\overline{x} -\sigma\, ;\, \overline{x}+\sigma]](/pictures/frwiki/55/70fcb25f978da6eabaca2105c3c5341c.png) ,
,
- 76% de la population est dans l'intervalle
![[\overline{x} -0,5H\, ;\, \overline{x}+0,5H]](/pictures/frwiki/53/5513c7612c8d4b51d52b43cb0cc20d99.png) ,
,
- 95% de la population est dans l'intervalle
![[\overline{x} -2\, \sigma\, ;\, \overline{x} + 2\, \sigma]](/pictures/frwiki/101/eb0df02e9fffd2c828977883e9e9bbb8.png) ,
,
- 99% de la population est dans l'intervalle
![[\overline{x} - 3\, \sigma\, ;\, \overline{x} + 3\, \sigma]](/pictures/frwiki/52/48f3f1175cb4ab1a8c6fa2e26f839b37.png) .
.
Lorsque ces pourcentages ne sont pas respectés, il y a fort à parier que la distribution n'est pas gaussienne.
On peut aussi utiliser la droite de Henry, en particulier quand on possède peu de renseignements sur la distribution. La droite de Henry va permettre de porter un diagnostic sur la nature non gaussienne de la distribution, et, dans le cas où celle-ci a des chances d'être gaussienne, elle permet d'en déterminer la moyenne et l'écart type.
Tests de normalité
Il existe également un grand nombre de tests de normalité:
- Tests basés sur la fonction de répartition empirique : Test de Kolmogorov-Smirnov et son adaptation le test de Lilliefors (en), ou le test de Anderson-Darling (en)
- Tests basés sur les moments, comme le Test de Jarque Bera ou test D'Agostino's K-squared (en)
- ou encore le test de Shapiro-Wilk (en)
Stabilité de la loi normale par la somme
La somme de deux variables gaussiennes indépendantes est elle-même une variable gaussienne. Plus explicitement :
Soient
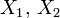 deux variables aléatoires indépendantes suivant respectivement les lois
deux variables aléatoires indépendantes suivant respectivement les lois 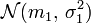 et
et 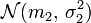 .
.Alors, la variable aléatoire
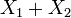 suit la loi normale
suit la loi normale 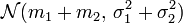 .
.Cette propriété se démontre directement (par convolution), ou indirectement (au moyen des fonctions caractéristiques).
Exemple
On prend ici le gramme comme unité de masse. Si la masse du contenu d'une boîte de conserve suit la loi normale d'espérance 400 et de variance 25, et si celle du contenant suit la loi normale d'espérance 60 et de variance 4, alors (avec l'hypothèse, naturelle, d'indépendance) la masse totale de la boîte de conserve suit la loi normale d'espérance 460 et de variance 29 ; son écart type est environ 5,4 grammes.
Stabilité de la loi normale par la moyenne
Stabilité de la loi normale par la combinaison
Mélange de populations
Il ne faut pas confondre la somme de deux variables gaussiennes indépendantes, qui reste une variable gaussienne, et le mélange de deux populations gaussiennes, qui n'est pas une population gaussienne (voir aussi modèle de mixture gaussienne).
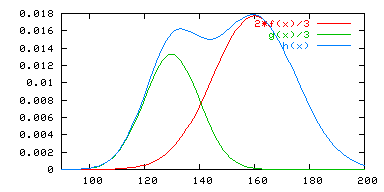
Un mélange constitué de
- 2/3 d'individus dont la taille suit une loi normale de moyenne 160 cm et d'écart type 15 cm, de densité f
- 1/3 d'individus dont la taille suit une loi normale de moyenne 130 cm et d'écart type 10 cm, de densité g
suit une loi de moyenne (2/3)×160+(1/3)×130 = 150 cm, mais non gaussienne, de densité
- h = (2/3) f + (1/3) g.
Sur la représentation graphique de la densité h, on peut apercevoir une double bosse : la distribution est bimodale.
Simulation
Il est possible de simuler, par exemple par ordinateur, un tirage aléatoire dont la loi est normale.
Les logiciels ou les langages de programmation possèdent en général un générateur de nombres pseudo-aléatoires ayant une distribution uniforme sur ]0,1[. On cherche donc une fonction transformant ces nombres. De manière générale, on peut prendre la fonction réciproque de la fonction de répartition : en l'occurrence, si la variable aléatoire U suit la loi uniforme sur ]0,1[, alors la variable aléatoire
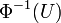 suit la loi normale centrée réduite ; cependant, cette méthode est tout à fait malcommode, faute d'expressions simples des fonctions et
suit la loi normale centrée réduite ; cependant, cette méthode est tout à fait malcommode, faute d'expressions simples des fonctions et 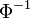 . En revanche, on peut facilement utiliser la méthode décrite ci-dessous.
. En revanche, on peut facilement utiliser la méthode décrite ci-dessous.Cas de la loi normale à une dimension
Pour simuler la loi normale à une dimension (celle qui a été étudiée jusqu'ici), on peut utiliser la méthode de Box-Muller dont voici le principe :
Si U1 et U2 sont des variables aléatoires indépendantes qui suivent la loi uniforme sur ]0,1[, alors on démontre assez aisément que les variables aléatoires :suivent toutes deux la loi normale centrée réduite (et sont indépendantes).
Les variables aléatoires
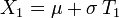 et
et 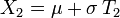 suivent donc toutes deux la loi normale
suivent donc toutes deux la loi normale 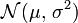 , et indépendamment l'une de l'autre.
, et indépendamment l'une de l'autre.- Voir aussi
- (fr) Générateur de nombres aléatoires gaussiens, message de news:fr.sci.maths, 27 janvier 2000 ;
- (en) Generating Gaussian Random Numbers
Cas de la loi multinormale
La loi multinormale ou loi normale sur
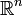 étend la loi normale à un vecteur aléatoire
étend la loi normale à un vecteur aléatoire 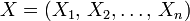 à valeurs dans .
à valeurs dans .Elle est caractérisée par deux paramètres : un vecteur m de moyennes, et une matrice de variance-covariance V (carrée d'ordre n).
Pour simuler une loi multinormale non dégénérée de paramètres m et V, on utilise la méthode suivante :
- Soit T un vecteur aléatoire à n composantes gaussiennes centrées réduites et indépendantes (la loi de T, multinormale, a pour moyenne le vecteur nul et pour matrice de variance-covariance la matrice identité).
- Soit L la matrice résultant de la factorisation de Cholesky de la matrice V.
- Alors, le vecteur aléatoire X = m + LT suit la loi multinormale de moyenne m et de variance-covariance V
- (on convient dans cette dernière relation d'identifier chaque élément de avec la matrice colonne de ses composantes en base canonique).
Le calcul de l'intégrale de Gauss
On trouvera ce calcul (utilisant une intégrale double) dans l'article sur l'intégrale de Gauss.
Annexes
Notes et références
Articles connexes
- Variable gaussienne
- Loi normale multidimensionnelle
- Loi normale asymétrique
- Loi log-normale où ln[X] suit une loi normale .
- Loi stable ou loi de Lévy tronquée, pour lequel la loi normale est un cas particulier pour le cas du paramètre alpha=2.
- Erreur (métrologie)
- Statistiques
- Probabilité
- Loi de probabilité
- loi du χ²
- Loi de Student
- Fonction d'erreur
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Loi de probabilité | Fonctions spéciales



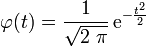
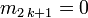
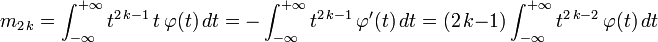
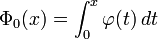
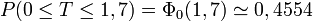
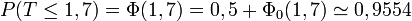
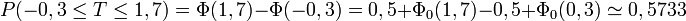
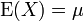 ,
, 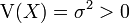
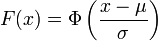
![\ \mathrm{E}[\exp(X)] = \exp\left( \mathrm{E}(X) + \frac{\mathrm{V}(X)}{2}\right) = \exp\left(\mu + \frac{\sigma^2}{2}\right)](/pictures/frwiki/51/30291b6746a216f9aea6087c3440c29c.png)
![\ \mathrm{V}[\exp(X)] = \exp( 2 \mathrm{E}(X) + \mathrm{V}(X)) \left[\exp( \mathrm{V}(X)) - 1\right] = \exp( 2 \mu + \sigma^2) (\exp(\sigma^2) - 1)](/pictures/frwiki/102/f7f3fc868964a3688295009b3f518506.png)
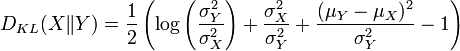
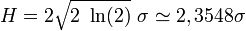
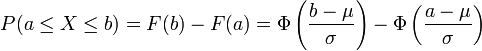
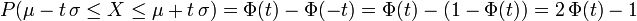

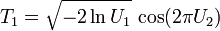
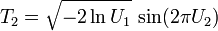
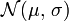 , mais cette notation, qui n'est pas cohérente avec la notation habituelle de la loi (multi-)normale sur
, mais cette notation, qui n'est pas cohérente avec la notation habituelle de la loi (multi-)normale sur 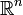 , tend à céder la place à la notation "classique"
, tend à céder la place à la notation "classique" Wikimedia Foundation. 2010.