- NP-difficile
-
Théorie de la complexité des algorithmes
La théorie de la complexité des algorithmes étudie formellement la difficulté intrinsèque des problèmes algorithmiques.
Sommaire
Histoire
Dans les années 1960 et au début des années 1970, alors qu'on en était à découvrir des algorithmes fondamentaux (tris tels que quicksort, arbres couvrants tels que les algorithmes de Kruskal ou de Prim), on ne mesurait pas leur efficacité. On se contentait de dire : « cet algorithme (de tri) se déroule en 6 secondes avec un tableau de 50 000 entiers choisis au hasard en entrée, sur un ordinateur IBM 360/91. Le langage de programmation PL/I a été utilisé avec les optimisations standards. » (cet exemple est imaginaire)
Une telle démarche rendait difficile la comparaison des algorithmes entre eux. La mesure publiée était dépendante du processeur utilisé, des temps d'accès à la mémoire vive et de masse, du langage de programmation et du compilateur utilisé, etc.
Une approche indépendante des facteurs matériels était nécessaire pour évaluer l'efficacité des algorithmes. Donald Knuth fut un des premiers à l'appliquer systématiquement dès les premiers volumes de sa série The Art of Computer Programming. Il complétait cette analyse de considérations propres à la théorie de l'information : celle-ci par exemple, combinée à la formule de Stirling, montre qu'il ne sera pas possible d'effectuer un tri général (c'est-à-dire uniquement par comparaisons) de N éléments en un temps croissant moins rapidement avec N que N ln N sur une machine algorithmique (à la différence peut-être d'un ordinateur quantique).
Signalons également deux autres directions alternatives: la complexité en moyenne des algorithmes, dont le calcul passe souvent par des techniques sophistiquées d'analyse mathématique, et la complexité amortie des structures de données, qui consiste à déterminer le coût de suites d'opérations.
Généralités
Présentation
La théorie de la complexité s'attache à connaître la difficulté (ou la complexité) d'une réponse par algorithme à un problème, dit algorithmique, posé de façon mathématique. Pour pouvoir la définir, il faut présenter ces trois concepts que sont les problèmes algorithmiques, les réponses algorithmiques aux problèmes, la complexité des problèmes algorithmiques.
Problème algorithmique
Un problème algorithmique est un problème posé de façon mathématique, c'est-à-dire qu'il est énoncé rigoureusement dans le langage des mathématiques – le mieux étant d'utiliser le calcul des prédicats. Il comprend des hypothèses, des données[1] et une question. On distingue deux types de problèmes :
- les problèmes de décision : ils posent une question dont la réponse est oui ou non ;
- les problèmes d'existence ou de recherche d'une solution : ils comportent une question ou plutôt une injonction de la forme « trouver un élément tel que …» dont la réponse consiste à fournir un tel élément.
Réponse algorithmique
Dans chaque catégorie de problèmes ci-dessus, on dit qu'un problème a une réponse algorithmique si sa réponse peut être fournie par un algorithme. Un problème est décidable s'il s'agit d'un problème de décision – donc d'un problème dont la réponse est soit oui soit non – et si sa réponse peut être fournie par un algorithme. Symétriquement, un problème est calculable s'il s'agit d'un problème d'existence et si l'élément calculé peut être fourni par un algorithme. La théorie de la complexité ne couvre que les problèmes décidables ou calculables et cherche à évaluer les ressources – temps et espace mémoire – mobilisées pour obtenir algorithmiquement la réponse.
Complexité d'un problème algorithmique
La théorie de la complexité vise à savoir si la réponse à un problème peut être donnée très efficacement, efficacement ou au contraire être inatteignable en pratique (et en théorie), avec des niveaux intermédiaires de difficulté entre les deux extrêmes ; pour cela, elle se fonde sur une estimation – théorique – des temps de calcul et des besoins en mémoire informatique. Dans le but de mieux comprendre comment les problèmes se placent les uns par rapport aux autres, la théorie de la complexité établit des hiérarchies de difficultés entre les problèmes algorithmiques, dont les niveaux sont appelés des « classes de complexité ». Ces hiérarchies comportent des ramifications, suivant que l'on considère des calculs déterministes – l'état suivant du calcul est « déterminé » par l'état courant – ou non déterministes.
De l'existence à la décision
Un problème d'existence peut être transformé en un problème de décision équivalent. Par exemple, le problème du voyageur de commerce, qui cherche, dans un graphe, dont les arêtes sont étiquetées par des coûts, à trouver un cycle, de coût minimum, passant une fois par chaque sommet, peut s'énoncer en un problème de décision comme suit : Existe-t-il un cycle passant une fois par chaque sommet tel que tout autre cycle passant par tous les sommets ait un coût supérieur. L'équivalence de ces deux problèmes suppose que la démonstration d'existence repose sur un argument constructif[2], c'est-à-dire, par exemple dans le cas du voyageur de commerce, fournit effectivement un cycle de coût minimum dans le cas où on a montré qu'un cycle de coût minimum existe. Le problème de l'existence d'un cycle de coût minimum est équivalent au problème du voyageur de commerce, au sens où si l'on sait résoudre efficacement l'un, on sait aussi résoudre efficacement l'autre. Dans la suite de cet article, nous ne parlerons donc que de problème de décision.
Modèle de calcul
L'analyse de la complexité est étroitement associée à un modèle de calcul. L'un des modèles de calcul les plus utilisés est celui des machines abstraites dans la lignée du modèle proposé par Alan Turing en 1936.
Article connexe : Machine de Turing.Les deux modèles les plus utilisés en théorie de la complexité sont :
- La machine de Turing ;
- La machine RAM (Random Access Machine).
Dans ces deux modèles de calcul, un calcul est constitué d'étapes élémentaires ; à chacune de ces étapes, pour un état donné de la mémoire de la machine, une action élémentaire est choisie dans un ensemble d'actions possibles. Les machines déterministes sont telles que chaque action possible est unique, c'est-à-dire que l'action à effectuer est dictée de façon unique par l'état courant de celle-ci. S'il peut y avoir plusieurs choix possibles d'actions à effectuer, la machine est dite non déterministe. Il peut sembler naturel de penser que les machines de Turing non déterministes sont plus puissantes que les machines de Turing déterministes, autrement dit qu'elles peuvent résoudre en un temps donné des problèmes que les machines déterministes ne savent pas résoudre dans le même temps[3].
D'autres modèles de calcul qui permettent d'étudier la complexité s'appuient sur :
- les fonctions récursives dues à Kleene ;
- le lambda-calcul ;
- les automates cellulaires ;
- la logique linéaire.
Complexité en temps et en espace
Sans nuire à la généralité on peut supposer que les problèmes que nous considérons n'ont qu'une donnée. Cette donnée a une taille qui est un nombre entier naturel. La façon dont cette taille est mesurée joue un rôle crucial dans l'évaluation de la complexité de l'algorithme. Ainsi si la donnée est elle-même un nombre entier naturel, sa taille peut être appréciée de plusieurs façons : on peut dire que la taille de l'entier p vaut p, mais on peut aussi dire qu'elle vaut log(p) parce que l'entier a été représenté en numération binaire ou décimale ce qui raccourcit la représentation des nombres, ainsi 1 024 peut être représenté avec seulement onze chiffres binaires et quatre chiffres décimaux et donc sa taille est 11 ou 4 et non pas de l'ordre de 1 000. Le but de la complexité est de donner une évaluation du temps de calcul ou de l'espace de calcul nécessaire en fonction de cette taille, qui sera notée n. L'évaluation des ressources requises permet de répartir les problèmes dans des classes de complexité.
Pour les machines déterministes, on définit la classe TIME(t(n)) des problèmes qui peuvent être résolus en temps t(n). C'est-à-dire pour lesquels il existe au moins un algorithme sur une machine déterministe résolvant le problème en temps t(n). Le temps est le nombre de transitions sur machine de Turing ou le nombre d’opérations sur machine RAM, mais en fait ce temps n'est pas une fonction précise, mais c'est un ordre de grandeur, on parle aussi d'évaluation asymptotique, ainsi pour un temps qui s'évalue par un polynôme ce qui compte c'est le degré du polynôme, si ce degré est 2, on dira que l'ordre de grandeur est en O(n²), que la complexité est quadratique et que le problème appartient à la classe TIME(n²).
Notation Type de complexité O(1) complexité constante (indépendante de la taille de la donnée) O(log(n)) complexité logarithmique O(n) complexité linéaire O(n.log(n)) complexité quasi-linéaire O(n2) complexité quadratique O(n3) complexité cubique O(np) complexité polynomiale O(nlog(n)) complexité quasi-polynomiale O(2n) complexité exponentielle O(n!) complexité factorielle - Les quatre familles de classes de complexité en temps et en espace
Suivant qu'il s'agit de temps et d'espace, de machine déterministes ou non déterministes, on distingue quatre classes de complexité.
- TIME(t(n)) est la classe des problèmes de décision qui peuvent être résolus en temps de l'ordre de grandeur de t(n) sur une machine déterministe.
- NTIME(t(n)) est la classe des problèmes de décision qui peuvent être résolus en temps de l'ordre de grandeur de t(n) sur une machine non déterministe.
- SPACE(s(n)) est la classe des problèmes de décision qui requièrent pour être résolus un espace de l'ordre de grandeur de s(n) sur une machine déterministe.
- NSPACE(s(n)) est la classe des problèmes de décision qui requièrent pour être résolus un espace de l'ordre de grandeur de s(n) sur une machine non déterministe.
Classes de complexité
Dans ce qui suit nous allons définir quelques classes de complexité parmi les plus étudiées en une liste qui va des plus basses aux plus hautes, c'est-à-dire de la plus basse complexité à la plus haute complexité. Il faut cependant avoir à l'esprit que ces classes ne sont pas totalement ordonnées. Commençons par la classe constituée des problèmes les plus simples, à savoir ceux dont la réponse peut être donnée en temps constant. Par exemple, la question de savoir si un nombre entier est positif peut être résolue sans vraiment calculer, donc en un temps indépendant de la taille du nombre entier, c'est la plus basse des classes de problèmes. La classe des problèmes linéaires est celle qui contient les problèmes qui peuvent être décidés en un temps qui est une fonction linéaire de la taille de la donnée. Comme la complexité est un ordre de grandeur, cela signifie que le temps de décision est proportionnel à la taille de la donnée. Il s'agit des problèmes qui sont en O(n).
Souvent au lieu de dire « un problème est dans la classe C » on dit plus simplement « le problème est dans C ».
Classes L et NL
Un problème de décision qui peut être résolu par un algorithme déterministe en espace logarithmique par rapport à la taille de l'instance est dans L. Avec les notations introduites plus haut, L = SPACE(log(n)). La classe NL s'apparente à la classe L mais sur une machine non déterministe (NL = NSPACE(log(n)). Par exemple savoir si un élément appartient à un tableau trié peut se faire en espace logarithmique.
Classe P
Un problème de décision est dans P s'il peut être décidé sur une machine déterministe en temps polynomial par rapport à la taille de la donnée. On qualifie alors le problème de polynomial, c'est un problème de complexité O(nk) pour un certain k.
Un exemple de problème polynomial est celui de la connexité dans un graphe. Étant donné un graphe à s sommets (on considère que la taille de la donnée, donc du graphe est son nombre de sommets), il s'agit de savoir si toutes les paires de sommets sont reliées par un chemin. Un algorithme de parcours en profondeur construit un arbre couvrant du graphe à partir d'un sommet. Si cet arbre contient tous les sommets du graphe, alors le graphe est connexe. Le temps nécessaire pour construire cet arbre est en au plus c.s² (où c est une constante), donc le problème est dans la classe P.
On admet, en général, que les problèmes dans P sont ceux qui sont facilement solubles[4].
Classe NP et classe Co-NP (complémentaire de NP)
La classe NP des problèmes Non-déterministes Polynomiaux réunit les problèmes de décision qui peuvent être décidés sur une machine non déterministe en temps polynomial. De façon équivalente, c'est la classe des problèmes qui admettent un algorithme polynomial capable de tester la validité d'une solution du problème, on dit aussi capable de construire un certificat. Intuitivement, les problèmes dans NP sont les problèmes qui peuvent être résolus en énumérant l'ensemble des solutions possibles et en les testant à l'aide d'un algorithme polynomial.
Par exemple, la recherche de cycle hamiltonien dans un graphe peut se faire à l'aide de deux algorithmes :
- le premier engendre l'ensemble des cycles (en temps exponentiel, classe EXPTIME, voir ci-dessous) ;
- le second teste les solutions (en temps polynomial).
Ce problème est donc de la classe NP.
La classe duale de la classe NP, quand la réponse est non, est appelée Co-NP.
Classe PSPACE
La classe PSPACE est celle des problèmes décidables par une machine déterministe en espace polynomial par rapport à la taille de sa donnée. On peut aussi définir la classe NSPACE ou NPSPACE des problèmes décidables par une machine non déterministe en espace polynomial par rapport à la taille de sa donnée. Par le théorème de Savitch, on a PSPACE = NPSPACE, c'est pourquoi on ne rencontre guère les notations NSPACE ni NPSPACE.
Classe EXPTIME
La classe EXPTIME rassemble les problèmes décidables par un algorithme déterministe en temps exponentiel par rapport à la taille de son instance.
Classe NC (Nick's Class)
La classe NC est la classe des problèmes qui peuvent être résolus en temps poly-logarithmique (c'est à dire résolus plus rapidement qu'il ne faut de temps pour lire séquentiellement leurs entrées) sur une machine parallèle ayant un nombre polynomial (c'est à dire raisonnable) de processeurs.
Intuitivement, un problème est dans NC s'il existe un algorithme pour le résoudre qui peut être parallélisé et qui gagne à l'être. C'est à dire, si la version parallèle de l'algorithme (s'exécutant sur plusieurs processeurs) est significativement plus efficace que la version séquentielle.
Par définition, NC est un sous ensemble de la classe P (NC
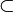 P) car une machine parallèle peut être simulée par un machine séquentielle.
P) car une machine parallèle peut être simulée par un machine séquentielle.Mais on ne sait pas si P
NC (et donc si NC = P). On conjecture que non, en supposant qu'il existe dans P des problèmes dont les solutions sont intrinsèquement non parallélisables.Inclusions des classes
On a les inclusions :
- P
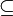 NP, et symétriquement P Co-NP
NP, et symétriquement P Co-NP - NP PSPACE = NPSPACE, et Co-NP PSPACE.
En effet, un problème polynomial peut se résoudre en engendrant une solution et en la testant à l'aide d'un algorithme polynomial. Tout problème dans P est ainsi dans NP.
Problèmes C-complets ou C-difficiles
Définition
Soit C une classe de complexité (comme P, NP, etc.). On dit qu'un problème est C-complet ou C-difficile si ce problème est au moins aussi difficile que tous les problèmes dans C. Formellement on définit une notion de réduction : soient ∏ et ∏' deux problèmes ; une réduction de ∏' à ∏ est un algorithme (ou une machine) d'une complexité qu'on sait être inférieure à celle de la classe C transformant toute instance de ∏' en une instance de ∏. Ainsi, si l'on a un algorithme pour résoudre ∏, on sait aussi résoudre ∏' , mais de plus, si la complexité de ∏ est au moins celle de la classe C, on peut dire que ∏ est donc au moins aussi difficile à résoudre que ∏' .
∏ est alors C-complet ou C-difficile si pour tout problème ∏' de C, ∏' se réduit à ∏.
Pour les problèmes NP-complet ou NP-difficile on s'autorise uniquement des réductions dans P, c'est-à-dire que l'algorithme qui calcule le passage d'une instance de ∏' à une instance de ∏ est polynomial (voir Réduction polynomiale). Quand on parle de problèmes P-complet ou P-difficile on s'autorise uniquement des réductions dans LOGSPACE.
On qualifie de NP-complet les problèmes décisionnels, c'est-à-dire que la réponse est de type binaire (oui/non, vrai/faux, 1/0,...). On qualifie de NP-difficile les problèmes d'optimisation, c'est-à-dire que la réponse est de type numérique. A un problème d'optimisation NP-difficile, est associé un problème de décision NP-complet, mais dire qu'un problème NP-difficile est aussi NP-complet est un abus de langage car il n'y a pas de comparaison possible.
Réduction de problèmes et problèmes NP-complets
Pour montrer qu'un problème ∏ est C-difficile pour une classe C donnée, il y a deux façons de procéder : ou bien montrer que tout problème de C se réduit à ∏, ou bien montrer qu’un problème C-difficile se réduit à ∏. Par exemple, démontrons que le problème de la recherche de circuit hamiltonien dans un graphe orienté est NP-Complet.
- Le problème est dans NP, car on peut trouver un algorithme pour le résoudre à l'aide d'une machine non déterministe, par exemple en engendrant (de façon non déterministe) un circuit, puis en testant au final s'il est hamiltonien.
- On sait que le problème de la recherche d'un cycle hamiltonien dans un graphe non orienté est NP-difficile. Or un graphe non orienté peut se transformer en un graphe orienté en créant deux arcs opposés pour chaque arête. Il est donc possible de ramener le problème connu, NP-difficile, à savoir chercher un cycle hamiltonien dans un graphe non orienté, au problème que nous voulons classer, à savoir chercher un circuit hamiltonien dans un graphe orienté. Le problème de l'existence d'un circuit hamiltonien est donc NP-difficile.
Article détaillé : Réduction polynomiale.- Théorème de Cook-Levin
Le théorème de Cook-Levin (dû à Stephen Cook et à Leonid Levin) énonce qu'il existe un problème NP-complet, plus précisément, Cook a montré que le problème SAT est NP-Complet.
- Problème NP-Complets célèbres
- Problème SAT et variante 3SAT (mais 2SAT est polynomial) ; il existe des logiciels (dits SAT solvers) spécialisés dans la résolution performante de problèmes SAT ;
- Problème du voyageur de commerce
- Problème du cycle hamiltonien
- Problème de la clique maximum
- Problèmes de colorations de graphes
- Problème d'ensemble dominant dans un graphe
- Problème de couverture de sommets dans un graphe
- Problème du sac à dos.
- Listes de problèmes NP-complets sur Wikipédia
Le problème ouvert P=NP
On a clairement P ⊆ NP car un algorithme déterministe est un algorithme non déterministe particulier, ce qui, dit en mots plus simples, signifie que si une solution peut être calculée en temps polynomial, alors elle peut être vérifiée en temps polynomial. En revanche, la réciproque : NP ⊆ P, qui est la véritable difficulté de l'égalité P = NP est un problème ouvert central d'informatique théorique. Il a été posé en 1970 indépendamment par Stephen Cook et Leonid Levin[5]. La plupart des spécialistes conjecturent que les problèmes NP-complets ne sont pas solubles en un temps polynomial. À partir de là, plusieurs approches ont été tentées.
- Des algorithmes d'approximation (ou heuristiques) permettent de trouver des solutions approchées de l'optimum en un temps raisonnable pour un certain nombre de programmes. Dans le cas d'un problème d'optimisation on trouve généralement une réponse correcte, sans savoir s'il s'agit de la meilleure solution.
- Des algorithmes stochastiques : en utilisant des nombres aléatoires on peut «forcer» un algorithme à ne pas utiliser les cas les moins favorables, l'utilisateur devant préciser une probabilité maximale admise que l'algorithme fournisse un résultat erroné.
- Des algorithmes par séparation et évaluation permettent de trouver la ou les solutions exactes. Le temps de calcul n'est bien sûr pas borné polynomialement mais, pour certaines classes de problèmes, il peut rester modéré pour des instances relativement grandes.
- L'approche de la complexité paramétrée consiste à identifier un paramètre qui, dans le cas où il reste petit, permet de résoudre rapidement le problème. En particulier les algorithmes FPT en un paramètre k permettent de résoudre un problème en temps proportionnel au produit d'une fonction quelconque de k et d'un polynôme en la taille de l'instance, ce qui fournit un algorithme polynomial quand k est fixé.
- On peut restreindre la classe des problèmes considérés à une sous-classe suffisante, mais plus facile à résoudre.
Problèmes apparentés
- On ne sait pas si L = NL.
- On sait que PSPACE = NPSPACE.
- Pour résumer, on a L ⊆ NL ⊆ P ⊆ NP ⊆ PSPACE = NPSPACE ⊆ EXPTIME ⊆ NEXPTIME.
- On sait de plus que NL ⊊ PSPACE. Donc deux classes au moins entre NL et PSPACE ne sont pas égales. On sait également que P ≠ EXPTIME.
Notes
- ↑ Les données sont aussi appelées des instances.
- ↑ En fait existence constructive et réponse par algorithme vont de paire et cette exigence est tout-à-fait naturelle.
- ↑ À noter qu'en théorie de la complexité on parle toujours d'ordre de grandeur.
- ↑ Il s'agit évidemment d'une convention, car un problème de la complexité
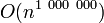 ne peut pas être considéré comme « facilement » résoluble.
ne peut pas être considéré comme « facilement » résoluble. - ↑ Celui qui arrivera à décider si P et NP sont différents ou égaux recevra le prix Clay de plus de 1 000 000 $. Ce problème fait partie des problèmes du prix du millénaire qui comptent 7 défis mathématiques réputés insurmontables.
Bibliographie
- (en) Patrick Blackburn, Maarten de Rijke et Yde Venema, Modal Logic, 2001 [détail des éditions], annexe C « A Computational Toolkit », pp. 504-515.
- (en) Michael R. Garey, David S. Johnson, Computers and Intractability : A guide to the theory of NP-completeness, W.H. Freeman & Company, 1979. ISBN 0716710455.
- Pierre Wolper, Introduction à la calculabilité, Dunod, 2001. ISBN 2100048538.
- Richard Lassaigne, Michel de Rougemont, Logique et Complexité, Hermes, 1996. ISBN 2866014960.
- (en) Christos Papadimitriou, Computational Complexity, Addison-Wesley, 1993. ISBN 0201530821.
Voir aussi
Articles connexes
- Complexité, article genéral sur la complexité,
- Complexité de Kolmogorov,
- Explosion combinatoire
- Fonctions récursives,
- Machine de Turing non déterministe,
- Réduction polynomiale.
Liens et documents externes
 Portail de l’informatique
Portail de l’informatique Portail des mathématiques
Portail des mathématiques
Catégories : Problèmes du prix du millénaire | Algorithmique | Informatique théorique | Logique mathématique | Calculabilité
Wikimedia Foundation. 2010.