- Quicksort
-
Tri rapide
Le tri rapide (en anglais quicksort) est une méthode de tri inventée par C.A.R. Hoare en 1961 et fondée sur la méthode de conception diviser pour régner. Il peut être implémenté sur un tableau (tri sur place) ou sur des listes ; son utilisation la plus répandue concerne tout de même les tableaux.
Le Quicksort est un tri dont la complexité moyenne est en
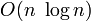 , mais dont la complexité dans le pire des cas est O(n2). Malgré ce désavantage théorique, c'est en pratique un des tris sur place le plus rapide pour des données réparties aléatoirement. Les entrées donnant lieu au comportement quadratique dépendent de l'implémentation de l'algorithme, mais sont souvent (si l'implémentation est maladroite) les entrées déjà presque triées. Il sera plus avantageux alors d'utiliser le tri par insertion ou l'algorithme Smoothsort.
, mais dont la complexité dans le pire des cas est O(n2). Malgré ce désavantage théorique, c'est en pratique un des tris sur place le plus rapide pour des données réparties aléatoirement. Les entrées donnant lieu au comportement quadratique dépendent de l'implémentation de l'algorithme, mais sont souvent (si l'implémentation est maladroite) les entrées déjà presque triées. Il sera plus avantageux alors d'utiliser le tri par insertion ou l'algorithme Smoothsort.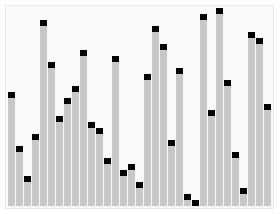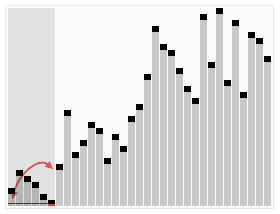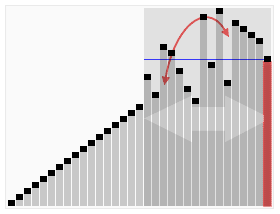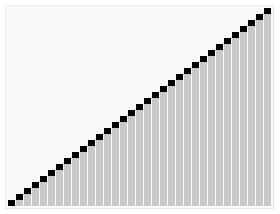 Quicksort en action sur une liste de nombre aléatoires Les lignes horizontales sont les valeurs des pivots.
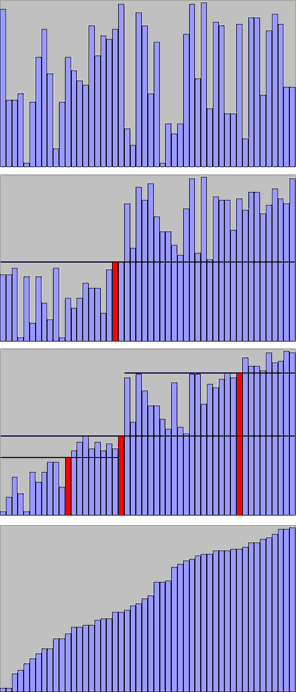
Quicksort en action sur une liste de nombre aléatoires Les lignes horizontales sont les valeurs des pivots.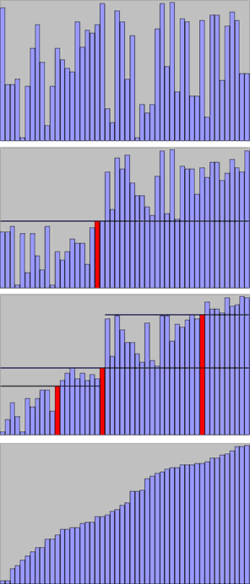 Autre illustration de l'algorithme de tri rapide (Quicksort).
Autre illustration de l'algorithme de tri rapide (Quicksort).
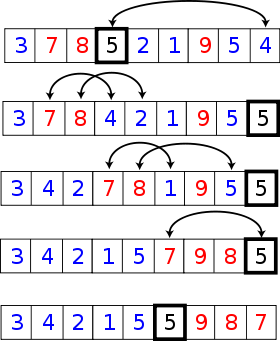 Exemple de tri d'une petite liste de nombres
Exemple de tri d'une petite liste de nombresSommaire
Performance et algorithme
La méthode consiste à placer un élément du tableau (appelé pivot) à sa place définitive, en permutant tous les éléments de telle sorte que tous ceux qui lui sont inférieurs soient à sa gauche et que tous ceux qui lui sont supérieurs soient à sa droite. Cette opération s'appelle le partitionnement. Pour chacun des sous-tableaux, on définit un nouveau pivot et on répète l'opération de partitionnement. Ce processus est répété récursivement, jusqu'à ce que l'ensemble des éléments soit trié.
tri_rapide(tableau t, entier premier, entier dernier) début si premier < dernier alors pivot <- choix_pivot(t,premier,dernier) pivot <- partitionner(t,premier,dernier,pivot) tri_rapide(t,premier,pivot-1) tri_rapide(t,pivot+1,dernier) finsi finSi le pivot est correctement choisi à chaque étape, c'est une des méthodes de tri les plus rapides dans le cas moyen (entrée triée dans un ordre aléatoire uniformément distribué), avec une complexité algorithmique en O(n ln(n)). Cette complexité peut se dégrader en O(n²) dans le pire des cas, qui se trouve être celui où les éléments sont déjà dans l'ordre pour certaines implémentations. Comme ce pire cas est finalement assez courant (tri de listes quasiment déjà triées), on se ramène parfois au cas moyen en appliquant une permutation aléatoire uniformément distribuée sur les entrées ou bien on choisit aléatoirement le pivot.
Dans la pratique, pour les partitions avec un faible nombre d'éléments (jusqu'à environ 15 éléments), on a souvent recours à un tri par insertion qui se révèle plus efficace que le tri rapide.
Grâce à ses bonnes performances et à son implémentation facile (en première approche), quicksort est l'un des algorithmes de tri les plus répandus.
Le tri rapide n'est pas un tri stable car il ne préserve pas nécessairement l'ordre des éléments possédant une clef de tri identique. On peut cependant compenser ce problème en ajoutant l'information sur la position de départ à chaque élément et en ajoutant un test sur la position en cas d'égalité sur la clef de tri.
Le problème le plus important est le choix du pivot. Une implémentation du tri rapide qui ne choisit pas adéquatement le pivot sera très inefficace pour certaines entrées. Par exemple, si le pivot est toujours le plus petit élément de la liste, QuickSort sera aussi efficace qu'un tri par sélection, c'est-à-dire de performance O(n²).
Enfin, un problème lié est le niveau de récursion: dans le pire des cas il peut être linéaire: la pile requiert un espace supplémentaire de O(n).
Choisir un meilleur pivot
Le pire cas du tri rapide n'est pas qu'un problème théorique. Quand il est utilisé avec des services Web, par exemple, il est possible pour un attaquant d'utiliser volontairement des données conduisant au pire cas de performance et de provoquer un ralentissement de la machine attaquée voire un arrêt intempestif du programme par débordement de pile.
Des données triées ou partiellement triées sont relativement fréquentes dans la pratique et l'implémentation naïve du tri rapide qui choisit le premier élément comme pivot conduit à une profondeur de récursivité linéaire. Pour résoudre ce problème, on peut utiliser l'élément du milieu du tableau. Cette façon de faire fonctionne bien pour les listes déjà triées ou à l'envers mais facilite la mise au point d'attaques.
Une meilleure optimisation peut consister par exemple à sélectionner le pivot aléatoirement entre 2 valeurs au centre, pour éviter que les pirates puissent prévoir la réaction de votre méthode de tri en fonction des données à trier.
Si le nombre d'éléments est suffisamment grand pour le justifier, on peut envisager de rechercher la valeur médiane de la liste, mais en pratique cela en vaut rarement la peine.
Autres optimisations
Une optimisation utile, déjà mentionnée plus haut, consiste à changer d'algorithme lorsque le sous-ensemble de données non encore trié devient petit. La taille optimale des sous-listes est d'environ 15 éléments. On peut alors utiliser le tri par sélection ou le tri par insertion. Le tri par sélection ne sera sûrement pas efficace pour un grand nombre de données, mais il est souvent plus rapide que le tri rapide sur des listes courtes, du fait de sa plus grande simplicité.
Robert Sedgewick 1978 suggère une amélioration (appelée Sedgesort) lorsqu'on utilise un tri simplifié pour les petites sous-listes : on peut diminuer le nombre d'opérations nécessaires en différant le tri des petites sous-listes après la fin du tri rapide, après quoi on exécute un tri par insertion sur le tableau entier.
LaMarca et Ladner 1997 ont étudié « l'influence des caches sur les performances des tris », un problème prépondérant sur les architectures récentes dotées de hiérarchies de caches avec des temps de latence élevés lors des échecs de recherche de données dans les caches. Ils concluent que, bien que l'optimisation de Sedgewick diminue le nombre d'instructions exécutées, elle diminue aussi le taux de succès des caches à cause de la plus large dispersion des accès à la mémoire (lorsque l'on fait le tri par insertion à la fin sur tout le tableau et non au fur et à mesure), ce qui entraine une dégradation des performances du tri. Toutefois l'effet n'est pas dramatique et ne devient significatif qu'avec des tableaux de plus de 4 millions d'éléments de 64 bits. Cette étude est citée par Musser.
Étant donné que le tri rapide nécessite davantage de mémoire pour implémenter la récursion, des variantes non récursives du tri rapide ont été écrites. Elles ont l'avantage d'utiliser la mémoire de façon plus prévisible, indépendante des données à trier, au prix d'une très nette augmentation de la complexité du code. Les programmeurs voulant utiliser un tri itératif peuvent envisager d'utiliser Introsort, le tri par tas et Smoothsort.
Une autre solution simple pour réduire l'utilisation de la mémoire par un tri rapide utilise une récursion pour la plus petite des sous-listes à trier, et une récursion finale (qui peut donc être transformée en une boucle) pour la plus grande. Ceci limite la quantité de mémoire utilisée a O(log n). Par exemple:
tri_rapide(a, gauche, droite) tant que droite-gauche+1 > 1 sélectionner une valeur de pivot a[pivotIndex] pivotNewIndex := partition(a, gauche, droit, pivotIndex) si pivotNewIndex-1 - gauche < droit - (pivotNewIndex+1) tri_rapide(a, gauche, pivotNewIndex-1) gauche := pivotNewIndex+1 sinon tri_rapide(a, pivotNewIndex+1, droit) droit := pivotNewIndex-1 fin_si fin_tant_queAlgorithmes de tri en n.log(n)
Une variante du tri rapide devenu largement utilisée est introsort alias introspective sort (Musser 1997). Elle démarre avec un tri rapide puis utilise un tri par tas lorsque la profondeur de récursivité dépasse une certaine limite prédéfinie. Elle permet d'éviter la complexité du choix d'un bon pivot tout en garantissant une exécution en O(n log n).
Sinon, on peut utiliser à la place du tri rapide un tri par tas pur. Le tri par tas est en moyenne plus lent que le tri rapide mais son plus mauvais comportement est en O(n log n), aussi il est préféré lorsque la complexité maximale doit être garantie ou lorsque l'on soupçonne que le comportement en O(n²) du tri rapide sera souvent atteint. Le tri par tas a aussi l'avantage de requérir un espace mémoire additionnel constant tandis que la meilleure variante du tri rapide utilise O(log n) d'espace mémoire additionnel.
Un inconvénient majeur du tri par tas est que si la liste est déjà triée, elle sera mélangée par l'algorithme avant d'être retriée. L'algorithme Smoothsort a pour but de pallier ce problème.
Relation avec le tri par sélection
Un algorithme de sélection simple, qui choisit le plus petit des éléments d'une liste, fonctionne globalement de la même manière que le quicksort, la différence étant qu'au lieu d'être appelé récursivement sur les deux sous-listes, il n'est appelé récursivement que sur la sous-liste contenant l'élément recherché. Cette petite différence fait passer la complexité moyenne à un niveau linéaire, en O(n). Une variante de cet algorithme trouve la valeur médiane à chaque étape, ce qui réduit également le temps d'exécution dans le pire des cas à O(n).
Implémentations
Pascal
Une mise en œuvre simple de QuickSort sur un tableau d'entiers en Pascal :
const MAX_VAL = 200; type tab_entier = array [1..MAX_VAL] of integer; procedure tri_rapide(deb, fin : integer ; var t : tab_entier); var i, p : integer; mid, aux : integer; begin (* si fin > deb alors le tableau nécessite d'être trié*) if (fin > deb) then begin (* choisir le milieu du tableau comme pivot *) mid := (deb + fin) div 2; (* mettre l'élément pivot au début afin de pouvoir parcourir le tableau en continu. *) aux := t[mid]; t[mid] := t[deb]; t[deb] := aux; (* parcourir le tableau tout en amenant les éléments infèrieurs à l'élément pivot au début de la plage *) p := deb; for i:=deb+1 to fin do begin if (t[i] < t[deb]) then begin p := p + 1; aux := t[i]; t[i] := t[p]; t[p] := aux; end; end; (* mettre le pivot à la position adéquate càd à la suite des éléments qui lui sont inférieurs *) aux := t[p]; t[p] := t[deb]; t[deb] := aux; tri_rapide(deb, p - 1, t); (* trie le sous tableau à gauche *) tri_rapide(p + 1, fin, t); (* trie le sous tableau à droite *) end; end;
Java
Une mise en œuvre simple de QuickSort (d'une manière récursive) sur un tableau d'entiers en Java :
public static void quicksort(int [] tableau, int début, int fin) { if (début < fin) { int indicePivot = partition(tableau, début, fin); quicksort(tableau, début, indicePivot-1); quicksort(tableau, indicePivot+1, fin); } } public static int partition (int [] t, int début, int fin) { int valeurPivot = t[début]; int d = début+1; int f = fin; while (d < f) { while(d < f && t[d] <= valeurPivot) d++; while(d < f && t[f] >= valeurPivot) f--; if(d < f) { int temp = t[d]; t[d]= t[f]; t[f] = temp; } } if (t[d] > valeurPivot) d--; t[début] = t[d]; t[d] = valeurPivot; return d; }
C
Une mise en œuvre simple de QuickSort sur un tableau d'entiers en C :
int partitionner(int *tableau, int p, int r) { int pivot = tableau[p], i = p-1, j = r+1; int temp; while (1) { do j--; while (tableau[j] > pivot); do i++; while (tableau[i] < pivot); if (i < j) { temp = tableau[i]; tableau[i] = tableau[j]; tableau[j] = temp; } else return j; } return j; } void quickSort(int *tableau, int p, int r) { int q; if (p < r) { q = partitionner(tableau, p, r); quickSort(tableau, p, q); quickSort(tableau, q+1, r); } }
Python
Ici, nous avons une implémentation en Python, qui utilise un meilleur partitionnement :
def partition(array, start, end, compare): while start < end: # au début de cette boucle, notre élément permettant la partition # est à la valeur 'start' while start < end: if compare(array[start], array[end]): (array[start], array[end]) = (array[end], array[start]) break end = end - 1 # au début de cette boucle, notre élément permettant la partition # est à la valeur 'end' while start < end: if compare(array[start], array[end]): (array[start], array[end]) = (array[end], array[start]) break start = start + 1 return start def quicksort(array, compare=lambda x, y: x > y, start=None, end=None): """Le plus rapide des tris par échanges pour la plupart des usages.""" if start is None: start = 0 if end is None: end = len(array) if start < end: i = partition(array, start, end-1, compare) quicksort(array, compare, start, i) quicksort(array, compare, i+1, end)
Haskell
Une version très courte écrite en langage fonctionnel Haskell :
quicksort :: (Ord a) => [a] -> [a] quicksort [] = [] quicksort (pivot:rest) = (quicksort [y| y<-rest, y<pivot]) ++ [pivot] ++ (quicksort [y| y<-rest,y>=pivot])
OCaml
Une version similaire, en OCaml :
let rec qsort = function | [] -> [] | pivot::reste -> let (petits, grands) = List.partition ((>) pivot) reste in qsort petits @ [pivot] @ qsort grands (* Type de List.partition : ('a -> bool) -> 'a list -> 'a list * 'a list *)
Prolog
Enfin, dans le langage de programmation logique Prolog :
qsort([X|L],R,R0) :- partition(L,X,L1,L2), qsort(L2,R1,R0), qsort(L1,R,[X|R1]). qsort([],R,R). partition([Y|L],X,[Y|L1],L2) :- Y=<X, partition(L,X,L1,L2). partition([Y|L],X,L1,[Y|L2]) :- Y>X, partition(L,X,L1,L2). partition([],_,[],[]).
Références
- Hoare, C. A. R. « Partition: Algorithm 63, » « Quicksort: Algorithm 64, » and « Find: Algorithm 65. » Comm. ACM 4, 321-322, 1961
- R. Sedgewick. Implementing quicksort programs, Communications of the ACM, 21(10):847857, 1978.
- David Musser. Introspective Sorting and Selection Algorithms, Software Practice and Experience vol 27, number 8, pages 983-993, 1997
- A. LaMarca and R. E. Ladner. « The Influence of Caches on the Performance of Sorting. » Proceedings of the Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, 1997. pp. 370-379.
Voir aussi
Liens externes
- Complexité dans le meilleur des cas
- QuickSort implementation
- Simulation en Java
- QuickSort en Java,C,PHP
- QuickSort "pour les nuls"
 Portail de l’informatique
Portail de l’informatique
Catégorie : Algorithme de tri

Wikimedia Foundation. 2010.