- Algorithme Génétique
-
Algorithme génétique
Les algorithmes génétiques appartiennent à la famille des algorithmes évolutionnistes (un sous-ensemble des métaheuristiques). Leur but est d'obtenir une solution approchée, en un temps correct, à un problème d'optimisation, lorsqu'il n'existe pas (ou qu'on ne connaît pas) de méthode exacte pour le résoudre en un temps raisonnable. Les algorithmes génétiques utilisent la notion de sélection naturelle développée au XIXe siècle par le scientifique Darwin et l'appliquent à une population de solutions potentielles au problème donné. On se rapproche par "bonds" successifs d'une solution, comme dans une procédure de séparation et évaluation, à ceci près que ce sont des formules qui sont recherchées et non plus directement des valeurs.
Sommaire
Les origines
L'utilisation d'algorithmes génétiques, dans la résolution de problèmes, est à l'origine le fruit des recherches de John Holland et de ses collègues et élèves de l'Université du Michigan qui ont, dès 1960, travaillé sur ce sujet. La nouveauté introduite par ce groupe de chercheurs a été la prise en compte de l'opérateur d'enjambement en complément des mutations. Et c'est cet opérateur qui permet le plus souvent de se rapprocher de l'optimum d'une fonction en combinant les gènes contenus dans les différents individus de la population. Le premier aboutissement de ces recherches a été la publication en 1975 de Adaptation in Natural and Artificial System.
Présentation
Analogie avec la biologie
Terminologie commune aux deux disciplines
Les algorithmes génétiques étant basés sur des phénomènes biologiques, il convient de rappeler au préalable quelques termes de génétique.
Les organismes vivants sont constitués de cellules, dont les noyaux comportent des chromosomes qui sont des chaînes d'ADN. L'élément de base de ces chromosomes (le caractère de la chaîne d'ADN) est un gène. Sur chacun de ces chromosomes, une suite de gènes constitue une chaîne qui code les fonctionnalités de l'organisme (la couleur des yeux ...). La position d'un gène sur le chromosome est son locus. L'ensemble des gènes d'un individu est son génotype et l'ensemble du patrimoine génétique d'une espèce est le génome. Les différentes versions d'un même gène sont appelées allèles.
On utilise aussi, dans les algorithmes génétiques, une analogie avec la théorie de l'évolution qui propose qu'au fil du temps, les gènes conservés au sein d'une population donnée sont ceux qui sont le plus adaptés aux besoins de l'espèce vis à vis de son environnement.
Les outils issus de la biologie
La génétique a mis en évidence l'existence de plusieurs opérations au sein d'un organisme donnant lieu au brassage génétique. Ces opérations interviennent lors de la phase de reproduction lorsque les chromosomes de deux organismes fusionnent.
Ces opérations sont imitées par les algorithmes génétiques afin de faire évoluer les populations de solutions de manière progressive.
- Les sélections
-
- Pour déterminer quels individus sont plus enclins à obtenir les meilleurs résultats, une sélection est opérée. Ce processus est analogue à un processus de sélection naturelle, les individus les plus adaptés gagnent la compétition de la reproduction tandis que les moins adaptés meurent avant la reproduction, ce qui améliore globalement l'adaptation. Etant donné que la sélection est le résultat d'une intervention humaine ou, du moins, l'application d'un critère défini par l'homme, les algorithmes génétiques devraient donc plutôt être rapprochés de la sélection artificielle telle que la pratiquent les agriculteurs que de la sélection naturelle, qui œuvre "en aveugle".
- Les enjambements ou croisement ou recombinaison
-
- Lors de cette opération, deux chromosomes s'échangent des parties de leurs chaînes, pour donner de nouveaux chromosomes. Ces enjambements peuvent être simples ou multiples.
- Dans le premier cas, les deux chromosomes se croisent et s'échangent des portions d'ADN en un seul point. Dans le deuxième cas, il y a plusieurs points de croisement. Pour les algorithmes génétiques, c'est cette opération (le plus souvent sous sa forme simple) qui est prépondérante. Sa probabilité d'apparition lors d'un croisement entre deux chromosomes est un paramètre de l'algorithme génétique et dépend du problème et de la technique de recombinaison. La probabilité d'un enjambement est alors comprise entre 0 et 1 strictement.
- Les mutations
-
- De façon aléatoire, un gène peut, au sein d'un chromosome être substitué à un autre. De la même manière que pour les enjambements, on définit ici un taux de mutation lors des changements de population qui est généralement compris entre 0,001 et 0,01. Il est nécessaire de choisir pour ce taux une valeur relativement faible de manière à ne pas tomber dans une recherche aléatoire et conserver le principe de sélection et d'évolution. La mutation sert à éviter une convergence prématurée de l'algorithme. Par exemple lors d'une recherche d'extremum la mutation sert à éviter la convergence vers un extremum local
Principe
Les algorithmes génétiques, afin de permettre la résolution de problèmes, se basent sur les différents principes décrits ci-dessus. De manière globale, on commence avec une population de base qui se compose le plus souvent de chaînes de caractères correspondant chacune à un chromosome. Nous reviendrons par la suite sur les différentes structures de données possibles (voir Codage) mais nous retiendrons pour le moment l'utilisation du codage binaire (ex. : 0100110).
Le contenu de cette population initiale est généré aléatoirement. On attribue à chacune des solutions une note qui correspond à son adaptation au problème. Ensuite, on effectue une sélection au sein de cette population.
Il existe plusieurs techniques de sélection. Voici les principales utilisées :
- Sélection par rang
-
- Cette technique de sélection choisit toujours les individus possédant les meilleurs scores d'adaptation, le hasard n'entre donc pas dans ce mode de sélection.
- Probabilité de sélection proportionnelle à l'adaptation (appelé aussi roulette ou roue de la fortune)
-
- Pour chaque individu, la probabilité d'être sélectionné est proportionnelle à son adaptation au problème. Afin de sélectionner un individu, on utilise le principe de la roue de la fortune biaisée. Cette roue est une roue de la fortune classique sur laquelle chaque individu est représenté par une portion proportionnelle à son adaptation. On effectue ensuite un tirage au sort homogène sur cette roue.
- Sélection par tournoi
-
- Cette technique utilise la sélection proportionnelle sur des paires d'individus, puis choisit parmi ces paires l'individu qui a le meilleur score d'adaptation.
- Sélection uniforme
-
- La sélection se fait aléatoirement, uniformément et sans intervention de la valeur d'adaptation. Chaque individu a donc une probabilité 1/P d'être sélectionné, où P est le nombre total d'individus dans la population.
Lorsque deux chromosomes ont été sélectionnés, on réalise un enjambement. On effectue ensuite des mutations sur une faible proportion d'individus, choisis aléatoirement. Ce processus nous fournit une nouvelle population. On réitère le processus un grand nombre de fois de manière à imiter le principe d'évolution, qui ne prend son sens que sur un nombre important de générations. On peut arrêter le processus au bout d'un nombre arbitraire de générations ou lorsqu'une solution possède une note suffisamment satisfaisante.
Considérons par exemple les deux individus suivants dans une population où chaque individu correspond à une chaîne de 8 bits : A = 00110010 et B = 01010100. On ajuste la probabilité d'enjambement à 0.7.
Chromosome Contenu A 00:110010 B 01:010100 A' 00 010100 B' 01 110010 Supposons ici que l'enjambement ait lieu, on choisit alors aléatoirement la place de cet enjambement (toutes les places ayant la même probablité d'être choisies). En supposant que l'enjambement ait lieu après le deuxième allèle, on obtient A' et B' (« : » marquant l'enjambement sur A et B). Ensuite, chacun des gènes des fils (ici, chacun des bits des chaînes) est sujet à la mutation. De la même manière que pour les combinaisons, on définit un taux de mutation (très bas, de l'ordre de 0,001 - ici on peut s'attendre à ce que A' et B' restent identiques).
En effectuant ces opérations (sélection de deux individus, enjambement, mutation), un nombre de fois correspondant à la taille de la population divisée par deux, on se retrouve alors avec une nouvelle population (la première génération) ayant la même taille que la population initiale, et qui contient globalement des solutions plus proches de l'optimum. Le principe des algorithmes génétiques est d'effectuer ces opérations un maximum de fois de façon à augmenter la justesse du résultat.
Il existe plusieurs techniques qui permettent éventuellement d'optimiser ces algorithmes, on trouve par exemple des techniques dans lesquelles on insère à chaque génération quelques individus non issus de la descendance de la génération précédente mais générés aléatoirement. Ainsi, on peut espérer éviter une convergence vers un optimum local.
Codage d'un algorithme génétique
Pour les algorithmes génétiques, un des facteurs les plus importants, si ce n'est le plus important, est la façon dont sont codées les solutions (ce que l'on a nommé ici les chromosomes), c'est-à-dire les structures de données qui coderont les gènes.
Codage binaire
Ce type de codage est certainement le plus utilisé car il présente plusieurs avantages. Son principe est de coder la solution selon une chaîne de bits (qui peuvent prendre les valeurs 0 ou 1). Les raisons pour lesquelles ce type de codage est le plus utilisé sont tout d'abord historiques. En effet, lors des premiers travaux de Holland, les théories ont été élaborées en se basant sur ce type de codage. Et même si la plupart de ces théories peuvent être étendues à des données autres que des chaînes de bits, elles n'ont pas été autant étudiées dans ces contextes. Cependant, l'avantage de ce type de codage sur ses concurrents a tendance à être remis en question par les chercheurs actuels qui estiment que les démonstrations d'Holland sur les avantages supposés de ce codage ne sont pas révélatrices.
La démonstration d'Holland (en 1975) pour prouver la supériorité de ce type de codage est la suivante. Il compara deux types de codage pour le même problème. Le premier était composé de peu de types d'allèles mais avec des chromosomes d'une longueur importante (des chaînes de 100 bits par exemple), l'autre était composé de chaînes plus courtes mais contenant plus d'allèles (en sachant que tout autre codage, pour le même chromosome, aboutira à une chaîne plus courte). Il prouva que le codage sous forme de bits était plus efficace de manière assez simple. En effet, les chaînes de 100 bits permettent d'avoir plus de possibilités d'enjambement. Entre deux chromosomes du premier type, l'enjambement peut avoir lieu à 100 endroits différents contre 30 pour ceux du second type. Le brassage génétique sur lequel repose l'efficacité des algorithmes génétiques sera donc plus important dans le premier cas.
Il existe cependant au moins un côté négatif à ce type de codage qui fait que d'autres existent. En effet, ce codage est souvent peu naturel par rapport à un problème donné (l'évolution des poids d'arcs dans un graphe par exemple est difficile à coder sous la forme d'une chaîne de bits).
Codage à caractères multiples
Une autre manière de coder les chromosomes d'un algorithme génétique est donc le codage à l'aide de caractères multiples (par opposition aux bits). Souvent, ce type de codage est plus naturel que celui énoncé ci-avant. C'est d'ailleurs celui-ci qui est utilisé dans de nombreux cas poussés d'algorithmes génétiques que nous présenterons par la suite.
Codage sous forme d'arbre
Ce codage utilise une structure arborescente avec une racine de laquelle peuvent être issus un ou plusieurs fils. Un de leurs avantages est qu'ils peuvent être utilisés dans le cas de problèmes où les solutions n'ont pas une taille finie. En principe, des arbres de taille quelconque peuvent être formés par le biais d'enjambements et de mutations.
Le problème de ce type de codage est que les arbres résultants sont souvent difficiles à analyser et que l'on peut se retrouver avec des arbres « solutions » dont la taille sera importante alors qu'il existe des solutions plus simples et plus structurées à côté desquelles sera passé l'algorithme. De plus, les performances de ce type de codage par rapport à des codages en chaînes n'ont pas encore été comparées ou très peu. En effet, ce type d'expérience ne fait que commencer et les informations sont trop faibles pour se prononcer.
Finalement, le choix du type de codage ne peut pas être effectué de manière sûre dans l'état actuel des connaissances. Selon les chercheurs dans ce domaine, la méthode actuelle à appliquer dans le choix du codage consiste à choisir celui qui semble le plus naturel en fonction du problème à traiter et développer ensuite l'algorithme de traitement.
Cas d'utilisation
Les conditions du problème
Comme cela a été dit plus haut, les algorithmes génétiques peuvent être une bonne solution pour résoudre un problème. Néanmoins, leur utilisation doit être conditionnée par certaines caractéristiques du problème.
Les caractéristiques à prendre en compte sont les suivantes :
- Nombre de solutions important : En effet, les performances des algorithmes génétiques par rapport aux algorithmes classiques sont plus marquées lorsque les espaces de recherches sont importants. En effet, pour un espace dont la taille est faible, il peut être plus sûr de parcourir cet espace de manière exhaustive afin d'obtenir la solution optimale en un temps qui restera somme toute correct. Au contraire, utiliser un algorithme génétique engendrera le risque d'obtenir une solution non optimale (voir Limites) en un temps qui restera sensiblement identique.
- Pas d'algorithme déterministe adapté et raisonnable.
- Lorsque l'on préfère avoir une solution relativement bonne rapidement plutôt qu'avoir la solution optimale en une durée indéfinie. C'est ainsi que les algorithmes génétiques sont utilisés pour la programmation de machines qui doivent être très réactives aux conditions environnantes.
Exemples d'applications
Applications dans la recherche
Le problème du voyageur de commerce : Ce problème est un classique d'algorithmique. Son sujet concerne les trajets d'un voyageur de commerce. Celui-ci dispose de plusieurs points où s'arrêter et le but de l'algorithme est d'optimiser le trajet de façon à ce que celui-ci soit le plus court possible. Dans le cas où huit points d'arrêts existent, cela est encore possible par énumération (2520 possibilités [pour n arrêts,n supérieur ou égal à 3, il y a (n-1)!/2 chemins possibles) mais ensuite, l'augmentation du nombre d'arrêts fait suivre au nombre de possibilités une croissance exponentielle.
Par le biais d'algorithmes génétiques, il est possible de trouver des chemins relativement corrects. De plus, ce type de problèmes est assez facile à coder sous forme d'algorithme génétique. L'idée de base est de prendre comme fonction d'adaptation d'un chemin sa longueur. Pour effectuer le croisement de deux chemins:
- On recopie le premier chemin jusqu'à une "cassure".
- On recopie ensuite les villes du second chemin. Si la ville est déjà utilisée, on passe à la ville suivante.
Chemin Codage A 1 2 3 4 : 5 6 7 8 9 B 4 1 6 3 : 9 8 2 5 7 fils 1 2 3 4 : 6 9 8 5 7 Soit un itinéraire qui contient 9 clients, on suppose que l'on croise les deux chemins suivants (un chiffre représente un client). On croise ces deux chemins après le locus 4: on obtient le chemin fils.
En partant de ce principe, de nombreux algorithmes génétiques ont été développés, chacun utilisant différentes variantes afin de se rapprocher le plus possible du maximum dans tous les cas. Il existe d'ailleurs un concours sur internet qui propose de développer un algorithme à même de trouver le meilleur chemin sur un problème de voyageur de commerce de 250 villes.
Applications industrielles
Un premier exemple est une réalisation effectuée au sein de l'entreprise Motorola. Le problème pour lequel Motorola a utilisé les algorithmes génétiques concerne les tests des applications informatiques. En effet, lors de chaque changement apporté à une application, il convient de retester l'application afin de voir si les modifications apportées n'ont pas eu d'influence négative sur le reste de l'application. Pour cela, la méthode classique est de définir manuellement des plans de test permettant un passage dans toutes les fonctions de l'application. Mais ce type de test nécessite un important travail humain. Le but de Motorola a donc été d'automatiser cette phase de définition de plans de tests. Ils ont pour cela défini un algorithme où chaque individu correspond à un résultat d'exécution d'un programme (l'enchaînement des valeurs passées au programme) et où chaque individu reçoit une valeur qui correspond à son aptitude à passer dans un maximum de parties du code de l'application. Finalement, l'outil développé permet, à l'aide d'un algorithme génétique, de faire évoluer ces programmes de test pour maximiser les zones testées de façon à ce que lors de modifications apportées à l'application on puisse soumettre celle-ci à des tests efficaces. D'autres domaines industriels utilisent aujourd'hui les algorithmes génétiques. On peut retenir entre autres l'aérodynamique où des optimisations sont mises au point à l'aide de ces outils, l'optimisation structurelle, qui consiste à minimiser le poids d'une structure en tenant compte des contraintes de tension admissibles pour les différents éléments, et la recherche d'itinéraires : ces algorithmes ont été utilisés par la NASA pour la mission d'exploration de Mars, dans la gestion des déplacements du robot Pathfinder.
La société Sony les a aussi utilisés dans son robot Aibo. En effet, ce robot a « appris » à marcher dans un dispositif expérimental où son système de commande a été soumis à une évolution artificielle. Différents modes de commandes ont été testés, les plus performants ont été croisés et le résultat a été très positif. De génération en génération, le robot s'est redressé, puis a commencé à marcher en chutant souvent et a fini par marcher d'un pas assuré.
Informatique décisionnelle
Les algorithmes génétiques sont mis en œuvre dans certains outils d'informatique décisionnelle ou de data mining par exemple pour rechercher une solution d'optimum à un problème par mutation des attributs (des variables) de la population étudiée.
Ils sont utilisés par exemple dans une étude d'optimisation d'un réseau de points de vente ou d'agences (banque, assurance, ...) pour tenter de répondre aux questions :
- quelles sont les variables (superficie, effectif, ...) qui expliquent la réussite commerciale de telle ou telle agence ?
- en modifiant telle variable (mutation) de telle agence améliore-t-on son résultat ?
Les limites
- Le temps de calcul : par rapport à d'autres métaheuristiques, ils nécessitent de nombreux calculs, en particulier au niveau de la fonction d'évaluation.
- Ils sont le plus souvent difficiles à mettre en œuvre : des paramètres comme la taille de la population ou le taux de mutation sont parfois difficiles à déterminer. Or le succès de l'évolution en dépend et plusieurs essais sont donc nécessaires, ce qui limite encore l'efficacité de l'algorithme. En outre, choisir une bonne fonction d'évaluation est aussi critique. Celle-ci doit prendre en compte les bons paramètres du problème. Elle doit donc être choisie avec soin.
- Il faut aussi noter l'impossibilité d'être assuré, même après un nombre important de générations, que la solution trouvée soit la meilleure. On peut seulement être sûr que l'on s'est approché de la solution optimale (pour les paramètres et la fonction d'évaluation choisie), sans la certitude de l'avoir atteinte.
- Un autre problème important est celui des optima locaux. En effet, lorsqu'une population évolue, il se peut que certains individus qui à un instant occupent une place importante au sein de cette population deviennent majoritaires. À ce moment, il se peut que la population converge vers cet individu et s'écarte ainsi d'individus plus intéressants mais trop éloignés de l'individu vers lequel on converge. Pour vaincre ce problème, il existe différentes méthodes comme l'ajout de quelques individus générés aléatoirement à chaque génération, des méthodes de sélection différentes de la méthode classique ...
Schéma récapitulatif
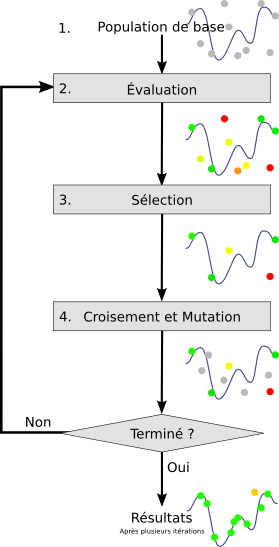
- Population de base générée aléatoirement
- n chaînes de caractères ou de bits.
- 1 chaîne correspond à 1 chromosome.
- Évaluation
- à chaque chaîne, une note correspondant à son adaptation au problème.
- Sélection
- tirage au sort de n/2 couples de chaînes sur une roue biaisée.
- Chaque chaîne a une probabilité d’être tirée proportionnelle à son adaptation au problème.
- Optimisation possible : si l’individu le plus adapté n’a pas été sélectionné, il est copié d’office dans la génération intermédiaire à la place d’un individu choisi aléatoirement.
- Croisement et mutation
- Chaque couple donne 2 chaînes filles.
- Enjambement. Probabilité : 70%. Emplacement de l'enjambement choisi aléatoirement.
- Exemple :
- Chaînes parents : A : 00110100 ; B : 01010010
- Chaînes filles : A’ : 00010010 ; B’ : 01110100
- Croisement en 2 points plus efficace.
- Exemple :
- Mutations des chaînes filles. Probabilité : de 0,1 à 1%.
- Inversion d’un bit au hasard ou remplacement au hasard d’un caractère par un autre.
- Probabilité fixe ou évolutive (auto-adaptation).
- On peut prendre probabilité = 1/nombre de bits.
Les algorithmes génétiques reprennent la théorie de Darwin : sélection naturelle de variations individuelles : les individus les plus adaptés (the fittest) tendent à survivre plus longtemps et à se reproduire plus aisément.
Amélioration de la population très rapide au début (recherche globale) ; de plus en plus lente à mesure que le temps passe (recherche locale).
Convergence : la valeur moyenne de la fonction d’adaptation a tendance à se rapprocher de celle de l’individu le plus adapté : uniformisation croissante de la population.
Le temps de calcul des algorithmes génétiques croît en nln(n), n étant le nombre de variables.
Implantation matérielle
Une implantation matérielle a été effectuée conjointement par les universités d'Oslo et de Tsukuba :
Voir aussi
- Au sein de l'intelligence artificielle, la programmation génétique est le domaine d'application englobant les algorithmes génétiques
- Les algorithmes à estimation de distribution sont une généralisation des algorithmes génétiques
Références
- Charles Darwin: The origin of species (1859)
- J. H. Holland: Adaptation In Natural And Artificial Systems, University of Michigan Press (1975)
- La robotique évolutive dans Pour la science, n° 284, p. 70 (juin 2001)
- M. Mitchell: An introduction to genetic algorithm, MIT press (1996)
- Comment l'ordinateur transforme les sciences dans Les Cahiers de Science et Vie, n° 53 (1999)
- D. Goldberg : Algorithmes génétiques, Addison-Wesley France (1994)
- (en) Poli, R., Langdon, W. B., McPhee, N. F., A Field Guide to Genetic Programming, Lulu.com, freely available from the internet, 2008 (ISBN 978-1-4092-0073-4)
 Portail de la programmation informatique
Portail de la programmation informatique
Catégories : Métaheuristique | Recherche opérationnelle | Intelligence artificielle
Wikimedia Foundation. 2010.