- Coefficient de corrélation multiple
-
Régression linéaire multiple
 Pour les articles homonymes, voir Régression.
Pour les articles homonymes, voir Régression.Sommaire
Modèle théorique
La régression linéaire multiple est une généralisation, à p variables explicatives, de la régression linéaire simple.
Nous sommes toujours dans le cadre de la régression mathématique : étant donné un échantillon
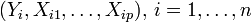 nous cherchons à expliquer, avec le plus de précision possible, les valeurs prises par Yi, dite variable endogène, à partir d'une série de variables explicatives
nous cherchons à expliquer, avec le plus de précision possible, les valeurs prises par Yi, dite variable endogène, à partir d'une série de variables explicatives 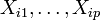 . Le modèle théorique, formulé en termes de variables aléatoires, prend la forme
. Le modèle théorique, formulé en termes de variables aléatoires, prend la formeoù
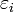 est l'erreur du modèle qui exprime, ou résume, l'information manquante dans l'explication linéaire des valeurs de Yi à partir des (problème de spécifications, variables non prises en compte, etc.).
est l'erreur du modèle qui exprime, ou résume, l'information manquante dans l'explication linéaire des valeurs de Yi à partir des (problème de spécifications, variables non prises en compte, etc.). 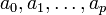 sont les paramètres à estimer.
sont les paramètres à estimer.Exemple
Nous relevons 20 fois les paramètres suivant: la demande totale en électricité (ce sera notre yi, i étant comprit entre 1 et 20) la température extérieure (ce sera notre xi1) l'heure à laquelle les données sont prises (ce sera notre xi2)
Faire une régression linéaire reviens à déterminer les ao, a1 et a2 et
tels que quel que soit la mesure prise: 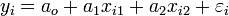
Estimation
Lorsque nous disposons de n observations
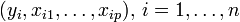 , qui sont des réalisations des variables aléatoires
, qui sont des réalisations des variables aléatoires 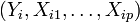 , l'équation de régression s'écrit
, l'équation de régression s'écrit
La problématique reste la même que pour la régression simple :- estimer les paramètres ai en exploitant les observations ;
- évaluer la précision de ces estimateurs ;
- mesurer le pouvoir explicatif du modèle ;
- évaluer l'influence des variables dans le modèle :
- globalement (les p variables en bloc) et,
- individuellement (chaque variable) ;
- évaluer la qualité du modèle lors de la prédiction (intervalle de prédiction) ;
- détecter les observations qui peuvent influencer exagérément les résultats (points atypiques).
Notation matricielle
Nous pouvons adopter une écriture condensée qui rend la lecture et la manipulation de l'ensemble plus facile. Les équations suivantes
peuvent être résumées avec la notation matricielle
Soit de manière compacte:
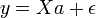
avec
- y est de dimension (n, 1)
- X est de dimension (n, p + 1)
- a est de dimension (p+1, 1)
- ε est de dimension (n, 1)
- la première colonne sert à indiquer que nous procédons à une régression avec constante.
Hypothèses
Comme en régression simple, les hypothèses permettent de déterminer : les propriétés des estimateurs (biais, convergence) ; et leurs lois de distributions (pour les estimations par intervalle et les tests d'hypothèses).
Il existe principalement deux catégories d'hypothèses :
- Hypothèses stochastiques
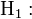 Les X j sont aléatoires, j = 1, …, p ;
Les X j sont aléatoires, j = 1, …, p ;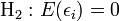 Le modèle est bien spécifié en moyenne ;
Le modèle est bien spécifié en moyenne ;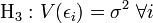 Homoscedasticité (en) des erreurs (variance constante)
Homoscedasticité (en) des erreurs (variance constante)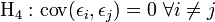 Pas d'autocorrélation des erreurs.
Pas d'autocorrélation des erreurs.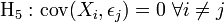 Les erreurs sont linéairement indépendantes des variables exogènes.
Les erreurs sont linéairement indépendantes des variables exogènes.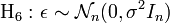 Les erreurs suivent une loi normale multidimensionnelle (H6 implique les hypothèses H2, H3 et H4 la réciproque étant fausse car les 3 hypothèses réunies n'impliquent pas que
Les erreurs suivent une loi normale multidimensionnelle (H6 implique les hypothèses H2, H3 et H4 la réciproque étant fausse car les 3 hypothèses réunies n'impliquent pas que  soit un vecteur gaussien).
soit un vecteur gaussien).
- Hypothèses structurelles
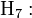 absence de colinéarité entre les variables explicatives, i.e. X 'X est régulière, det(X 'X) ≠ 0 et (X 'X)-1 existe (remarque : c'est équivalent à rang(X) = rang(X 'X) = p + 1) ;
absence de colinéarité entre les variables explicatives, i.e. X 'X est régulière, det(X 'X) ≠ 0 et (X 'X)-1 existe (remarque : c'est équivalent à rang(X) = rang(X 'X) = p + 1) ;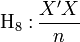 tend vers une matrice finie non singulière lorsque n → +∞ ;
tend vers une matrice finie non singulière lorsque n → +∞ ;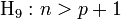 Le nombre d'observations est supérieur au nombre de variables + 1 (la constante). S'il y avait égalité, le nombre d'équations serait égal au nombre d'inconnues aj, la droite de régression passe par tous les points, nous sommes face à un problème d'interpolation linéaire (voir Interpolation numérique).
Le nombre d'observations est supérieur au nombre de variables + 1 (la constante). S'il y avait égalité, le nombre d'équations serait égal au nombre d'inconnues aj, la droite de régression passe par tous les points, nous sommes face à un problème d'interpolation linéaire (voir Interpolation numérique).
- Écriture matricielle de l'hypothèse H6
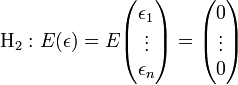
Sous l'hypothèse d'homoscedasticité et d'absence d'auto-corrélation, la matrice de variance-covariance du vecteur des erreurs peut s'écrire:
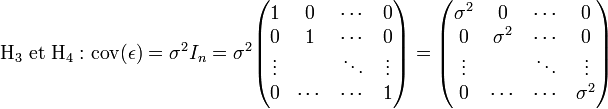
Régresseurs stochastiques
Dans certains cas, l'hypothèse (H1) est intenable : les régresseurs X sont supposés aléatoires. Mais dans ce cas, on suppose que X est aléatoire mais est indépendant de l'aléa
 . On remplace alors l'hypothèse (H2) par une hypothèse sur l'espérance conditionnelle:
. On remplace alors l'hypothèse (H2) par une hypothèse sur l'espérance conditionnelle:De même, il faudrait changer en conséquence les hypothèses (H3), (H4) et aussi (H5).
La méthode des moindres carrés ordinaires
Estimateur des moindres carrés ordinaires (EMCO)
Du modèle complet:
On va estimer les paramètres et obtiendra:
Les résidus estimés sont la différence entre la valeur de y observée et estimée. Soit:
Définition —
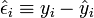
Le principe des moindres carrés consiste à rechercher les valeurs des paramètres qui minimisent la somme des carrés des résidus.
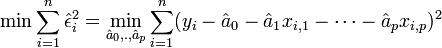 .
.
Ce qui revient à rechercher les solutions de
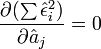 . Nous avons j =p + 1 équations, dites équations normales, à résoudre.
. Nous avons j =p + 1 équations, dites équations normales, à résoudre.La solution obtenue est l'estimateur des moindres carrés ordinaires, il s'écrit :
Théorème —
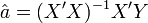 est l'estimateur qui minimise la somme des carrés des résidus.
est l'estimateur qui minimise la somme des carrés des résidus.-
- avec X' la transposée de X
DémonstrationRemarques:
- Pourquoi minimiser la somme des carrés plutôt que la simple somme? Cela tient au fait que la moyenne de ces résidus sera 0, et donc que nous disposerons de résidus positifs et négatifs. Une simple somme les annulerait, ce qui n'est pas le cas avec les carrés.
- si les x j sont centrés, X 'X correspond à la matrice de variance-covariance des variables exogènes ; s'ils sont centrés et réduits, X 'X correspond à la matrice de corrélation.
Interprétation géométrique, algébrique et statistique de l'estimateur MCO
- L'estimateur MCO correspond à une projection orthogonale du vecteur Y sur l'espace formé par les vecteurs X.
- L'estimateur MCO correspond à une matrice inverse généralisée du système Y = Xa pour mettre a en évidence. En effet, si on prémultiplie par l'inverse généraliseé (X'X) − 1X' on a: (X'X) − 1X'Y = (X'X) − 1X'Xa = a
- L'estimateur MCO est identique à l'estimateur obtenu par le principe du maximum de vraisemblance.
Propriétés des estimateurs
Si les hypothèses initiales sont respectées, l'estimateur des MCO (Moindres Carrés Ordinaires) possède d'excellentes propriétés.
Propriétés en échantillons finis
Propriété — L'estimateur MCO est sans biais, c.-à-d.
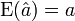 , sous les hypothèses H1,H2, et H5Preuve
, sous les hypothèses H1,H2, et H5Preuve![\begin{align}
\operatorname{E}[\hat a] &=\operatorname{E}\left[(X'X)^{-1}X'Y\right]\\
&= \operatorname{E}\left[a + (X'X)^{-1}X'\varepsilon\right]\\
&= a + (X'X)^{-1}X'\operatorname{E}[\varepsilon]\qquad \text{ sous } H_1 \text{ et } H_5\\
&=a+0 \qquad \qquad \qquad \qquad \text{ sous } H_2\\
&=a\end{align}](/pictures/frwiki/54/652c61484a82737503ef24f774b4d642.png)
- Cette propriété se base seulement sur les hypothèses d'espérance nulle des résidus. La présence d'autocorrélation ou d'hétéroscédasticité n'affecte pas ce résultat.
Propriété — L'estimateur MCO est le meilleur estimateur linéaire sans biais, sous les hypothèses H1 à H5
- C.-à.-d. qu'il n'existe pas d'estimateur linéaire sans biais de a qui ait une variance plus petite. Cette propriété en anglais est désignée par BLUE, pour best linear unbiased estimator. La preuve est donnée par le Théorème de Gauss-Markov.
Propriété — L'estimateur MCO est distribué selon une loi normale
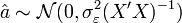 sous les hypothèses H1,H2, et H6
sous les hypothèses H1,H2, et H6Propriétés asymptotiques
Propriété — L'estimateur MCO est convergent en probabilité, c.-à-d.
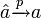 , sous les hypothèses H6, et H8Preuve
, sous les hypothèses H6, et H8Preuve- Récrivons:
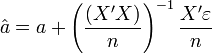
- Prenons la limite en probabilité:
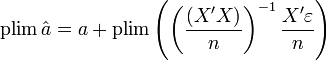
- Comme on a fait l'hypothèse H8 que
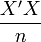 tend vers une matrice Q définie positive, la limite devient:
tend vers une matrice Q définie positive, la limite devient:
- Il reste alors à étudier le comportement de
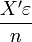 . Sous l'hypothèse H6, (ou plutôt sur une forme plus restrictive
. Sous l'hypothèse H6, (ou plutôt sur une forme plus restrictive ![\operatorname{E}[x_i\varepsilon_i]=0](/pictures/frwiki/53/51a6492a30d60c2e0bf31cffb8227cf0.png) ) on peut montrer que son espérance est nulle, et que sa variance tend asymptotiquement vers 0, ce qui implique qu'il converge en moyenne quadratique vers 0, et donc qu'il converge en probabilité vers 0.
) on peut montrer que son espérance est nulle, et que sa variance tend asymptotiquement vers 0, ce qui implique qu'il converge en moyenne quadratique vers 0, et donc qu'il converge en probabilité vers 0.
- On a donc finalement:
Propriété — L'estimateur MCO suit asymptotiquement une loi normale
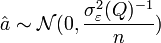 sous les hypothèses H1 à H5 et H8
sous les hypothèses H1 à H5 et H8- Ce résultat est obtenu sans l'hypothèse de normalité des résidus (H6).
Évaluation
Pour réaliser les estimations par intervalle et les tests d'hypothèses, la démarche est presque toujours la même en statistique paramétrique :
- définir l'estimateur (â dans notre cas) ;
- calculer son espérance mathématique (ici E(â ) = a) ;
- calculer sa variance (ou sa matrice de variance co-variance) et produire son estimation ;
- et enfin déterminer sa loi de distribution (en général et sous l'hypothèse nulle des tests).
Matrice de variance-covariance de â
La matrice de variance-covariance des coefficients est importante car elle renseigne sur la variance de chaque coefficient estimé, et permet de faire des tests d'hypothèse, notamment de voir si chaque coefficient est significativement différent de zéro. Elle est définie par :
Sous les hypothèses d'espérance nulle, d'absence d'autocorrélation et d'hétéroscédasticité des résidus (H1 à H5), on a:
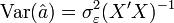 Preuve
Preuveen récrivant:
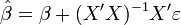 , on obtient que:
, on obtient que:![\begin{align}
\operatorname{Var}[\hat \beta]
&= \operatorname{Var}\left[(X'X)^{-1}X'\varepsilon \right ]\\
&=(X'X)^{-1}X'\operatorname{Var}[\varepsilon] X(X'X)^{-1}\\
&=(X'X)^{-1}X'\sigma^2_{\varepsilon}I X(X'X)^{-1}\qquad \text{ sous } H_3 \text{ et } H_4\\
&=\sigma^2_{\varepsilon}(X'X)^{-1}X'X(X'X)^{-1}\\
&=\sigma^2_{\varepsilon}(X'X)^{-1}
\end{align}](/pictures/frwiki/48/09f73b4f4959f97a82d8f1eb588b81cc.png)
Cette formule ne s'applique cependant que dans le cas où les les résidus sont homoscédastiques et sans auto-corrélation, ce qui permet d'écrire la matrice des erreurs comme:
![\textrm{Cov}[\varepsilon] = \sigma^2 I_{n} \,](/pictures/frwiki/53/5d54b9905389d754bd36b55bbae4dadf.png)
S'il y a de l'hétéroscédasticité ou de l'auto-corrélation, et donc
![\textrm{Cov}[\varepsilon] \neq \sigma^2 I_{n}](/pictures/frwiki/52/4fb7cb0c423a1b4eb09b12e8be7dd7ba.png) , il est possible de rectifier la matrice de variance-covariance estimée par:
, il est possible de rectifier la matrice de variance-covariance estimée par:- Matrice de variance-covariance de White (ou Eicker-White (1967, 1980)), consistante en cas d'hétéroscédasticité (en anglais HC Heteroskedasticity Consistent).
- Matrice de variance-covariance de Newey-West (1987), consistante en cas d'hétéroscédasticité et d'auto-corrélation (en anglais HAC Heteroskedasticity and Autocorrelation Consistent).
Ces deux estimateurs sont disponible pour le logiciel libre de statistique R dans le paquet externe "sandwich".
Estimation de la variance du résidu
Pour la variance du résidu
![\sigma_{\varepsilon}^{2}\equiv \operatorname{Var}[\varepsilon]](/pictures/frwiki/55/707adaf7ebd3ecabcfebe90406facf5d.png) , on peut utiliser l'estimateur sans biais construit à partir de la variance des résidus observés :
, on peut utiliser l'estimateur sans biais construit à partir de la variance des résidus observés :Les
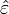 correspondent aux résidus observés:
correspondent aux résidus observés: 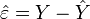 .
.On remarque deux choses par rapport à l'estimateur classique de la variance:
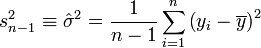 ,
,- on n'inclut pas l'espérance des résidus, car celle-ci est supposée être de zéro (selon H2). Surtout, les résidus du modèle ont exactement une moyenne de zéro lorsqu'une constante est introduite dans le modèle.
- La somme des carré est divisé par n - p - 1 = n - (p + 1) et non par n-1. En fait, n-p-1 correspond aux degrés de liberté du modèle (le nombre d'observations moins le nombre de coefficients à estimer). on remarque effectivement que
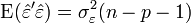 .
.
Il existe également un autre estimateur, obtenu par la méthode du maximum de vraisemblance, qui est cependant biaisé:
Estimation de la matrice de variance-covariance de â
Il suffit de remplacer la variance théorique des résidus,
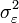 , par son estimateur sans biais des moindres carrés:
, par son estimateur sans biais des moindres carrés: 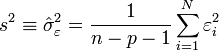
L'estimateur de la matrice de variance-covariance des résidus devient:
La variance estimée
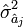 de l'estimation du paramètre â j est lue sur la diagonale principale de cette matrice.
de l'estimation du paramètre â j est lue sur la diagonale principale de cette matrice.Étude des coefficients
Après avoir obtenu l'estimateur, son espérance et une estimation de sa variance, il ne reste plus qu'à calculer sa loi de distribution pour produire une estimation par intervalle et réaliser des tests d'hypothèses.
Distribution
En partant de l'hypothèse
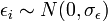 ,
,
nous pouvons montrer
Le rapport d'une loi normale et de la racine carrée d'une loi du χ² normalisée par ses degrés de liberté aboutit à une loi de Student. Nous en déduisons donc la statistique :
elle suit une loi de Student à (n - p - 1) degrés de liberté.
Intervalle de confiance et tests d'hypothèses
À partir de ces informations, il est possible de calculer les intervalles de confiance des estimations des coefficients.
Il est également possible de procéder à des tests d'hypothèses, notamment les tests d'hypothèses de conformité à un standard. Parmi les différents tests possibles, le test de nullité du coefficient (H0 : a j = 0, contre H1 : a j ≠ 0) tient un rôle particulier : il permet de déterminer si la variable x j joue un rôle significatif dans le modèle. Il faut néanmoins être prudent quant à ce test. L'acceptation de l'hypothèse nulle peut effectivement indiquer une absence de corrélation entre la variable incriminée et la variable endogène ; mais il peut également résulter de la forte corrélation de x j avec une autre variable exogène, son rôle est masqué dans ce cas, laissant à croire une absence d'explication de la part de la variable.
Evaluation globale de la régression — Tableau d'analyse de variance
Tableau d'analyse de variance et coefficient de détermination
L'évaluation globale de la pertinence du modèle de prédiction s'appuie sur l'équation d'analyse de variance SCT = SCE + SCR, où
- SCT, somme des carrés totaux, traduit la variabilité totale de l'endogène ;
- SCE, somme des carrés expliqués, traduit la variabilité expliquée par le modèle ;
- SCR, somme des carrés résiduels correspond à la variabilité non-expliquée par le modèle.
Toutes ces informations sont résumées dans un tableau, le tableau d'analyse de variance.
Source de variation Somme des carrés Degrés de liberté Carrés moyens Expliquée 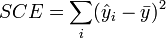
p 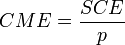
Résiduelle 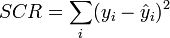
n - p - 1 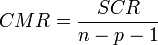
Totale 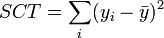
n - 1 Dans le meilleur des cas, SCR = 0, le modèle arrive à prédire exactement toutes les valeurs de y à partir des valeurs des x j. Dans le pire des cas, SCE = 0, le meilleur prédicteur de y est sa moyenne
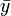 .
.Un indicateur spécifique permet de traduire la variance expliquée par le modèle, il s'agit du coefficient de détermination. Sa formule est la suivante :
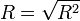 est le coefficent de corrélation multiple.
est le coefficent de corrélation multiple.Dans une régression avec constante, nous avons forcément
- 0 ≤ R ² ≤ 1.
Enfin, si le R ² est certes un indicateur pertinent, il présente un défaut parfois ennuyeux, il a tendance à mécaniquement augmenter à mesure que l'on ajoute des variables dans le modèle. De ce fait, il est inopérant si l'on veut comparer des modèle comportant un nombre différent de variables. Il est conseillé dans ce cas d'utiliser le coefficient de détermination ajusté qui est corrigé des degrés de libertés :
Significativité globale du modèle
Le R ² est un indicateur simple, on comprend aisément que plus il s'approche de la valeur 1, plus le modèle est intéressant. En revanche, il ne permet pas de savoir si le modèle est statistiquement pertinent pour expliquer les valeurs de y.
Nous devons nous tourner vers les tests d'hypothèses pour vérifier si la liaison mise en évidence avec la régression n'est pas un simple artefact.
La formulation du test d'hypothèse qui permet d'évaluer globalement le modèle est la suivante :
- H0 : a1 = a2 = … = ap = 0 ;
- H1 : un des coefficients au moins est non nul.
La statistique dédiée à ce test s'appuie (parmi les différentes formulations possibles) sur le R ², il s'écrit :
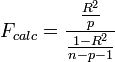 ,
,
et suit une loi de Fisher à (p, n - p - 1) degrés de liberté.
La région critique du test est donc : rejet de H0 si et seulement si Fcalc > F1 - α(p, n - p - 1), où α est le risque de première espèce.
Une autre manière de lire le test est de comparer la p-value (probabilité critique du test) avec α : si elle est inférieure, l'hypothèse nulle est rejetée.
Un exemple
Les données CARS disponibles sur le site DASL ont été utilisées pour illustrer la régression linéaire multiple.
L'objectif est de prédire la consommation des véhicules, exprimée en MPG (miles parcouru par gallon de carburant, plus le chiffre est élevé, moins la voiture consomme) à partir de leurs caractéristiques (weight — poids, drive ratio — rapport de pont, horsepower — puissance, …). Conformément à ce qui est indiqué sur le site, l'observation « Buick Estate Wagon », qui est un point atypique, a été supprimée de l'analyse.
Les résultats sont consignés dans les tableaux suivants :Résultats globaux Variable endogène MPG Exemples 37 R ² 0,933 367 R ² ajusté 0,922 62 Erreur σ 1,809 093 Test F(5,31) 86,847 2 (0,000 000) 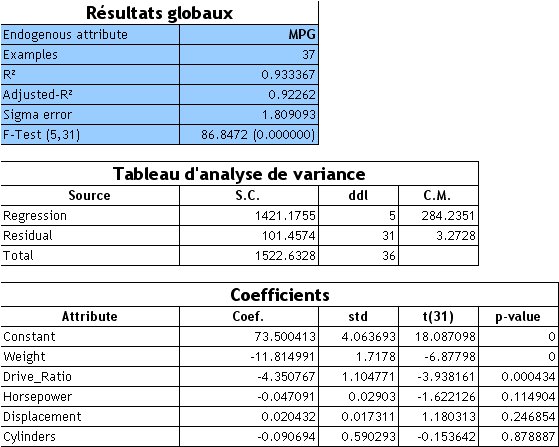
- La variance expliquée par le modèle est de R ² = 0,93, ce qui est elévé ; le modèle semble très bon ;
- le tableau d'analyse de variance et le test F associé indique effectivement que le modèle est globalement très significatif ; Fcalc = 86,84, avec une probabilité critique (p-value) très nettement en-deça du seuil de 5 % couramment utilisé dans la pratique ;
- les variables significatives sont le poids (weight) et le rapport de pont (drive ratio). Les autres semblent sans effet dans l'explication de la consommation.
Cette lecture très simplifiée du rôle des variables doit bien sûr être relativisée. La puissance (horsepower) est vraisemblablement masquée par le poids auquel elle est très fortement corrélée. Ce problème de colinéarité des exogènes est crucial dans la régression. Il faut le détecter, et il faut le traiter. Il existe des méthodes de sélection automatique de variables pour y rémedier, l'expert du domaine joue également un rôle important. C'est pour cette raison par exemple qu'en économie, une analyse de régression doit être accompagnée d'une analyse économique fine des causalités que l'on essaie de déceler.
Régression de séries temporelles
La régression de séries temporelles, c'est-à-dire de variables indexées par le temps, peut poser des problèmes, en particulier à cause de la présence d'autocorrélation dans les variables donc aussi dans les résidus. Dans des cas extrêmes (lorsque les variables ne sont pas stationnaires), on aboutit au cas de régression fallacieuse: des variables qui n'ont aucune relation entre elles apparaissent pourtant significativement liées selon les tests classiques.
La régression de séries temporelles demande donc dans certains cas l'application d'autres modèles de régression, comme les modèles vectoriels autorégressifs (VAR) ou les modèles à correction d'erreur (VECM).
Voir aussi
Références
- Régis Bourbonnais, Économétrie, Dunod, 1998 (ISBN 2100038605)
- Yadolah Dodge et Valentin Rousson, Analyse de régression appliquée, Dunod, 2004 (ISBN 2100486594)
- R. Giraud, N. Chaix, Économétrie, Puf, 1994
- C. Labrousse, Introduction à l'économétrie -- Maîtrise d'économétrie, Dunod, 1983
Articles connexes
Logiciels
- Regress32, un logiciel dédié à la régression linéaire multiple.
- Tanagra, un logiciel de statistique et d'analyse de données, comportant un module de régression.
- Free Statistics, un portail recensant plusieurs logiciels de statistique libres et gratuits, plusieurs d'entre eux traitent de la régression linéaire multiple.
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégorie : Estimation (statistique)
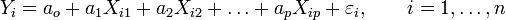
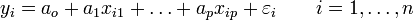
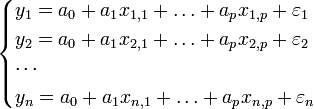
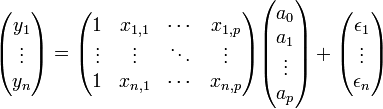
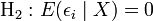
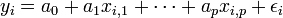
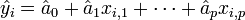
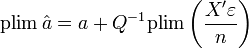
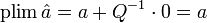
![\operatorname{Var}(\hat a)\equiv \Sigma = \operatorname{E}[(\hat a- a)(\hat a- a)']](/pictures/frwiki/57/98f0798443d48ea38c2eeada6eac8629.png)
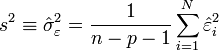
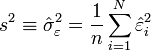
![\hat{\operatorname{Var}[{\hat a}]}\equiv \hat \Sigma_{\hat a} = \hat \sigma_{\varepsilon}^{2}(X'X)^{-1}](/pictures/frwiki/49/1842dad948a617cbe372e39ce32282fc.png)
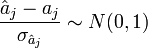
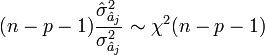
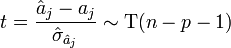
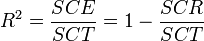
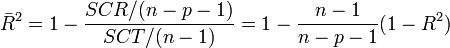
Wikimedia Foundation. 2010.