- Chaîne de Markov à espace d'états discret
-
Chaîne de Markov
Selon les auteurs, une chaîne de Markov est de manière générale un processus de Markov à temps discret ou un processus de Markov à temps discret et à espace d'états discret. En mathématiques, un processus de Markov est un processus stochastique possédant la propriété de Markov : de manière simplifiée, la prédiction du futur, sachant le présent, n'est pas rendue plus précise par des éléments d'information supplémentaires concernant le passé. Les processus de Markov portent le nom de leur découvreur, Andrei Markov.
Un processus de Markov à temps discret est une séquence
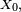
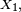
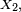
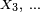 de variables aléatoires à valeurs dans l’espace des états, qu'on notera
de variables aléatoires à valeurs dans l’espace des états, qu'on notera 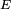 dans la suite. La valeur
dans la suite. La valeur 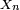 est l'état du processus à l'instant
est l'état du processus à l'instant 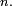 Les applications où l'espace d'états est fini ou dénombrable sont innombrables : on parle alors de chaîne de Markov ou de chaînes de Markov à espace d'états discret. Les propriétés essentielles des processus de Markov généraux, par exemple les propriétés de récurrence et d'ergodicité, s'énoncent ou se démontrent plus simplement dans le cas des chaînes de Markov à espace d'états discret. Cet article concerne précisément les chaînes de Markov à espace d'états discret.
Les applications où l'espace d'états est fini ou dénombrable sont innombrables : on parle alors de chaîne de Markov ou de chaînes de Markov à espace d'états discret. Les propriétés essentielles des processus de Markov généraux, par exemple les propriétés de récurrence et d'ergodicité, s'énoncent ou se démontrent plus simplement dans le cas des chaînes de Markov à espace d'états discret. Cet article concerne précisément les chaînes de Markov à espace d'états discret.Andrei Markov a publié les premiers résultats sur les chaînes de Markov à espace d'états fini en 1906. Une généralisation à un espace d'états infini dénombrable a été publiée par Kolmogorov en 1936. Les processus de Markov sont liés au mouvement brownien et à l'hypothèse ergodique, deux sujets de physique statistique qui ont été très importants au début du XXe siècle.
Sommaire
Propriété de Markov faible
Article détaillé : Propriété de Markov.Définitions
C'est la propriété caractéristique d'une chaîne de Markov : en gros, la prédiction du futur à partir du présent n'est pas rendue plus précise par des éléments d'information supplémentaires concernant le passé, car toute l'information utile pour la prédiction du futur est contenue dans l'état présent du processus. La propriété de Markov faible possède plusieurs formes équivalentes qui reviennent toutes à constater que la loi conditionnelle de
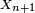 sachant le passé, i.e. sachant
sachant le passé, i.e. sachant 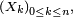 est une fonction de seul :
est une fonction de seul :On suppose le plus souvent les chaînes de Markov homogènes, i.e. on suppose que le mécanisme de transition ne change pas au cours du temps. La propriété de Markov faible prend alors la forme suivante :
Cette forme de la propriété de Markov faible est plus forte que la forme précédente, et entraîne en particulier que
Dans la suite de l'article on ne considèrera que des chaînes de Markov homogènes. Pour une application intéressante des chaînes de Markov non homogènes à l'optimisation combinatoire, voir l'article Recuit simulé. Il existe une propriété de Markov forte, liée à la notion de temps d'arrêt : cette propriété de Markov forte est cruciale pour la démonstration de résultats importants (divers critères de récurrence, loi forte des grands nombres pour les chaînes de Markov). Elle est énoncée dans l'article "Propriété de Markov".
Critère
Critère fondamental — Soit une suite
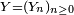 de variables aléatoires indépendantes et de même loi, à valeurs dans un espace
de variables aléatoires indépendantes et de même loi, à valeurs dans un espace  , et soit
, et soit  une application mesurable de
une application mesurable de 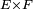 dans
dans 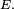 Supposons que la suite
Supposons que la suite 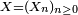 est définie par la relation de récurrence :
est définie par la relation de récurrence :et supposons que la suite
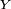 est indépendante de
est indépendante de 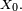 Alors
Alors 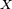 est une chaîne de Markov homogène.Collectionneur de vignettes (coupon collector) :
est une chaîne de Markov homogène.Collectionneur de vignettes (coupon collector) :Petit Pierre fait la collection des portraits des onze joueurs de l'équipe nationale de football, qu'il trouve sur des vignettes à l'intérieur de l'emballage des tablettes de chocolat Cémoi ; chaque fois qu'il achète une tablette il a une chance sur 11 de tomber sur le portrait du joueur n°
 (pour tout ). On note
(pour tout ). On note ![\scriptstyle\ X_{n}\in\mathcal{P}([\![ 1,11]\!])\](/pictures/frwiki/97/a724e9ac3370b700a53a33ea3da4024f.png) l'état de la collection de Petit Pierre, après avoir ouvert l'emballage de sa
l'état de la collection de Petit Pierre, après avoir ouvert l'emballage de sa  -ème tablette de chocolat. est une chaîne de Markov partant de
-ème tablette de chocolat. est une chaîne de Markov partant de 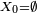 , car elle rentre dans le cadre précédent pour le choix
, car elle rentre dans le cadre précédent pour le choix ![\scriptstyle\ F=[\![1,11]\!],\ E=\mathcal{P}(F),\ f(x,y)=x\cup\{y\},\](/pictures/frwiki/51/372498e85e6edf20771a7d7b8b861881.png) puisque
puisqueoù les variables aléatoires
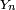 sont des variables aléatoires indépendantes et uniformes sur
sont des variables aléatoires indépendantes et uniformes sur ![\scriptstyle\ [\![1,11]\!]\](/pictures/frwiki/101/e76ea9e4de780d45f1e611b71c61ffb5.png) : ce sont les numéros successifs des vignettes tirées des tablettes de chocolat. Le temps moyen nécessaire pour compléter la collection (ici le nombre de tablettes que Petit Pierre doit acheter en moyenne pour compléter sa collec') est, pour une collection de
: ce sont les numéros successifs des vignettes tirées des tablettes de chocolat. Le temps moyen nécessaire pour compléter la collection (ici le nombre de tablettes que Petit Pierre doit acheter en moyenne pour compléter sa collec') est, pour une collection de 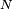 vignettes au total, de
vignettes au total, de 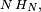 où
où 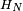 est le -ème nombre harmonique. Par exemple,
est le -ème nombre harmonique. Par exemple, 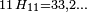 tablettes de chocolat.Remarques :
tablettes de chocolat.Remarques :- La propriété de Markov découle de l'indépendance des
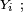 elle reste vraie lorsque les
elle reste vraie lorsque les 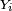 ont des lois différentes, et lorsque la "relation de récurrence"
ont des lois différentes, et lorsque la "relation de récurrence" 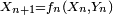 dépend de
dépend de 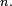 Les hypothèses faites en sus de l'indépendance sont là uniquement pour assurer l'homogénéité de la chaîne de Markov.
Les hypothèses faites en sus de l'indépendance sont là uniquement pour assurer l'homogénéité de la chaîne de Markov. - Le critère est fondamental en cela que toute chaîne de Markov homogène peut être simulée via une récurrence de la forme
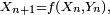 pour une fonction bien choisie. On peut même choisir
pour une fonction bien choisie. On peut même choisir ![\scriptstyle\ F=[0,1],\](/pictures/frwiki/101/ec112d58275f3bfdad8c05658666a1cd.png) et choisir des variables
et choisir des variables 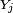 indépendantes et uniformes sur l'intervalle [0,1], ce qui est commode pour l'étude de chaînes de Markov via des méthodes de Monte-Carlo.
indépendantes et uniformes sur l'intervalle [0,1], ce qui est commode pour l'étude de chaînes de Markov via des méthodes de Monte-Carlo.
Probabilités de transition
Définition — Le nombre
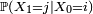 est appelé probabilité de transition de l'état
est appelé probabilité de transition de l'état  à l'état
à l'état 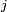 en un pas, ou bien probabilité de transition de l'état à l'état
en un pas, ou bien probabilité de transition de l'état à l'état 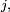 s'il n'y a pas d'ambiguité. On note souvent ce nombre
s'il n'y a pas d'ambiguité. On note souvent ce nombre 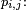
- La famille de nombres
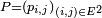 est appelée matrice de transition, noyau de transition, ou opérateur de transition de la chaîne de Markov.
est appelée matrice de transition, noyau de transition, ou opérateur de transition de la chaîne de Markov.
La terminologie matrice de transition est la plus utilisée, mais elle n'est appropriée, en toute rigueur, que lorsque, pour un entier
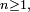
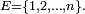 Lorsque est fini, par exemple de cardinal
Lorsque est fini, par exemple de cardinal 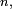 on peut toujours numéroter les éléments de arbitrairement de 1 à ce qui règle le problème, mais imparfaitement, car cette renumérotation est contre-intuitive dans beaucoup d'exemples.Modèle d'Ehrenfest : les deux chiens et leurs puces :
on peut toujours numéroter les éléments de arbitrairement de 1 à ce qui règle le problème, mais imparfaitement, car cette renumérotation est contre-intuitive dans beaucoup d'exemples.Modèle d'Ehrenfest : les deux chiens et leurs puces :Deux chiens se partagent
puces de la manière suivante : à chaque instant, une des puces est choisie au hasard et saute alors d'un chien à l'autre. L'état du système est décrit par un élément 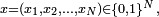 où
oùAlors
possède 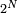 éléments, mais les numéroter de 1 à serait malcommode pour suivre l'évolution du système, qui consiste à choisir une des coordonnées de
éléments, mais les numéroter de 1 à serait malcommode pour suivre l'évolution du système, qui consiste à choisir une des coordonnées de  au hasard et à changer sa valeur. Si l'on veut comprendre le système moins en détail (car on n'est pas capable de reconnaître une puce d'une autre), on peut se contenter d'étudier le nombre de puces sur le chien n°1, ce qui revient à choisir
au hasard et à changer sa valeur. Si l'on veut comprendre le système moins en détail (car on n'est pas capable de reconnaître une puce d'une autre), on peut se contenter d'étudier le nombre de puces sur le chien n°1, ce qui revient à choisir  Là encore, pour la compréhension, il serait dommage de renuméroter les états de 1 à
Là encore, pour la compréhension, il serait dommage de renuméroter les états de 1 à 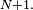 Notons que pour cette nouvelle modélisation,
Notons que pour cette nouvelle modélisation,puisque, par exemple, le nombre de puces sur le dos du chien n°1 passe de k à k-1 si c'est une de ces k puces qui est choisie pour sauter, parmi les N puces présentes dans le "système". Ce modèle porte plus souvent le nom de "modèle des urnes d'Ehrenfest". Il a été introduit en 1907 par Paul et Tatiana Ehrenfest pour illustrer certains des « paradoxes » apparus dans les fondements de la mécanique statistique naissante, et pour modéliser le bruit rose. Le modèle des urnes d'Ehrenfest était considéré par le mathématicien Mark Kac [1] comme « ... probablement l'un des modèles les plus instructifs de toute la physique ... »
Plutôt que de renuméroter les états à partir de 1, il est donc plus ergonomique dans beaucoup de cas d'accepter des matrices finies ou infinies dont les lignes et colonnes sont "numérotées" à l'aide des éléments de
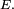 Le produit de deux telles "matrices",
Le produit de deux telles "matrices", 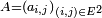 et
et 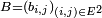 , est alors défini très naturellement par
, est alors défini très naturellement parpar analogie avec la formule plus classique du produit de deux matrices carrées de taille
Proposition — La matrice de transition
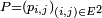 est stochastique : la somme des termes de n'importe quelle ligne de
est stochastique : la somme des termes de n'importe quelle ligne de 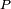 donne toujours 1.
donne toujours 1.Proposition — La loi de la chaîne de Markov
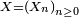 est caractérisée par le couple constitué de sa matrice de transition
est caractérisée par le couple constitué de sa matrice de transition 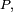 et de sa loi initiale (la loi de
et de sa loi initiale (la loi de 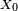 ) : pour tout
) : pour tout 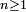 la loi jointe de
la loi jointe de 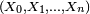 est donnée parDémonstration
est donnée parDémonstrationPar récurrence, au rang 0,
Au rang
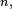 en posant
en posant 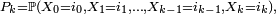
en vertu de la propriété de Markov faible, donc si
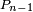 a l'expression attendue, alors
a l'expression attendue, alors 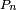 aussi.
aussi.Lorsqu'on étudie une chaîne de Markov particulière, sa matrice de transition est en général bien définie et fixée tout au long de l'étude, mais la loi initiale peut changer lors de l'étude et les notations doivent refléter la loi initiale considérée sur le moment : si à un moment de l'étude on considère une chaîne de Markov de loi initiale définie par
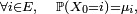 alors les probabilités sont notées
alors les probabilités sont notées 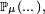 et les espérances sont notées
et les espérances sont notées ![\scriptstyle\ \mathbb{E}_{\mu}\left[\dots\right].\quad](/pictures/frwiki/51/3e2421993f873822f3b9e2d8663d4de1.png) En particulier, si
En particulier, si 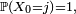 on dit que la chaîne de Markov part de
on dit que la chaîne de Markov part de 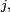 les probabilités sont notées
les probabilités sont notées 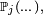 et les espérances sont notées
et les espérances sont notées ![\scriptstyle\ \mathbb{E}_{j}\left[\dots\right].\quad](/pictures/frwiki/53/5135c6bcf8632270695e11834cf2f1cf.png)
Pour
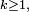 la probabilité de transition en pas,
la probabilité de transition en pas, 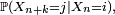 ne dépend pas de
ne dépend pas de  :
:Proposition — La matrice de transition en
pas, 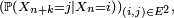 est égale à la puissance
est égale à la puissance  -ème de la matrice de transition
-ème de la matrice de transition 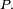 On note
On noteet
DémonstrationPar récurrence. Au rang 1, c'est une conséquence de l'homogénéité de la chaîne de Markov déjà mentionnée à la section Propriété de Markov faible :
Au rang
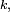
où
- la 2-ème égalité est la formule des probabilités totales,
- la 3-ème égalité est due à une forme de propriété de Markov faible,
- la 4-ème égalité est la propriété de récurrence au pas
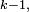
- la 5-ème égalité est la formule du produit de deux "matrices", appliquée au produit de
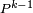 avec
avec
Pour conclure, on divise les deux termes extrêmes de cette suite d'égalités par
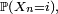 sauf si ce dernier terme est nul, auquel cas on peut définir
sauf si ce dernier terme est nul, auquel cas on peut définir 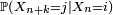 arbitrairement, donc, par exemple, égal à
arbitrairement, donc, par exemple, égal à 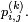
Par une simple application de la formule des probabilités totales, on en déduit les lois marginales de la chaîne de Markov.
Corollaire — La loi de
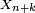 est donnée par
est donnée parEn particulier,
En écriture matricielle, si la loi de
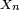 est considérée comme un vecteur-ligne
est considérée comme un vecteur-ligne 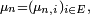 avec
avec 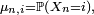 cela se reformule en :
cela se reformule en :Classification des états
Article détaillé : Graphe d'une chaîne de Markov et classification des états.Pour
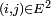 , on dit que est accessible à partir de si et seulement s'il existe
, on dit que est accessible à partir de si et seulement s'il existe 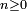 tel que
tel que 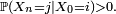 On note :
On note :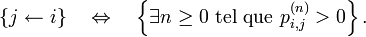
On dit que
et communiquent si et seulement s'il existe 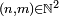 tels que et
tels que et 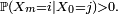 On note :
On note :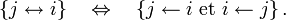
La relation communiquer, notée
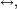 est une relation d'équivalence. Quand on parle de classe en parlant des états d'une chaîne de Markov, c'est général aux classes d'équivalence pour la relation
est une relation d'équivalence. Quand on parle de classe en parlant des états d'une chaîne de Markov, c'est général aux classes d'équivalence pour la relation  qu'on fait référence. Si tous les états communiquent, la chaîne de Markov est dite irréductible.
qu'on fait référence. Si tous les états communiquent, la chaîne de Markov est dite irréductible.La relation être accessible, notée
 s'étend aux classes d'équivalence : pour deux classes
s'étend aux classes d'équivalence : pour deux classes  et
et  , on a
, on a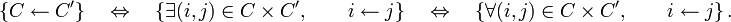
La relation
 est une relation d'ordre entre les classes d'équivalence.
est une relation d'ordre entre les classes d'équivalence.
Une classe est dite finale si elle ne conduit à aucune autre, i.e. si la classe est minimale pour la relation Sinon, elle est dite transitoire. L'appartenance à une classe finale ou transitoire a des conséquences sur les propriétés probabilistes d'un état de la chaîne de Markov, en particulier sur son statut d'état récurrent ou d'état transient. Le nombre et la nature des classes finales dicte la structure de l'ensemble des probabilités stationnaires, qui résument de manière précise le comportement asymptotique de la chaîne de Markov, comme on peut le voir à la prochaine section et dans les deux exemples détaillés à la fin de cette page.
Sinon, elle est dite transitoire. L'appartenance à une classe finale ou transitoire a des conséquences sur les propriétés probabilistes d'un état de la chaîne de Markov, en particulier sur son statut d'état récurrent ou d'état transient. Le nombre et la nature des classes finales dicte la structure de l'ensemble des probabilités stationnaires, qui résument de manière précise le comportement asymptotique de la chaîne de Markov, comme on peut le voir à la prochaine section et dans les deux exemples détaillés à la fin de cette page.Soit
La période d'un état
est le PGCD de l'ensemble 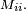 Si deux états communiquent, ils ont la même période : on peut donc parler de la période d'une classe d'états. Si la période vaut 1, la classe est dite apériodique. L'apériodicité des états d'une chaîne de Markov conditionne la convergence de la loi de vers la probabilité stationnaire, voir la page Probabilité stationnaire d'une chaîne de Markov.
Si deux états communiquent, ils ont la même période : on peut donc parler de la période d'une classe d'états. Si la période vaut 1, la classe est dite apériodique. L'apériodicité des états d'une chaîne de Markov conditionne la convergence de la loi de vers la probabilité stationnaire, voir la page Probabilité stationnaire d'une chaîne de Markov.
La classification des états et leur période se lisent de manière simple sur le graphe de la chaîne de Markov. Toutefois, si tous les éléments de la matrice de transition sont strictement positifs, la chaîne de Markov est irréductible et apériodique : dessiner le graphe de la chaîne de Markov est alors superflu.
Loi stationnaire
Article détaillé : Probabilité stationnaire d'une chaîne de Markov.Définition
Il peut exister une ou plusieurs mesures
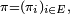 sur l'espace d'états
sur l'espace d'états 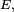 telles que :
telles que :ou bien encore
Une telle mesure
 est appelée une mesure stationnaire. Une mesure stationnaire est une fonction propre de la transposée de la matrice de transition, associée à la valeur propre 1. Elle est appelée probabilité stationnaire ou loi stationnaire si elle remplit les conditions supplémentaires :
est appelée une mesure stationnaire. Une mesure stationnaire est une fonction propre de la transposée de la matrice de transition, associée à la valeur propre 1. Elle est appelée probabilité stationnaire ou loi stationnaire si elle remplit les conditions supplémentaires :Si la loi initiale de la chaîne de Markov (i.e. la loi de
) est une probabilité stationnaire 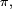 alors pour tout
alors pour tout 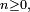 la loi de est
la loi de est 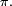 Plus généralement, la chaîne de Markov est un processus stationnaire si et seulement si sa loi initiale est une probabilité stationnaire.
Plus généralement, la chaîne de Markov est un processus stationnaire si et seulement si sa loi initiale est une probabilité stationnaire.Existence et unicité
Article détaillé : Récurrence et transience d'une chaîne de Markov.Dans le cas des chaînes de Markov à espace d'états discret, certaines propriétés du processus déterminent s'il existe ou non une probabilité stationnaire, et si elle est unique ou non :
- une chaîne de Markov est irréductible si tout état est accessible à partir de n'importe quel autre état ;
- un état est récurrent positif si l'espérance du temps de premier retour en cet état, partant de cet état, est finie.
Si une chaîne de Markov possède au moins un état récurrent positif, alors il existe une probabilité stationnaire. S'il existe une probabilité stationnaire
telle que 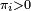 , alors l'état est récurrent positif, et réciproquement.
, alors l'état est récurrent positif, et réciproquement.Théorème — Si une chaîne de Markov possède une seule classe finale
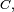 alors il existe au plus une probabilité stationnaire. On a alors équivalence entre les 3 propositions :
alors il existe au plus une probabilité stationnaire. On a alors équivalence entre les 3 propositions :- il existe une unique probabilité stationnaire, notée
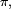
- il existe un état récurrent positif,
- tous les états de la classe finale sont récurrents positifs.
On a de plus l'équivalence
Ce théorème vaut en particulier pour les chaînes de Markov irréductibles, puisque ces dernières possèdent une seule classe (qui est donc nécessairement une classe finale) ; les chaînes de Markov irréductibles vérifient en particulier
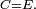
Loi forte des grands nombres et ergodicité
Dans le cas d'une chaîne de Markov irréductible et récurrente positive, la loi forte des grands nombres est en vigueur : la moyenne d'une fonction
sur les instances de la chaîne de Markov est égale à sa moyenne selon sa probabilité stationnaire. Plus précisément, sous l'hypothèseon a presque sûrement :
La moyenne de la valeur des instances est donc, sur le long terme, égale à l'espérance suivant la probabilité stationnaire. En particulier, cette équivalence sur les moyennes s'applique si
est la fonction indicatrice d'un sous-ensemble 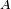 de l'espace des états :
de l'espace des états :Cela permet d'approcher la probabilité stationnaire par la distribution empirique (qui est un histogramme construit à partir d'une séquence particulière), comme par exemple dans le cas de la marche aléatoire avec barrière.
En particulier, si le processus est construit en prenant la probabilité stationnaire comme loi initiale, le shift
 défini par
défini parpréserve la mesure, ce qui fait de la chaîne de Markov un système dynamique. La loi forte des grands nombres entraine alors que la chaîne de Markov est un système dynamique ergodique. L'ergodicité est à la fois plus forte que la loi forte des grands nombres car on peut en déduire, par exemple, que
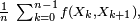 a pour limite presque sûre
a pour limite presque sûre 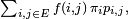 mais elle est aussi plus faible car elle réclame en principe la stationnarité de la chaîne de Markov, ce qui n'est pas le cas de la loi forte des grands nombres.
mais elle est aussi plus faible car elle réclame en principe la stationnarité de la chaîne de Markov, ce qui n'est pas le cas de la loi forte des grands nombres.Convergence vers la loi stationnaire
Si la chaîne de Markov est irréductible, récurrente positive et apériodique, alors
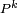 converge vers une matrice dont chaque ligne est l'unique distribution stationnaire En particulier, la loi
converge vers une matrice dont chaque ligne est l'unique distribution stationnaire En particulier, la loi 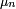 de converge vers indépendamment de la loi initiale
de converge vers indépendamment de la loi initiale 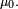 Dans le cas d'un espace d'état fini, cela se prouve par le théorème de Perron-Frobenius. Notons qu'il est naturel que la suite
Dans le cas d'un espace d'état fini, cela se prouve par le théorème de Perron-Frobenius. Notons qu'il est naturel que la suite 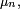 définie par récurrence par la relation
définie par récurrence par la relation 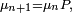 ait, éventuellement, pour limite un point fixe de cette transformation, i.e. une solution de l'équation
ait, éventuellement, pour limite un point fixe de cette transformation, i.e. une solution de l'équation 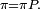
Chaînes de Markov à espace d'états fini
Si une chaîne de Markov est irréductible et si son espace d'états est fini, tous ses états sont récurrents positifs. La loi forte des grands nombres est alors en vigueur.
Plus généralement, tous les éléments d'une classe finale finie sont récurrents positifs, que l'espace d'états soit fini ou bien infini dénombrable.
Notation
Dans les formules qui précèdent, l'élément (i, j) est la probabilité de la transition de i à j. La somme des éléments d'une ligne vaut toujours 1 et la distribution stationnaire est donnée par le vecteur propre gauche de la matrice de transition.
On rencontre parfois des matrices de transition dans lesquelles le terme (i,j) est la probabilité de transition de j vers i, auquel cas la matrice de transition est simplement la transposée de celle décrite ici. La somme des éléments d'une colonne vaut alors 1. De plus, la distribution stationnaire du système est alors donnée par le vecteur propre droit de la matrice de transition, au lieu du vecteur propre gauche.
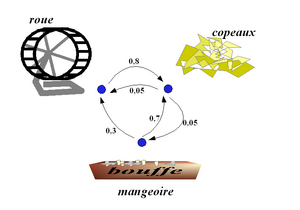
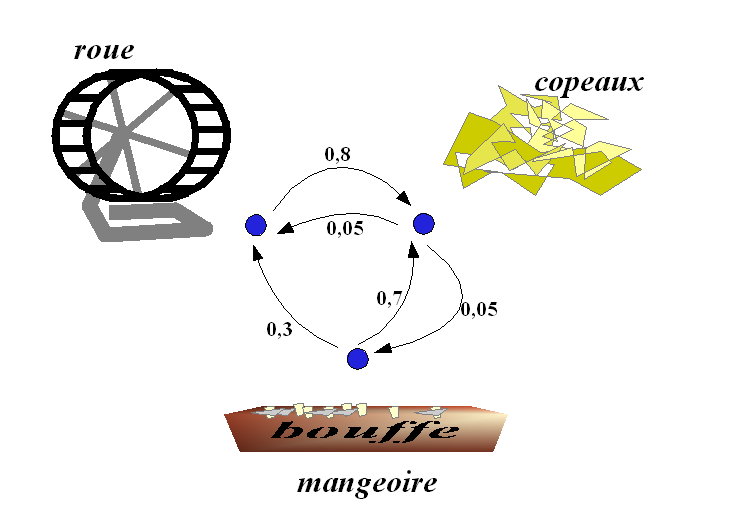
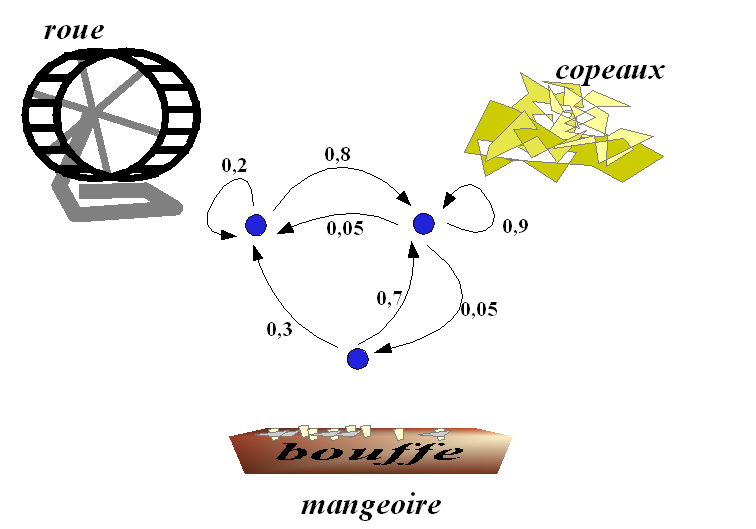
Exemple : Doudou le hamster
Doudou, le hamster paresseux, ne connaît que trois endroits dans sa cage : les copeaux où il dort, la mangeoire où il mange et la roue où il fait de l'exercice. Ses journées sont assez semblables les unes aux autres, et son activité se représente aisément par une chaîne de Markov. Toutes les minutes, il peut soit changer d'activité, soit continuer celle qu'il était en train de faire. L'appellation processus sans mémoire n'est pas du tout exagérée pour parler de Doudou.
- Quand il dort, il a 9 chances sur 10 de ne pas se réveiller la minute suivante.
- Quand il se réveille, il y a 1 chance sur 2 qu'il aille manger et 1 chance sur 2 qu'il parte faire de l'exercice.
- Le repas ne dure qu'une minute, après il fait autre chose.
- Après avoir mangé, il y a 3 chances sur 10 qu'il parte courir dans sa roue, mais surtout 7 chances sur 10 qu'il retourne dormir.
- Courir est fatigant ; il y a 8 chances sur 10 qu'il retourne dormir au bout d'une minute. Sinon il continue en oubliant qu'il est déjà un peu fatigué.
Diagrammes
Les diagrammes peuvent montrer toutes les flèches, chacune représentant une probabilité de transition. Cependant, c'est plus lisible si :
- on ne dessine pas les flèches de probabilité zéro (transition impossible) ;
- on ne dessine pas les boucles (flèche d'un état vers lui-même). Cependant elles existent ; leur probabilité est sous-entendue car on sait que la somme des probabilités des flèches partant de chaque état doit être égale à 1.
exemple avec boucles implicites
exemple avec boucles dessinées
Matrice de transition
La matrice de transition de ce système est la suivante (les lignes et les colonnes correspondent dans l'ordre aux états représentés sur le graphe par copeaux, mangeoire, roue) :
Prévisions
Prenons l'hypothèse que Doudou dort lors de la première minute de l'étude.
Au bout d'une minute, on peut prédire :
Ainsi, après une minute, on a 90 % de chances que Doudou dorme encore, 5 % qu'il mange et 5 % qu'il coure.
Après 2 minutes, il y a 4,5 % de chances que le hamster mange.
De manière générale, pour n minutes :
La théorie montre qu'au bout d'un certain temps, la loi de probabilité est indépendante de la loi initiale. Notons la q :
On obtient la convergence si et seulement si la chaîne est apériodique et irréductible. C'est le cas dans notre exemple, on peut donc écrire :
Sachant que q1 + q2 + q3 = 1, on obtient :
Doudou passe 88,4 % de son temps à dormir !
Illustration de l'impact du modèle
L'exemple qui suit a pour but de montrer l'importance de la modélisation du système. Une bonne modélisation permet de répondre à des questions complexes avec des calculs simples.
On étudie une civilisation (fictive) constituée de plusieurs classes sociales, et dans laquelle les individus peuvent passer d'une classe à l'autre. Chaque étape représentera un an. On considérera une lignée plutôt qu'un individu, pour éviter d'obtenir des citoyens bicentenaires. Les différents statuts sociaux sont au nombre de quatre :
- esclave ;
- libre ;
- citoyen ;
- haut-fonctionnaire.
Dans cette société :
- les esclaves peuvent rester esclaves ou devenir des hommes libres (en achetant leur liberté ou en étant affranchis généreusement par leur maître) ;
- les hommes libres peuvent rester libres ou bien vendre leur liberté (pour payer leurs dettes, etc.) ou encore devenir citoyens (là encore par mérite ou en achetant le titre de citoyen) ;
- les citoyens sont citoyens à vie et transmettent leur citoyenneté à leur lignée (on pourrait croire que le nombre de citoyens tend à augmenter et qu'au bout d'un certain temps, tous sont citoyens mais historiquement, dans les civilisations qui suivaient ce schéma, les citoyens sont décimés par les guerres et de nouveaux esclaves arrivent régulièrement de l'étranger). Ils peuvent aussi se porter candidats lors des élections annuelles afin de devenir hauts-fonctionnaires (magistrats). Au terme de leur mandat, ils peuvent être réélus ou redevenir de simples citoyens.
Pour compliquer un peu l'exemple et montrer ainsi l'étendue des applications des chaînes de Markov, nous considérerons que les fonctionnaires sont élus pour plusieurs années. Par conséquent, l'avenir d'un individu fonctionnaire dépend du temps depuis lequel il est fonctionnaire. Nous sommes donc dans le cas d'une chaîne de Markov non homogène. Heureusement, nous pouvons aisément nous ramener à une chaîne homogène. En effet, il suffit de rajouter un état artificiel pour chaque année du mandat. Au lieu d'avoir un état 4 : Fonctionnaire, nous aurons un état :
- 4 : Fonctionnaire en début de mandat ;
- 5 : Fonctionnaire en seconde année de mandat ;
- etc.
Les probabilités reliant deux états artificiels consécutifs (troisième et quatrième année par exemple) sont de valeur 1 car l'on considère que tout mandat commencé se termine (on pourrait modéliser le contraire en changeant la valeur de ces probabilités). Fixons la durée des mandats à deux ans, le contingent des fonctionnaires étant renouvelable par moitié chaque année. On a alors le graphe suivant :
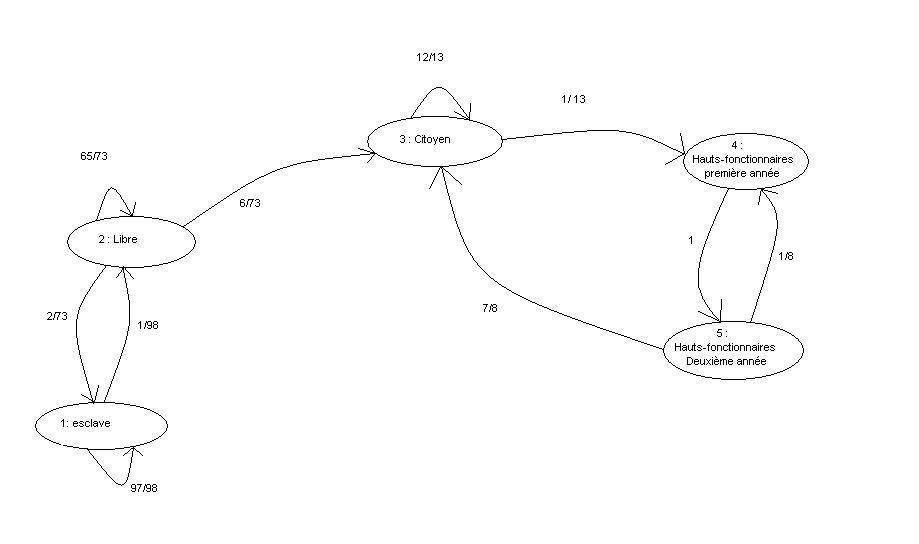
Pour modéliser des élections qui ne seraient pas annuelles, il faudrait de même ajouter des états fictifs (année d'élection, un an depuis la dernière élection, etc.).
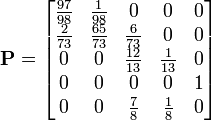
La matrice P s'écrit alors :
Comme cela est expliqué plus haut, Pn donne les probabilités de transition en n étapes. Donc
 est la probabilité d'être dans l'état j au bout de n années pour une lignée partie de la classe sociale i. Pour savoir ce que devient un esclave au bout de n ans, il suffit donc d'écrire :
est la probabilité d'être dans l'état j au bout de n années pour une lignée partie de la classe sociale i. Pour savoir ce que devient un esclave au bout de n ans, il suffit donc d'écrire :Où
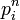 est la probabilité d'être dans la classe sociale i au bout de n années sachant que la lignée étudiée est partie de l'état d'esclave.
est la probabilité d'être dans la classe sociale i au bout de n années sachant que la lignée étudiée est partie de l'état d'esclave.Si on connaît les effectifs de chaque classe sociale à l'an 0, il suffit alors de calculer :
On obtient ainsi la répartition de la population dans les différentes classes sociales (au bout de n années). En multipliant ce vecteur Y par l'effectif total de la population, on obtient les effectifs de chaque classe au bout de n années.
Posons-nous maintenant la question suivante : « Au bout de n années, combien de lignées auront déjà eu un haut fonctionnaire ayant terminé son mandat ? »
La réponse est différente du nombre de mandats effectués en n années car il y a possibilité d'être réélu. Répondre à cette question semble difficile (encore faudrait-il que ce soit possible). En fait, il suffit de changer la modélisation du problème. Passons donc à une nouvelle modélisation pour répondre à cette question. (Par contre, elle ne permet pas de répondre aux questions précédentes d'où la présentation des deux modèles.)
Il suffit de modifier ainsi le graphe :
On ajoute un sommet absorbant car une fois qu'une lignée a fini un mandat, on ne tient plus compte d'elle.
Si certains lecteurs font preuve d'esprit critique, ils diront peut-être que le modèle est faux car les lignées comportant un élu ne participent plus aux élections. Il n'en est rien. En effet, le nombre d'élus est proportionnel au nombre de citoyens. Ne pas réinjecter les anciens hauts-fonctionnaires parmi les candidats ne change donc en rien la probabilité pour un citoyen d'être élu car, la population des citoyens étant plus restreinte, le nombre de postes offerts l'est aussi. Ce modèle permet de répondre avec exactitude à la question posée.
On a donc une nouvelle matrice de transition :
En faisant les mêmes calculs qu'aux questions précédentes on obtient en dernière ligne du vecteur solution le pourcentage de lignées ayant accompli au moins un mandat ou bien l'effectif (si on multiplie par l'effectif total de la population). Autrement dit, modéliser à nouveau le problème permet de répondre à la question qui semblait si compliquée par un simple calcul de puissances d'une matrice.
Applications
- Les systèmes Markoviens sont très présents en physique particulièrement en physique statistique. Plus généralement l'hypothèse markovienne est souvent invoquée lorsque des probabilités sont utilisées pour modéliser l'état d'un système, en supposant toutefois que l'état futur du système peut être déduit du passé avec un historique assez faible.
- Le célèbre article de 1948 de Claude Shannon, A mathematical theory of communication, qui fonde la théorie de l'information, commence en introduisant la notion d'entropie à partir d'une modélisation Markovienne de la langue anglaise. Il montre ainsi le degré de prédictibilité de la langue anglaise, muni d'un simple modèle d'ordre 1. Bien que simples, de tels modèles permettent de bien représenter les propriétés statistiques des systèmes et de réaliser des prédictions efficaces sans décrire la structure complète des systèmes.
- En compression, la modélisation markovienne permet la réalisation de techniques de codage entropique très efficaces, comme le codage arithmétique. De très nombreux algorithmes en reconnaissance des formes ou en intelligence artificielle comme par exemple l'algorithme de Viterbi, utilisé dans la grande majorité des systèmes de téléphonie mobile pour la correction d'erreurs, font l'hypothèse d'un processus markovien sous-jacent.
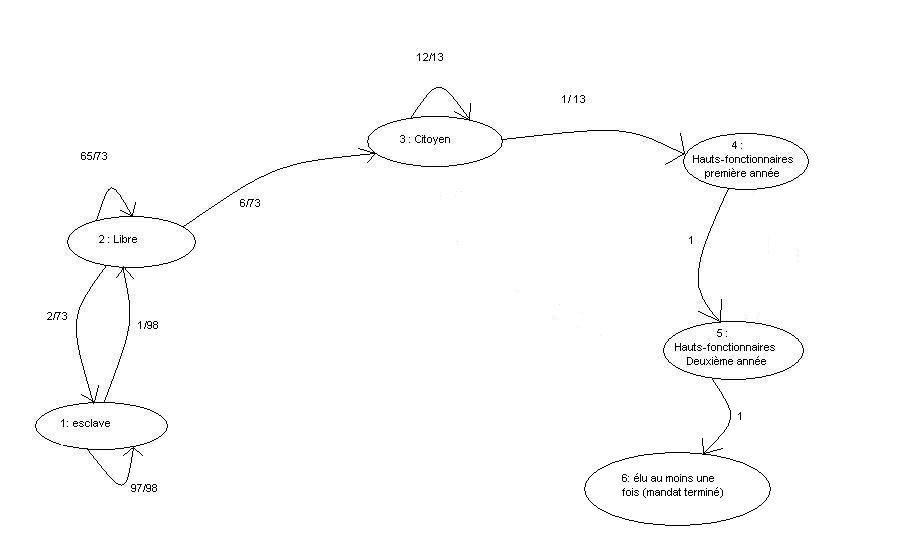
- L'indice de popularité d'une page Web (PageRank) tel qu'il est utilisé par Google est défini par une chaîne de Markov. Il est défini par la probabilité d'être dans cette page à partir d'un état quelconque de la chaine de Markov représentant le Web. Si N est le nombre de pages Web connues, et une page i a ki liens, alors sa probabilité de transition vers une page liée (vers laquelle elle pointe) est
 et
et  pour toutes les autres (pages non liées). Notons qu'on a bien
pour toutes les autres (pages non liées). Notons qu'on a bien 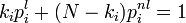 . Le paramètre q vaut environ 0,15.
. Le paramètre q vaut environ 0,15.
- Les chaînes de Markov sont un outil fondamental pour modéliser les processus en théorie des files d'attente et en statistiques.
- Les chaînes de Markov fondent les systèmes de Bonus/Malus mis au point par les actuaires des sociétés d'assurances automobiles (la probabilité d'avoir n accidents au cours de l'année t étant conditionnée par le nombre d'accidents en t-1)
- Les chaînes de Markov sont également utilisées en bioinformatique pour modéliser les relations entre symboles successifs d'une même séquence (de nucléotides par exemple), en allant au delà du modèle polynomial. Les modèles markoviens cachés ont également diverses utilisations, telles que la segmentation (définition de frontières de régions au sein de séquences de gènes ou de protéines dont les propriétés chimiques varient), l'alignement multiple, la prédiction de fonction, ou la découverte de gènes (les modèles markoviens cachés sont plus « flexibles » que les définitions strictes de type codon start + multiples codons + codons stop et ils sont donc plus adaptés pour les eucaryotes (à cause de la présence d'introns dans le génome de ceux-ci) ou pour la découverte de pseudo-gènes).
Voir aussi
- Matrice d'adjacence
- Problème de décision de Markov (MDP)
- Problème de décision de Markov partiellement observable (POMDP)
- Marche aléatoire
- Mouvement brownien
- Modèle des urnes d'Ehrenfest
- Modèle de Markov caché
- Chaîne de Markov à temps continu
- Processus de Markov
- Propriété de Markov
Liens externes
- (en) (pdf) Markov Chains chapter in American Mathematical Society's introductory probability book
- (en) Exemples
- (fr) Exercices corrigés
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de la physique
Portail de la physique
Catégories : Processus stochastique | Physique statistique
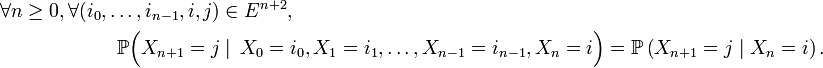
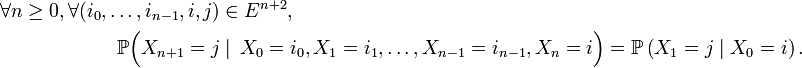
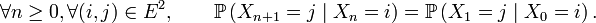
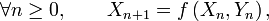
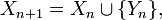
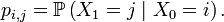
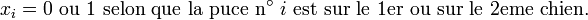
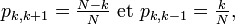
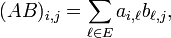
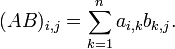
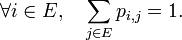
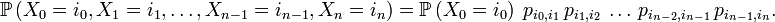
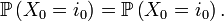
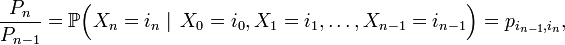
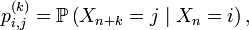
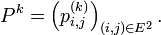
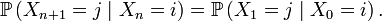
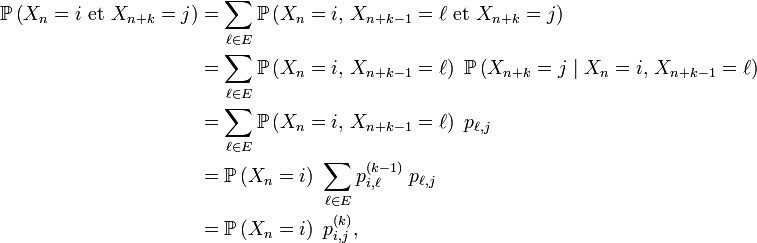
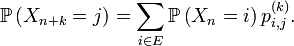
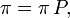
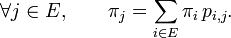

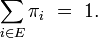
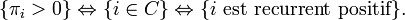
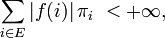
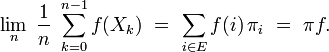
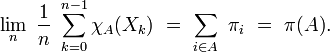
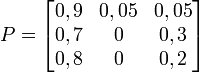
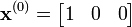
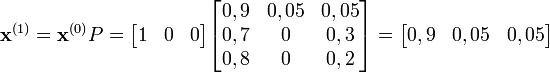
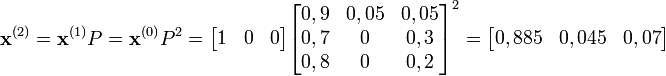
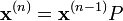
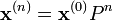
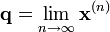
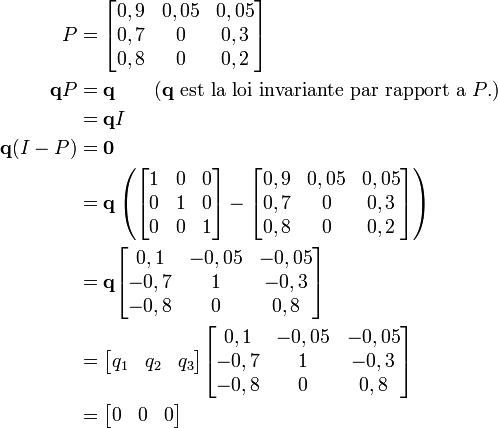
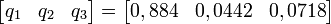
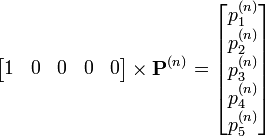
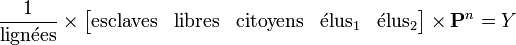

Wikimedia Foundation. 2010.