- Captcha
-
 Ce captcha de « smwm » rend difficile son interprétation par un ordinateur en modifiant la forme des lettres et en ajoutant un dégradé de couleur en fond.
Ce captcha de « smwm » rend difficile son interprétation par un ordinateur en modifiant la forme des lettres et en ajoutant un dégradé de couleur en fond.
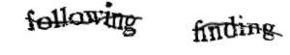 Captcha plus récent (reCAPTCHA) : plutôt que d'utiliser un dégradé du fond et une distorsion des lettres, la segmentation est rendue difficile par l'ajout d'une ligne brisée.
Captcha plus récent (reCAPTCHA) : plutôt que d'utiliser un dégradé du fond et une distorsion des lettres, la segmentation est rendue difficile par l'ajout d'une ligne brisée. Un autre moyen de rendre la segmentation difficile est d'imbriquer les lettres les unes dans les autres, comme dans le format actuel de captcha de Yahoo.
Un autre moyen de rendre la segmentation difficile est d'imbriquer les lettres les unes dans les autres, comme dans le format actuel de captcha de Yahoo.Un captcha est une forme de test de Turing permettant de différencier de manière automatisée un utilisateur humain d'un ordinateur.
C'est un test de défi-réponse utilisé dans le domaine de l'informatique, ayant pour but de s'assurer qu'une réponse n'est pas générée par un ordinateur. L'acronyme « CAPTCHA » est basé sur le mot "capture", et vient de l'anglais "Completely Automated Public Turing test to tell Computers and Humans Apart"[1].
Parce que le test est réalisé par un ordinateur, en opposition avec les tests de Turing standard réalisés par des humains, un captcha est souvent décrit comme un test de Turing inversé. Ce terme est néanmoins ambigu parce qu’il pourrait aussi signifier que les participants essaient de prouver qu'ils sont des ordinateurs.
Sommaire
Applications
Ce test est utilisé sur Internet dans les formulaires pour se prémunir contre les soumissions automatisées et intensives réalisées par des robots malveillants.
La vérification utilise la capacité d'analyse d'image ou de son de l'être humain. Un captcha usuel requiert ainsi que l'utilisateur tape les lettres et les chiffres visibles sur une image distordue qui apparaît à l'écran. Certains sites web préfèrent afficher une image qui contient une question mathématique.
Ils sont utilisés :
- contre le spam :
- lors de l'inscription à des webmails gratuits (dont les comptes pourraient être utilisés par la suite pour l'envoi de courriers non sollicités),
- lors de la soumission de messages dans des forums de discussion et des blogs (qui pourraient permettre de faire du référencement abusif), etc. ;
- contre l'extraction automatisée de bases de données ;
- contre les tentatives d'attaque par force brute ;
- pour la participation à des sondages (dont les résultats pourraient être faussés par des votes automatisés).
À propos du nom
« Captcha » est un rétro-acronyme : le mot se prononce comme capture en anglais américain et est censé être composé des initiales de Completely Automated Public Turing test to Tell Computers and Humans Apart, soit en français, « test public de Turing complètement automatique ayant pour but de différencier les humains des ordinateurs ». Ce terme, qui est une marque déposée par l'université Carnegie Mellon, a été inventé en 2000 par Luis von Ahn, Manuel Blum et Nicholas J. Hopper de cette université, et par John Langford d'IBM. Le nom "captcha" peut également être interprété comme "capture character" (capture de caractères).
Histoire
Dès le début d'Internet, les utilisateurs ont toujours voulu rendre le texte illisible par les ordinateurs. Les premiers furent les hackers, postant sur des sujets sensibles dans des forums en ligne, qui étaient automatiquement surveillés avec des mots-clefs. Pour contourner ces filtres, ces hackers ont commencé à remplacer les mots par des caractères visuellement ressemblants. Par exemple, HELLO pouvait être remplacé par |-|3|_|_() ou )-(3££0, ainsi qu'une multitude d'autres variantes numériques. Ainsi les filtres à mots-clefs ne pouvaient pas tous les détecter. Ce procédé fut plus tard connu sous le nom de « 13375p34k » (leetspeak).
La première réflexion sur la création de tests automatiques qui pourraient distinguer les humains des ordinateurs dans le but de contrôler l'accès aux services web est apparue dans un manuscrit de Moni Naor de l'institut de science de Weizmann, daté de 1996, et intitulé Verification of a human in the loop, or Identification via the Turing Test. Des captcha primitifs semblent avoir été développés plus tard, en 1997 chez AltaVista par Andrei Broder et ses collègues dans le but d'empêcher des robots d'ajouter des sites à leur moteur de recherche.
En recherchant un moyen de rendre leurs images résistantes à des attaques de logiciels de reconnaissance de caractères, l'équipe a cherché dans le manuel de leur numériseur de marque Brother, qui donnait des recommandations pour améliorer les performances de la reconnaissance de caractères (types d'écritures similaires, fond homogène…). L'équipe conçut des puzzles en essayant de simuler ce qui pourrait causer une mauvaise reconnaissance automatique de caractères. En 2000, von Ahn et Blum développèrent et publièrent la notion de captcha, qui comprenait tout programme qui pouvait différencier un humain d'un ordinateur. Ils inventèrent de multiples exemples de captcha, dont les premiers qui furent largement utilisés (par Yahoo! notamment).
Caractéristiques
Les captchas sont, par définition, entièrement automatisés, ne nécessitant qu'une petite intervention humaine lors de l'utilisation du test. Ceci présente donc des bénéfices au niveau des coûts et des performances.
L'algorithme utilisé pour créer un captcha est souvent public, bien qu'il puisse être breveté. Ceci est fait dans le but de démontrer que casser ce type de test nécessite la résolution d'un problème difficile en faisant appel à des notions de l'intelligence artificielle, plutôt que la découverte des secrets de l'algorithme, qui pourraient être obtenus par décompilation ou un autre moyen.
Complexité
La complexité de certains types de ce système contribue à pénaliser l'expérience des internautes contraints d'essayer plusieurs fois des combinaisons possibles. En effet, certains captcha sont tellement déformés pour éviter une reconnaissance automatique que même les internautes ne peuvent les reconnaître. Pire, certain captchas sont plus facilement reconnus par les ordinateurs.
De plus, leur efficacité est contestée, et des captchas peuvent être reconnus en quelques secondes[2].
Accessibilité
Les tests de captcha basés sur une lecture de texte - ou toute autre tâche de perception visuelle - rendent impossible l'accès aux ressources protégées pour des personnes déficientes visuelles. Néanmoins, le captcha n'a pas forcément besoin d'être visuel. N'importe quel problème d'intelligence artificielle, comme la reconnaissance vocale, peut être utilisé comme base pour un test de captcha. Certaines implémentations de captcha permettent aux utilisateurs d'opter pour un captcha audio.
Le développement des captcha audio semble être en retard par rapport aux tests visuels. D'autres types de tests, comme ceux qui nécessitent une compréhension de texte (par exemple, un puzzle logique, des questions ou des instructions pour créer un mot de passe) peuvent aussi constituer des méthodes utilisables dans le cadre d'un captcha. Encore une fois, il n'y a que peu d'études concernant leur résistance face aux contre-mesures.
Quelques tests intéressants apparurent avec l'idée de la reconnaissance d'images. KittenAuth[3] est un test de ce type, qui demande à l'utilisateur de reconnaître un animal (des chatons) dans une série de photographies de différentes espèces (dauphins, chiots, renards, etc.)
Pour les personnes déficientes visuelles (comme les utilisateurs aveugles ou ayant des difficultés à la perception des couleurs), les captcha visuels présentent de sérieuses difficultés. Du fait que les captcha sont conçus pour ne pas être lus par les machines, les outils courants d'aide comme les lecteurs d'écran ne peuvent pas les interpréter. Du fait que certains sites peuvent utiliser les tests de captcha dès le processus d'inscription initial, ou même à chaque connexion, ces derniers peuvent complètement bloquer l'accès. Dans certaines juridictions, les propriétaires de sites peuvent devenir la cible de litiges s'ils utilisent des captcha qui discriminent les gens ayant certains handicaps. Dans d'autres cas, ceux qui ont des difficultés visuelles peuvent choisir d'identifier un mot qui leur est lu.
Bien que fournir un captcha audio permette aux utilisateurs aveugles de lire le texte, ce procédé exclut toujours les personnes souffrant à la fois d’un déficit visuel et auditif[4].
L'utilisation d'un captcha empêche ainsi un grand nombre d'individus d'utiliser tous les services basés sur Internet comme PayPal, Gmail, Orkut, Yahoo!, ainsi que de nombreux forums et blogs.
Même pour des personnes parfaitement voyantes, les nouvelles générations de captcha, conçues pour résister aux logiciels sophistiqués de reconnaissance, peuvent devenir pratiquement impossibles à lire.
Un rapport du W3C a souligné l'inaccessibilité de certains tests visuels anti-robots[5]!
Contournement
Il y a plusieurs approches pour mettre en échec un captcha :
- utiliser une main-d’œuvre humaine pour les reconnaître ;
- exploiter les bogues dans les implémentations qui permettent à l'attaquant de passer complètement outre le captcha ;
- améliorer les logiciels de reconnaissance de caractères ;
- l'attaque par force brute ou l'attaque par dictionnaire, qui peuvent être facilitées par la reconnaissance partielle du captcha (notamment le nombre de caractères).
Main-d’œuvre humaine
Il est possible de passer au travers du test de captcha en utilisant des opérateurs humains employés à décoder les captcha. Une publication du W3C indique qu'un tel opérateur « pourrait aisément vérifier des centaines de captcha par heure ». Des entreprises de services indiennes sont spécialisées dans ce négoce[6]. Des spammeurs ont réussi à contourner la difficulté en créant des sites internet qui demandent à ce que l'utilisateur passe un test de captcha pour y accéder, ce test étant en fait celui requis par un autre site, tel celui de Yahoo pour valider la création d'une nouvelle adresse électronique. L'utilisateur du premier site contribue ainsi, à son insu, aux actes malveillants de ces derniers. Une contre-mesure existe : ajouter, dans le captcha, une expression identifiant clairement son émetteur (telle que « yahoo.fr »).
Bogues de conception
Certains systèmes de protection par captcha mal conçus peuvent parfois être forcés sans utiliser de logiciels de reconnaissance de caractères, mais simplement en réutilisant l'ID d'une session d'une image connue de captcha. Parfois, si une partie du logiciel qui génère le captcha est située côté client (la validation est faite sur un serveur, mais le texte que l'utilisateur doit saisir pour s'identifier est généré côté client), alors les utilisateurs peuvent modifier le logiciel client pour afficher le texte de captcha non déformé par exemple.
Reconnaissance automatique de caractères
Bien que les captcha fussent initialement conçus pour contrer les logiciels de reconnaissance de caractères standards utilisés pour la numérisation par balayage de documents, plusieurs projets de recherche ont prouvé qu'il est possible de décrypter un grand nombre de captcha avec des programmes spécifiquement adaptés à un type de captcha. Pour des captcha avec des lettres déformées, l'approche adaptée est constituée d'une manière générale par les étapes suivantes :
- suppression du fond de l'image, par exemple avec des filtres de couleurs et la détection de lignes fines ;
- segmentation, c'est-à-dire découpe de l'image en plusieurs segments contenant une seule lettre ;
- identification de la lettre contenue dans chaque segment.
Le reCAPTCHA propose une approche semblable.
Publicité
Certaines entreprises proposent d'utiliser le captcha comme vecteur de propagation de publicité[7].
Notes et références
- http://www.captcha.net/
- http://www.xmcopartners.com/article-captcha.html
- KittenAuth.
- D'après sense.org.uk, environ 4 % des gens au Royaume-Uni ont de sérieuses déficiences visuelles et auditives. D'après le Consortium national d'assistance technique pour les enfants et jeunes adultes aveugles, sourds et muets (NTAC), il y avait 9 516 enfants aveugles, sourds et muets aux États-Unis en 2004. L'université Gallaudet cite une estimation de 1993 qui donne 35 000 adultes entièrement aveugles, sourds et muets aux États-Unis. L'estimation de la population aveugle, sourde et muette dépend du degré de handicap retenu dans les définitions.
- [1] « Souvent, ces systèmes de vérification font qu'il est impossible, pour certains utilisateurs handicapés, de créer des comptes, de rédiger des commentaires ou de faire des achats sur les sites, c'est-à-dire que les captcha ne reconnaissent pas les utilisateurs handicapés comme étant des utilisateurs humains. »
- Inside India's CAPTCHA solving economy. ZDNet, 29 aout 2009. La rémunération mentionnée par l'article est de l'ordre de 2 dollars pour mille problèmes résolus.
- http://www.solvemedia.com//index.html
Voir aussi
Articles connexes
Liens externes
- (en) captcha.net, site du Projet Captcha, à l'Université Carnegie Mellon, qui est à l'origine de ce concept, et qui est le propriétaire de la marque
- (en) Sur les captcha et les alternatives, W3C
- (fr) Pourquoi les captchas basés sur les questions, les calculs ne sont pas fiables ?
- (fr) Bypass Captcha : petit tour d’horizon des techniques pour contourner les captchas
- (en) Internet Captcha, ASP ou PHP avec captcha réglable niveau de la sécurité et le flash des effets visuels.
- (en) PWNtcha stands for "Pretend We’re Not a Turing Computer but a Human Antagonist"
- contre le spam :
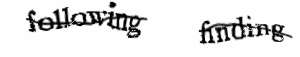
Wikimedia Foundation. 2010.