- Images numériques
-
Image numérique
On désigne sous le terme d'image numérique toute image (dessin, icône, photographie …) acquise, créée, traitée ou stockée sous forme binaire (suite de 0 et de 1) :
- Acquise par des Convertisseurs Analogique-Numérique situés dans des dispositifs comme les scanners, les appareils photo ou caméscopes numériques, les cartes d'acquisition vidéo (qui numérisent directement une source comme la télévision).
- Créée directement par des programmes informatiques, via la souris, les tablettes graphiques ou par la modélisation 3D (ce que l'on appelle par abus de langage les « images de synthèse »).
- Traitée grâce à des outils informatiques. Il est facile de la transformer, modifier en taille, en couleur, d'ajouter ou supprimer des éléments, d'appliquer des filtres variés, etc.
- Stockée sur un support informatique (disquette, disque dur, CD-ROM, …)
Sommaire
Types d'images
Images matricielles (ou images bitmap)
Article détaillé : Image matricielle.Elle est composée comme son nom l'indique d’une matrice (tableau) de points à plusieurs dimensions, chaque dimension représentant une dimension spatiale (hauteur, largeur, profondeur), temporelle (durée) ou autre (par exemple, un niveau de résolution).
Images 2D
Dans le cas des images à deux dimensions (le plus courant), les points sont appelés pixels. D'un point de vue mathématique, on considère l'image comme une fonction de
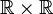 dans
dans 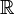 où le couplet d'entrée est considéré comme une position spatiale, le singleton de sortie comme un codage.
où le couplet d'entrée est considéré comme une position spatiale, le singleton de sortie comme un codage.Ce type d'image s'adapte bien à l'affichage sur écran informatique (lui aussi orienté pixel) ; il est en revanche peu adapté pour l'impression, car la résolution des écrans informatiques, généralement de 72 à 96 ppp (« points par pouce », en anglais dots per inch ou dpi) est bien inférieure à celle atteinte par les imprimantes, au moins 600 ppp aujourd'hui. L'image imprimée, si elle n'a pas une haute résolution, sera donc plus ou moins floue ou laissera apparaître des pixels carrés visibles.
Images 2D + t (vidéo), images 3D, images multi-résolution
- Lorsqu'une image possède une composante temporelle, on parle d'animation.
- Dans le cas des images à trois dimensions les points sont appelés des voxels. Ils représentent un volume.
Ces cas sont une généralisation du cas 2D, la dimension supplémentaire représentant respectivement le temps, une dimension spatiale ou une échelle de résolution.
D'un point de vue mathématique, il s'agit d'une fonction de
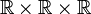 dans
dans Images stéréoscopiques
Il s'agit d'un cas particulier dans lequel on travaille par couples d'images, ces derniers pouvant être de n'importe lequel des types précédents.
Il existe un grand nombre de sortes d'images stéréoscopiques, et un encore plus grand nombre de moyens pour les observer en relief, mais le codage recommandé par les organisations internationales de stéréoscopie est désigné comme "jps"[réf. nécessaire], c'est à dire un format jpg dans lequel les deux vues gauche et droite sont juxtaposées dans un même fichier, le plus souvent 2048x768, chacune des deux vues étant inscrite dans un rectangle 1024x768 et, si son rapport largeur/hauteur n'est pas 4/3, chaque vue est complétée dans ce rectangle par deux bandes noires symétriques, soit en haut et en bas, soit à gauche et à droite.
Images vectorielles
Article détaillé : Image vectorielle.Le principe est de représenter les données de l'image par des formules géométriques qui vont pouvoir être décrites d'un point de vue mathématique. Cela signifie qu'au lieu de mémoriser une mosaïque de points élémentaires, on stocke la succession d'opérations conduisant au tracé. Par exemple, un dessin peut être mémorisé par l'ordinateur comme « une droite tracée entre les points (x1, y1) et (x2, y2) », puis « un cercle tracé de centre (x3, y3) et de rayon 30 de couleur rouge ».
L'avantage de ce type d'image est la possibilité de l'agrandir indéfiniment sans perdre la qualité initiale, ainsi qu'un faible encombrement. L'usage de prédilection de ce type d'images concerne les schémas qu'il est possible de générer avec certains logiciels de DAO (Dessin Assisté par Ordinateur) comme AutoCAD ou CATIA. Ce type d'images est aussi utilisé pour les animations Flash, utilisées sur Internet pour la création de bannières publicitaires, l'introduction de sites web, voire des sites web complets.
Étant donné que les moyens de visualisation d'images actuels comme les moniteurs d'ordinateur reposent essentiellement sur des images matricielles, les descriptions vectorielles (Fichiers) doivent préalablement être converties en descriptions matricielles avant d'être affichées comme images.
Définition et résolution
Les images matricielles sont également définies par leur définition et leur résolution.
La définition d'une image est définie par le nombre de points la composant. En image numérique, cela correspond au nombre de pixels qui compose l'image en hauteur (axe vertical) et en largeur (axe horizontal) : 200 pixels par 450 pixels par exemple, abrégé en « 200×450 ».
La résolution d'une image est définie par un nombre de pixels par unité de longueur de la structure à numériser (classiquement en ppp). Ce paramètre est défini lors de la numérisation (passage de l’image sous forme binaire), et dépend principalement des caractéristiques du matériel utilisé lors de la numérisation. Plus le nombre de pixels par unité de longueur de la structure à numériser est élevé, plus la quantité d'information qui décrit cette structure est importante et plus la résolution est élevée. La résolution d'une image numérique définit le degré de détail de l’image. Ainsi, plus la résolution est élevée, meilleure est la restitution.
Cependant, pour une même dimension d'image, plus la résolution est élevée, plus le nombre de pixels composant l'image est grand. Le nombre de pixels est proportionnel au carré de la résolution, étant donné le caractère bidimensionnel de l'image : si la résolution est multipliée par deux, le nombre de pixels est multiplié par quatre. Augmenter la résolution peut entraîner des temps de visualisation et d'impression plus longs, et conduire à une taille trop importante du fichier contenant l'image et à de la place excessive occupée en mémoire.

Représentation des couleurs
Il existe plusieurs modes de codage informatique des couleurs, le plus utilisé pour le maniement des images est l'espace colorimétrique Rouge, Vert, Bleu (RVB ou RGB - Red green Blue). Cet espace est basé sur une synthèse additive des couleurs, c'est-à-dire que le mélange des trois composantes R, V, et B à leur valeur maximum donne du blanc, à l'instar de la lumière. Le mélange de ces trois couleurs à des proportions diverses permet de reproduire à l'écran un part importante du spectre visible, sans avoir à spécifier une multitude de fréquences lumineuses.
Il existe d'autres modes de représentation des couleurs :
- Cyan, Magenta, Jaune, Noir (CMJN ou CMYK) utilisé principalement pour l'impression, et basé sur une synthèse soustractive des couleurs ;
- Teinte, Saturation, Luminance (TSL ou HSL), où la couleur est codée suivant le cercle des couleurs ;
- base de couleur optimale YUV, Y représentant la luminance, U et V deux chrominances orthogonales.
Les images bitmap en couleurs peuvent dont être représentées soit par une image dans laquelle la valeur du pixel est une combinaison linéaire des valeurs des trois composantes couleurs, soit par trois images représentant chacune une composante couleur. Dans le premier cas, selon le nombre de bits (unité d’information élémentaire qui peut prendre deux valeurs distinctes) alloués pour le stockage d'une couleur de pixel, on distingue généralement les différents types d'images suivants :
Images 24 bits (ou « couleurs vraies »)
Il s'agit d'une appellation trompeuse car le monde numérique (fini, limité) ne peut pas rendre compte intégralement de la réalité (infinie). Le codage de la couleur est réalisé sur trois octets, chaque octet représentant la valeur d'une composante couleur par un entier de 0 à 255. Ces trois valeurs codent généralement la couleur dans l'espace RVB. Le nombre de couleurs différentes pouvant être ainsi représenté est de 256 x 256 x 256 possibilités, soit près de 16 millions de couleurs. Comme la différence de nuance entre deux couleurs très proches mais différentes dans ce mode de représentation est quasiment imperceptible pour l'œil humain, on considère commodément que ce système permet une restitution exacte des couleurs, c'est pourquoi on parle de « couleurs vraies ».
R V B Couleur 0 0 0 noir 0 0 1 nuance de noir 255 0 0 rouge 0 255 0 vert 0 0 255 bleu 128 128 128 gris 255 255 255 blanc Les images bitmap basées sur cette représentation peuvent rapidement occuper un espace de stockage considérable, chaque pixel nécessitant trois octets pour coder sa couleur.
Images à palettes, images en 256 couleurs (8 bits)
Pour réduire la place occupée par l'information de couleur, on utilise une palette de couleurs « attachée » à l'image. On parle alors de couleurs indexées : la valeur associée à un pixel ne véhicule plus la couleur effective du pixel, mais renvoie à l'entrée correspondant à cette valeur dans une table (ou palette) de couleurs appelée look-up table ou LUT en anglais, dans laquelle on dispose de la représentation complète de la couleur considérée.
Selon le nombre de couleurs présentes dans l'image, on peut ainsi gagner une place non négligeable : on considère en pratique que 256 couleurs parmi les 16 millions de couleurs 24 bits sont suffisantes. Pour les coder, on aura donc une palette occupant 24 bits x 256 entrées, soit 3 x 256 octets, et les pixels de l'image seront associés à des index codés sur un octet. L'occupation d'une telle image est donc de 1 octet par pixel plus la LUT, ce qui représente un peu plus du tiers de la place occupée par une image en couleurs 24 bits (plus l'image contient de pixels, plus le gain de place est important, la limite étant le tiers de la place occupée par l'image en couleurs vraies).
Une autre méthode existante consiste à se passer de palette, et de coder directement les trois couleurs en utilisant un octet : chaque composante couleur est codée sur deux bits, le bit restant peut servir soit à gérer plus de couleurs sur une des composantes, soit à gérer la transparence du pixel. Avec cette méthode, on obtient des images bitmap avec un codage couleur effectivement limité à 8 bits, bien que la plage des couleurs possibles soit très réduite par rapport à celle qu'offre la méthode utilisant une palette.
Dans le cas des images en couleurs indexées, il est possible de spécifier que les pixels utilisant une des couleurs de la palette ne soient pas affichés lors de la lecture des données de l'image. Cette propriété de transparence est très utilisée (et utile) pour les images des pages web, afin que la couleur de fond de l'image n'empêche pas la visualisation de l'arrière-plan de la page.
Images en teintes (ou niveaux) de gris
On ne code ici plus que le niveau de l'intensité lumineuse, généralement sur un octet (256 valeurs). Par convention, la valeur zéro représente le noir (intensité lumineuse nulle) et la valeur 255 le blanc (intensité lumineuse maximale) :
000 008 016 024 032 040 048 056 064 072 080 088 096 104 112 120 128 255 248 240 232 224 216 208 200 192 184 176 168 160 152 144 136 Ce procédé est fréquemment utilisé pour reproduire des photos en noir et blanc ou du texte dans certaines conditions (avec utilisation d'un filtre pour adoucir les contours afin d'obtenir des caractères plus lisses).
Ce codage de la simple intensité lumineuse est également utilisé pour le codage d'images couleurs : l'image est représentée par trois images d'intensité lumineuses, chacune se situant dans une composante distincte de l'espace colorimétrique (par exemple, intensité de rouge, de vert et de bleu).
Images avec gestion de la translucidité
On peut attribuer à une image un canal supplémentaire, appelé canal alpha, qui définit le degré de transparence de l'image. Il s'agit d'un canal similaire aux canaux traditionnels définissant les composantes de couleur, codé sur un nombre fixe de bits par pixel (en général 8 ou 16). On échelonne ainsi linéairement la translucidité d'un pixel, de l'opacité complète à la transparence.
Autres formats
Certains formats originaux furent utilisés :
- Le mode HAM sur Amiga est un format célèbre pour son codage assez spécial des couleurs. En effet, la couleur d'un pixel était décrite à l'aide de celle du pixel immédiatement à sa gauche dont une des composantes de couleur était modifiée ou bien tirée d'une palette de 16 couleurs.
- Le mode Halfbrite toujours sur Amiga qui permettait de contourner une limitation des palettes Amiga qui étaient limitées à 32 couleurs. 32 autres couleurs étaient déduites des premières en diminuant leur intensité de moitié.
Formats d'image
Définition
Un format d'image est une représentation informatique de l'image, associée à des informations sur la façon dont l'image est codée et fournissant éventuellement des indications sur la manière de la décoder et de la manipuler.
Structuration, utilisation de métadonnées
Article détaillé : Métadonnées.La plupart des formats sont composés d'un en-tête contenant des attributs (dimensions de l'image, type de codage, LUT, etc.), suivi des données (l'image proprement dite). La structuration des attributs et des données diffère pour chaque format d'image.
De plus, les formats actuels intègrent souvent une zone de métadonnées (metadata en anglais) servant à préciser les informations concernant l'image comme :
- la date, l'heure et le lieu de la prise de vue,
- les caractéristiques physiques de la photographie (sensibilité ISO, vitesse d'obturation, usage du flash…)
Ces métadonnées sont par exemple largement utilisées dans le format Exif (extension du format JPEG), qui est le format le plus utilisé dans les appareils photo numériques.
Précautions à prendre
Quelques précautions à prendre concernant les formats d'images :
- les formats dits « propriétaires », peuvent différer selon le logiciel qui les manipule. De plus, leur pérennité n'est pas garantie : réaliser de nouveaux programmes pour les lire peut s'avérer difficile (surtout si leurs spécifications n'ont pas été rendues publiques), cela peut même s'avérer illégal si les algorithmes utilisés sont protégés par des brevets.
- Il faut prêter attention aux différentes versions que peut recouvrir un format particulier. Notamment pour le format TIFF qui varie selon les versions ; certaines d’entre elles ne sont pas reconnues par certains logiciels.
Tableau comparatif
Type
(matriciel/
vectoriel)Compression
des donnéesNombre de couleurs
supportéesAffichage
progressifAnimation Transparence JPEG matriciel Oui,
réglable
(avec perte)16 millions Oui Non Non JPEG2000 matriciel Oui,
avec ou sans perte32 millions Oui Oui Oui GIF matriciel Oui,
Sans perte256 maxi (palette) Oui Oui Oui PNG matriciel Oui,
sans pertePalettisé (256 couleurs ou moins) ou
16 millionsOui Non Oui
(couche Alpha)TIFF matriciel Compression ou pas
avec ou sans pertesde monochrome à 16 millions Non Non Oui
(couche Alpha)SVG vectoriel compression possible 16 millions * ne s'applique pas * Oui Oui
(par nature)Formats propriétaires
Le format TIFF est considéré comme un format propriétaire, le brevet étant contrôlé par la firme Aldus qui a fusionné avec Adobe en 1994.
Dans le passé, le format GIF était soumis au brevet Unisys contrôlé par le société CompuServe, c'était donc un format propriétaire. Mais les brevets d'Unisys sont arrivés à expiration le 20 juin 2003 aux États-Unis, le 18 juin 2004 dans la plupart des pays d'Europe, le 20 juin 2004 au Japon et le 7 juillet 2004 au Canada. Il est donc devenu depuis un format libre de droits.
Image numérique et droits d'auteur
Pour tenter de faire respecter le droit d'auteur (en France) et le copyright (dans presque tous les autres pays), il existe des techniques de marquage numérique d'une image. Ces techniques, que l'on nomme empreinte, sont de plus en plus utilisées. L'empreinte est supposée conserver une preuve de l'origine de l'image, sous la forme d'une signature visible ou invisible, qui doit résister aux traitements susceptibles d'être appliqués à l'image. Ce « tatouage » peut se faire selon deux méthodes, généralement désignées par le même terme de filigrane :
 Photo de l'île de Groix avec signature visible
Photo de l'île de Groix avec signature visible
Protection par signature visible
Cette technique consiste à intégrer une indication sur l'image, par exemple l'organisme ou l'auteur à qui appartient l'image, afin de dissuader les pirates de s’en servir. L'inconvénient de cette méthode est qu'il est très facile d'éliminer ce type de tatouage avec un outil de traitement d'images, puisque le tatouage est visible.
Protection par Tatouage numérique
Cette technique consiste à cacher le tatouage dans les données de l'image. Cette approche a l'avantage de ne pas gêner la lecture de l'image par le simple spectateur tout en permettant une facile identification. L'auteur en tire un avantage complémentaire : l'éventuel pirate inattentif ne sera pas tenté de retirer ou modifier la signature ; le pirate plus volontaire verra son activité illégale rendue un peu plus difficile ou facilement prouvable (par la seule présence du tatouage).
Voir aussi : stéganographie
Catégorie : Imagerie numérique


Wikimedia Foundation. 2010.