- Synthese des proteines
-
Synthèse des protéines
 Procédé général
Procédé général
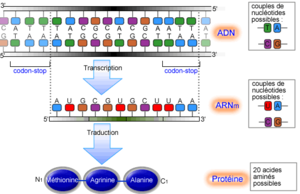
La synthèse des protéines est le processus par lequel une cellule assemble une chaîne protéique en combinant des acides aminés isolés présents dans son cytoplasme, guidé par l'information contenue dans l'ADN. Elle se déroule en deux étapes au moins : la transcription de l'ADN en ARN messager et la traduction de l'ARN messager en une protéine.
Chez les eucaryotes, il existe une étape intermédiaire, la maturation de l'ARN prémessager, qui se passe dans le noyau. L'ARN prémessager subit l'ajout d'une coiffe de 7-méthylguanosine triphosphate à l'extrémité 5' et d'une queue poly(A) (50 à 250 nucléotides d'adénine) à l'extrémité 3'. Par la suite, l'ARN prémessager subit une excision de ses introns (les parties du gène qui ne codent pas un polypeptide) et l'épissage de ses exons (les brins codant). L'ARN prémessager est maintenant à maturité et prend le nom d'ARN messager. La transcription se déroule dans le noyau, la traduction, dans le réticulum endoplasmique. Une dernière étape de glycosylation (liaison covalente d'oses aux protéines) a lieu dans l'appareil de Golgi. Chez les procaryotes, les deux étapes ont lieu dans le cytoplasme et peuvent être simultanées, la traduction débutant alors que la transcription n'est pas encore achevée. Cette simultanéité donne lieu à un important type de régulation de la traduction.
Sommaire
Première approche : mécanisme global
Mise en évidence du mécanisme global de synthèse (pulse-chase)
Il est légitime de se demander comment les biologistes ont découvert la succession d'étapes qui mène à l'achèvement des protéines. La technique principale est celle du pulse-chase ou pulse-chasse, qui se déroule en quatre étapes principales.
On prélève à intervalles réguliers des cellules de ce nouveau milieu ; on dispose alors de deux techniques d'exploitation de cette expérience. La première est l'autoradiographie ; la seconde passe par une ultracentrifugation et donne une meilleure précision dans les résultats. On prépare une coupe de la cellule, par fixation puis découpage au microtome. Sur la plaquette obtenue, on dépose un film photographique contenant des grains d'argent, et on laisse le tout reposer quelques semaines à l'obscurité. Les électrons issus de la désintégration des noyaux radioactifs assimilés par la cellule réduisent les ions Ag+ en grains noirs d'argent, donnant ainsi une « photographie » de la localisation de la radioactivité cellulaire. On peut ainsi retracer, par observation de lames minces à temps de « chasse » différents, le trajet cellulaire des protéines lors de leur synthèse. Cependant les électrons de la lame mince peuvent marquer la plaque photographique assez loin de leur zone d'émission (précision de l'ordre du demi-micromètre). Ainsi, on ne peut pas savoir par exemple, si la radioactivité dans un organite est à l'intérieur ou éventuellement juste à l'extérieur de ses parois. On centrifuge à haute vitesse chaque prélèvement de cellules du second milieu. On obtient ainsi, après plusieurs centrifugations successives à des accélérations croissantes, différentes fractions de cellule, classées suivant leur masse. On connaît la correspondance entre les divers organites (réticulum endoplasmique, appareil de Golgi, noyau) et les fractions après centrifugations. Ainsi, si on mesure la radioactivité de chaque fraction, on peut savoir dans quel organite les acides aminés marqués se trouvaient au moment du prélèvement. On en déduit des courbes de répartition de radioactivité en fonction du temps pour chaque compartiment cellulaire, ce qui permet de retrouver le trajet des acides aminés nouvellement assemblés en protéines.
Complémentarité des bases azotées
Il est important de savoir, avant de procéder, qu'il existe une complémentarité entre les bases azotées de l'ADN et de l'ARN. C'est cette complémentarité, due à des liaisons hydrogène, qui permet la réplication, la transcription et la traduction des acides nucléiques.
Il existe 5 bases azotées :
- Adénine (A)
- Guanine (G)
- Thymine (T) On ne retrouve T que dans l'ADN
- Cytosine (C)
- Uracile (U) On ne retrouve U que dans l'ARN
A et G sont des purines (2 cycles)
T, C et U sont des pyrimidines (1 cycle)A et T sont complémentaires
G et C sont complémentairesA et U sont complémentaires
La transcription et la traduction utilisent cette complémentarité lors de la création d'ARN et de l'approche de l'ARNt.
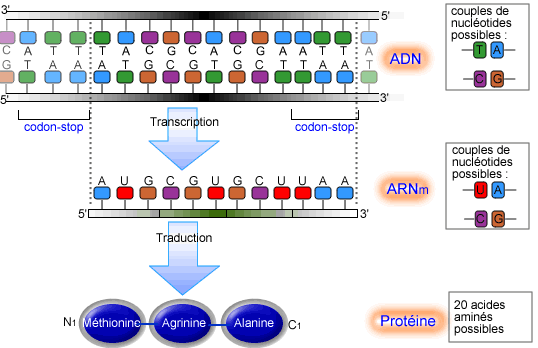
Transcription de l'ADN
Article détaillé : transcription (biologie).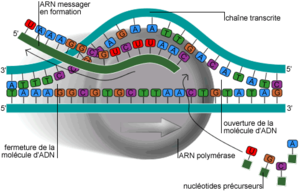 Processus de transcription de l'ADN
Processus de transcription de l'ADNLa première étape de la synthèse des protéines est la transcription d'un gène de l'ADN en une molécule d'ARN messager (ARNm ou acide ribonucléique messager). L'étape se déroule à l'intérieur même du noyau d'une cellule eucaryote et dans le cytoplasme des procaryotes. Cette différence va avoir des conséquences importantes sur le traitement de l'ARN synthétisé. L'ADN est une molécule constituée d'une succession de nucléotides. Aucune particularité physique ne différencie un gène d'une portion non codante de l'organisme. Le repérage des gènes le long de la molécule d'ADN (et d'une manière générale toute information de régulation le long de la chaîne d'ADN) va se faire de la même façon que celui du repérage des fichiers sur une bande magnétique : des marquages consistant en une séquence particulière de nucléotides vont indiquer le début du gène. Ces marques spéciales sont appelées séquences consensus, il ne s'agit en effet pas de séquences exactes mais de séquences approchées d'une séquence moyenne mais différant seulement par quelques paires de bases. Les deux utilisées pour repérer le début d'un gène sont les boîtes CAAT et TATA, du nom des nucléotides formant le cœur de la séquence moyenne et situées dans une zone précédant le gène appelée promoteur car elle initie la transcription du gène.
La transcription consiste à faire une «copie de travail» de l'ADN. L'ADN est une molécule unique dans la cellule. Outre le fait que la synthèse d'un ARN intermédiaire permet de limiter les dommages de l'ADN par suite de trop de manipulations, cela permet de multiplier les copies disponibles pour la phase de traduction et donc de synthétiser la protéine beaucoup plus rapidement.
La synthèse de l'ARN fait intervenir un ensemble protéique très complexe, l'ARN polymérase. La première étape de la transcription est la reconnaissance du gène à transcrire. Cette étape fait intervenir des mécanismes variés qui dépendent de la protéine à transcrire, mais qui reposent tous sur le principe d'une protéine spécifique du ou des gènes à transcrire, qui se fixe en un endroit précis de l'ADN, situé dans le promoteur. Cette protéine va servir de point d'ancrage au système ARN polymérase, cette phase n'ayant lieu naturellement que si les deux boîtes CAAT et TATA sont présentes. Ce complexe va parcourir la molécule d'ADN pour la lire. Elle va tout d'abord dérouler la molécule d'ADN, puis séparer les deux brins, puis assembler les bases azotées en se servant du brin complémentaire comme matrice pour aboutir à la molécule d'ARN. Derrière elle, les deux brins se réassemblent et l'ADN se réenroule. Quand l'ARN polymérase rencontre le site de terminaison de gène, elle se sépare de l'ADN, et l'ARN est libéré de la chaîne d'ADN.
Modification post-transcriptionnelle
Article détaillé : Modification post-transcriptionnelle.L'ARN transcrit n'est pas toujours directement utilisable, il est d'ailleurs souvent appelé ARN pré-messager, il peut nécessiter différentes modifications avant de pouvoir être traduit. Les modifications les plus connues sont l'épissage, et chez les eucaryotes, l'ajout d'une coiffe et d'une queue poly (A).
L'ARNm va maintenant pouvoir être passer par la phase suivante de la synthèse protéique : la traduction
Un exemple de transcription
Une molécule d'ADN est constituée de deux brins :
le brin d'ADN non transcrit : A T A G C G T T C A G A A C T G A T A C G T A A le brin d'ADN transcrit : T A T C G C A A G T C T T G A C T A T G C A T T le brin d'ARN : A U A G C G U U C A G A A C U G A U A C G U A A
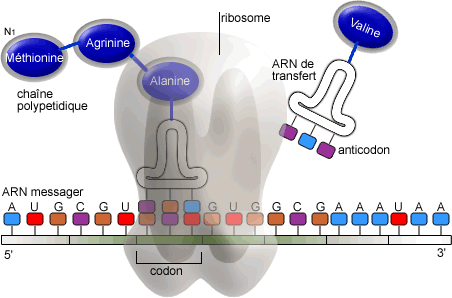
Traduction de l'ARNm
Article détaillé : Traduction (biologie).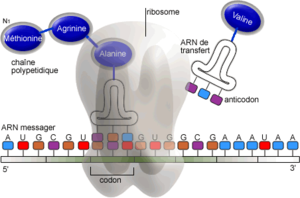 Processus de traduction de l'ARN en protéine
Processus de traduction de l'ARN en protéineUne fois que le brin d'ARNm a atteint le cytoplasme, où a lieu la traduction, il se fixe à un ribosome, composé d'une petite sous-unité et d'une grande sous-unité, qui va assembler une séquence d'acides aminés selon les « instructions » du code génétique : chaque codon (groupe de 3 nucléotides de l'ARNm) correspond à un acide aminé, sauf 3 codons, appelés codons-stop, qui provoquent l'arrêt de la traduction. Le codon AUG, appelé codon-initiateur, va permettre de commencer la traduction, comme son nom l'indique, en formant l'acide aminé méthionine, qui se détachera plus tard de la chaîne polypeptidique.
Le ribosome va parcourir le brin d'ARNm codon par codon et va par l'intermédiaire d'un ARN de transfert (ARNt) ajouter un acide aminé à la protéine en cours de fabrication selon le codon lu. Une fois le codon-stop atteint, la protéine est complète: le ribosome se détache de la protéine et du brin d'ARNm, et la protéine est libérée dans l'organisme.
Le même filament d'ARNm peut servir à la fabrication simultanée de plusieurs molécules de protéines, lorsque plusieurs ribosomes s'en chargent. Avant d'être détruite, cette molécule participe en effet à la fabrication de 10 à 20 protéines.
Dès que la chaîne d'acides aminés est terminée, elle se détache du ribosome qui est alors disponible pour une nouvelle synthèse. S'entame alors le transport des protéines, qui les mène hors de la cellule et dans le système sanguin ou encore à l'intérieur même de la cellule l'ayant synthétisé.
Reprenons notre exemple
Le brin d'ARN messager est A U A G C G U U C A G A A C U G A U A C G U A A Les différents codons sont donc AUA - GCG - UUC - AGA - ACU - GAU - ACG - UAA Les ARN de transfert se fixent UAU CGC AAG UCU UGA CUA UGC AUU par complémentarité et apportent | | | | | | | | les acides aminés appropriés Île Ala Phe Arg Thr Asp Thr X
Les ARN de transfert arrivent successivement avec pour anti-codon :
- AUU, AUC, AUA : il se forme l'acide aminé isoleucine (ISO)(Île)
- GCA, GCC, GCU: il se forme l'acide aminé alanine (ALA)(Ala)
- UUC, UUU : il se forme l'acide aminé phénylalanine (PHE)(Phe)
- CGG, CGA, CGC, CGU : il se forme l'acide aminé arginine (ARG)(Arg)
- ACG, ACA, ACC, ACU : il se forme l'acide aminé thréonine (THR)(Thr)
- GAC, GAU : il se forme l'acide aminé acide aspartique (ASP)(Asp)
- ACG, ACA, ACC, ACU : il se forme l'acide aminé thréonine (THR)(Thr)
- UGA, UAG, UAA : ces codons sont des codons stop (qui ne code donc aucun acide aminé). La chaine polypeptidique se détache du ribosome et la traduction est terminée.
Sources
- Neil A. Campbell et Jane B. Reece, Biologie, traduit par Richard Mathieu, Éd. Éditions du Renouveau Pédagogique Inc., Saint-Laurent (Québec), 3 mars 2004, 1400 pages, ISBN 2-7613-1379-8.
Voir aussi
Liens internes
- Cellule
- Protéine
- Génétique > ADN > Gène > Synthèse des protéines > ARN
- Transcription
- Traduction
Liens externes
- Baptiste Deleplace (2003), La traduction (une approche ludique de la traduction de l'ARN m en chaîne polypeptidique).
- Voir la vidéo en 3D de la synthèse des protéines dans l'encyclopédie vulgaris-medical.com[1]
 Portail de la biologie cellulaire et moléculaire
Portail de la biologie cellulaire et moléculaire Portail de la biochimie
Portail de la biochimie
Catégories : Expression génétique | Génétique | Physiologie cellulaire | Protéomique
Wikimedia Foundation. 2010.