- Somme de controle
-
Somme de contrôle
La somme de contrôle (en anglais checksum) est un concept de la théorie des codes utilisé pour les codes correcteurs, elle correspond à un cas particulier de contrôle par redondance. Elle est largement utilisée en informatique et en télécommunications numériques.
Sommaire
Utilisation
Les codes utilisant les sommes de contrôle permettent de valider un message. Si le nombre d'altérations durant la transmission est suffisamment petit, alors elles sont détectées. L'utilisation d'une unique somme de contrôle permet la détection mais non la correction des erreurs.
Une somme de contrôle est un moyen simple pour garantir l'intégrité de données en détectant les erreurs lors d'une transmission de données dans le temps (sur un support de données) ou dans l'espace (télécommunications). Le principe est d'ajouter aux données des éléments dépendant de ces dernières — on parle de redondance — et simples à calculer. Cette redondance accompagne les données lors d'une transmission ou bien lors du stockage sur un support quelconque. Plus tard, il est possible de réaliser la même opération sur les données et de comparer le résultat à la somme de contrôle originale, et ainsi conclure sur la corruption potentielle du message.
Un cas particulier répandu dans l'industrie est celui du bit de parité. C'est une somme de contrôle dans le cas où l'alphabet comporte deux lettres zéro et un.
Remarque : Le terme de somme de contrôle est aussi utilisé de manière générique pour décrire la redondance dans les codes correcteurs linéaires. Cette utilisation du mot est décrite dans le paragraphe Code systématique de l'article Matrice génératrice. Cette acception du mot est parfois considérée comme impropre.
Approche intuitive
Motivation
Article détaillé : Code correcteur. Voyager 2 est un des nombreux utilisateurs des codes de parité pour communiquer de manière fiable.
Voyager 2 est un des nombreux utilisateurs des codes de parité pour communiquer de manière fiable.
Les codes correcteurs ont leur source dans un problème très concret lié à la transmission de données. Dans certains cas, une transmission de données se fait en utilisant une voie de communication qui n'est pas entièrement fiable. Autrement dit, les données, lorsqu'elles circulent sur cette voie, sont susceptibles d'être altérées. L'objectif des sommes de contrôle est l'apport d'une redondance de l'information de telle manière à ce que l'erreur puisse être détectée.
Dans le cas d'une unique somme de contrôle, et à la différence d'autres codes correcteurs, comme par exemple les codes cycliques, l'objectif n'est pas la correction automatique des erreurs, mais la détection. La correction est alors réalisée par une nouvelle demande de la part du récepteur. Si les codes cycliques sont plus performants, leur complexité algorithmique grandit ainsi que leur taille.
Une simple somme de contrôle se contente de faire une somme des lettres du message. Elle ne peut pas détecter certains types d'erreurs. En particulier une telle somme de contrôle est invariante par :
- réorganisation des octets du message
- ajout ou suppression d'octets à zéro
- erreurs multiples se compensant.
Plusieurs sommes de contrôles sont alors nécessaires, et la multiplication quitte parfois le domaine des corps binaires pour d'autres structures de corps fini plus complexes. Le terme de somme de contrôle est toujours utilisé, même si celui de contrôle de redondance cyclique est plus approprié.
Ce type de code entre dans la famille des codes linéaires. Elle a été formalisée après la Seconde Guerre mondiale. Claude Shannon (1916, 2001) et formalise la théorie de l'information comme une branche des mathématiques[1]. Richard Hamming (1915, 1998) travaille spécifiquement sur la question de la fiabilité des codes pour les laboratoires Bell. Il développe les fondements de la théorie des codes correcteurs et formalise le concept de somme de contrôle dans sa généralité[2].
Exemple : bit de parité
données sur 7 bits parité pair = 0 impair = 0 0000000 00000000 10000000 1010001 11010001 01010001 1101001 01101001 11101001 1111111 11111111 01111111 Supposons que l'objectif soit la transmission de sept bits auxquels s'ajoute le bit de parité. Les huit bits transmis sont d'abord la parité puis les sept bits du message.
On peut définir le bit de parité comme étant égal à zéro si la somme des autres bits est paire et à un dans le cas contraire. On parle de parité paire, c’est-à-dire la deuxième colonne du tableau intitulée pair = 0. Les messages envoyés sur huit bits ont toujours la parité zéro, ainsi si une erreur se produit, un zéro devient un un, ou l'inverse ; le récepteur sait qu'une altération a eu lieu. En effet la somme des bits devient impaire ce qui n'est pas possible sans erreur de transmission.
Une deuxième convention peut être prise, le bit de parité est alors défini comme étant égal à un si la somme des autres bits est paire et à zéro dans le cas contraire. Le résultat correspond à la troisième colonne, intitulée impair = 0.
Le bit de parité est en gras sur les deuxièmes et troisièmes colonnes.
Il ne faut pas confondre parité d'un nombre, et le fait qu'il soit pair ou impair (au sens mathématique du terme). Le nombre binaire 00000011 (3 en nombre décimal) est impair (non-divisible par 2) mais de parité paire (nombre pair de bits à 1).
Cette approche permet de détecter les nombres d'erreurs impaires dans le cas où les lettres sont soit zéro soit un. La somme de contrôle généralise le concept pour la détection d'erreurs plus nombreuses et pour d'autres alphabets.
Exemples d'utilisation
ASCII
Une utilisation célèbre est celle faite au début de l'utilisation du code ASCII : 7 bits étaient utilisés ; les ordinateurs utilisant couramment 8 bits, il en restait un de disponible. Ce dernier bit a donc été fréquemment utilisé pour une somme de contrôle : sa valeur était la somme, binaire, ou de manière équivalente le « ou exclusif » des 7 premiers bits. Tout changement d'un nombre impair de bits peut alors être détecté.
Protocole IP
Plus récemment, une telle somme est utilisée pour les octets numéro 11 et 12 de l'en-tête des paquets IP. Ces deux octets sont calculés de la manière suivante. Les octets sont numérotés de 1 à 10.
Les 16 bits constitués par les octets numéros i et i+1, pour i=1,3,5,7 et 9, sont considérés comme l'écriture binaire d'un entier. Les 5 entiers ainsi obtenus sont additionnés. On obtient alors un entier pouvant nécessiter plus de 16 bits. Ce dernier est alors coupé en deux, les 16 bits de poids faibles et les autres, on calcule la somme de ces deux moitiés et on itère ce procédé tant que l’on n’obtient pas un entier n'utilisant que 16 bits. Pour finir, chaque bit de ce dernier entier est changé. L'objectif derrière ce calcul est plus simple qu'il n'y paraît. Lorsque l'on répète l'opération en incluant la somme de contrôle, c'est-à-dire lorsque l'on vérifie la validité de l'en-tête, on obtient 16 bits à la valeur 1.
Ligne de commande Unix
Sous Unix il existe un utilitaire en ligne de commande, cksum, qui indique une somme de contrôle (checksum en anglais) basée sur un Contrôle de redondance cyclique en 32 bits ainsi que la taille (en octets) et le nom du ou des fichiers donné en entrée.
Communication
Pour transmettre à distance une suite de caractères, il est généralement fait appel à un UART (Universal Asynchronous Synchronous Receiver Transmitter) qui opère entre autres la conversion parallèle/série à l'émission et série/parallèle à la réception. De nombreux modèles d'UART permettent de calculer automatiquement et d'accoler aux bits des caractères le bit de parité ; à la réception, on contrôle la parité du caractère et on positionne un drapeau (flag) en cas d'erreur.
Carte mémoire
Les ordinateurs utilisent comme mémoire de travail des mémoires dynamiques (DRAM). Pendant de nombreuses années, les boîtiers de DRAM géraient des mots d'un bit ; il fallait donc placer sur la carte mémoire 8 boîtiers pour travailler avec des octets (8 bits). Pourtant, de nombreuses cartes comportaient non pas 8, mais 9 boîtiers ! Le neuvième boîtier était destiné à stocker un bit de parité lors de chaque mise en mémoire d'un octet. Lors de la lecture d'un octet, on vérifiait si, entre le moment de l'écriture et celui de la lecture, la parité n'avait pas été modifiée (suite à un parasite, par exemple).
Formalisation
Code linéaire
Article détaillé : Code linéaire.L'objectif est la transmission d'un message m, c’est-à-dire d'une suite de longueur k de lettres choisies dans un alphabet. Le message apparaît comme un élément d'un ensemble Sk. L'objectif est de transmettre un code c tel que le récepteur soit capable de détecter l'existence d'altérations si le nombre d'erreurs ne dépasse pas un entier t. Un code est la donnée d'une application φ de Sk dans un ensemble E qui à m associe φ(m) = c. L'application φ est une injection, car sinon deux messages distincts auraient le même code et le récepteur ne saurait les distinguer.
Le bit de parité procède de la famille des codes linéaires. Cette méthode consiste à munir les ensembles Sk et E d'une structure algébrique adaptée pour bénéficier de bonnes propriétés. L'alphabet K est choisi muni d'une structure de corps fini. En général il est égal à {0,1} le corps à deux éléments. Sk et E sont des K espace vectoriel. L'application φ est linéaire. L'ensemble des messages reçus sans erreurs est égal à φ(Sk), un sous-espace vectoriel de E appelé code.
Poids de Hamming
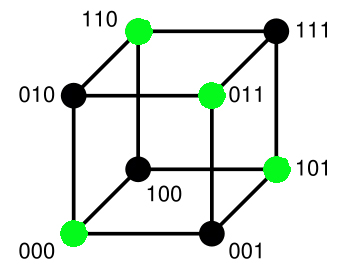
Article détaillé : Poids de Hamming.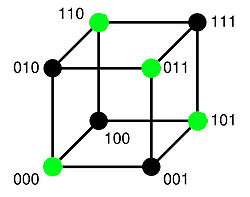 Code de longueur deux avec un bit de parité
Code de longueur deux avec un bit de paritéLa transmission est sujet à des altérations, en conséquence le récepteur ne reçoit pas toujours le code c = φ(m) mais parfois φ(m) + e où e est la conséquence de la mauvaise transmission. Par hypothèse, e contient moins de t coordonnées non nulles. Le nombre de coordonnées non nulles d'un vecteur de E est appelé poids de Hamming et le nombre de coordonnées qui diffèrent entre c et c + e est la distance de Hamming. C'est une distance au sens mathématique du terme.
Si tous les points du code φ(Sk) sont à une distance strictement supérieure à t les uns des autres, alors c + e n'est pas un élément du code, le récepteur sait donc que le message est erroné et il est en mesure de demander une nouvelle transmission.
La figure de droite illustre cette situation. k est égal à deux, le corps K est égal à {0,1} et t est égal à 1. Sk = {00, 01, 10, 11} est un espace vectoriel de dimension deux. E est l'espace vectoriel K3, illustré sur la figure. L'application φ associe à un message m, le vecteur de coordonnés celle de m et la somme dans K des deux coordonnées de m. Dans le corps K l'égalité 1 + 1 = 0 est vérifiée. On a donc :
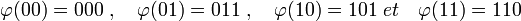
Le code, c’est-à-dire φ(Sk) est représenté par les points verts sur la figure. Les points à distance de 1 d'un point vert sont ceux obtenus par un déplacement sur un unique segment du cube. Ils sont tous noirs, c’est-à-dire qu’ils ne font pas partie du code et sont donc nécessairement erronés. Si une unique altération se produit, alors le récepteur sait que la transmission a été mauvaise.
Un code linéaire est décrit par trois paramètres, noté [k, n, d]. La première valeur k est la longueur du code, c’est-à-dire le nombre de lettres d'un message, n est la dimension du code, correspondant à la dimension de l'espace vectoriel E et d est la distance minimale entre deux mots du code. Un code est dit parfait s'il existe un entier t tel que les boules de centre un élément du code et de rayon t forment une partition de E.
Propriétés
La théorie des corps finis permet de démontrer deux propriétés essentielles sur l'utilisation d'une unique somme de contrôle dans un code.
-
- Soit K un corps fini et k un entier strictement positif. Il existe un code sur le corps K de paramètre [k+ 1, k, 2] composé de l'identité et d'une somme de contrôle.
Ce type de code est le plus compact à même de détecter une erreur de poids un. En effet, un code plus petit aurait une dimension égale à k et donc aucune redondance. il est MDS, car il atteint la borne du singleton. C’est-à-dire que sa dimension moins sa longueur est égale à sa distance minimale moins un. En revanche, le code n'est pas parfait, c’est-à-dire que les boules de centres les mots du code et de rayon un ne forment pas une partition de E, un point extérieur au code est en général à une distance de un de plusieurs points du code, il appartient donc à plusieurs boules.
-
- Soit K un corps fini et k un entier strictement positif. Tout code sur le corps K de paramètre [k + 1, k, 2] est isomorphe à un code composée de l'identité et d'une somme de contrôle.
En d'autres termes, si un code MDS est de distance minimale égale à deux, alors il est construit à l'aide de l'identité et d'une somme de contrôle. La somme de contrôle est donc l'unique manière optimale de détecter une altération.
Démonstrations-
- Soit K un corps fini et k un entier strictement positif. Il existe un code sur le corps K de paramètre [k + 1, k, 2] composé l'identité et d'une somme de contrôle.
Considérons le code de matrice génératrice (cf le paragraphe Définitions de l'article Code linéaire) c’est-à-dire dont la matrice G de k lignes et k + 1 colonnes, dans les bases canoniques est la suivante:
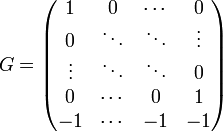
La matrice est bien construite à l'aide de la matrice identité et de la somme de contrôle. Par construction, les deux premiers paramètres du code sont bien k et k + 1. L'endomorphisme φ est bien injectif car sa matrice contient une sous-matrice identité de dimension k.
Il ne reste plus qu'à montrer que si m et m' sont deux messages distincts, alors la distance de Hamming entre φ(m) et φ(m') est bien supérieure ou égal à deux. Ceci revient à montrer que si a est le message égal m - m' alors φ(a) possède un poids de Hamming supérieur ou égal à deux. On remarque qu'il existe des éléments du code φ(Sk) dont le poids est égal à deux, par exemple l'image de n'importe quel élément de la base de Sk. Il suffit donc de montrer que tout vecteur ayant une unique coordonnée non nulle n'est pas élément du code. C’est-à-dire qu'aucun vecteur de la base de E n'est élément de φ(Sk).
Soit (fj) où j est un entier compris entre 1 et k + 1 la base canonique de E. Si f k + 1 est élément du code, alors comme fj - f k + 1 est élément du code si j est inférieur ou égal à k, fj est aussi élément du code. Le code contiendrait donc les k + 1 vecteur de la base de E. Or le code est de dimension k, en conclusion f k + 1 n'est pas élément du code. Si fj est élément du code avec j inférieur ou égal à k, alors f k + 1 est aussi élément du code car fj - f k + 1 l'est, or c'est impossible d'après l'analyse précédente. La distance minimale est donc bien égale à deux.
-
- Tout code sur le corps K de paramètre [k + 1, k, 2] est isomorphe à un code composée de l'identité et d'une somme de contrôle.
Les mêmes notations que précédemment sont utilisées, en particulier φ est l'application linéaire de Sk dans E du code. Notons (fj) pour j variant de 1 à k + 1 la base canonique de F. L'objectif est de trouver une base (ei) où i est un entier compris entre 1 et k de E tel que la matrice de φ soit égal à G dans ces bases.
Remarquons tout d'abord qu'aucun vecteur de la base canonique de F n'est élément du code, en effet, le code est de distance minimale égale à deux, et tout vecteur de la base est à une distance de un du mot du code nul.
En revanche, il existe un coefficient ci tel que f i + ci.f k + 1 si i est compris entre 1 et k est élément du code. L'espace vectoriel engendré par les vecteurs f i et f k+1 est de dimension deux, son intersection avec le code, qui est un hyperplan n'est pas réduite au vecteur nul. Tout vecteur de l'intersection possède une coordonnée non nulle sur f i car f k+1 n'est pas élément de l'intersection. Quitte à appliquer une homothétie sur le vecteur, la coordonnée sur f i peut être choisie égale à un.
Soit ei l'antécédent du mot du code fi + ci.f k + 1. Il suffit alors de démontrer que (ei) est une base de E et de remarquer que la matrice de φ est bien celle de G dans les bases (ei) et (fj) pour conclure.
Considérons une relation de dépendance linéaire de la famille (ei) :
![\sum_{j=1}^{k} \lambda_i.e_i = 0 \quad avec \quad \forall i \in [1, k] \quad \lambda_i \in \mathbb K](/pictures/frwiki/55/7b8e4528226d723f752723121db94fac.png)
En appliquant φ à la relation de dépendance linéaire, on obtient :
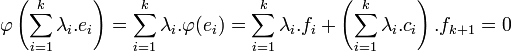
La relation de dépendance linéaire s'applique sur une base, donc les coefficients sont nuls. La famille (ei) est libre de cardinal égal à la dimension de E, c'est donc une base de E, ce qui termine la démonstration.
Sommes de contrôle multiple
Article détaillé : Code de Hamming (7,4).L'association de plusieurs sommes de contrôle permet d'obtenir un code à même de corriger automatiquement des altérations. Cette logique est utilisée, par exemple, pour le cas du code binaire de Hamming de paramètres [7,4,3]. Trois sommes de contrôles permettent systématiquement de corriger une altération.
Une famille importante de codes correcteur, les code cycliques utilisent les sommes de contrôles dans le contexte de la correction automatique. Si certains cas simples, comme les codes de Hamming utilisent de simples bits de parités, d'autres comme les codes de Reed-Solomon utilisent des tables de multiplication plus complexes issues des extensions de corps finis. La logique est la même, en revanche la somme de contrôle n'est plus équivalente à un ensemble de bits de parité.
Somme de contrôle et cryptographie
Une somme de contrôle est utile pour détecter des modifications accidentelles des données, mais n'a pas vocation à assurer une protection contre les modifications intentionnelles. Plus précisément, elle ne peut en général pas assurer directement l'intégrité cryptographique des données. Pour éviter de telles modifications, il est possible d'utiliser une fonction de hachage adaptée, comme SHA-256, couplée à un élément secret (clé secrète), ce qui correspond au principe du HMAC.
Notes et références
Notes
- ↑ Claude Shannon A mathematical theory of communication Bell System Technical Journal, vol. 27, pp. 379-423 et 623-656, juil et oct 1948
- ↑ Richard Hamming Error-detecting and error-correcting codes Bell Syst. Tech. J. 29 pp 147 à 160 1950
Liens externes
- (fr) Code correcteur C.I.R.C par J.P. Zanotti
- (fr) Code linéaire Université de Bordeaux
- (fr) Cours de code par Christine Bachoc Université de Bordeaux
- (en) Jacksum (un programme open source permettant de calculer de nombreux contrôles par redondance
Références
- FJ MacWilliams & JJA Sloane The Theory of Error-Correcting Codes North-Holland, 1977
- A Spataru Fondements de la théorie de l'information Presses polytechniques romandes, 1991
- M. Demazure Cours d'algèbre Cassini, 1997
- B. Martin - Codage, cryptologie et applications - (éd. Presses polytechniques et universitaires romandes (PPUR), 2004) - 354 p. - (ISBN 978-2880745691)
- J.-G. Dumas, J.-L. Roch, E. Tannier et S. Varrette - Théorie des codes (Compression, cryptage, correction) - (éd Dunod, 2007) - 352 p. - (ISBN 978-2100506927)
 Portail des mathématiques
Portail des mathématiques Portail de l’informatique
Portail de l’informatique Portail de la sécurité informatique
Portail de la sécurité informatique
Catégorie : Somme de contrôle

Wikimedia Foundation. 2010.