- Weka (apprentissage automatique)
-
 Pour les articles homonymes, voir Weka.
Pour les articles homonymes, voir Weka.Weka 
 Weka 3.5.5 avec la fenêtre d'explorateur ouverte avec les données de l'iris de l'université de Californie à Irvine.
Weka 3.5.5 avec la fenêtre d'explorateur ouverte avec les données de l'iris de l'université de Californie à Irvine.Développeur Université de Waikato Version avancée 3.6.6 (book 3e éd.), 3.7.5 (development) (31 octobre 2011) [+/−] Environnements Plateforme Java Langues Multilingue Type Apprentissage automatique Licence Licence publique générale GNU Site web weka.wikispaces.com modifier 
Weka (acronyme pour Waikato Environment for Knowledge Analysis, en français : « Environnement Waikato pour l'analyse de connaissances ») est une suite populaire de logiciels d'apprentissage automatique. Écrite en Java, développée à l'université de Waikato, Nouvelle-Zélande. Weka est un Logiciel libre disponible sous la Licence publique générale GNU (GPL).
Sommaire
Description
L'espace de travail Weka[1] contient une collection d'outils de visualisation et d'algorithmes pour l'analyse des données et la modélisation prédictive, allié à une interface graphique pour un accès facile de ses fonctionnalités. La version « non-Java » originale de Weka était un front-end en TCL/TK pour des algorithmes de modélisation (essentiellement tierces) implémentés dans d'autres langages de programmation, complété par un des utilitaires de préprocesseur de données en C, et un système à base de makefile pour lancer les expériences d'apprentissage automatique. Cette version originale était avant tout conçue comme un outil pour analyser des données agricoles[2],[3], mais la version plus récente entièrement basée sur Java (Weka 3), pour laquelle le développement à débuté en 1997, est désormais utilisée dans beaucoup de domaines d'application différents, en particulier pour l'éducation et la recherche. Les principaux points forts de Weka sont qu'il:
- est librement disponible (en particulier gratuitement) sous la licence publique générale GNU,
- est très portable car il est entièrement implémenté en Java et donc fonctionne sur quasiment toutes les plateformes modernes, et en particulier sur quasiment tous les systèmes d'exploitations actuels.
- contient un collection complète de préprocesseurs de données et de techniques de modélisation, et
- est facile à utiliser par un novice en raison de l'interface graphique qu'il contient.
Weka supporte plusieurs outils d'exploration de données standards, et en particulier, des préprocesseurs de données, des agrégateurs de données (data clustering), des classificateurs statistiques, des analyseurs de régression, des outils de visualisation, et des outils d'analyse discriminante. Toutes les techniques de Weka reposent sur la supposition que les données sont disponibles dans un unique fichier plat ou une Relation binaire, ou chaque type de donnée est décrit par un nombre fixe d'attributs (les attributs ordinaires, numériques ou symboliques, mais quelques autres type d'attributs sont aussi supportés). Weka fournit un accès aux bases de données SQL en utilisant le Java Database Connectivity (JDBC) et peut traiter le résultat d'une requête SQL. Il n'est pas capable de faire de l'exploration de données multi-relationnelle, mais il existe des logiciels tiers pour convertir une collection de tables de base de données liées entres elles en un table unique adaptée au traitement par Weka[4]. Un autre domaine important qui n'est pour le moment pas couvert par les algorithmes inclus dans la distribution Weka est la modélisation de séquences.
L'interface principale de Weka est l’Explorer, mais à peu près les mêmes fonctionnalités peuvent être atteintes via l'interface Flux de Connaissance de chaque composant et depuis la ligne de commande. Il y a aussi l’Experimenteur, qui permet la comparaison systématique (taxonimique) des performances prédictives des algorithmes d'apprentissage automatique de Weka sur une collection de jeux de données.
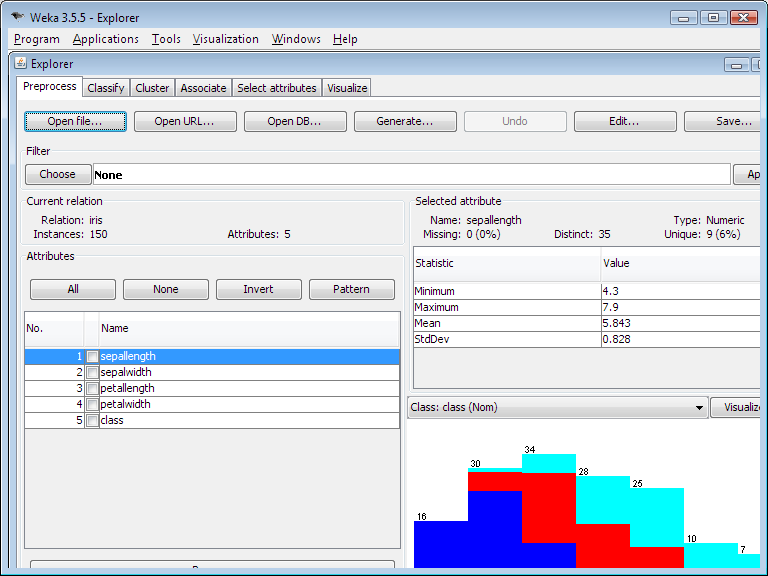
L'interface Explorer possèdes plusieurs onglets qui donnent accès aux principaux composants de l'espace de travail. L'onglet Preprocesseur a plusieurs fonctionnalités d'import de données depuis des bases de données, un fichier CSV, … et pour pré-traiter ces données avec une algorithme appelé filtering. Ces filtres peuvent être utilisés pour transformer les données (ex : transformer des attributs numériques réels en attributs discrets) et rendre possible l'effacement d'instances et d'attributs selon des critères spécifiques. L'onglet Classify permet à l'utilisateur d'appliquer des classifications et des algorithmes de régression (indifféremment appelés « classifiers » dans Weka) au jeu de données résultant, pour estimer la précision du modèle prédictif, et de visualiser les prédictions erronées, ROC curves, etc. ou le modèle lui-même (si le modèle est sujet à visualisation, comme par exemple un Arbre de décision). L'onglet Associate donne accès aux apprentissages par règles d'association qui essayent d'identifier toutes les relations importantes entre les attributs dans les données. L'onglet Cluster donne accès aux techniques de clustering de Weka, comme par exemple l'algorithme du k-means. Il y a aussi une implémentation d'algorithme espérance-maximisation pour l'apprentissage d'un mélange de distributions normales. L'onglet « Select attributes » fournit des algorithmes pour l'identification des attributs les plus prédictifs dans un jeu de donné. Le dernier onglet, « Visualize » montre une matrice de nuages de points, ou des nuages de points individuels peuvent être sélectionnés et élargis, et davantage analysés en utilisant divers opérateurs de sélection.
Historique
- En 1993, l'Université de Waikato en Nouvelle-Zélande commença le développement de la version originale de Weka (qui devint une mixture à base de TCL/TK, C, de Makefiles).
- En 1997, la décision fut prise de développer une nouvelle fois Weka à partir de zéro en Java, y compris l'implémentation des algorithmes de modélisation[5].
- En 2005, Weka reçoit le SIGKDD (Data Mining and Knowledge Discovery Service Award)[6],[7].
- En 2006, Pentaho acquiert une licence exclusive pour utiliser Weka pour de l'informatique décisionnelle[8]. Il forme le composant d'exploration de données analytique et prédictif de la suite de logiciel décisionnels Pentaho.
Notes et références
- (en) Ian H. Witten, Eibe Frank, et Mark A. Hall, Data Mining: Practical machine learning tools and techniques, 3e édition, Morgan Kaufmann, 2011 (ISBN 978-0-1237-4856-0), 629 pages [présentation en ligne]
- (en) G. Holmes, « Weka: A machine learning workbench », Proc Second Australia and New Zealand Conference on Intelligent Information Systems, Brisbane, Australia, 1994. Consulté le 2007-06-25 [PDF]
- (en) S.R. Garner, « Applying a machine learning workbench: Experience with agricultural databases », Proc Machine Learning in Practice Workshop, Machine Learning Conference, Tahoe City, CA, USA, 1995. Consulté le 2007-06-25 [PDF]
- (en) P. Reutemann, « Proper: A Toolbox for Learning from Relational Data with Propositional and Multi-Instance Learners », 17th Australian Joint Conference on Artificial Intelligence (AI2004), Springer-Verlag, 2004. Consulté le 2007-06-25
- (en) Ian H. Witten, « Weka: Practical Machine Learning Tools and Techniques with Java Implementations », Proceedings of the ICONIP/ANZIIS/ANNES'99 Workshop on Emerging Knowledge Engineering and Connectionist-Based Information Systems, 1999. Consulté le 2007-06-26 [PDF]
- (en) Winner of SIGKDD Data Mining and Knowledge Discovery Service Award ... - Gregory Piatetsky-Shapiro, KDnuggets, 28 juin 2005
- (en) Past SIGKDD Service Award Recipients - SIGKDD
- (en) Pentaho Acquires Weka Project - Site de Pentaho, 19 septembre 2006
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Weka (machine learning) » (voir la liste des auteurs)
Annexes
Article connexe
Liens externes
- (en) Site officiel
- (en) Weka---Machine Learning Software in Java - SourceForge.net
- Exemples d'applications
- (en) Acronym identification
- (en) Gene selection from microarray data for cancer classification - ScienceDirect, 1er février 2005
- (en) Benchmarking of Linear and Nonlinear Approaches for Quantitative Structure−Property Relationship Studies of Metal Complexation with Ionophores - ACS Publications
- (en) MIPS EST Classification Server
- (en) Weka : Related Projects
- Autres versions
Catégories :- Apprentissage automatique
- Exploration de données
- Logiciel libre sous licence GPL
- Logiciel scientifique
- Plateforme Java
Wikimedia Foundation. 2010.