- Arbre De Décision
-
Arbre de décision
Un arbre de décision est un outil d'aide à la décision et à l'exploration de données. Il permet de modéliser simplement, graphiquement et rapidement un phénomène mesuré plus ou moins complexe. Sa lisibilité, sa rapidité d'exécution et le peu d'hypothèses nécessaires a priori expliquent sa popularité actuelle.
Sommaire
Introduction
Dans le domaine de l'aide à la décision (informatique décisionnelle et datawarehouse) et du data mining, certains algorithmes produisent des arbres de décision, utilisés pour répartir une population d'individus (de clients par exemple) en groupes homogènes, selon un ensemble de variables discriminantes (l'âge, la catégorie socio-professionnelle, ...) en fonction d'un objectif fixé et connu (chiffres d'affaires, réponse à un mailing, ...). À ce titre, cette technique fait partie des méthodes d’apprentissage supervisé. Il s’agit de prédire avec le plus de précision possible les valeurs prises par la variable à prédire (objectif, variable cible, variable d’intérêt, attribut classe, variable de sortie, ...) à partir d’un ensemble de descripteurs (variables prédictives, variables discriminantes, variables d'entrées, ...).
Cette technique est autant populaire en statistique qu’en apprentissage automatique. Son succès réside en grande partie à ses caractéristiques :
- lisibilité du modèle de prédiction, l’arbre de décision, fourni. Cette caractéristique est très importante, car le travail de l'analyste consiste aussi à faire comprendre ses résultats afin d’emporter l’adhésion des décideurs.
- capacité à sélectionner automatiquement les variables discriminantes dans un fichier de données contenant un très grand nombre de variables potentiellement intéressantes. En ce sens, un arbre de décision constitue une technique exploratoire privilégiée pour appréhender de gros fichiers de données.
Exemple didactique
Pour mieux appréhender l’induction des arbres de décision, nous allons reprendre un exemple décrit dans l’ouvrage de Quinlan (1993). Il s’agit de prédire le comportement de sportifs (Jouer ; variable à prédire) en fonction de données météo (Ensoleillement, Température, Humidité, Vent ; variables prédictives).
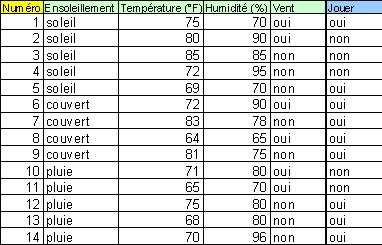
L’algorithme d’apprentissage cherche à produire des groupes d’individus le plus homogène possible du point de vue de la variable à prédire à partir des variables de météo. Le partitionnement est décrit à l’aide d’un arbre de décision.
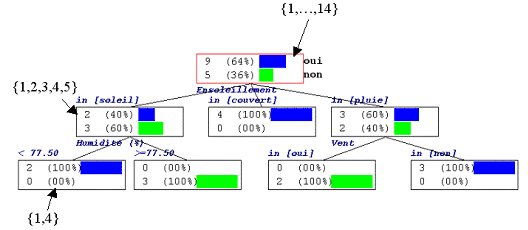
Sur chaque sommet de l’arbre est décrit la distribution de la variable à prédire. Dans le cas du premier sommet, la racine de l’arbre, nous constatons qu’il y a 14 observations dans notre fichier, 9 d’entre eux ont décidé de jouer (Jouer = oui), 5 ont décidé le contraire (Jouer = non).
Ce premier sommet est segmenté à l’aide de la variable Ensoleillement, 3 sous-groupes ont été produits. Le premier groupe à gauche (Ensoleillement = Soleil) comporte 5 observations, 2 d’entre eux correspondent à Jouer = oui, 3 à Jouer = non.
Chaque sommet est ainsi itérativement traité jusqu’à ce que l’on obtienne des groupes suffisamment homogènes. Elles correspondent aux feuilles de l’arbre, des sommets qui ne sont plus segmentés.
La lecture d’un arbre de décision est très intuitive, c’est ce qui fait son succès. L’arbre peut être traduit en base de règles sans pertes d’informations. Si l’on considère la feuille la plus à gauche, nous pouvons aisément lire la règle d’affectation suivante : « Si ensoleillement = soleil et humidité < 77.5% alors jouer = oui ».
Construction d'un arbre de décision
Pour construire un arbre de décision, nous devons répondre aux 4 questions suivantes :
- Comment choisir, parmi l’ensemble des variables disponibles, la variable de segmentation d’un sommet ?
- Lorsque la variable est continue, c’est le cas de la variable Humidité, comment déterminer le seuil de coupure lors de la segmentation (la valeur 77.5 dans l’arbre de décision ci-dessus) ?
- Comment déterminer la bonne taille de l’arbre ? Est-il souhaitable de produire absolument des feuilles pures selon la variable à prédire, même si le groupe correspondant correspond à une fraction très faible des observations ?
- Enfin, comment affecter la valeur de la variable à prédire dans les feuilles ? Lorsque le groupe est pur la réponse est évidente, dans le cas contraire, nous verrons qu'il nous faut adopter une stratégie.
Critère de segmentation
Pour choisir la variable de segmentation sur un sommet, l’algorithme s’appuie sur une technique très fruste : il teste toutes les variables potentielles et choisit celle qui maximise un critère donné. Il faut donc que le critère utilisé caractérise la pureté (ou le gain en pureté) lors du passage du sommet à segmenter vers les feuilles produites par la segmentation. Il existe un grand nombre de critères informationnels ou statistiques, les plus utilisés sont l’entropie de Shannon et le coefficient de Gini et leurs variantes.
Une autre manière de caractériser la segmentation est de mesurer le lien ou la causalité entre la variable candidate et la variable à prédire. Dans ce cas, le critère le plus utilisé est le lien du KHI-2 et ses dérivés.
Certains critères permettent de prendre en compte la nature ordinale de la cible, et ce, en utilisant des mesures ou des heuristiques[1] appropriées.
Au final, ces critères, pour peu qu’ils permettent de faire tendre le partitionnement vers la constitution de groupes purs, jouent peu sur les performances des algorithmes.
Chaque valeur de la variable de segmentation permet de produire une feuille (cf. 3 valeurs d’ensoleillement produit 3 sommets), c’est le cas de l’algorithme C4.5 par exemple. Les algorithmes d’apprentissage peuvent différer sur ce point. Certains tels que CART produisent systématiquement des arbres binaires, il cherche donc lors de la segmentation le regroupement binaire qui optimise le critère de segmentation. D’autres tels que CHAID cherchent à effectuer les regroupements les plus pertinents en s’appuyant sur des critères statistiques. Selon la technique, nous obtiendrons des arbres plus ou moins larges, l’idée est d’éviter de fractionner exagérément les données afin de ne pas produire des groupes d’effectifs trop faibles, ne correspondant à aucune réalité statistique.
Traitement des variables continues
Le traitement des variables continues doit être en accord avec l’utilisation du critère de segmentation. Dans la grande majorité des cas, le principe de segmentation des variables continues est très simple : trier les données selon la variable à traiter, tester tous les points de coupure possibles situés entre deux points successifs et évaluer la valeur du critère dans chaque cas. Le point de coupure optimal correspond tout simplement à celui qui maximise le critère de segmentation.
Dans notre exemple, l’algorithme a donc évalué les points de coupure situés à mi-distance des observations 1 à 5 correspondants aux valeurs {70, 75, 80, 85, 95} de Humidité.
Définir la bonne taille de l’arbre
L’objectif étant de produire des groupes homogènes, il paraît naturel de fixer comme règle d’arrêt de construction de l’arbre la constitution de groupes purs du point de vue de la variable à prédire. C’est le cas dans notre exemple ci-dessus, aucune des feuilles de l’arbre ne comporte de contre-exemples. Souhaitable en théorie, cette attitude n’est pas tenable dans la pratique.
En effet, nous travaillons souvent sur un échantillon que l'on espère représentatif d’une population. Tout l’enjeu est donc de trouver la bonne mesure entre capter l’information utile, correspondant réellement à une relation dans la population, et ingérer les spécificités du fichier sur lequel nous sommes en train de travailler (l'échantillon dit d'apprentissage), correspondant en fait à un artefact statistique. Autement dit, il ne faut jamais oublier que la performance de l'arbre est évaluée sur les données mêmes qui ont servi à sa construction : plus le modèle est complexe (plus l'arbre est grand, plus il a de branches, plus il a de feuilles), plus l'on court le risque de voir ce modèle incapable d'être extrapolé à de nouvelles données, c'est-à-dire de rendre compte de la réalité que nous essayons justement d'appréhender. À la limite, et c'est particulièrement vrai des arbres de décision, un modèle est capable de répliquer exactement n'importe quel échantillon de données, sans pour autant appréhender une quelconque réalité... En effet, si dans un cas extrême on décide de faire pousser notre arbre le plus loin possible, nous pouvons obtenir un arbre composé d'autant de feuilles que d'individus dans l'échantillon d'apprentissage. Notre arbre ne commet alors aucune erreur sur cet échantillon puisqu'il en épouse toutes les caractéristiques : performance égale à 100%. Dès lors que l'on applique ce modèle sur de nouvelles données qui par nature n'ont pas toutes les caractéristiques de notre échantillon d'apprentissage (il s'agit simplement d'un autre échantillon) sa performance va donc se dégrader pour à la limite se rapprocher de 0%...!
Ainsi, lorsque l'on construit un arbre de décision, on risque ce que l'on appelle un surajustement du modèle : le modèle semble performant (son erreur moyenne est très faible) mais il ne l'est en réalité pas du tout ! Il va nous falloir trouver l'arbre le plus petit possible ayant la plus grande performance possible. Plus un arbre est petit et plus il sera stable dans ses prévisions futures (en statistiques, le principe de parcimonie prévaut presque toujours) ; plus un arbre est performant, plus il est satisfaisant pour l'analyste. Il ne sert à rien de générer un modèle de très bonne qualité, si cette qualité n’est pas constante et se dégrade lorsque l’on applique ce modèle sur un nouvel ensemble de données.
Autrement dit, pour éviter un sur-ajustement de nos arbres (et c'est également vrai de tous les modèles mathématiques que l'on pourrait construire), il convient d'appliquer un principe de parcimonie et de réaliser des arbitrages performance/complexité des modèles utilisés. À performance comparable, on préfèrera toujours le modèle le plus simple, si l'on souhaite pouvoir utiliser ce modèle sur de nouvelles données totalement inconnues.
Le problème du sur-ajustement des modèles
Comment réaliser cet arbitrage performance/complexité des modèles utilisés ? En premier lieu, en évaluant la performance d'un ou de plusieurs modèles sur les données qui ont servi à sa construction (le ou les échantillons d'apprentissage), mais également sur ce que l'on appelle un (ou plusieurs) échantillon de test, c'est-à-dire des données à notre disposition mais que nous décidons volontairement de ne pas utiliser dans la construction de nos modèles[2]. Tout se passe comme si ces données de test étaient de nouvelles données, la réalité. C'est notamment la stabilité de la performance de nos modèles sur ces deux types d'échantillon nous permettra de juger de son sur-ajustement potentiel et donc de sa capacité à être utilisé avec un risque d'erreur maitrisé dans des conditions réelles où les données ne sont pas connues à l'avance...
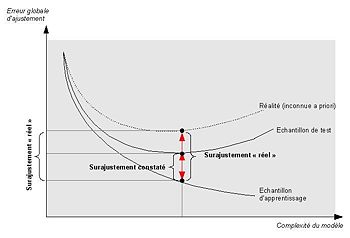 Sur-ajustement d'un modèle : arbitrage performance / complexité
Sur-ajustement d'un modèle : arbitrage performance / complexité
Dans le graphique ci-contre, nous observons l’évolution de l’erreur d’ajustement d'un arbre de décision en fonction du nombre de feuilles de l’arbre (complexité). Nous constatons que si l’erreur décroît constamment sur l’échantillon d’apprentissage, à partir d'un certain niveau de complexité (de très nombreuses branches et de très nombreuses feuilles) ce modèle s'éloigne de la réalité, réalité que l’on essaie de mesurer ou en tout cas d'approcher sur un second échantillon de données (échantillon test dans le graphique).
Dans le cas des arbres de décisions, plusieurs types de solutions algorithmiques ont été envisagées pour tenter d'éviter autant que possible un problème de sur-ajustement potentiel des modèles : il s'agit des techniques dites de pré ou de post élagage des arbres.
Certaines théories statistiques (voir les travaux du mathématicien russe Vladimir Vapnik) vont même jusqu'à avoir pour objet de trouver l'optimum entre l'erreur commise sur l'échantillon d'apprentissage et celle commise sur l'échantillon de test. La théorie de Vapnik Chervonenkis, « Structured Risk Minimization (SRM) », en utilisant une variable appelée « VC dimension », fournit une modélisation mathématique parfaite de la détermination de l’optimum d’un modèle, utilisable par conséquent pour générer des modèles qui assurent le meilleur compromis entre qualité et robustesse du modèle.
Dans tous les cas, ces solutions algorithmiques sont complémentaires des analyses de performances comparées et de stabilité effectuées sur les échantillons d'apprentissage et de test.
Le pré-élagage
La première stratégie utilisable pour éviter un surajustement massif des arbres de décision consiste à proposer des critères d’arrêt lors de la phase d’expansion. C’est le principe du pré-élagage. Nous considérons par exemple qu’une segmentation n’est plus nécessaire lorsque le groupe est d’effectif trop faible ; ou encore, lorsque la pureté d’un sommet a atteint un niveau suffisant, nous considérons qu’il n’est plus nécessaire de le segmenter ; autre critère souvent rencontré dans ce cadre, l’utilisation d’un test statistique pour évaluer si la segmentation introduit un apport d’information significatif quant à la prédiction des valeurs de la variable à prédire.
Le post-élagage
La seconde stratégie consiste à construire l’arbre en deux temps : produire l’arbre le plus pur possible dans une phase d’expansion en utilisant une première fraction de l’échantillon de données (échantillon d’apprentissage à ne pas confondre avec la totalité de l’échantillon, en anglais « growing set » est moins ambigu) ; puis effectuer une marche arrière pour réduire l’arbre, c’est la phase de post-élagage, en s’appuyant sur une autre fraction des données de manière à optimiser les performances de l’arbre. Selon les logiciels, cette seconde portion des données est désignée par le terme d’échantillon de validation ou échantillon de test, introduisant une confusion avec l’échantillon utilisé pour mesurer les performances des modèles. Le terme qui permet de le désigner sans ambiguïté est « échantillon d’élagage », traduction directe de l’appellation anglo-saxonne « pruning set ».
Affectation de la conclusion sur chaque feuille
Une fois l’arbre construit, il faut préciser la règle d’affectation dans les feuilles. A priori, si elles sont pures, la réponse est évidente. Si ce n’est pas le cas, une règle simple est de décider comme conclusion de la feuille la classe majoritaire, celle qui est la plus représentée.
Cette technique très simple est la procédure optimale dans un cadre très précis : les données sont issues d’un tirage aléatoire simple dans la population ; la matrice des coûts de mauvaise affectation est unitaire (symétrique) c'est-à-dire affecter à bon escient ne coûte rien (coût égal à 0), et affecter à tort coûte 1 quel que soit le cas de figure. En dehors de ce canevas, la règle de la majorité n’est pas justifiée. Il reste néanmoins que c’est un référentiel facile à utiliser dans la pratique.
Les différents algorithmes envisageables
À partir de ces 4 points, il existe un très grand nombre de variantes. Certaines mettent l’accent sur tel ou tel aspect de l’algorithme de construction, mais il n’existe pas de méthode qui soit dans la pratique systématiquement plus performante. Voici une liste non exhaustive des algorithmes classiquement utilisés :
Ces algorithmes se distinguent par le ou les critères de segmentation utilisés, par les méthodes d'élégages implémentées... mais aussi par leur manière de gérer les données manquantes dans nos prédicteurs. Ce point prend toute son importance dans la pratique. En effet, les données à disposition en entreprise par exemple sont quasi systématiquement incomplètes. Que faire en présence de données manquantes ?
- Les ignorer : cela n'est possible que si l'échantillon de données est suffisamment grand pour supprimer des individus (des lignes de la base de données), et que si l'on est sûr que lorsque l'arbre de décision sera utilisé en pratique (lorsqu'il sera déployé), toutes les données seront toujours disponibles pour tous les individus.
- Les remplacer par une valeur calculée jugée adéquate (on parle d'imputation de valeurs manquantes) : cette technique est parfois utilisée dans le monde de la statistique mais au-delà des problèmes purement mathématiques qu'elle peut poser elle se heurte à une pierre d'achoppement méthodologique.
- Utiliser des variables subsituts : cela consiste, pour un individu qui aurait une donnée manquante pour une variable sélectionnée par l'arbre comme étant discriminante, à utiliser la variable qui parmi l'ensemble des variables disponibles dans la base de données produit localement les feuilles les plus similaires aux feuilles produites par la variable dont la donnée est manquante. Cette variable s'appelle un substitut. Si un individu a une valeur manquante pour la variable initiale, mais aussi pour la variable substitut, on peut utiliser une deuxième variable substitut. Et ainsi de suite, jusqu'à la limite d'un critère de qualité du substitut. Cette technique a l'avantage d'exploiter l'ensemble de l'information disponible (cela est donc très utile lorsque cette information est complexe à récupérer mais est malheureusement incomplète) pour chaque individu.
Les arbres ont connu un net regain d’intérêt lorsque les méthodes d’agrégation des classifieurs tels que le boosting ou le bagging ont été développées et popularisées dans la communauté de l’apprentissage automatique. Certaines des caractéristiques des arbres, notamment leur variabilité très marquée, leur permettent de tirer parti des avantages de la combinaison des prédicteurs. Des techniques spécifiques ont même été développées pour produire des arbres individuellement peu efficaces, mais lorsqu’elles sont combinées, s’avèrent très performantes, c’est le cas notamment des Random Forests (forêts d'arbres) de Breiman.
Dans des processus de data mining les arbres de décision sont parfois combinés à des techniques plus classiques de modélisation d'un objectif fixé : analyse discriminante, régressions logisitiques (régression logistique), régressions linéaires (régression linéaire), réseaux de neurones (perceptrons multicouches, radial basis function network...)... Ils sont également très souvent combinés entre eux pour tirer profit de leurs avantages respectifs. Des procédures d'agrégation des performances des différents modèles utilisés, parfois appelées procédures de vote, sont alors mises en place pour obtenir une performance maximale, tout en controlant et en minimisant le niveau de complexité de l'ensemble des modèles utilisés.
Généralisation à d'autres problématiques
Les arbres de décision telles qu’ils ont été présentés ici sont dédiés à l’apprentissage supervisé où l’on essaie de prédire (expliquer) les valeurs prises par une variable discrète (Etre malade ou pas, Répondre positivement à une offre promotionnelle ou pas, etc.) à partir d’une série de variables discriminantes de type quelconque. En réalité, la démarche peut être étendue à d’autres types de problématiques.
Lorsque la variable cible est continue, nous nous situons dans le cadre de la régression (la méthode la plus populaire dans ce cadre est la Régression linéaire). Le même schéma d’exploration peut être appliqué, sauf qu’au lieu d’optimiser le taux d’erreur, nous optimisons l’erreur quadratique, et le critère de segmentation devient la décomposition de la variance : nous choisissons la variable qui maximise la variance inter-classes. On parle dans ce cas d’arbres de régression, la méthode CART, dans sa version RT (Regression Tree) est la plus connue.
Lorsque nous avons affaire à plusieurs variables cibles, nous nous situons dans un problème de classification automatique (ou de typologie). On parle dans ce cas d’arbres de classification (Clustering Tree en anglais). Le critère d’évaluation des partitions est l’inertie, qui est ni plus ni moins qu’une généralisation de la variance dans un cadre multidimensionnel. Les méthodes les plus connues sont dues à Chavent (1998, les Méthodes Divisives Monothétiques) et Blockeel (1998, Predictive Clustering Tree). Il semble que les typologies proposées par ces techniques soient aussi bonnes, en termes d’inertie expliquée, que celles produites par les approches classiques (Classification Ascendante Hiérarchique, Nuées dynamiques, etc.), avec la lisibilité des résultats en plus.
Notes
- ↑ Des heuristiques sont notamment utilisées lorsque l'on cherche à réduire la complexité de l'arbre en agrégeant les modalites des variables utilisées comme prédicteurs de la cible. Par exemple, pour le cas des modalités d'une variable de classes d'âge, on ne va autoriser que des regroupements de classes d'âge contigues.
- ↑ Le problème du sur-ajustement des modèles n'est pas propre aux arbres de décisions mais commun à l'ensemble des techniques de modélisation mathématico-informatiques. Il est au centre des processus de data mining.
Références
- L. Breiman, J. Friedman, R. Olshen, C. Stone: CART: Classification and Regression Trees, Wadsworth International, 1984.
- R. Quinlan: C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers Inc., 1993.
- D. Zighed, R. Rakotomalala: Graphes d'Induction -- Apprentissage et Data Mining, Hermes, 2000.
- Daniel T. Larose (adaptation française T. Vallaud): Des données à la connaissance : Une introduction au data-mining (1Cédérom), Vuibert, 2005.
Liens externes
- Arbres de décision, Tutoriel en ligne, Revue MODULAD n°33.
- Manuel de statistiques en ligne, (en Anglais).
Logiciels
Tous les principaux logiciels commerciaux d'analyse statistique ou de Data Mining intègrent un module de construction graphique des arbres de décision. L’offre est moins pléthorique concernant les logiciels gratuits ou libres.
- SPSS, Clementine, SAS, SAS Enterprise Miner, ALICE, SPAD, STATISTICA, SYSTAT
- SIPINA, un logiciel gratuit de construction des arbres de décision.
- R, un logiciel gratuit très complet d'analyses statistiques, pour construire entre autres des arbres de décision.
- Liens vers d'autres logiciels d’induction des arbres de décision.
Certains progiciels de gestion de campagnes marketing et/ou d'optimisation de campagnes marketing (c'est aussi le cas d'autres problématiques fonctionnelles) intègrent notamment des algorithmes de construction d'arbre de décision (ainsi très souvent que des heuristiques fonctionnelles), de manière tout à fait transparente, et en rendent l'utilisation directement opérationnelle :
Aujourd'hui, la plupart des grands éditeurs commerciaux de bases de données relationnelles (Base de données relationnelle, Oracle (base de données), Microsoft SQL Server...) embarquent de nombreux algorithmes de data mining dont certains arbres de décision. L'idée est de permettre aux analystes d'exploiter toute la puissance de calcul de ces bases de données et des machines serveur sur lesquelles elles sont installées.
 Portail de l’informatique
Portail de l’informatique
Catégories : Décision | Métaheuristique | Apprentissage automatique

Wikimedia Foundation. 2010.