- WWW
-
World Wide Web
Le World Wide Web, littéralement la « toile (d’araignée) mondiale », communément appelé le Web, parfois la Toile ou le WWW, est un système hypertexte public fonctionnant sur Internet et qui permet de consulter, avec un navigateur, des pages mises en ligne dans des sites. L’image de la toile d'araignée vient des hyperliens qui lient les pages web entre elles[1].
Le Web n’est qu’une des applications d’Internet. D’autres applications d’Internet sont le courrier électronique, la messagerie instantanée, Usenet, etc. Le Web a été inventé plusieurs années après Internet, mais c’est lui qui a rendu les médias grand public attentifs à Internet. Depuis, le Web est fréquemment confondu avec Internet ; en particulier, le mot Toile est souvent utilisé dans les textes non techniques sans qu’il soit clairement exprimé s’il désigne le Web ou Internet.

Sommaire
Terminologie
Termes désignant le World Wide Web
Le World Wide Web est et a été désigné par de nombreux noms et abréviations synonymes : WorldWideWeb, World Wide Web, World-wide Web, Web, WWW, W3, Toile d’araignée mondiale, Toile mondiale, Toile.
Le nom du projet originel était WorldWideWeb[2]. Les mots ont été rapidement séparés en World Wide Web pour améliorer la lisibilité. Le nom World-Wide Web a également été utilisé par les inventeurs du Web, mais le nom désormais préconisé par le World Wide Web Consortium sépare les trois mots sans trait d’union[3]. Bien que « mondial » s’écrive world-wide ou worldwide en anglais, l’orthographe World Wide Web et l’abréviation Web sont maintenant bien établies.
En inventant le Web, Tim Berners-Lee avait aussi pensé à d’autres noms, comme Information Mesh (maillage d’informations), Mine of Information ou encore The Information Mine (la mine d’informations, dont le sigle serait Tim).
Le sigle WWW a été largement utilisé pour abréger World Wide Web avant que l’abréviation Web ne prenne le pas. La prononciation laborieuse (en français comme en anglais) de WWW a sans doute précipité son déclin. WWW se prononce souvent trois double V, triple double V, ou vévévé.
Les lettres www restent cependant très utilisées dans les adresses Web et quelques autres usages formels ou techniques, bien que cela ne réponde à aucune contrainte technique. Dans la seconde moitié des années 1990, alors que les réseaux étaient engorgés par la popularité grandissante du Web, une blague répandue prétendait que WWW signifiait World Wide Wait, soit « attente mondiale ». WWW est parfois abrégé en W3, abréviation qu’on retrouve dans le sigle W3C du World Wide Web Consortium.
Pour écrire « le web », l’usage de la minuscule (« le web ») est de plus en plus courant. L’Office québécois de la langue française préconise la majuscule[4], le Journal officiel français préconise « la toile d’araignée mondiale »[5]. Cet article fait la distinction entre « le Web » et « un web », aussi la majuscule est toujours utilisée pour désigner le Web.
Web 2.0
L'expression « Web 2.0 » a été utilisée à partir de 2004. Son usage a été massif et reconnu vers 2007. En principe, l'expression désigne une certaine évolution de l'usage du Web, les sites étant devenu plus interactifs. Le terme a rapidement été réutilisé à des fins marketing, au point que certains informaticiens en viennent à considérer que cette expression n'a pas d'existence autre que marketing.
Depuis, le terme a été décliné, d'une part en ajoutant « 2.0 » à tout concept pour signifier « s'appuyant sur le web 2.0 » (par exemple le Marketing 2.0). De même, pour décrire l'évolution du Web, de nombreux numéros de versions ont été proposés (Web 1.0 pour désigner, par opposition, les débuts du Web) — certains pour tenter d'établir une terminologie cohérente, d'autres par parodie.
Termes rattachés au Web
La terminologie propre au Web contient plusieurs dizaines de termes. Ce chapitre expose ceux qui sont utilisés dans cet article.
L’expression en ligne signifie « connecté à un réseau », en l’occurrence le réseau informatique Internet. Cette expression n’est pas propre au Web, on la retrouve à propos du téléphone.
Un hôte est un ordinateur en ligne. Chaque hôte d’Internet est identifié par une adresse IP à laquelle correspondent zéro, un ou plusieurs noms d’hôte. Cette terminologie n’est pas propre au Web, mais à Internet.
Une ressource du World Wide Web est une entité informatique (texte, image, forum Usenet, boîte aux lettres électronique, etc.) accessible indépendamment d’autres ressources. Une ressource en accès public est librement accessible depuis Internet. Une ressource locale est présente sur l’ordinateur utilisé, par opposition à une ressource distante (ou en ligne), accessible à travers un réseau.
On ne peut accéder à une ressource distante qu’en respectant un protocole de communication. Les fonctionnalités de chaque protocole varient : réception, envoi, voire échange continu d’informations.
HTTP (pour HyperText Transfer Protocol) est le protocole de communication communément utilisé pour transférer les ressources du Web. HTTPS est la variante sécurisée de ce protocole.
Une URL (pour Uniform Resource Locator) pointe sur une ressource. C’est une chaîne de caractères permettant d’indiquer un protocole de communication et un emplacement pour toute ressource du Web.
Un hyperlien (ou lien) est un élément dans une ressource associé à une URL. Les hyperliens du Web sont orientés : ils permettent d’aller d’une source à une destination. Seule la ressource à la source contient les données définissant l’hyperlien, la ressource de destination n’en porte aucune trace. Il existe deux types d’hyperlien : ceux du premier type doivent être activés pour accéder à la destination ; ceux du second causent un accès automatique à la destination.
HTML (pour HyperText Markup Language) est un langage informatique permettant de décrire le contenu d’un document (titres, paragraphes, disposition des images, etc.) et d’y inclure des hyperliens. Un document HTML est un document décrit avec le langage HTML. Les documents HTML sont les ressources les plus consultées du Web. Le HTML est maintenant remplacé par le XHTML (Extensible HyperText Markup Language).
Dans un mode de communication client-serveur, un serveur est un hôte sur lequel fonctionne un logiciel serveur auquel peuvent se connecter des logiciels clients fonctionnant sur des hôtes clients.
Un serveur Web est un hôte sur lequel fonctionne un serveur HTTP (ou serveur Web). Un serveur Web héberge les ressources qu’il dessert.
Un navigateur Web est un logiciel client HTTP conçu pour accéder aux ressources du Web. Sa fonction de base est de permettre la consultation des documents HTML disponibles sur les serveurs HTTP. Le support d’autres types de ressource et d’autres protocoles de communication dépend du navigateur considéré.
Une page Web (ou page) est un document destiné à être consulté avec un navigateur Web. Une page Web est toujours constituée d’une ressource centrale (généralement un document HTML) et d’éventuelles ressources liées automatiquement accédées (typiquement des images).
Un éditeur HTML (ou éditeur Web) est un logiciel conçu pour faciliter l’écriture de documents HTML et de pages Web en général.
Un site Web (ou site) est un ensemble de pages Web et d’éventuelles autres ressources, liées dans une structure cohérente, publiées par un propriétaire (une entreprise, une administration, une association, un particulier, etc.) et hébergées sur un ou plusieurs serveurs Web.
Visiter un site Web signifie « consulter ses pages ». Le terme visite vient du fait que l’on consulte généralement plusieurs pages d’un site, comme on visite les pièces d’un bâtiment. La visite est menée par un utilisateur (ou visiteur ou internaute). La mesure d’audience est obtenue en copiant le code en javascript d’un lien vers le site d’un prestataire spécialisé suivant la technique du marqueur à distance.
Une adresse Web est une URL de page Web, généralement écrite sous une forme simplifiée limitée à un nom d’hôte. Une adresse de site Web est en fait l’adresse d’une page du site prévue pour accueillir les visiteurs.
Un hébergeur Web est une entreprise de services informatiques hébergeant (mettant en ligne) sur ses serveurs Web les ressources constituant les sites Web de ses clients.
Une agence Web est une entreprise de services informatiques réalisant des sites Web pour ses clients.
L’expression surfer sur le Web signifie « consulter le Web ». Elle a été inventée pour mettre l’accent sur le fait que consulter le Web consiste à suivre de nombreux hyperliens de page en page. Elle est principalement utilisée par les médias ; elle n’appartient pas au vocabulaire technique.
Un annuaire Web est un site Web répertoriant des sites Web.
Un portail Web est un site Web tentant de regrouper la plus large palette d’informations et de services possibles dans un site Web. Certains portails sont thématiques.
Un service Web est une technologie client-serveur basée sur les protocoles du Web.
Architecture
Modèle mathématique
Le World Wide Web, en tant qu’ensemble de ressources hypertextes, est modélisable en graphe orienté avec les ressources pour sommets et les hyperliens pour arcs. Du fait que le graphe est orienté, certaines ressources peuvent constituer des puits (ou des cul-de-sac, moins formellement) : il n’existe aucun chemin vers le reste du Web. À l’inverse, certaines ressources peuvent constituer des sources : il n’existe aucun chemin depuis le reste du Web.
Techniquement, rien ne distingue le World Wide Web d’un quelconque autre Web utilisant les mêmes technologies ; d’ailleurs d’innombrables Webs privés existent. Dans la pratique, on considère qu’une page d’un site Web populaire, comme un annuaire Web, fait partie du Web. Le Web peut alors être défini comme étant l’ensemble des ressources et des hyperliens que l’on peut récursivement découvrir à partir de cette page, ce qui exclut les sources et les Webs privés.
Exploration du Web et Web profond
L’exploration récursive du Web à partir de ressources bien choisies est la méthode de base programmée dans les robots d’indexation des moteurs de recherche. En 2004, les moteurs de recherche indexent environ 4 milliards de ressources.
Le Web profond, ou Web invisible, est la partie du Web qui n’est pas indexée et donc introuvable avec les moteurs de recherche généralistes. Des études indiquent que la partie invisible du Web représente plus de 99 % du Web[6]. Le Web profond comprend notamment les ressources suivantes :
- les ressources inaccessibles au public, donc aux robots, notamment les pages administratives ou payantes, protégées par un mot de passe ;
- les ressources qui ne sont pas communiquées par des protocoles de communication pris en charge par les robots (souvent ils ne prennent en charge que HTTP et HTTPS) ;
- les ressources dont le format de données n'est pas pris en charge par le robot ;
- les ressources listées dans un fichier d’exclusion des robots ;
- les ressources exclues par le robot car elles sont conçues pour abuser du référencement (spamdexing) ;
- les ressources exclues par le robot car elles sont considérées comme trop peu pertinentes (par exemple si un site contient des millions de ressources qui ne sont liées par aucun autre site) ;
- les ressources vers lesquelles les hyperliens sont créés dynamiquement en réponse aux interrogations des visiteurs.
Ces dernières ressources proviennent généralement de bases de données et constituent la partie la plus importante du Web profond.
Serveurs publics
L’exploration récursive n’est pas le seul moyen utilisé pour indexer le Web et mesurer sa taille. L’autre solution consiste à mesurer l’infrastructure informatique connectée à Internet pour héberger des sites Web. Au lieu de suivre des hyperliens, cette méthode consiste à utiliser les noms de domaine enregistrés dans le Domain Name System et essayer de se connecter à tous les serveurs Web potentiels. C’est notamment la méthode utilisée par la société Netcraft, qui publie régulièrement les résultats de ses explorations, dont les mesures de popularité des serveurs HTTP. Cette mesure porte plus sur l’utilisation des technologies du Web que sur le Web lui-même. Elle permet notamment de trouver des sites publics qui ne sont pas liés au World Wide Web.
Intranets et Webs privés
Un Web disponible sur un intranet est privé. Il est soit totalement séparé du Web, soit une source du Web. Il est une source lorsque l’intranet est relié à Internet et qu’un hyperlien du Web pointe sur une ressource du Web. Les liens depuis le Web sont en revanche impossibles car par définition un intranet n’offre pas d’accès public.
Une source peut aussi se trouver sur Internet. En ce cas, elle constitue un Web virtuellement privé, car le public ne peut pas le découvrir en suivant des hyperliens.
Archivage
Le Web change constamment : les ressources ne cessent d’être créées, modifiées et supprimées. Il existe quelques initiatives d’archive du Web dont le but est de permettre de retrouver ce que contenait un site à une date donnée. Le projet Internet Archive est l’un d’eux.
Types de ressource
Les divers types de ressource du Web ont des usages assez distincts :
- les ressources constituant les pages Web : documents HTML, images JPEG ou PNG ou GIF, scripts JavaScript, feuilles de style CSS, sons, animations ;
- les ressources accessibles depuis une page Web mais consultables avec une interface particulière : flux audio, flux vidéo ;
- les ressources conçues pour être consultées séparément : documents (PDF, PostScript, Word, etc.), fichier texte, images de tout types, morceaux de musique, vidéo, fichiers à sauvegarder ;
- les ressources appartenant à des systèmes bien distincts du Web : forums Usenet, boîtes aux lettres électronique, fichiers locaux.
Documents HTML
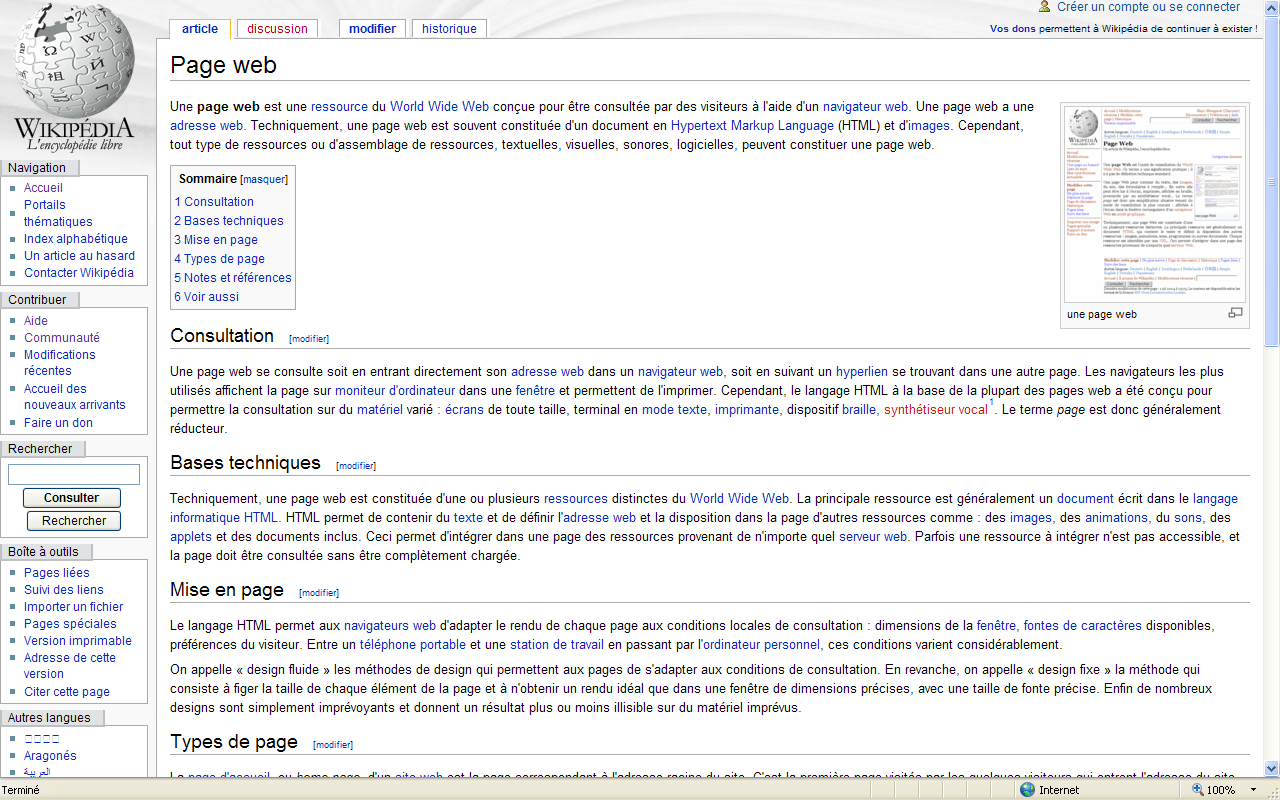
Le document HTML est la principale ressource d’une page Web, celle qui contient les hyperliens, qui contient et structure le texte, qui lie et dispose les ressources multimédias. Un document HTML contient uniquement du texte : le texte consulté, le texte en langage HTML plus d’éventuels autres langages de script ou de style.
La présentation de documents HTML est la principale fonctionnalité d’un navigateur Web. HTML laisse au navigateur le soin d’exploiter au mieux les capacités de l’ordinateur pour présenter les ressources. Typiquement, la police de caractère, la longueur des lignes de texte, les couleurs, etc, doivent être adaptées au périphérique de sortie (écran, imprimante, etc).
Multimédia
Les éléments multimédias proviennent toujours de ressources indépendantes du document HTML. Les documents HTML contiennent des hyperliens pointant sur les ressources multimédias, qui peuvent donc être éparpillées sur Internet. Les éléments multimédias liés sont automatiquement transférés pour présenter une page Web.
Seul l’usage des images et des petites animations est standardisé. Le support du son, de la vidéo, d’espaces tridimensionnels ou d’autres éléments multimédias repose encore sur des technologies non standardisées. De nombreux navigateurs Web proposent la possibilité de greffer des logiciels (plugin) pour étendre leurs fonctionnalités, notamment le support de types de média non standard.
Les flux (audio, vidéo) nécessitent un protocole de communication au fonctionnement différent de HTTP. C’est une des raisons pour lesquelles ce type de ressource nécessite souvent un plugin et est mal intégré aux pages Web.
Images
Ce chapitre concerne les images intégrées aux pages Web.
L’usage du format de données JPEG est indiqué pour les images naturelles, principalement les photographies.
L’usage du format de données PNG est indiqué pour les images synthétiques (logos, éléments graphiques). Il est aussi indiqué pour les images naturelles, mais uniquement lorsque la qualité prime totalement sur la durée du transfert.
L’usage du format de données GIF est indiqué pour les petites animations. Pour les images synthétiques, la popularité ancienne de GIF le fait souvent préférer à PNG. Cependant, GIF souffre de quelques désavantages, notamment la limitation du nombre de couleurs et un degré de compression généralement moindre. En outre une controverse a entouré l’usage de GIF de 1994 à 2004 car Unisys a fait valoir un brevet couvrant la méthode de compression.
L’usage d’images de format de données XBM est obsolète.
Scripts
Un langage de script permet d’écrire le texte d’un programme directement exécuté par un logiciel. Dans le cadre du Web, un script est exécuté par un navigateur Web et programme des actions répondant à l’usage que le visiteur fait de la page Web consultée. Un script peut être intégré au document HTML ou provenir d’une ressource liée. Le premier langage de script du Web fut JavaScript, développé par Netscape. Ensuite Microsoft a développé une variante concurrente sous le nom de JScript. Finalement, la norme ECMAScript a été proposée pour la syntaxe du langage, et les normes DOM pour l’interface avec les documents.
Styles
Le langage CSS a été développé pour gérer en détail la présentation des documents HTML. Le texte en langage CSS peut être intégré au document HTML ou provenir de ressources liées, les feuilles de style. Cette séparation permet une gestion séparée de l’information (contenue dans des documents HTML) et de sa présentation (contenue dans des feuilles de style). On parle aussi de « séparation du fond et de la forme ».
Autres
La gestion des autres types de ressource dépend des logiciels installés sur l’hôte client et de leurs réglages.
Lorsque le logiciel correspondant est disponible, les documents et images de tout types sont généralement automatiquement présentés, selon des modalités (fenêtrage, dialogues) dépendant du navigateur Web et du logiciel gérant le type. Lorsque le type de la ressource n’est pas géré, il est généralement possible de la sauver dans un fichier local.
Pour gérer les ressources de systèmes différents du Web comme le courrier électronique, les navigateurs font habituellement appel à des logiciels séparés. Si aucun logiciel ne gère un type de ressource, un simple message d’erreur l’indique.
Conception
Universalité
Le Web a été conçu pour être accessible avec les équipements informatiques les plus divers : station de travail, terminal informatique en mode texte, ordinateur personnel, PDA, etc. Cette universalité d’accès dépend en premier lieu de l’universalité des protocoles Internet. En second lieu, elle dépend de la flexibilité de présentation des pages Web, offerte par HTML. En outre, HTTP offre aux navigateurs la possibilité de négocier le type de chaque ressource. Enfin, CSS permet de proposer différentes présentations, sélectionnées pour leur adéquation avec l’équipement utilisé.
Le W3C a pour cela créé des normes dans le but de permettre l'indépendance des outils qui servent à créer du contenu avec ceux qui servent à le lire. On appelle cela l'interopérabilité.
L’accessibilité du Web pour les individus handicapés est aussi l’objet d’attentions particulières comme la Web Accessibility Initiative.
Décentralisation
Les technologies du Web n’imposent pas d’organisation entre les pages Web, ni a fortiori entre les sites Web. Toute page du Web peut contenir un hyperlien vers toute autre ressource accessible d’Internet. L’établissement d’un hyperlien ne requiert absolument aucune action du côté de la ressource pointée. Il n’y a pas de registre centralisé d’hyperliens, de pages ou de sites. Le seul registre utilisé est celui du DNS, c’est une base de donnée distribuée qui répertorie des hôtes et est utile à tous les systèmes basés sur Internet.
Cette conception décentralisée devait favoriser, et a favorisé, une augmentation rapide de la taille du Web. Elle a aussi favorisé l’essor de sites spécialisés dans les informations sur les autres sites : les annuaires et les moteurs de recherche. Sans ces sites, la recherche d’information dans le Web serait extrêmement laborieuse. La démarche inverse, le portail Web, tente de concentrer un maximum d’informations et de services dans un seul site.
Une faiblesse de la décentralisation est le manque de suivi lorsqu’une ressource est déplacée ou supprimée : les hyperliens qui la pointaient se retrouvent cassés. Et cela n’est visible qu’en activant l’hyperlien, le résultat le plus courant étant le message d’erreur 404.
Technologies
Pré-existantes
Le Web repose sur les technologies d’Internet, notamment TCP/IP pour assurer le transfert des données, DNS pour convertir les noms d’hôte en adresses IP et MIME pour indiquer le type des données. Les standards de codage de caractères et les formats d’image numérique GIF et JPEG ont été développés indépendamment.
Spécifiques
Trois technologies ont dû être développées pour le World Wide Web :
- les URL pour pouvoir identifier toute ressource dans un hyperlien ;
- le langage HTML pour écrire des pages Web contenant des hyperliens ;
- le protocole de communication HTTP utilisé entre les navigateurs et les serveurs Web, qui permet d’indiquer le type MIME des ressources transférées.
Ces premières technologies ont été normalisées comme les autres technologies d’Internet : en utilisant le processus des Request for Comments. Cela a donné le RFC 1738 pour les URL, le RFC 1866 pour HTML 2.0 et le RFC 1945 pour HTTP/1.0.
Le World Wide Web Consortium (W3C) a été fondé en 1994 pour développer et promouvoir les nouveaux standards du Web. Son rôle est notamment de veiller à l’universalité des nouvelles technologies. Des technologies ont également été développées par des entreprises privées.
Actuelles
Les principaux standards actuels sont :
- XML 1.0 développé pour donner aux langages de balises, dont HTML, une syntaxe plus simple que SGML ;
- HTML 4.01 basé sur SGML, et XHTML 1.0 basés sur XML ;
- le RFC 2396 (Uniform Resource Identifiers), qui recouvre les URL ;
- le RFC 2616 (HTTP/1.1) ;
- les feuilles de styles en cascade CSS level 1 et level 2 ;
- les modèles de document DOM level 1 et level 2 ;
- le langage de script JavaScript pour manipuler les documents ;
- les formats d’image numérique PNG, JPEG et GIF.
Technologies serveur
Outre les protocoles de communication et formats de données échangés sur le Web, plusieurs techniques propres au Web sont mises en œuvre pour faire fonctionner les serveurs Web. Comme ces techniques ne sortent pas du serveur, elles ne sont pas standardisées par le World Wide Web Consortium.
- Le standard CGI (Common Gateway Interface) est un protocole de communication inter-processus entre le serveur HTTP et des applications externes.
- Le langage de programmation PHP (PHP: Hypertext Preprocessor) a été développé pour générer les pages Web. Il jouit d’une forte intégration avec le serveur HTTP et les langages HTML.
- Le moteur ASP (Active Server Pages) a été développé par Microsoft pour interpréter du langage de script dans le serveur IIS (Internet Information Services).
Historique
Tim Berners-Lee travaille comme informaticien à l’Organisation européenne pour la recherche nucléaire (CERN) lorsqu’il propose, en 1989, de créer un système hypertexte distribué sur le réseau informatique pour que les collaborateurs puissent partager les informations au sein du CERN[7]. Cette même année, les responsables du réseau du CERN décident d’utiliser le protocole de communication TCP/IP et le CERN ouvre sa première connexion extérieure avec Internet[8].
L’année suivante, l’ingénieur système Robert Cailliau se joint au projet d’hypertexte au CERN, immédiatement convaincu de son intérêt, et se consacre énergiquement à sa promotion[9]. Tim Berners-Lee et Robert Cailliau sont reconnus comme les deux personnes à l’origine du World Wide Web.
Jusqu’en 1993, le Web est essentiellement développé sous l’impulsion de Tim Berners-Lee et Robert Cailliau. Les choses changent avec l’apparition de NCSA Mosaic, un navigateur Web développé par Eric Bina et Marc Andreessen au National Center for Supercomputing Applications (NCSA), dans l’Illinois. NCSA Mosaic jette les bases de l’interface graphique des navigateurs modernes et cause un accroissement exponentiel de la popularité du Web. Le NCSA produit également le NCSA HTTPd, un serveur HTTP qui évoluera en Apache HTTP Server, le serveur HTTP le plus utilisé depuis 1996.
En 1994, Netscape Communications Corporation est fondée avec une bonne partie de l’équipe de développement de NCSA Mosaic. Sorti fin 1994, Netscape Navigator supplante NCSA Mosaic en quelques mois.
En 1995, Microsoft essaie de concurrencer Internet avec The Microsoft Network (MSN) et échoue. Fin 1995, après la sortie de Windows 95 sans le moindre navigateur Web préinstallé, Microsoft lance avec Internet Explorer la guerre des navigateurs contre Netscape Navigator.
Chronologie
Les premières années de cet historique sont largement basées sur A Little History of the World Wide Web (Une petite histoire du World Wide Web).
- 1989
- Le 13 mars, Tim Berners-Lee, engagé au CERN à Genève en 1984 pour travailler sur l’acquisition et le traitement des données[10], propose de développer un système hypertexte organisé en Web, afin d’améliorer la diffusion des informations internes : Information Management: A Proposal[7].
- 1990

- Robert Cailliau rejoint le projet et collabore à la révision de la proposition : WorldWideWeb: Proposal for a HyperText Project[2].
- Étendue : Le premier serveur Web est
nxoc01.cern.ch; la première page Web esthttp://nxoc01.cern.ch/hypertext/WWW/TheProject.html; la plus ancienne page conservée date du 13 novembre. - Logiciels : Le premier navigateur Web, appelé WorldWideWeb (plus tard rebaptisé Nexus) est développé en Objective C sur NeXT [1]. En plus d’être un navigateur, WorldWideWeb est un éditeur Web. Le navigateur mode texte line-mode est développé en langage C pour être portable sur les nombreux modèles d’ordinateurs et simples terminaux de l’époque.
- Technologies : Les trois technologies à la base du Web, URL, HTML et HTTP, sont à l’œuvre. Sur NeXT, des feuilles de style simples sont également utilisées, ce qui ne sera plus le cas jusqu’à l’apparition des Cascading Style Sheets.
- 1991
- 1992
- 1993
- Le 30 avril, le CERN met les logiciels du World Wide Web dans le domaine public [8]. À la fin de l’année, les médias grand public remarquent Internet et le WWW.
- Étendue : 130 sites Web en juin, 623 en décembre [9] ; l’usage croît d’un rythme annuel de 341 634 %.
- Logiciels : Apparitions des navigateurs NCSA Mosaic et Lynx. Disponible d’abord sur X Window, puis sur Windows et MacOS, Mosaic cause un phénoménal accroissement de la popularité du Web.
- Technologies : images dans les pages Web (Mosaic 0.10) ; formulaires interactifs (Mosaic 2.0pre5).
- 1994
- Étendue : 2 738 sites en juin, 10 022 en décembre.
- Sites : Yahoo! créé par deux étudiants ; apparition de la publicité sur HotWired.
- Logiciels : Netscape Navigator 1.0.
- Standards : fondation du World Wide Web Consortium ; RFC 1738 (Uniform Resource Locators).
- 1995
- Microsoft crée MSN pour concurrencer Internet et le Web, puis change d’avis et lance la guerre des navigateurs.
- Étendue : 23 500 sites en juin (18 957 en août selon la première mesure de Netcraft [10]).
- Logiciels : serveur HTTP Apache ; Microsoft Internet Explorer 1.0 et 2.0.
- Sites : moteur de recherche AltaVista.
- Technologies : formatage tabulaire (Netscape Navigator 1.1b1), documents multi-cadres (Netscape Navigator 2.0b1), Java, JavaScript (Netscape Navigator 2.0b3), PHP.
- Standards : RFC 1866 (HTML 2.0).
- 1996
- Étendue : 100 000 sites en janvier, environ 230 000 en juin.
- Logiciels : Netscape Navigator 2.0 et 3.0 ; Internet Explorer 3.0 ; Opera 2.1.
- Standards : RFC 1945 (HTTP/1.0) ; CSS level 1.
- Sites : Internet Archive commence à archiver le Web.
- 1997
- Étendue : plus de 1 000 000 sites en avril selon Netcraft.
- Logiciels : Netscape Navigator 4.0 ; Internet Explorer 4.0.
- Standards : HTML 3.2 ; HTML 4.0.
- 1998
- 1999
- Étendue : plus de 4 000 000 de sites en janvier, plus de 7 400 000 en août.
- Logiciels : Internet Explorer 5.0.
- Standards : HTML 4.01 ; RFC 2616 (HTTP/1.1).
- 2000
- 2001
- Étendue : 27 585 719 sites en janvier, 30 775 624 en août.
- Logiciels : Internet Explorer 6.
- Sites : Wikipédia.
- 2002
- Étendue : 36 689 008 sites en janvier, 35 991 815 en août.
- Logiciels : Mozilla 1.0.
- 2003
- Étendue : 35 863 952 sites en février, 42 807 275 en août.
- Logiciels : Safari.
- 2004
- Le concept de Web 2.0 (désignant un phénomène pré-existant) apparaît.
- Étendue : 46 067 743 sites en janvier, 53 341 867 en août.
- Standards : création du WHATwg.
- Logiciels : Mozilla Firefox 1.0.
- 2005
- Étendue : 59 100 880 sites en février, 70 392 567 en août
- Logiciels : Mozilla Firefox 1.5.
- 2006
- Étendue : 76 184 000 sites en février, 92 615 362 en août[réf. nécessaire].
- Logiciels : Internet Explorer 7, Mozilla Firefox 2.0.
- 2007
- 2008
- Étendue : 158 209 426 sites en février, 176 748 506 en août[réf. nécessaire].
- Logiciels : Mozilla Firefox 3.0.
- Logiciels : Google Chrome 0.2.
- 2009
- Étendue : 216 000 000 sites en février[11]
- Logiciels : Internet Explorer 8
- Logiciels : Mozilla Firefox 3.5
- Logiciels : Safari 4
Notes et références
- ↑ L’image de l’araignée est parfois utilisée par les anglophones, on la retrouve ainsi dans l’expression web spider pour le robot d’indexation.
- ↑ a et b (en)WorldWideWeb: Proposal for a HyperText Project, T. Berners-Lee/CN, R. Cailliau/ECP, 12 novembre 1990
- ↑ (en)Frequently asked questions by the Press - Tim BL - Spelling of WWW
- ↑ Vocabulaire d’Internet - Banque de terminologie du Québec - World Wide Web
- ↑ Journal officiel du 16 mars 1999 - Vocabulaire de l’informatique et de l’internet
- ↑ (en)The Deep Web: Surfacing Hidden Value, Michael K. Bergman, The Journal of Electronic Publishing, August, 2001, Volume 7, Issue 1
- ↑ a et b (en)Tim Berners-Lee, Information Management: A Proposal, CERN, mars 1989
- ↑ James Gillies, Robert Cailliau, How the Web was born: the story of the World Wide Web, Oxford, Oxford University Press, 2000, ISBN 0-19-286207-3, p. 87
- ↑ (en) Tim Berners-Lee, Mark Fischetti, Weaving the Web: the past, present and future of the World Wide Web by its inventor, 2000 [détail des éditions] p. 27
- ↑ (en) Tim Berners-Lee, Mark Fischetti, Weaving the Web: the past, present and future of the World Wide Web by its inventor, 2000 [détail des éditions] p. 15
- ↑ http://news.netcraft.com/archives/2009/02/18/february_2009_web_server_survey.html
Voir aussi
Articles connexes
Concepts généraux
Internet, hypertexte, hyperlien, multimédia, réseau informatique
Concepts du Web
Accessibilité du Web, Adresse Web, agence Web, annuaire Web, hébergeur Web, page Web, portail Web, serveur Web, site Web, Web 2.0, Web profond, Web sémantique, Surf rémunéré
Technologies
ActionScript, DOM, dynamic HTML, CSS, HTML, HTTP, JavaScript, SGML, standards du Web, URI, URL, XHTML, XML
Logiciels serveurs
Apache HTTP Server, moteur de recherche, NCSA HTTPd, serveur HTTP, serveur proxy
Logiciels clients
Éditeur HTML, guerre des navigateurs, liste de navigateurs Web, navigateur Web, robot d’indexation
Acteurs
America Online, IETF, Marc Andreessen, Microsoft, Netscape Communications Corporation, Robert Cailliau, Tim Berners-Lee, WHATWG, World Wide Web Consortium
Applications
Blog, gestion des connaissances, système de gestion de contenu, Webmail, wiki
Liens externes
- (en) A Little History of the World Wide Web
- (en) (fr) info.cern.ch, rétrospective historique du CERN
 Portail sur Internet
Portail sur Internet
Catégorie : World Wide Web

Wikimedia Foundation. 2010.