- Ontologie informatique
-
Ontologie (informatique)
 Pour les articles homonymes, voir Ontologie.
Pour les articles homonymes, voir Ontologie.En philosophie, l'ontologie (du grec ὄν, ὄντος, participe présent du verbe être) est l'étude de l'être en tant qu'être, c'est-à-dire l'étude des propriétés générales de ce qui existe.
Par analogie, le terme est repris en informatique et en science de l'information, où une ontologie est l'ensemble structuré des termes et concepts représentant le sens d'un champ d'informations, que ce soit par les métadonnées d'un espace de noms, ou les éléments d'un domaine de connaissances. L'ontologie constitue en soi un modèle de données représentatif d'un ensemble de concepts dans un domaine, ainsi que les relations entre ces concepts. Elle est employée pour raisonner à propos des objets du domaine concerné.
Les concepts sont organisés dans un graphe dont les relations peuvent être :
- des relations sémantiques,
- des relations de subsomption (inclusion).
L'objectif premier d'une ontologie est de modéliser un ensemble de connaissances dans un domaine donné, qui peut être réel ou imaginaire.
Les ontologies sont employées dans l'intelligence artificielle, le Web sémantique, le génie logiciel, l'informatique biomédicale et l'architecture de l'information comme une forme de représentation de la connaissance au sujet d'un monde ou d'une certaine partie de ce monde. Les ontologies décrivent généralement :
- Individus : les objets de base,
- Classes : ensembles, collections, ou types d'objets[1],
- Attributs : propriétés, fonctionnalités, caractéristiques ou paramètres que les objets peuvent posséder et partager,
- Relations : les liens que les objets peuvent avoir entre eux,
- Événements : changements subis par des attributs ou des relations.
Sommaire
Définitions d'une ontologie
Approche abstraite
L’étymologie renvoie à la « théorie de l’existence », c’est-à-dire la théorie qui tente d’expliquer les concepts qui existent dans le monde et comment ces concepts s’imbriquent et s’organisent pour donner du SENS.
Contrairement à l'être humain, la connaissance pour un système informatique se limite à la connaissance qu'il peut représenter.
Chez l'être humain, les connaissances représentables (c'est-à-dire l'univers du discours) sont complétées par des connaissances non exprimables (sensations, perceptions, sentiments non verbalisables, connaissances inconscientes, connaissances tacites, etc.). Ces éléments non représentables participent pourtant aux processus de raisonnement et de décision, qui sont des processus cognitifs en gestion des connaissances. Les performances cognitives d'un agent informatique vont donc en partie reposer sur le champ des représentations auquel il aura accès, c'est-à-dire concrètement au champ des représentations qui aura été formalisé.
Les ontologies informatiques sont des outils qui permettent précisément de représenter un corpus de connaissances sous une forme utilisable par un ordinateur.
Une des définitions de l'ontologie qui fait autorité est celle de Gruber[2]:
« Une ontologie est la spécification d'une conceptualisation d'un domaine de connaissance »Cette définition s'appuie sur deux dimensions :
- Une ontologie est la conceptualisation d'un domaine, c'est-à-dire un choix quant à la manière de décrire un domaine.
- C'est par ailleurs la spécification de cette conceptualisation, c'est-à-dire sa description formelle.
C'est une base de formalisation des connaissances. Elle se situe à un certain niveau d'abstraction et dans un contexte particulier.C'est aussi une représentation d'une conceptualisation partagée et consensuelle, dans un domaine particulier et vers un objectif commun. Elle classifie en catégories les relations entre les concepts.
Critères d'évaluation d'une ontologie
D'après Gruber, cinq critères permettent de mettre en évidence des aspects importants d'une ontologie :
- La clarté : La définition d'un concept doit faire passer le sens voulu du terme, de manière aussi objective que possible (indépendante du contexte). Une définition doit de plus être complète (c’est-à-dire définie par des conditions à la fois nécessaires et suffisantes) et documentée en langage naturel.
- La cohérence : Rien qui ne puisse être inféré de l'ontologie ne doit entrer en contradiction avec les définitions des concepts (y compris celles qui sont exprimées en langage naturel).
- L'extensibilité : Les extensions qui pourront être ajoutées à l'ontologie doivent être anticipées. Il doit être possible d'ajouter de nouveaux concepts sans avoir à toucher aux fondations de l'ontologie.
- Une déformation d'encodage minimale : Une déformation d'encodage a lieu lorsque la spécification influe la conceptualisation (un concept donné peut être plus simple à définir d'une certaine façon pour un langage d'ontologie donné, bien que cette définition ne corresponde pas exactement au sens initial). Ces déformations doivent être évitées autant que possible.
- Un engagement ontologique minimal : Le but d'une ontologie est de définir un vocabulaire pour décrire un domaine, si possible de manière complète ; ni plus, ni moins. Contrairement aux bases de connaissances par exemple, on n'attend pas d'une ontologie qu'elle soit en mesure de fournir systématiquement une réponse à une question arbitraire sur le domaine. Une ontologie est la théorie la plus faible couvrant un domaine ; elle ne définit que les termes nécessaires pour partager la connaissance liée à ce domaine[réf. nécessaire].
Approche opérationnelle
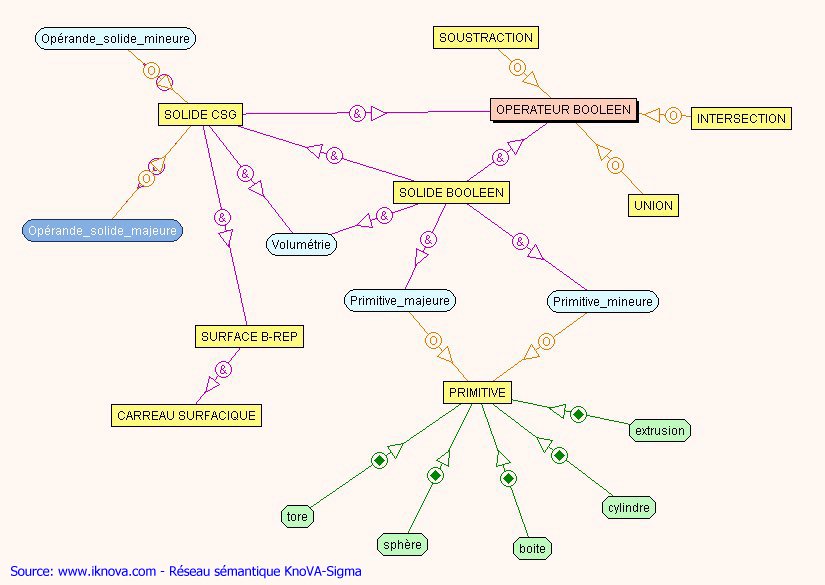
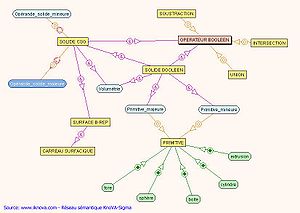 Exemple de réseau sémantique.
Exemple de réseau sémantique.
Parallèlement à cette définition assez théorique de ce que représente une ontologie, une autre définition, plus opérationnelle, peut être formulée ainsi :
- Une ontologie est un réseau sémantique qui regroupe un ensemble de concepts décrivant complètement un domaine. Ces concepts sont liés les uns aux autres par des relations taxonomiques (hiérarchisation des concepts) d'une part, et sémantiques d'autre part.
Cette définition rend possible l'écriture de langages destinés à implémenter des ontologies.
Pour construire une ontologie, on dispose d'au moins trois de ces notions :
- Détermination des agents passifs ou actifs.
- Leurs conditions fonctionnelles et contextuelles.
- Leurs transformations possibles vers des objectifs limités.
Pour modéliser une ontologie, on utilisera ces outils :
- Raffiner les vocabulaires et notions adjacentes.
- Décomposer en catégories et autres topics.
- Prédiquer afin de connaître les transformations adjacentes et d'orienter vers les objectifs internes.
- Relativiser afin d'englober des concepts.
- Similariser afin de réduire à des bases totalement distinctes.
- Instancier afin de reproduire l'ensemble d'une "branche" vers une autre ontologie.
Les ontologies en pratique
Exemple d'ontologies
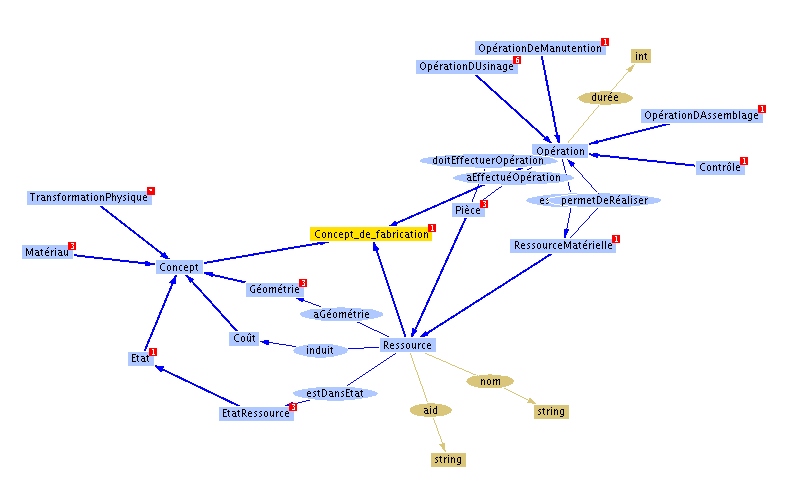
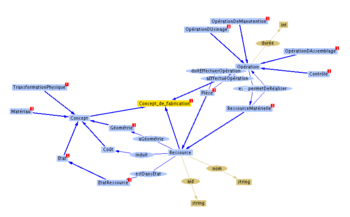 Quelques concepts et liens sémantiques d'une ontologie relative à la production manufacturière, présentés sous forme d'arbre heuristique
Quelques concepts et liens sémantiques d'une ontologie relative à la production manufacturière, présentés sous forme d'arbre heuristiquePar exemple, pour décrire les concepts entrant en jeu dans la conception de cartes électroniques, on pourrait définir l'ontologie (simplifiée ici) suivante :
- une carte électronique est un ensemble de composants,
- un composant peut être soit un condensateur, soit une résistance, soit une puce,
- une puce peut être soit une unité de mémoire, soit une unité de calcul,
.
Langages pour les ontologies
Le langage de spécification est l'élément central sur lequel repose l'ontologie.
La plupart de ces langages se basent sur la logique du premier ordre, et représentent donc les connaissances sous forme d'assertion (sujet, prédicat, objet). Parmi les formalismes les plus employés se basant sur la logique des prédicats, on retrouve des langages comme N3 ou N-Triple.
On peut aussi évoquer le langage DEF-*.
Par ailleurs, dans le cadre de ses travaux sur le Web sémantique, le W3C a mis en place en 2002 un groupe de travail dédié au développement de langages standards pour modéliser des ontologies utilisables et échangeables sur le Web. S'inspirant de langages précédents comme DAML+OIL et des fondements théoriques des logiques de description, ce groupe a publié en 2004 une recommandation définissant le langage OWL (Web Ontology Language), fondé sur le standard RDF et en spécifiant une syntaxe XML. Plus expressif que son prédecesseur RDFS, OWL a rapidement pris une place prépondérante dans le paysage des ontologies et est désormais, de facto, le standard le plus utilisé.
Bien que développé pour la représentation des vocabulaires contrôlés et structurés (thésaurus), SKOS peut être utilisé pour élaborer et gérer des ontologies légères multilingues [3].
Outils pour travailler avec les ontologies
Les éditeurs d'ontologie suivants sont gratuits et téléchargeables
- (en) Protégé est le plus connu et le plus utilisé des éditeurs d'ontologie. Open-source, développé par l'Université de Stanford, il a évolué depuis ses premières versions (Protégé-2000) pour intégrer à partir de 2003 les standards du Web sémantique et notamment OWL. Il offre de nombreux composants optionnels : raisonneurs, interfaces graphiques.
- (en) SWOOP est un éditeur d'ontologie développé par l'Université du Maryland dans le cadre du projet MINDSWAP. Contrairement à Protégé, il a été développé de façon native sur les standards RDF et OWL, qu'il prend en charge dans leurs différentes syntaxes (pas seulement XML). C'est une application plus légère que Protégé, moins évoluée en termes d'interface, mais qui intègre aussi des outils de raisonnement.
- KMgen est un éditeur d'ontologie pour le langage KM (KM: The Knowledge Machine).
Avec l'émergence du marché des technologies du Web sémantique, on peut noter l'apparition depuis 2005 d'outils logiciels proposés par des éditeurs commerciaux. On peut citer:
- SemanticWorks fait partie de la suite d'outils XML développée par Altova. Il supporte le langage OWL à travers sa syntaxe XML.
- TopBraid Composer est développé par TopQuadrant. Son interface et ses fonctionnalités ressemblent beaucoup à celles de Protégé (le développeur principal de TopBraid étant l'ancien développeur des extensions OWL de Protégé).
- Ontology Craft Workbench développé par l'équipe Condillac "Ingénierie des Connaissances" de l'Université de Savoie. Les ontologies sont disponibles aux formats XML et OWL. OCW est utilisé par la société Ontologia.
Il existe d'autre part des outils informatiques permettant de construire une ontologie à partir d'un corpus de textes. Ces outils parcourent le texte à la recherche de termes récurrents ou définis par l'utilisateur, puis analysent la manière dont ces termes sont mis en relation dans le texte (par la grammaire, et par les concepts qu'ils recouvrent et dont une définition peut être trouvée dans un lexique fourni par l'utilisateur). Le résultat est une ontologie qui représente la connaissance globale que contient le corpus de texte sur le domaine d'application qu'il couvre. Le projet WordNet (voir les liens) en est l'exemple le plus important.
Approche normative
En Europe, la norme qui fait actuellement l'objet d'une attention particulière est une norme permettant notamment de décrire les ontologies sur le patrimoine culturel immatériel (bibliothèques, musées et archives,...).
Ses références exactes sont : ISO 21127 : "ontologies nécessaires à la description des données concernant le patrimoine culturel".
Voir aussi
- Gestion des connaissances
- Métadonnée
- Ontoterminologie
- Arbre heuristique
- Analyse de concepts formels
Notes et références
- ↑ Voir Classe (mathématiques), Classe (informatique), and Classe (philosophique), chacun étant pertinent, mais non identique à la notion de "classe" ici.
- ↑ Thomas R. Gruber, Towards Principles for the Design of Ontologies Used for Knowledge Sharing in Formal Ontology in Conceptual Analysis and Knowledge Representation, Kluwer Academic Publishers, 1993
- ↑ Extraction et Gestion des Connaissances, 8èmes Journées Francophones, Sophia Antipolis, 29 janvier 2008.
Liens externes
- (en) OpenCyc est un projet qui vise à la construction d'une ontologie-mère.
- (en) WordNet est une ontologie de la langue anglaise particulièrement riche.
 Portail de l’informatique
Portail de l’informatique
Catégories : Ontologie (informatique) | Architecture logicielle
Wikimedia Foundation. 2010.