- Machine À Vecteurs De Support
-
Machine à vecteurs de support
Les machines à vecteurs de support ou séparateurs à vaste marge (en anglais Support Vector Machine, SVM) sont un ensemble de techniques d'apprentissage supervisé destinées à résoudre des problèmes de discrimination[1] et de régression. Les SVM sont une généralisation des classifieurs linéaires.
Les SVM ont été développés dans les années 1990 à partir des considérations théoriques de Vladimir Vapnik sur le développement d'une théorie statistique de l'apprentissage : la Théorie de Vapnik-Chervonenkis. Les SVM ont rapidement été adoptés pour leur capacité à travailler avec des données de grandes dimensions, le faible nombre d'hyper paramètres, le fait qu'ils soient bien fondés théoriquement, et leurs bons résultats en pratique.
Les SVM ont été appliqués à de très nombreux domaines (bio-informatique, recherche d'information, vision par ordinateur, finance...[2]). Selon les données, la performance des machines à vecteurs de support est de même ordre, ou même supérieure, à celle d'un réseau de neurones ou d'un modèle de mixture gaussienne.
Sommaire
Historique
Les séparateurs à vastes marges reposent sur deux idées clés : la notion de marge maximale et la notion de fonction noyau. Ces deux notions existaient depuis plusieurs années avant qu'elles ne soient mises en commun pour construire les SVM.
L'idée des hyperplans à marge maximale a été explorée dès 1963 par Vladimir Vapnik et A. Lerner[3], et en 1973 par Richard Duda et Peter Hart dans leur livre Pattern Classification[4]. Les fondations théoriques des SVM ont été explorés par Vapnik et ses collègues dans les années 70 avec le développement de la Théorie de Vapnik-Chervonenkis, et par Valiant et la théorie de l'apprentissage PAC[5].
L'idée des fonctions noyaux n'est pas non plus nouvelle: le théorème de Mercer date de 1909[6], et l'utilité des fonctions noyaux dans le contexte de l'apprentissage artificiel a été montré dès 1964 par Aizermann, Bravermann et Rozoener[7].
Ce n'est toutefois qu'en 1992 que ces idées seront bien comprises et rassemblées par Boser, Guyon et Vapnik dans un article, qui est l'article fondateur des séparateurs à vaste marge[8]. L'idée des variables ressorts, qui permet de résoudre certaines limitations pratiques importantes, ne sera introduite qu'en 1995. À partir de cette date, qui correspond à la publication du livre de Vapnik [9], les SVM gagnent en popularité et sont utilisés dans de nombreuses applications.
Un brevet américain sur les SVM est déposé en 1997 par les inventeurs originels[10].
Résumé intuitif
Les séparateurs à vastes marges sont des classifieurs qui reposent sur deux idées clés, qui permettent de traiter des problèmes de discrimination non-linéaire, et de reformuler le problème de classement comme un problème d'optimisation quadratique.
La première idée clé est la notion de marge maximale. La marge est la distance entre la frontière de séparation et les échantillons les plus proches. Ces derniers sont appelés vecteurs supports. Dans les SVM, la frontière de séparation est choisie comme celle qui maximise la marge. Ce choix est justifié par la théorie de Vapnik-Chervonenkis (ou théorie statistique de l'apprentissage), qui montre que la frontière de séparation de marge maximale possède la plus petite capacité[11]. Le problème est de trouver cette frontière séparatrice optimale, à partir d'un ensemble d'apprentissage. Ceci est fait en formulant le problème comme un problème d'optimisation quadratique, pour lequel il existe des algorithmes connus.
Afin de pouvoir traiter des cas où les données ne sont pas linéairement séparables, la deuxième idée clé des SVM est de transformer l'espace de représentation des données d'entrées en un espace de plus grande dimension (possiblement de dimension infinie), dans lequel il est probable qu'il existe une séparatrice linéaire. Ceci est réalisé grâce à une fonction noyau, qui doit respecter certaines conditions, et qui a l'avantage de ne pas nécessiter la connaissance explicite de la transformation à appliquer pour le changement d'espace. Les fonctions noyau permettent de transformer un produit scalaire dans un espace de grande dimension, ce qui est coûteux, en une simple évaluation ponctuelle d'une fonction. Cette technique est connue sous le nom de kernel trick.
Principe général
Les SVM peuvent être utilisés pour résoudre des problèmes de discrimination, c'est-à-dire décider à quelle classe appartient un échantillon, ou de régression, c'est-à-dire prédire la valeur numérique d'une variable. La résolution de ces deux problèmes passe par la construction d'une fonction h qui à un vecteur d'entrée x fait correspondre une sortie y :
- y = h(x)
On se limite pour l'instant à un problème de discrimination à deux classes (discrimination binaire), c'est-à-dire
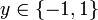 , le vecteur d'entrée x étant dans un espace X muni d'un produit scalaire. On peut prendre par exemple
, le vecteur d'entrée x étant dans un espace X muni d'un produit scalaire. On peut prendre par exemple 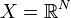 .
.Discrimination linéaire et hyperplan séparateur
Pour rappel, le cas simple est le cas d'une fonction discriminante linéaire, obtenue par combinaison linéaire du vecteur d'entrée
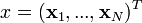 :
:- h(x) = wTx + w0
Il est alors décidé que x est de classe 1 si
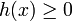 et de classe -1 sinon. C'est un classifieur linéaire.
et de classe -1 sinon. C'est un classifieur linéaire.La frontière de décision h(x) = 0 est un hyperplan, appelé hyperplan séparateur, ou séparatrice. Rappelons que le but d'un algorithme d'apprentissage supervisé est d'apprendre la fonction h(x) par le biais d'un ensemble d'apprentissage :
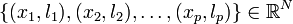 ×{ − 1,1}
×{ − 1,1}
où les lk sont les labels, p est la taille de l'ensemble d'apprentissage, N la dimension des vecteurs d'entrée. Si le problème est linéairement séparable, on doit alors avoir :
Exemple
Prenons un exemple pour bien comprendre le concept. Imaginons un plan (espace à deux dimensions) dans lequel sont répartis deux groupes de points. Ces points sont associés à un groupe : les points (+) pour y > x et les points (-) pour y < x. On peut trouver un séparateur linéaire évident dans cet exemple, la droite d'équation y=x. Le problème est dit linéairement séparable.
Pour des problèmes plus compliqués, il n'existe en général pas de séparatrice linéaire. Imaginons par exemple un plan dans lequel les points (-) sont regroupés en un cercle, avec des points (+) tout autour : aucun séparateur linéaire ne peut correctement séparer les groupes : le problème n'est pas linéairement séparable. Il n'existe pas d'hyperplan séparateur.
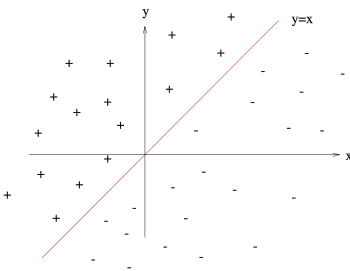 Exemple d'un problème de discrimination à deux classes, avec une séparatrice linéaire : la droite d'équation y=x. Le problème est linéairement séparable.
Exemple d'un problème de discrimination à deux classes, avec une séparatrice linéaire : la droite d'équation y=x. Le problème est linéairement séparable.
 Exemple d'un problème de discrimination à deux classes, avec une séparatrice non-linéaire : le cercle unité. Le problème n'est pas linéairement séparable.
Exemple d'un problème de discrimination à deux classes, avec une séparatrice non-linéaire : le cercle unité. Le problème n'est pas linéairement séparable.Marge maximale
On se place désormais dans le cas où le problème est linéairement séparable. Même dans ce cas simple, le choix de l'hyperplan séparateur n'est pas évident. Il existe en effet une infinité d'hyperplans séparateurs, dont les performances en apprentissage sont identiques (le risque empirique est le même), mais dont les performances en généralisation peuvent être très différentes. Pour résoudre ce problème, il a été montré[réf. nécessaire] qu'il existe un unique hyperplan optimal, défini comme l'hyperplan qui maximise la marge entre les échantillons et l'hyperplan séparateur.
Il existe des raisons théoriques à ce choix. Vapnik a montré[réf. nécessaire] que la capacité des classes d'hyperplans séparateurs diminue lorsque leur marge augmente.
 Pour un ensemble de points linéairement séparables, il existe une infinité d'hyperplans séparateurs.
Pour un ensemble de points linéairement séparables, il existe une infinité d'hyperplans séparateurs.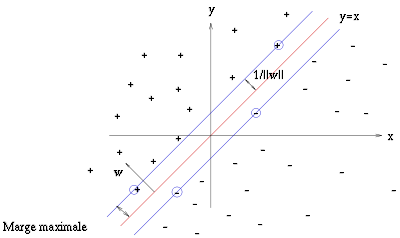 L'hyperplan optimal (en rouge) avec la marge maximale. Les échantillons entourés sont des vecteurs supports.
L'hyperplan optimal (en rouge) avec la marge maximale. Les échantillons entourés sont des vecteurs supports.La marge est la distance entre l'hyperplan et les échantillons le plus proches. Ces derniers sont appelés vecteurs supports. L'hyperplan qui maximise la marge est donné par :
Il s'agit donc de trouver w et w0 remplissant ces conditions, afin de déterminer l'équation de l'hyperplan séparateur :
- h(x) = wTx + w0 = 0
Recherche de l'hyperplan optimal
Formulation primale
La marge est la plus petite distance entre les échantillons d'apprentissage et l'hyperplan séparateur qui satisfasse la condition de séparabilité (à savoir
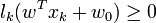 comme expliqué précédemment). La distance d'un échantillon xk à l'hyperplan est donnée par sa projection orthogonale sur l'hyperplan[12] :
comme expliqué précédemment). La distance d'un échantillon xk à l'hyperplan est donnée par sa projection orthogonale sur l'hyperplan[12] :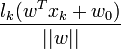 .
.
L'hyperplan séparateur (w,w0) de marge maximale est donc donné par:
Afin de faciliter l'optimisation, on choisit de normaliser w et w0, de telle manière que les échantillons à la marge (
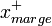 pour les vecteurs supports sur la frontière positive, et
pour les vecteurs supports sur la frontière positive, et 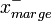 pour ceux situés sur la frontière opposée) satisfassent :
pour ceux situés sur la frontière opposée) satisfassent :D'où pour tous les échantillons,
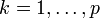
Cette normalisation est parfois appelée la forme canonique de l'hyperplan, ou hyperplan canonique[13].
Avec cette mise à l'échelle, la marge vaut désormais
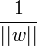 , il s'agit donc de maximiser | | w | | − 1. La formulation dite primale des SVM s'exprime alors sous la forme suivante[14] :
, il s'agit donc de maximiser | | w | | − 1. La formulation dite primale des SVM s'exprime alors sous la forme suivante[14] :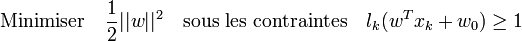
Ceci peut se résoudre par la méthode classique des Multiplicateur de Lagrange, où le lagrangien est donné par :
Le lagrangien doit être minimisé par rapport à w et w0, et maximisé par rapport à α.
Formulation duale
En annulant les dérivées partielles du lagrangien, selon les conditions de Kuhn-Tucker, on obtient :
En réinjectant ces valeurs dans l'équation (1), on obtient la formulation duale :
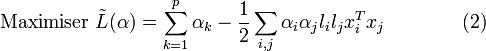
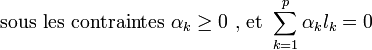
Ce qui donne les multiplicateurs de Lagrange optimaux
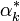 .
.Afin d'obtenir l'hyperplan solution, on remplace w par sa valeur optimale w*, dans l'équation de l'hyperplan h(x) , ce qui donne :
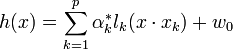
Conséquences
- Il y a trois remarques intéressantes à faire à propos de ce résultat. La première découle de l'une des conditions de Kuhn-Tucker, qui donne :
d'où
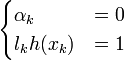 .
.
Les seuls points pour lesquels les contraintes du lagrangien sont actives sont donc les points tels que lkh(xk) = 1, qui sont les points situés sur les hyperplans de marges maximales. En d'autres termes, seuls les vecteurs supports participent à la définition de l'hyperplan optimal.
- La deuxième remarque découle de la première. Seul un sous-ensemble restreint de points est nécessaire pour le calcul de la solution, les autres échantillons ne participant pas du tout à sa définition. Ceci est donc efficace au niveau de la complexité. D'autre part, le changement ou l'agrandissement de l'ensemble d'apprentissage a moins d'influence que dans un modèle de mélanges gaussiens par exemple, où tous les points participent à la solution. En particulier, le fait d'ajouter des échantillons à l'ensemble d'apprentissage qui ne sont pas des vecteurs supports n'a aucune influence sur la solution finale.
- La dernière remarque est que l'hyperplan solution ne dépend que du produit scalaire entre le vecteur d'entrée et les vecteurs supports. Cette remarque est l'origine de la deuxième innovation majeure des SVM: le passage par un espace de redescription grâce à une fonction noyau.
Cas non séparable: Kernel trick
Principe
Exemple simple de transformation: le problème n'est pas linéairement séparable en coordonnées cartésiennes, par contre en coordonnées polaires, le problème devient linéaire. Il s'agit ici d'un exemple très simple, l'espace de redescription étant de même dimension que l'espace d'entrée.La notion de marge maximale et la procédure de recherche de l'hyperplan séparateur telles que présentées pour l'instant ne permettent de résoudre que des problèmes de discrimination linéairement séparables. C'est une limitation sévère qui condamne à ne pouvoir résoudre que des problèmes jouets, ou très particuliers. Afin de remédier au problème de l'absence de séparateur linéaire, l'idée des SVM est de reconsidérer le problème dans un espace de dimension supérieure, éventuellement de dimension infinie. Dans ce nouvel espace, il est alors probable qu'il existe une séparatrice linéaire.
Plus formellement, on applique aux vecteurs d'entrée x une transformation non-linéaire φ. L'espace d'arrivée φ(X) est appelé espace de redescription. Dans cet espace, on cherche alors l'hyperplan
- h(x) = wTφ(x) + w0
qui vérifie
- lkh(xk) > 0 , pour tous les points xk de l'ensemble d'apprentissage, c'est-à-dire l'hyperplan séparateur dans l'espace de redescription.
En utilisant la même procédure que dans le cas sans transformation, on aboutit au problème d'optimisation suivant :
Le problème de cette formulation est qu'elle implique un produit scalaire entre vecteurs dans l'espace de redescription, de dimension élevée, ce qui est couteux en termes de calculs. Pour résoudre ce problème, on utilise une astuce connue sous le nom de Kernel trick, qui consiste à utiliser une fonction noyau, qui vérifie :
d'où l'expression de l'hyperplan séparateur en fonction de la fonction noyau:
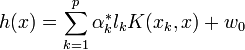
L'intérêt de la fonction noyau est double :
- Le calcul se fait dans l'espace d'origine, ceci est beaucoup moins coûteux qu'un produit scalaire en grande dimension.
- La transformation φ n'a pas besoin d'être connue explicitement, seule la fonction noyau intervient dans les calculs. On peut donc envisager des transformations complexes, et même des espaces de redescription de dimension infinie.
Choix de la fonction noyau
En pratique, on ne connait pas la transformation φ, on construit plutôt directement une fonction noyau. celle ci doit respecter certaines conditions, elle doit correspondre à un produit scalaire dans un espace de grande dimension. Le théorème de Mercer explicite les conditions que K doit satisfaire pour être une fonction noyau : elle doit être symétrique, semi-définie positive.
L'exemple le plus simple de fonction noyau est le noyau linéaire :
On se ramène donc au cas d'un classifieur linéaire, sans changement d'espace. L'approche par Kernel trick généralise ainsi l'approche linéaire. Le noyau linéaire est parfois employé pour évaluer la difficulté d'un problème.
Des noyaux usuels employés avec les SVM sont:
- le noyau polynomial
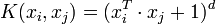
- le noyau gaussien
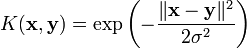
Extensions
Marge souple
En général, il n'est pas non plus possible de trouver une séparatrice linéaire dans l'espace de redescription. Il se peut aussi que des échantillons soient mal étiquetés, et que l'hyperplan séparateur ne soit pas la meilleure solution au problème de classement.
En 1995, Corinna Cortes et Vladimir Vapnik proposent une technique dite de marge souple [15], qui tolère les mauvais classements. La technique cherche un hyperplan séparateur qui minimise le nombre d'erreurs grâce à l'introduction de variables ressort ξk (slack variables en anglais), qui permettent de relacher les contraintes sur les vecteurs d'apprentissage:
Avec les contraintes précédentes, le problème d'optimisation est modifié par un terme de pénalité, qui pénalise les variables ressort élevées:
où C est une constante qui permet de contrôler le compromis entre nombre d'erreurs de classement, et la largeur de la marge. Elle doit être choisie par l'utilisateur, en général par une recherche exhaustive dans l'espace des paramètres, en utilisant par exemple la validation croisée sur l'ensemble d'apprentissage. Le choix automatique de ce paramètre de régularisation est un problème statistique majeur.
Cas multi-classe
Plusieurs méthodes ont été proposées pour étendre le schéma ci-dessus au cas où plus de deux classes sont à séparer. Ces schémas sont applicables à tout classifieur binaire, et ne sont donc pas spécifiques aux SVM[16]. Les deux plus connues sont appelées one versus all et one versus one. Formellement, les échantillons d'apprentissage et de test peuvent ici être classés dans M classes {C1,C2,...,CM}.
La méthode one-versus-all (appelée parfois one-versus-the-rest) consiste à construire M classifieurs binaires en attribuant le label 1 aux échantillons de l'une des classes et le label -1 à toutes les autres. En phase de test, le classifieur donnant la valeur de confiance (e.g la marge) la plus élevée remporte le vote.
La méthode one-versus-one consiste à construire M(M − 1) / 2 classifieurs binaires en confrontant chacune des M classes. En phase de test, l'échantillon à classer est analysé par chaque classifieur et un vote majoritaire permet de déterminer sa classe. Si l'on note xt l'échantillon à classer et hij(.) le classifieur SVM séparant la classe Ci et la classe Cj et renvoyant le label attribué à l'échantillon à classer, alors le label attribué à xt peut formellement se noter
![Card(\{h_{i,j}(x_t)\} \cap \{k\};i,j,k \in [1,M], i<j)](/pictures/frwiki/57/90e715621b0ef7844dcfe6795b4efbae.png) . C'est la classe qui sera le plus souvent attribuée à xt quand il aura été analysé par tous les hij. Il peut exister une ambiguité dans le résultat du comptage, s'il n'existe pas de vote majoritaire[17]
. C'est la classe qui sera le plus souvent attribuée à xt quand il aura été analysé par tous les hij. Il peut exister une ambiguité dans le résultat du comptage, s'il n'existe pas de vote majoritaire[17]Une généralisation de ces méthodes a été proposée en 1995[18] sous le nom d'ECOC, consistant à représenter les ensembles de classifieurs binaires comme des codes sur lesquels peuvent être appliqués les techniques de correction d'erreur.
Ces méthodes souffrent toutes de deux défauts. Dans la version one-versus-all, rien n'indique que les valeurs du résultat de classification des M classifieurs soient comparables (pas de normalisation, donc possibles problèmes d'échelle)[17]. De plus le problème n'est plus équilibré, par exemple avec M=10, on utilise seulement 10% d'exemples positifs pour 90% d'exemples négatifs.
Les SVM pour la régression
Voir aussi
- Apprentissage automatique
- Apprentissage supervisé
- Réseau de neurones
- Modèle de mélanges gaussiens
- Théorie de Vapnik-Chervonenkis
Bibliographie
- (en) Vapnik, V. Statistical Learning Theory. Wiley-Interscience, New York, (1998)
- (en) Bernhard Schölkopf, Alexander J. Smola, Learning With Kernels: Support Vector Machines, Regularization, Optimization and Beyond, 2002, MIT Press.
- (en) John Shawe-Taylor, Nello Cristianini, Support Vector Machines and other kernel-based learning methods, Cambridge University Press, 2000.
- (en) Christopher J.C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and Knowledge Discovery, 2, 121–167 (1998)
- Christopher M. Bishop, Pattern Recognition And Machine Learning, Springer, 2006 (ISBN 0-387-31073-8) [détail des éditions]
Notes et références
- ↑ Le terme anglais pour discrimination est classification, qui a un sens différent en français (se rapporte au clustering). On utilise aussi le terme classement à la place de discrimination, plus proche du terme anglais, et plus compréhensible.
- ↑ (en) Bernhard Schölkopf, Alexander J. Smola, Learning With Kernels: Support Vector Machines, Regularization, Optimization and Beyond, 2002, MIT Press.
- ↑ (en) Vladimir Vapnik et A. Lerner, Pattern Recognition using Generalized Portrait Method, Automation and Remote Control, 1963
- ↑ (en) Richard O. Duda, Peter E. Hart, Pattern classification and Scene Analysis. Wiley, 1973.
- ↑ (en) L.G. Valiant. A Theory of the Learnable, Communications of the ACM, 27(11), pp. 1134-1142, November 1984.
- ↑ (en) J. Mercer, Functions of positive and negative type and their connection with the theory of integral equations. Philos. Trans. Roy. Soc. London, A 209:415--446, 1909.
- ↑ M. Aizerman, E. Braverman, and L. Rozonoer, Theoretical foundations of the potential function method in pattern recognition learning, Automation and Remote Control 25:821--837, 1964.
- ↑ (en) Bernhard E. Boser, Isabelle M. Guyon, Vladimir N. Vapnik, A Training Algorithm for Optimal Margin Classifiers In Fifth Annual Workshop on Computational Learning Theory, pages 144--152, Pittsburgh, ACM. 1992
- ↑ V. Vapnik, "The nature of statistical learning theory", N-Y: Springer-Verlag, 1995.
- ↑ (en)Pattern recognition system using support vectors. B. Boser, I. Guyon, and V. Vapnik, US Patent 5,649,068 1997
- ↑ (en) Marti A. Hearst, Support Vector Machines, IEEE Intelligent Systems, vol. 13, no. 4, pp. 18-28, Jul/Aug, 1998
- ↑ Pour un hyperplan d'équation wTxk + w0 = 0, la distance de tout point a de l'espace à l'hyperplan est
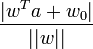
- ↑ (en) Bernhard Schölkopf, Alexander J. Smola, Learning With Kernels: Support Vector Machines, Regularization, Optimization and Beyond, 2002, MIT Press, p.190
- ↑ Maximiser | | w | | − 1 est équivalent à minimiser | | w | | 2. Le carré est pris pour se débarrasser de la racine carrée incluse dans la norme. Le 1/2 n'est présent que pour faciliter la lisibilité des calculs et du résultat de l'optimisation.
- ↑ Corinna Cortes and V. Vapnik, "Support-Vector Networks, Machine Learning, 20, 1995. http://www.springerlink.com/content/k238jx04hm87j80g/
- ↑ Christopher M. Bishop, Pattern Recognition And Machine Learning, Springer, 2006 (ISBN 0-387-31073-8) [détail des éditions], p.182-184
- ↑ a et b Christopher M. Bishop, Pattern Recognition And Machine Learning, Springer, 2006 (ISBN 0-387-31073-8) [détail des éditions], p.338-339
- ↑ Dietterich, T.G. and Bakiri, G., Solving multiclass learning problems via error-correcting output codes. Journal of Artificial Intelligence Research. v2. 263-286.
Liens externes
- (en) Introduction aux SVM
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de l’informatique
Portail de l’informatique
Catégories : Informatique théorique | Apprentissage automatique | Algorithme de classification
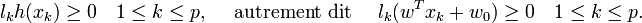




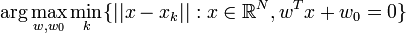
![\arg \max_{w,w_0} \left \{ \frac{1}{||w||} \min_k \left [ l_k(w^Tx_k+w_0) \right ] \right \}](/pictures/frwiki/99/ceae17185779e88122e69261dabaa722.png)
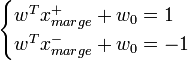
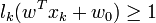
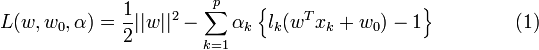
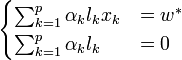
![\alpha_k [ l_k h(x_k)-1 ] = 0 \quad 1 \le k \le p.](/pictures/frwiki/50/2f3e83931bdf6f835ba79bcc98c0b9e6.png)
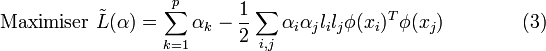
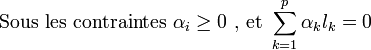
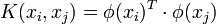
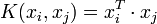
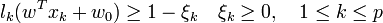
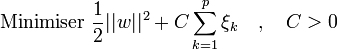
Wikimedia Foundation. 2010.