- Modele de melanges gaussiens
-
Modèle de mélanges gaussiens
Dans les modèles de mélanges, fréquemment utilisées en classification automatique, on considère qu'un échantillon de données suit, non pas une loi de probabilité usuelle, mais une loi dont la fonction de densité est une densité mélange.
Bien que n'importe quelle loi puisse être utilisée, la plus courante est la loi normale dont la fonction de densité est une gaussienne. On parle alors de mélange gaussien.
Sommaire
Utilisation en classification automatique
Le problème classique de la classification automatique est de considérer qu'un échantillon de données provienne d'un nombre de groupes inconnus a priori qu'il faut retrouver. Lorsqu'on part du postulat que ces groupes suivent une loi de probabilité (quelconque), alors on se place nécessairement dans le cadre des modèles de mélanges. Si en plus, on considère que les lois que suivent les individus sont normales, alors on se place dans le cadre des modèles de mélanges gaussiens.
Par la suite, on notera
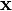 un échantillon composé de n individus
un échantillon composé de n individus 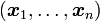 appartenant à
appartenant à 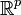 (i.e. caractérisés par p variables continues). Dans le cadre des modèles de mélanges, on considère que ces individus appartiennent chacun à un des g (g étant fixé a priori)
(i.e. caractérisés par p variables continues). Dans le cadre des modèles de mélanges, on considère que ces individus appartiennent chacun à un des g (g étant fixé a priori) 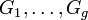 suivant chacun une loi normale de moyenne
suivant chacun une loi normale de moyenne 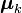
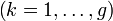 et de matrice de variance-covariance
et de matrice de variance-covariance 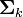 . D'autre part, en notant
. D'autre part, en notant 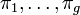 les proportions des différents groupes,
les proportions des différents groupes, 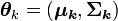 le paramètre de chaque loi normale et
le paramètre de chaque loi normale et 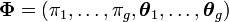 le paramètre global du mélange, la loi mélange que suit l'échantillon peut s'écrire
le paramètre global du mélange, la loi mélange que suit l'échantillon peut s'écrireavec
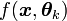 la loi normale multidimensionnelle paramétrée par
la loi normale multidimensionnelle paramétrée par 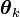 .
.La principale difficulté de cette approche consiste à déterminer le meilleur paramètre
 . Pour cela, on cherche habituellement le paramètre qui maximise la vraisemblance, donnée dans ce cas, par
. Pour cela, on cherche habituellement le paramètre qui maximise la vraisemblance, donnée dans ce cas, par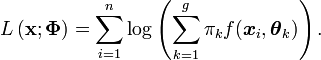
Bien que ce problème puisse sembler particulièrement hardu, l'algorithme EM permet de lever cette difficulté.
Une fois l'estimation effectuée, il s'agit d'attribuer à chaque individu la classe à laquelle il appartient le plus probablement. Pour cela, on utilise la règle d'inversion de Bayes. D'après celle-ci, on a
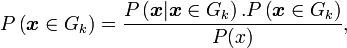
ce qui se traduit, dans notre cas, par
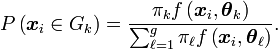
Il suffit alors d'attribuer chaque individu
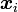 à la classe pour laquelle la probabilité a posteriori
à la classe pour laquelle la probabilité a posteriori 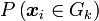 est la plus grande.
est la plus grande.Modèles parcimonieux
Un problème qu'on peut rencontrer lors de la mise en œuvre des modèles de mélange concerne la taille du vecteur de paramètres à estimer. Dans le cas d'un mélange gaussien de g composantes de dimension p le paramètre est de dimension k(1 + p + p2) − 1. La quantité de données nécessaire à une estimation fiable peut alors être trop importante par rapport au coût de leur recueil.
Une solution couramment employée est de déterminer quelles sont, parmi toutes les variables disponibles, celles qui apporteront le plus d'information à l'analyse et d'éliminer les variables ne présentant que peu d'intérêt. Cette technique, très employée dans des problèmes de discrimination l'est moins dans les problèmes de classification.
Une méthode alternative consiste à considérer des modèles dits parcimonieux dans lesquels on contraint le modèle initial de manière à n'estimer qu'un nombre plus restreint de paramètres. Dans le cas gaussien, la paramétrisation synthétique des lois de probabilités grâce à deux ensembles
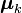 et
et 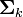 de paramètres permet des ajouts de contraintes relativement simples. Le plus souvent, ces contraintes ont une signification géométrique en termes de volumes, d'orientation et de forme.
de paramètres permet des ajouts de contraintes relativement simples. Le plus souvent, ces contraintes ont une signification géométrique en termes de volumes, d'orientation et de forme.En notant Bk la matrice des valeurs propres de
et Dk la matrice de ses vecteurs propres, on peut noter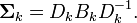
D'autre part, Bk peut également être décomposée en Bk = λkAk où λk est un réel et Ak une matrice dont le déterminant vaut 1. En utilisant ces notations, on peut considérer que λk représente le volume de la classe, la matrice Ak représente sa forme et Dk son orientation.
Il est alors possible d'ajouter des hypothèses sur formes, des volumes ou les orientations des classes :
- Formes quelconques : En fixant des contraintes d'égalité entre les Ak, les Dk ou les λk, on peut générer 8 modèles différents. On peut par exemple considérer des volumes et des formes identiques mais orientées différemment, ou encore des formes et orientations identiques avec des volumes différents, etc.
- Formes diagonales : En considérant que les matrices Dk sont diagonales, on oblige les classes à être alignées sur les axes. Il s'agit en fait de l'hypothèse d'indépendance conditionnelle dans laquelle les variables sont indépendantes entre elles à l'intérieur d'une même classe.
- Formes sphériques : En fixant Ak = I, on se place dans le cas ou les classes sont de formes sphériques, c’est-à-dire que les variances de toutes les variables sont égales à l'intérieur d'une même classe.
Liens externes
- (fr) mixmod traite de problèmes de classification, analyse discriminante (et estimation de densité) par la méthode des mélanges gaussien à l'aide de l'algorithme espérance-maximisation (EM)
Voir aussi
- Réseaux de neurones
- Machines à vecteurs de support
- Modèle de Markov caché
- Modèles de régression multiple postulés et non postulés
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques Portail de l’informatique
Portail de l’informatique
Catégories : Optimisation | Algorithmique | Loi de probabilité | Apprentissage automatique
Wikimedia Foundation. 2010.