- Ⲋ
-
Alphabet copte
 Pour les articles homonymes, voir Copte (homonymie).
Pour les articles homonymes, voir Copte (homonymie).Copte 
Lettres de l'alphabet copteCaractéristiques Type Alphabet Langue(s) Copte Historique Époque vers 300 av. J.-C. - XIVe siècle (usage rare de nos jours) Système(s)
parent(s)Phénicien et hiéroglyphes
Grec et démotique
CopteSystème(s)
apparenté(s)Cyrillique, latin, arménien, ancien nubien Encodage Unicode U+2C80 à U+2CFF
U+03E2 à U+03EFISO 15924 Copt L'alphabet copte est l'alphabet utilisé pour écrire la langue copte. Cette langue est l'héritière moderne de l'égyptien, écrit auparavant avec les hiéroglyphes, qui a cessé d'être une langue vivante au Xe siècle de l'ère chrétienne mais continue d'être utilisée comme langue liturgique de l'Église copte orthodoxe. L'alphabet copte est donc maintenant une écriture « sacrée ».
Sommaire
- 1 Histoire
- 2 Lettres
- 3 Sens de lecture
- 4 Codage informatique
- 5 Divers
- 6 Annexes
Histoire
L'écriture hiéroglyphique antique a cédé la place, pour écrire la langue copte, à un alphabet dérivé du grec, dont les lettres ont été empruntées vers la fin du Ier siècle de l'ère chrétienne. La mère de cet alphabet est donc le grec oncial. La langue copte différant de la langue grecque en termes de phonèmes, il a fallu compléter l'alphabet de vingt-quatre lettres par sept signes supplémentaires, qui ont été empruntés à la démotique, écriture d'origine hiéroglyphique qui a précédé l'alphabet copte et a cessé d'être utilisée pendant le Ve siècle. Inversement, certaines lettres grecques se sont avérées inutiles mais ont été conservées pour la notation de terme empruntés au grec biblique.
L'alphabet copte est aujourd'hui réservé aux textes chrétiens. Cependant, il servait à ses débuts pour des écrits au contenu varié, comme des textes « magiques ». Pour W. V. Davies (cf. bibliographie), l'importation de lettres grecques dans cette langue ─ qui pouvait utiliser une écriture ancestrale mais phonétiquement imprécise ─ s'expliquerait par la nécessité de représenter le plus fidèlement possible les sons des formules magiques. L'alphabet dans ses versions les plus anciennes n'est pas normalisé et contient, selon les lieux et les dialectes, de nombreuses lettres issues de la démotique qui n'ont pas été conservées dans la version définitive, laquelle est bien attestée à partir du IVe siècle. Au cours des siècles, les documents religieux ont pris le pas sur les écrits profanes, parmi lesquels on pouvait trouver lettres, correspondance commerciale et textes de lois.
Fait notable, l'alphabet nubien dérive de l'alphabet copte bien que les langues n'aient aucun lien entre elles.
Lettres
Note : toutes les transcriptions phonétiques suivent les usages de l'API.
Liste des graphèmes
Les lettres sont données pour l'alphabet bohaïrique.
Les lettres sont aussi utilisées ─ à partir du bohaïrique ─, comme en grec, en tant que nombres (d'où la présence dans l'alphabet d'un signe non littéral et purement numéral, soou, issu du digamma grec, et d'une ligature abréviative, le rō barré valant 900, en remplacement du sampi grec) ; consulter numération copte pour plus de détails. Le sa'idique semble ignorer une telle pratique et note les nombres au long.
Image Majuscule Minuscule Valeur numérique Nom Translittération Prononciation 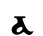
Ⲁ ⲁ 1 alpʰa a [a, ʕ, ʔ] 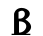
Ⲃ ⲃ 2 bēta b [b, v, w] 
Ⲅ ⲅ 3 gamma g [k] / [g, ŋ, ɣ] 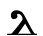
Ⲇ ⲇ 4 dalda d [d] / [d, ð] 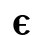
Ⲉ ⲉ 5 ei [e] 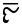
Ⲋ ⲋ 6 sou — — 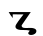
Ⲍ ⲍ 7 zēta z [s] / [z] 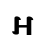
Ⲏ ⲏ 8 ēta ē [eː] / [ɛː, i] 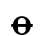
Ⲑ ⲑ 9 tʰēta tʰ [tʰ] / [tʰ, θ] 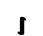
Ⲓ ⲓ 10 iōta i [i, j] 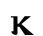
Ⲕ ⲕ 20 kappa k [k] 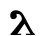
Ⲗ ⲗ 30 laula l [l] 
Ⲙ ⲙ 40 mē m [m] 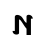
Ⲛ ⲛ 50 nē n [n] 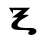
Ⲝ ⲝ 60 kˢi kˢ [ks] 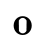
Ⲟ ⲟ 70 ou o [o] 
Ⲡ ⲡ 80 pi p [p] 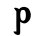
Ⲣ ⲣ 100 rō r [r] 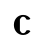
Ⲥ ⲥ 200 sēmma s [s] 
Ⲧ ⲧ 300 tau t [t] / [t, d] 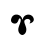
Ⲩ ⲩ 400 he u [u, w] / [u, w, i, v] 
Ⲫ ⲫ 500 pʰi pʰ [pʰ] / [pʰ, f] 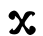
Ⲭ ⲭ 600 kʰi kʰ [kʰ] / [kʰ, χ, ʃ] 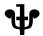
Ⲯ ⲯ 700 pˢi pˢ [ps] 
Ⲱ ⲱ 800 ō ō [oː] 
Ϣ ϣ šai š [ʃ] 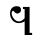
Ϥ ϥ 90 fai [f] 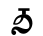
Ϧ ϧ ḫai ḫ [x] 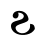
Ϩ ϩ hori h [h] 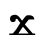
Ϫ ϫ ḏanḏia ḏ [ʤ] / [ʤ, g] 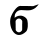
Ϭ ϭ čima č [q] / [ʧ] 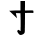
Ϯ ϯ ti ti [ti] 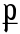
Ⳁ ⳁ 900 pˢis ənše — — Origine
Les premières lettres de l'alphabet copte possèdent un étymon grec oncial évident. On notera la présence du sigma lunaire.
Grec Copte Nom Image Nom Image Alpha 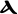
alpʰa Bêta 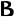
bēta Gamma 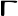
gamma Delta 
dalda Epsilon 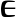
ei Zêta 
zēta Êta 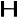
ēta Thêta 
tʰēta Iota 
iōta Kappa 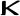
kappa Lambda 
laula Mu 
mē Nu 
nē Xi 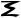
kˢi Omicron 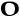
ou Pi 
pi Rhô 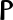
rō Sigma 
sēmma Tau 
tau Upsilon 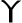
he Phi 
pʰi Chi 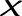
kʰi Psi 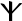
pˢi Oméga 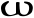
ō Les sept dernières lettres de l'alphabet ne sont pas d'origine grecque mais furent empruntées à la démotique égyptienne. Elles permettent de noter des sons pour lesquels l'alphabet grec ne possède pas d'équivalents. Leur origine est bien connue : on peut en effet remonter des hiéroglyphes jusqu'à la lettre copte en passant par le tracé démotique des hiéroglyphes :
Hiéroglyphe Démotique Copte Valeur Image Valeur Image Nom Image SA 
š 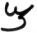
šai F 
f 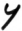
fai 
ḫ 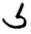
ḫai 

h 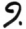
hori 
ḏ 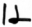
ḏanḏia K 
č 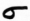
čima TI 

ti 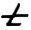
ti Capitales
L'alphabet copte peut être considéré bicaméral : chaque lettre possède une majuscule et une minuscule. Dans les faits, sauf dans certains styles particulièrement ornés, les capitales ne sont rien d'autre que des minuscules de grand format et elles ne nécessitent pas un apprentissage séparé. Il n'y a là rien de comparable au cas du grec actuel, dont la minuscule de Ν est ν, par exemple. La lettre ḫai est vraisemblablement la seule dont les deux variantes sont différentes quel que soit le style : Ϧ en capitale, ϧ en minuscule.
Nom des lettres
On a retenu dans ce tableau l'un des nombreux noms possibles pour chaque lettre, ceux donnés grosso modo par la grammaire de Plumley (cf. bibliographie). On peut considérer que ce sont les noms anciens.
Les noms des lettres ne sont en effet pas réellement normalisés et l'on trouve dans ce domaine d'importantes variations selon les textes, minimes (la lettre fai peut être nommée fei) ou plus notables (he est souvent désignée par le nom epˢilon dans les textes récents). L'hellénisation de la prononciation (voir plus bas) a bien sûr joué un rôle non négligeable, de même que des contraintes liées à la langue copte elle-même : l'apparition d'une voyelle épenthétique en début de mot dans une syllabe qui débuterait sinon par deux consonnes est visible dans des cas comme kˢi souvent nommé ekˢi.
Translittération et codage
À partir de maintenant, les mots codés en alphabet grec en italique sont à lire comme s'ils étaient écrits en copte. En effet, Unicode ne distingue pas encore les deux blocs de caractères (voir plus bas). Les mots écrits en grec en romaine (contraire de l'italique) doivent bien être compris comme du grec. Il serait en 2008 possible de coder toute la page en copte (consulter la section « Codage informatique »).
Pour des raisons de simplicité, on a choisi de représenter le sēmma (sigma grec) par la lettre latine c : en effet, le copte ayant emprunté le sigma lunaire grec, il ne connaît pas de variante finale ς. Écrire σ en fin de mot serait trop dérangeant pour l'œil habitué à lire le grec. Il est aussi plus prudent de coder le sigma lunaire par un c plutôt que par le caractère grec prévu par Unicode (ϲ U+03F2), qui n'est pas toujours présent dans les polices de caractères courantes.
On a choisi une translittération et non une transcription pour les mots coptes. Cette translittération est bijective : à chaque symbole ou digramme symbolique choisi ne peut correspondre qu'une seule lettre copte et inversement, d'où la notation des consonnes aspirées par un ʰ. Ainsi, pʰ (φ) ne peut être confondu avec la suite de lettres ph (πϩ). ḏ peut facilement être remplacé par j. La présence d'un ḏinkim (voir plus bas) est indiquée par un ə en exposant : ρ̄ est translittéré ər.
Valeur des lettres
Les différentes sources consultées donnent pour certaines lettres des valeurs très différentes, selon qu'on se place dans une optique historique (le copte tel qu'il a été parlé dans le passé ; encore faut-il savoir de quel dialecte l'on parle) ou actuelle (tel qu'il est maintenant prononcé lors des cérémonies religieuses). De plus, il faut distinguer la prononciation sa'idique (dialecte maintenant éteint) de la bohaïrique (seul dialecte encore « vivant »). Les textes récents consacrés au copte insistent généralement plus sur la prononciation bohaïrique liturgique actuelle. Deux ouvrages, cependant, s'appuient surtout sur la prononciation ancienne : l'article de Ritner et la grammaire de Plumley (cf. bibliographie).
D'autre part, selon Emile Maher Ishak (cf. bibliographie), la prononciation bohaïrique de la langue copte aurait été rapprochée artificiellement de celle du grec moderne au milieu du XIXe siècle, afin de permettre une fusion entre l'église orthodoxe grecque et l'église copte orthodoxe d'Égypte, fusion qui ne s'est finalement pas faite. Ce mouvement d'hellénisation, placé sous l'égide du pope Cyrille IV et d'Arian Girgis Moftah, enseignant de copte liturgique, a cependant été globalement et graduellement accepté : actuellement, sauf dans de rares églises, le copte est lu « à la grecque ». Cette prononciation est pourtant réputée factice et artificielle (d'autant plus qu'elle ne s'applique pas forcément à tous les mots : pour ne pas trop contrevenir aux usages établis, les noms propres, par exemple, sont souvent prononcés « à l'ancienne »). On considère alors qu'appartient au « vieux bohaïrique » une prononciation plus hypothétique restituée et datant d'avant l'hellénisation, prononciation parfois ─ à tort ou à raison ─ désignée comme étant celle du sa'idique.
Dans le tableau ci-dessus, on a indiqué en première valeur celle probable du sa'idique (ou du « vieux bohaïrique »), restituée à partir de l'égyptien ancien, des pratiques scripturales anciennes et de la valeur des lettres grecques à l'époque de l'emprunt de l'alphabet. La deuxième valeur est celle du bohaïrique hellénisé actuel. On décrira ci-dessous ces deux systèmes.
Consonnes aspirées et consonnes doubles
Prononciation ancienne / sa'idique
Les consonnes apirées grecques ont été utilisées au départ comme des raccourcis permettant de noter une consonne occlusive suivie de /h/. Ainsi, θ correspondait à la suite de consonnes τϩ, soit /th/. De telles lettres transcrivaient alors deux consonnes et non une seule (en grec ancien, θ valait /tʰ/). On trouve par exemple les graphies équivalentes θε ou τϩε /the/ (et non /tʰe/ puisque les consonnes aspirées n'existent pas en copte) pour le mot « chemin ». L'utilisation de ces lettres, en sa'idique, est bien plus limitée qu'en bohaïrique (elle se cantonne la plupart du temps aux mots d'origine grecque quand elles ne servent pas de raccourci, c'est-à-dire de lettre doubles), de même pour φ et χ, qui peuvent remplacer πϩ et κϩ.
Le cas est similaire avec les deux consonnes doubles grecques ξ et ψ, qui, dans les textes anciens, servent parfois de raccourci à κc et πc, sans pour autant que l'usage soit obligatoire (au contraire du grec). Par exemple, le nombre 9 peut s'épeler πcιc ou ψιc.
Prononciation hellénisée
Actuellement, dans la prononciation bohaïrique hellénisée les consonnes aspirées se prononcent soit comme des simples (θ vaut donc τ, φ se lit π et χ comme κ) soit d'une manière similaire à la prononciation du grec moderne (mais adaptée à une population majoritairement arabophone).
- θ : après c, τ, υ, et ϣ → /t/, sinon → /θ/ ;
- φ : dans un nom propre → /f/, sinon → /v/ ;
- χ : dans un mot copte → /k/, sinon (principalement dans des mots grecs) → /x/ après α, ο et ω, /ʃ/ après ε, η, ι et υ (par imitation du grec [ç]).
L'utilisation des aspirées ainsi que des consonnes doubles (dont la prononciation ne soulève aucun problème) est plus fréquente en bohaïrique que dans les textes plus anciens.
Occlusives sonores et zēta
Prononciation ancienne / sa'idique
Les lettres grecques γ, δ et ζ, prononcées /g/, /d/ et /zː/ en grec ancien, font partie de celles dont le copte aurait pu faire l'économie puisque les sons en question ne sont pas des phonèmes du copte ancien (alors que le β grec, déjà passé à /v/ à l'époque médiévale, s'avérait utile). Dans les textes anciens, on note une grande propension à la confusion avec des sourdes plus ou moins équivalentes : ainsi, γ alterne avec κ ou ϭ (qui, en sa'idique, ne vaut pas /ʧ/ mais vraisemblablement /q/), δ avec ϯ, ζ avec c.
En règle générale, ces consonnes sont utilisées principalement (mais pas exclusivement) dans des mots d'emprunt au grec.
Prononciation hellénisée
Celle du bohaïrique actuel est très éloignée de la prononciation ancienne. Ces lettres apparaissent aussi surtout dans des mots d'emprunt au grec :
- β : à la fin d'un mot ou dans un nom propre → /b/ ; sinon → /v/ ;
- γ : devant ε, ι, η et υ → /g/ ; devant γ et χ → /ŋ/ (comme en grec depuis l'Antiquité) ; sinon → /ɣ/ ;
- δ : dans un nom propre → /d/ ; sinon → /ð/.
Voyelles
Noter que l'on entend ici voyelle au sens de « voyelle graphique » et non phonologique : en effet, les voyelles du copte peuvent aussi servir à noter des consonnes.
Prononciation ancienne / sa'idique
Il semble que la quantité vocalique (différence entre voyelles brèves et voyelles longues) soit pertinente en copte ancien. La langue connaît trois timbres phonologiques fondamentaux, /a/, /e/ et /o/. Ceux-ci sont notés par α /a/, ε /e/ et ο /o/ pour les brèves, ι /i/ (ou η /eː/), η /ē/ et ω /oː/ (ou ου /uː/) pour les longues : les timbres ne correspondent donc pas exactement (à cause vraisemblablement d'une apophonie) et il ne semble pas que ι soit forcément une voyelle longue.
La voyelle /uː/ ainsi que la consonne /w/ sont régulièrement écrites grâce au digramme ου, la lettre υ seule étant réservée aux mots grecs ou comme second élément de diphtongue. Par exemple, νουτε /nuːte/, « dieu » et ουααβ /waab/, « saint ». La voyelle /i/ et la consonne /j/ sont écrites différemment : ι sert pour la voyelle, ει pour la consonne en début de syllabe (parfois ϊ, forme plus commune en bohaïrique), ϊ en fin de syllabe. Ainsi : ψιc /psis/, « 9 », ειωϩε (plus rare : ϊωϩε) /joːhe/ « champ », ηϊ /eːj/, « maison ».
Prononciation hellénisée
Autres détails
- les lettres π et τ sont, à la manière grecque, susceptible d'être voisées après μ ou ν → /b/ et /d/ ;
- la lettre ϫ se comporte comme un g français : il se prononce « doux » devant ε, η, ι et υ → /ʤ/ (parfois réalisé [ʒ]), « dur » ailleurs → /g/.
Diacritiques
Ḏinkim
Ce signe (plus souvent transcrit jinkim), très fréquent, indique que la consonne sonante qui le porte est vocalisée. Dans la pratique, on la prononce avec un schwa [ə] ou un [e] léger (représenté ici par ə dans la translittération). Le ḏinkim se trace différemment selon les dialectes : en sa'idique, c'est un macron, un accent grave en akhmimique et fayoumique, un accent grave ou un point suscrit en bohaïrique. Actuellement, c'est le macron qui semble préféré dans les éditions récentes.
Ponctuation
Autres signes
Ḫai
Le phonème /x/ ne se rencontre pas en sa'idique. La lettre ḫai n'y est donc pas utilisée. La forme usuelle,
, est propre au bohaïrique. On la trace en akminmique 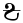 ; cette seconde graphie ne provient pas de la démotique mais d'un hori, barré.
; cette seconde graphie ne provient pas de la démotique mais d'un hori, barré.Soou
Cette « lettre »,
, n'est utilisée que dans la numération (avec la valeur 6), ce qui explique qu'on l'ait représentée ici avec sa barre suscrite. Elle remonte clairement au digamma grec dans sa graphie ancienne, Ϝ, lettre qui, déjà en grec, n'avait plus de valeur littérale (sauf quand elle a été confondue avec un stigma).Abréviations et ligatures
À l'instar du grec, qu'il a copié, le copte a développé nombre de ligatures et de signes d'abréviation. Les plus notables sont les caractères composés et la ligature abréviative suivants :
Signe 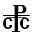
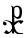 et
et 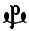
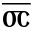
Se lit... cταυροc
staurosχρονοc μαρτυρων
kʰronos marturōnψιc ν̄ϣε
pˢis ənšeϭωιc
čōisSens « croix » « temps des martyrs » (ère de Dioclétien) 900 « Seigneur » - n'est utilisé que comme signe numérique et correspondrait au sampi grec ;
- cταυροc et χρονοc μαρτυρων sont des mots empruntés au grec ;
- est une ligature abréviative de ϭ et c (noter le trait de surlignement, la barre indiquant une contraction).
Les autres abréviations concernent surtout les noms propres bibliques grecs et sémitiques : ils sont contractés et représentés par deux ou trois lettres du mot, lettres qui sont la plupart du temps surlignées. Ainsi, χ̅c̅ représente Χριcτοc, Christ. Les usages sont semblables à ceux suivis dans les manuscrits grecs.
Signes didactiques

Le signe ci-contre, un double trait d'union, sert, dans les ouvrages didactiques, à indiquer qu'un mot est à l'état pronominal (suivi d'un suffixe pronominal). C'est le trait d'union simple qui sert à indiquer l'état construit du verbe ou de la préposition (lorsque la forme est suivie d'un complément nominal). La forme absolue, le cas échéant, est présentée sans trait d'union. Quand la typographie éditoriale s'adapte au style des lettres coptes, ce double trait d'union prend des allures plus penchées. Dans les faits, il est possible de le remplacer par le signe = (ce qu'on fera ici). Unicode prévoit de lui consacrer un emplacement.
On peut ainsi, dans les grammaires et les dictionnaires, savoir que telle préposition ou tel verbe doit être suivi d'un complément nominal, que telle autre forme doit être suivie d'un suffixe personnel :
- κοτ= kot= « construire » → état pronominal (exemple : κοτ=ϥ̄ kot=əf « le construire », comme dans « il faut le construire ») ;
- κετ- ket- : « construire » → état construit (comme dans κετ-πηϊ ket-pēï, « construire [une] maison »).
Dans un dictionnaire, on pourrait trouver les indications suivantes :
- ε- e-, ερο= ero=, préposition, « pour ».
Il faudrait alors comprendre que la préposition signifiant « pour, à » a la forme ε e quand elle a pour régime un nom, la forme ερο ero quand c'est un suffixe personnel : επηϊ epēï « à la maison », εροϥ erof « pour lui ».
Ces usages sont identiques à ceux qu'on trouve en égyptologie.
Article connexe : Transcription des hiéroglyphes.Sens de lecture
Fait notable, alors que la démotique se lisait de droite à gauche, le copte, par imitation du grec, se lit exclusivement de gauche à droite.
Codage informatique
Unicode, jusque sa version 4.1, n'a pas distingué les lettres grecques des lettres coptes, considérant que le copte n'était qu'une variante graphique et « stylistique » du grec. Plusieurs demandes ont été déposées pour que les deux graphies soient séparées (« désunifiées ») et plusieurs propositions retenues. L'alphabet copte est désormais intégré à Unicode (bloc U+2C80..U+2CFF)
Les lettres démotiques situées dans le bloc « Grec et copte » ne pouvant pas être déplacées, les lettres du copte sont donc codées sur deux blocs :
Lettres démotiques du bloc bloc « Grec et copte »
0123456789ABCDEF037 ʹ͵ͺͻͼͽ;038 ΄΅Ά·ΈΉΊΌΎΏ039 ΐΑΒΓΔΕΖΗΘΙΚΛΜΝΞΟ03A ΠΡΣΤΥΦΧΨΩΪΫάΪΫί03B ΰαβγδεζηθικλμνξο03C πρςστυφχψωϊϋόϊϋ03D ϐϑϒϓϔϕϖϗϘϙϚϛϜϝϞϟ03E ϠϡϢϣϤϥϦϧϨϩϪϫϬϭϮϯ03F ϰϱϲϳϴϵ϶ϷϸϹϺϻϼϽϾϿLettres grecques en tracé copte dans le bloc « Copte »
0123456789ABCDEF2C8 ⲀⲁⲂⲃⲄⲅⲆⲇⲈⲉⲊⲋⲌⲍⲎⲏ2C9 ⲐⲑⲒⲓⲔⲕⲖⲗⲘⲙⲚⲛⲜⲝⲞⲟ2CA ⲠⲡⲢⲣⲤⲥⲦⲧⲨⲩⲪⲫⲬⲭⲮⲯ2CB ⲰⲱⲲⲳⲴⲵⲶⲷⲸⲹⲺⲻⲼⲽⲾⲿ2CC ⳀⳁⳂⳃⳄⳅⳆⳇⳈⳉⳊⳋⳌⳍⳎⳏ2CD ⳐⳑⳒⳓⳔⳕⳖⳗⳘⳙⳚⳛⳜⳝⳞⳟ2CE ⳠⳡⳢⳣⳤ⳥⳦⳧⳨⳩⳪2CF ⳹⳺⳻⳼⳽⳾⳿Divers
- code ISO 15924 : Copt
Annexes
Bibliographie
- Charles Higounet, L'écriture, Presses universitaires de France, coll. « Que sais-je ? no 653 » (réimpr. 11e édition de 2003) ;
- The World's Writing Systems, article « The Coptic Alphabet » de R. K. Ritner, Oxford University Press, Oxford, 1996 ;
- Reading the Past, article « Egyptian Hieroglyphs » de W. V. Davies, British Museum Press, Londres, 1990 ;
- Emile Maher Ishak, The Phonetics and Phonology of the Bohairic Dialect of Coptic, Oxford University Press, Oxford, 1975 ;
- Charles Fossey, Notices sur les caractères étrangers anciens et modernes rédigées par un groupe de savants, presses de l'Imprimerie nationale, Paris, 1948 ;
- J. M. Plumley, [consultable An Introductory Coptic Grammar (Sahidic Dialect)], Home & van Thal, Londres, 1948 ;
- W. E. Crum, [consultable A Coptic Dictionary], Clarendon Press, Oxford, 1939 ;
- Rodolphe Kasser, Compléments au Dictionnaire copte de Crum, Institut français d'archéologie orientale, Le Caire, 1964 ;
- Reichsdruckerei, Alphabete und Schrifzeichen des Morgen- un Abendlandes, zum allgemeinen Gebrauch mit besonderer Berücksichtigung des Buchwerbes, Berlin, 1924 ;
- Jean-François Champollion, Grammaire égyptienne, fac simile de l'édition originale éditée entre 1836 et 1841 par Firmin Didot, éditions Solin, Acte Sud, 1997 ;
- Jean-François Champollion, [consultable Dictionnaire égyptien en écriture hiéroglyphique], Firmin-Didot Frères, Paris, 1841-1843).
Articles connexes
- Langue copte ;
- numération copte ;
- alphabet grec.
Liens externes
- [pdf] Le copte dans Unicode 4.1
- (en) à propos de la prononciation hellénisée du copte
- (en) Apprendre le copte
- Typographies coptes ; Création et distribution de polices de caractères coptes Unicode par Laurent Bourcellier & Jonathan Perez, typographes ;
- Création d'une typographie copte à usage éditorial ; Mémoire sur l'analyse des écritures coptes tracées, gravées et numérisées. [pdf]
Catégories : Langue copte | Alphabet

Wikimedia Foundation. 2010.