- Échantillonnage d'importance
-
Échantillonnage préférentiel
L'échantillonnage préférentiel, en anglais importance sampling, est une méthode de réduction de la variance qui peut être utilisée dans la méthode de Monte-Carlo. L'idée sous-jacente à l'échantillonnage préférentiel, EP dans la suite, est que certaines valeurs prises par une variable aléatoire dans une simulation ont plus d'impact que d'autres sur l'estimateur recherché. Si ces valeurs importantes se réalisent plus souvent, la variance de notre estimateur peut être réduite. Par conséquent la méthodologie de l'EP est de choisir une distribution qui « encourage » les valeurs importantes. L'utilisation d'une distribution biaisée conduira à un estimateur biaisé si nous l'appliquons directement aux simulations. Cependant, les différentes simulations sont pondérées afin de corriger ce biais, l'estimateur EP est alors sans biais. Le poids qui est donné à chaque simulation est le ratio de vraisemblance, qui est la densité de Radon-Nikodym de la vraie distribution par rapport à la distribution biaisée.
Le point fondamental dans l'implémentation d'une simulation utilisant l'EP est le choix de la distribution biaisée. Choisir ou créer une bonne distribution biaisée est l'art des EP. L'avantage peut alors être une énorme économie de temps de calculs alors que l'inconvénient pour une mauvaise distribution peut être des calculs plus longs qu'une simple simulation de Monte-Carlo.
Sommaire
Approche Mathématique
Principe général
La méthode de Monte-Carlo classique
On souhaite estimer une quantité G, qui s'exprime sous la forme d'une intégrale :
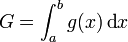
On considère ici une intégration en dimension 1, mais on peut généraliser à une dimension quelconque.
Le principe de base des méthodes de Monte-Carlo est de voir l'intégrale précédente comme
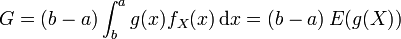
où X est une variable aléatoire uniformément distribuée sur [a;b] et
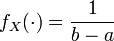 sa densité.
sa densité.Si on dispose d'un échantillon
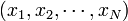 , identiquement et indépendamment distribué (i.i.d.) selon U([a;b]), on peut estimer G par :
, identiquement et indépendamment distribué (i.i.d.) selon U([a;b]), on peut estimer G par :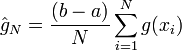
Il s'agit, d'après la loi des grands nombres, d'un estimateur de G non-biaisé (c'est-à-dire que
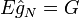 ). Sa variance est :
). Sa variance est :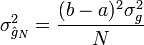
avec
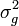 la variance de la variable aléatoire g(X)
la variance de la variable aléatoire g(X)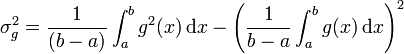
L'échantillonnage préférentiel
L'idée principale de l'échantillonnage préférentiel est de remplacer dans la simulation la densité uniforme sur [a;b] par une densité alternative (ou densité biaisée), disons
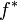 , qui tente d'imiter la fonction g. Ce faisant, on remplace les tirages uniformes, qui n'avantagent aucune région, par des tirages plus « fidèles ». Ainsi, l'échantillonnage est fait suivant l'importance de la fonction g: il est inutile de tirer dans les régions où g prend des valeurs non-significatives, pour, au contraire, se concentrer sur les régions de haute importance. On espère ainsi diminuer la variance . Autrement dit, si on se fixe un niveau d'erreur donné, l'EP permet de diminuer théoriquement le nombre de simulations N par rapport à une méthode de Monte-Carlo classique.
, qui tente d'imiter la fonction g. Ce faisant, on remplace les tirages uniformes, qui n'avantagent aucune région, par des tirages plus « fidèles ». Ainsi, l'échantillonnage est fait suivant l'importance de la fonction g: il est inutile de tirer dans les régions où g prend des valeurs non-significatives, pour, au contraire, se concentrer sur les régions de haute importance. On espère ainsi diminuer la variance . Autrement dit, si on se fixe un niveau d'erreur donné, l'EP permet de diminuer théoriquement le nombre de simulations N par rapport à une méthode de Monte-Carlo classique.L'intégrale à estimer est ré-écrite comme:
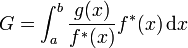
ce qui revient à:
![G = E^{\ast} [w(X)]](/pictures/frwiki/54/672811cef2592d2bdba7cf45acfe6805.png)
où on a posé
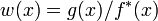 (appelé ratio de vraisemblance) et où X est simulé selon la densité
(appelé ratio de vraisemblance) et où X est simulé selon la densité 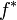 . Il est facile de généraliser les résultats précédents: l'estimateur de G est
. Il est facile de généraliser les résultats précédents: l'estimateur de G est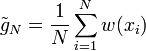
où
est un échantillon i.i.d. selon la densité . La variance de l'estimateur est donné par![\mbox{Var}^{\ast} (\tilde{g}_N) = \frac{\mbox{Var}^{\ast}[w(X)]}{N}](/pictures/frwiki/102/f2f05f85e86d5ffddaf638a5c6a04f0b.png)
avec enfin
![\mbox{Var}^{\ast}[w(X)] = \mbox{Var}^{\ast}\left[\frac{g(X)}{f^{\ast}(X)}\right]=\int_a^b \left[\frac{g(x)}{f^{\ast}(x)}\right]^2 f^{\ast}(x) \,\mbox{d}x - G^2](/pictures/frwiki/102/f6876319e8922f5e312f7393a753e09e.png)
Dès lors, le problème est de se concentrer sur l'obtention d'une densité biaisée
telle que la variance de l'estimateur EP soit moindre que celle de la méthode de Monte-Carlo classique. La densité minimisant la variance (qui la rend nulle sous certaines conditions) est appelée densité biaisée optimale. Cette dernière est égale à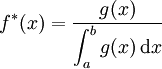
mais ce choix est inopérant, car on recherche justement le dénominateur. Mais, on peut s'attendre à réduire la variance en choisissant une densité
reproduisant la fonction g.Application: estimation d'une probabilité
Considérons que nous voulons estimer par simulation la probabilité
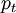 d'un événement
d'un événement 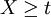 où X est une variable aléatoire de fonction de distribution F et de densité
où X est une variable aléatoire de fonction de distribution F et de densité 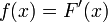 . Ce problème se ramène à la présentation générale dans le sens où il met en œuvre une intégrale à estimer. Un échantillon
. Ce problème se ramène à la présentation générale dans le sens où il met en œuvre une intégrale à estimer. Un échantillon 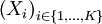 identiquement et indépendamment distribué (i.i.d.) est tiré dans cette loi. On note kt le nombre de réalisation supérieures à t. La variable kt est une variable aléatoire suivant une loi binomiale de paramètres K et pt:
identiquement et indépendamment distribué (i.i.d.) est tiré dans cette loi. On note kt le nombre de réalisation supérieures à t. La variable kt est une variable aléatoire suivant une loi binomiale de paramètres K et pt: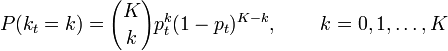
ce qui signifie notamment que E(kt) = Kpt: la fréquence empirique kt / N converge donc vers sa probabilité associée pt.
L'échantillonnage préférentiel entre en jeu ici pour diminuer la variance de l'estimation Monte-Carlo de la probabilité
. En effet, est donnée par![\begin{align}
p_t &= {E} [X \ge t]\\
&= \int (x \ge t) \frac{f(x)}{f^{\ast}(x)} f^{\ast}(x) \,dx\\
&= {E_*} [(X \ge t) w(X)]
\end{align}](/pictures/frwiki/52/4f0c9e0847e7e192d6cc3038111badbc.png)
où, on a encore posé
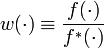
La dernière égalité de l'équation précédente suggère l'estimateur de pt suivant :
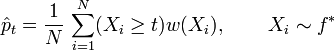
C'est un estimateur EP de
qui est sans biais. Ceci étant défini, la procédure d'estimation est de générer un échantillon i.i.d. à partir de la densité et pour chaque réalisation dépassant  de calculer son poids
de calculer son poids 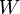 . Le résultat sera la moyenne obtenue avec
. Le résultat sera la moyenne obtenue avec 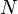 tirages. La variance de cet estimateur est :
tirages. La variance de cet estimateur est :![\begin{align}
\mbox{Var}^{\ast} \hat p_t &= \frac{1}{N} \mbox{Var}^{\ast} [(X \ge t)w(X)]\\
&= \frac{1}{N} \mbox{Var}^{\ast} [(X \ge t)w(X)] \\
&= \frac{1}{N}\Big[{E_*}[(X \ge t)^2 w^2(X)] - p_t^2 \Big]\\
&= \frac{1}{N}\Big[{E}[(X \ge t)^2 w(X)] - p_t^2 \Big]
\end{align}](/pictures/frwiki/56/869d682993f9063bd872abb0589a8ea8.png)
Là encore il faudra profile au mieux la densité
afin de diminuer la variance.Un exemple numérique
On souhaite estimer la quantité suivante:
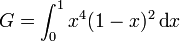
qui se trouve être la fonction bêta de paramètre (5;3), qui vaut G = 1/105 = 0,0095238095238095. Cela correspond au cas général avec a=0, b=1 et g(x) = x4(1 − x)2.
On simule un échantillon
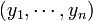 selon la loi uniforme standard (U[0;1]) pour obtenir l'estimateur Monte-Carlo classique:
selon la loi uniforme standard (U[0;1]) pour obtenir l'estimateur Monte-Carlo classique: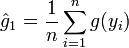
et l'estimateur de sa variance:
![\hat{\sigma}^2_{g_1} = \frac{1}{n} \left[ \frac{1}{n} \sum_{i=1}^n g^2(y_i) - \hat{g}_1^2\right]](/pictures/frwiki/97/a9b14a971ab386815302837ed2704528.png)
S'inspirant de la forme générale de la fonction bêta, on peut remplacer la loi uniforme standard par la loi triangulaire T(a=0,c=2/3,b=1). Elle ressemble à un triangle basé sur le segment [0;1] et "culminant" en (2/3;2). Sa densité est
![f^{\ast}(x) = \begin{cases}
3x & x \in [0;2/3]\\
6(1-x) & x \in [2/3;1]
\end{cases}](/pictures/frwiki/56/83d4639be375ba300afcd01e4b0fc3b5.png)
On simule un échantillon
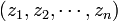 dans cette loi, par la méthode de la transformée inverse, et, en posant , l'estimateur EP est donné par
dans cette loi, par la méthode de la transformée inverse, et, en posant , l'estimateur EP est donné par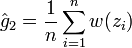
et l'estimateur de sa variance est
![\hat{\sigma}^2_{g_2} = \frac{1}{n} \left[ \frac{1}{n} \sum_{i=1}^n w^2(z_i) - \hat{g}_2^2\right]](/pictures/frwiki/98/b359f57179b35657ae4eb7d1685758b6.png)
Dans le tableau, on constate que l'utilisation de l'EP permet systématiquement de réduire la variance de l'estimation par rapport à l'estimation Monte-Carlo de même taille (c'est-à-dire à n donné). On constate aussi que la variance d'estimation est proportionnelle à 1/n: en passant de n = 1000 à n = 10 000 (multiplication par 10 dela taille), on réduit d'un facteur 10 la variance.
Comparaison de la méthode Monte-Carlo et de l'échantillonnage préférentiel Monte-Carlo classique Echantillonage préférentiel n estimateur biais variance estimateur biais variance 500 0,009843 -3,19E-004 1,32E-007 0,009712 -1,88E-004 2,50E-008 1000 0,009735 -2,12E-004 6,53E-008 0,009680 -1,57E-004 1,26E-008 2500 0,009628 -1,04E-004 2,60E-008 0,009576 -5,18E-005 5,36E-009 5000 0,009717 -1,93E-004 1,31E-008 0,009542 -1,83E-005 2,71E-009 10000 0,009634 -1,10E-004 6,52E-009 0,009544 -1,99E-005 1,35E-009 On espère améliorer encore les performances en considérant une densité
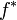 "plus proche" de la densité f. Le principal problème sera d'obtenir des simulations. Dans les cas les plus simples, comme la loi triangulaire, la méthode de la transformée inverse pourra suffir; dans les cas plus complexes, il faudra avoir recours à la méthode de rejet.
"plus proche" de la densité f. Le principal problème sera d'obtenir des simulations. Dans les cas les plus simples, comme la loi triangulaire, la méthode de la transformée inverse pourra suffir; dans les cas plus complexes, il faudra avoir recours à la méthode de rejet.Voir aussi
Liens internes
Catégorie : Probabilités
Wikimedia Foundation. 2010.