- Information de fisher
-
Information de Fisher
L'information de Fisher est une notion de statistique introduite par R.A. Fisher qui quantifie l'information relative à un paramètre contenue dans une distribution.
Soit f(x;θ) la distribution de vraisemblance d'une grandeur x (qui peut être multidimensionelle), paramétrée par θ. La technique d'estimation de θ par le maximum de vraisemblance, introduite par Fisher consiste à choisir la valeur maximisant la vraisemblance des observations X :
![E\left[\frac{\partial \log f(X;\theta)}{\partial \theta} | \theta \right] =0](/pictures/frwiki/57/9aab5e67b42d935aab5ce9f5dd5cda91.png) .
.L'information de Fisher est quant à elle définie comme la variance associée à ce maximum :
![I(\theta)=E\left[ \left(\frac{\partial \log f(X;\theta)}{\partial \theta} \right)^2 |\theta \right]](/pictures/frwiki/52/4c33d29908a7705cac62d85db9ab3c6c.png) .
.Sommaire
Formulation discrète
Les différentes observations xi nous permettent d'échantillonner la fonction de densité de probabilité f(x;θ). Selon le théorème de Bayes, en l'absence d'a priori sur θ on a
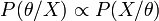 Si les observations sont décorrélées, la valeur la plus probable
Si les observations sont décorrélées, la valeur la plus probable 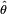 nous est donnée par le maximum de
nous est donnée par le maximum de∏ P(xi / θ), i qui est aussi le maximum de
λ(θ) = ∑ logP(xi / θ). i Le passage en logarithme permet de transformer le produit en somme, ce qui nous autorise à trouver le maximum par dérivation :
![\sum_i \left[
\frac{\partial}{\partial \theta} \log P(x_i/\theta)
\right]_{\theta=\hat\theta} =0.](/pictures/frwiki/50/2a3918474e37c34a0c7f09a74b4b0bc1.png)
Cette somme correspond pour un nombre d'observations suffisamment élevé à l'espérance mathématique. La résolution de cette équation permet de trouver un estimateur de θ à partir du jeu de paramètre au sens du maximum de vraisemblance. Maintenant, la question est de quantifier la précision de notre estimation. On cherche donc à estimer la forme de la distribution de probabilité de θ autour de la valeur donnée par l'estimateur
. À partir d'un développement limité à l'ordre 2, comme le terme linéaire est nul au maximum, on obtient :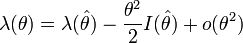
où
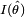 est l'information de Fisher relative à θ au point de maximum de vraisemblance. Ceci signifie que la distribution est en première approximation une gaussienne de variance
est l'information de Fisher relative à θ au point de maximum de vraisemblance. Ceci signifie que la distribution est en première approximation une gaussienne de variance 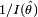 :
: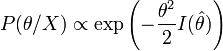
Cette variance est appelé la borne de Cramér-Rao et constitue la meilleure précision d'estimation atteignable en absence d'a priori.
Formulation multi-paramétrique
Dans le cas où la distribution de probabilité dépend de plusieurs paramètres, θ n'est plus un scalaire mais un vecteur
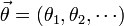 . La recherche du maximum de vraisemblance ne se résume donc non pas à une seule équation mais à un système :
. La recherche du maximum de vraisemblance ne se résume donc non pas à une seule équation mais à un système :![E\left[\frac{\partial}{\partial \theta_i} \log f(X;\vec\theta) \right]
=0, \qquad \forall i](/pictures/frwiki/102/f6455596dea774a984d8432ab1177eb8.png)
on dérive vis à vis des différentes composantes de
 . Enfin, l'information de Fisher n'est plus définie comme une variance scalaire mais comme une matrice de covariance :
. Enfin, l'information de Fisher n'est plus définie comme une variance scalaire mais comme une matrice de covariance :![I(\theta_i,\theta_j)=E\left[
\left(\frac{\partial}{\partial \theta_i} \log f(X;\vec\theta) \right)
\left(\frac{\partial}{\partial \theta_j} \log f(X;\vec\theta) \right)\right].](/pictures/frwiki/101/e7fc2678c617c8cd64ae362488b17e7b.png)
Cette matrice est couramment appelée la métrique d'information de Fisher. En effet, le passage de l'espace des observations à l'espace des paramètres est un changement de système de coordonnées. Dans la base des paramètres, avec comme produit scalaire la covariance, cette matrice est la métrique.
L'inverse de cette matrice permet quant à elle de déterminer les bornes de Cramér-Rao, i.e. les covariances relatives aux estimations conjointes des différents paramètres à partir des observations : en effet, le fait que tous les paramètres soient à estimer simultanément rend l'estimation plus difficile. Ce phénomène est une manifestation de ce qui est parfois appelé le « fléau de la dimension ». C'est pour cette raison que l'on utilise quand on le peut des a priori sur les paramètres (méthode d'estimation du maximum a posteriori). Ainsi, on restreint l'incertitude sur chacun des paramètres, ce qui limite l'impact sur l'estimation conjointe.
Information apportée par une statistique
De la même façon que l'on à définit l'information de Fisher pour le vecteur des observations X on peut définir l'information de Fisher contenue dans une statistique S(X):
![I_{S}(\theta)=\mathbb{E}_\theta\left[
\left(\nabla_\theta \log f_S(S;\theta) \right)\cdot\left(\nabla_\theta \log f_S(S;\theta)\right)'\right].](/pictures/frwiki/57/9d29df81df3ae0a46270ffe0874449a8.png)
Cette définition est exactement la même que celle de l'information de Fisher pour X pour un modèle multiparamétrique on remplace juste la densité de X par celle de S(X) la statistique S. Deux théorèmes illustrent l'intérêt de cette notion:
- Pour une statistique exhaustive on a IS(θ) = I(θ) ce qui permet de voir une statistique exhaustive comme une statistique comprenant toute l'information du modèle. L'on a aussi la réciproque à savoir que si IS(θ) = I(θ) alors S est exhaustif bien que cette caractérisation est rarement utilisée dans ce sens la définition grâce au critère de factorisation des statistiques exhaustives étant souvent plus maniable.
- Quelle que soit la statistique S,
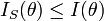 avec un cas d'égalité uniquement pour des statistiques exhaustives. On ne peut donc récupérer plus d'information que celle contenue dans une statistique exhaustive. Ceci explique en grande partie l'intérêt des statistiques exhaustives pour l'estimation. La relation d'ordre est ici la relation d'ordre partielle sur les matrices symétriques à savoir qu'une matrice
avec un cas d'égalité uniquement pour des statistiques exhaustives. On ne peut donc récupérer plus d'information que celle contenue dans une statistique exhaustive. Ceci explique en grande partie l'intérêt des statistiques exhaustives pour l'estimation. La relation d'ordre est ici la relation d'ordre partielle sur les matrices symétriques à savoir qu'une matrice 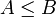 si B-A est une matrice symétrique positive.
si B-A est une matrice symétrique positive.
Références
- A. Montfort Cours de statistique mathématique, 1982, Economica. Paris.
Voir aussi
Liens externes
- P. Druilhet [1] Cours de statistique inférentielle.
Catégorie : Estimation (statistique)
Wikimedia Foundation. 2010.