- Déviation standard
-
Écart type
En mathématiques, plus précisément en statistiques et probabilités, l'écart type mesure la dispersion d'une série de valeurs autour de leur moyenne.
Dans le domaine des probabilités, l'écart type est une quantité réelle positive, éventuellement infinie, utilisée pour caractériser la répartition d'une variable aléatoire réelle autour de sa moyenne. En particulier, la moyenne et l'écart type caractérisent entièrement les lois gaussiennes à un paramètre réel, de sorte qu'ils sont utilisés pour les paramétrer. Plus généralement, l'écart type, à travers son carré, appelé variance, permet de caractériser des lois gaussiennes en dimension supérieure. Ces considérations ne sont pas sans importance, notamment dans l'application du théorème de la limite centrale.
En statistiques, plus particulièrement en théorie des sondages, ainsi qu'en métrologie, l'écart type (standard deviation en anglais) tente d'évaluer, à partir d'un échantillon soumis au hasard, la dispersion de la population tout entière. On distingue alors l'écart type empirique (biaisé) et l'écart type empirique corrigé dont la formule diffère de celle utilisée en probabilité.
Les écarts types connaissent de nombreuses applications, tant dans les sondages, qu'en physique (où ils sont souvent nommés RMS par abus de langage), ou en biologie. Ils permettent en pratique de rendre compte des résultats numériques d'une expérience répétée. En finance l'écart type est une mesure de la volatilité d'un actif.
Sommaire
Généralités
En statistiques comme en probabilités on définit, outre des valeurs centrales, des valeurs de dispersion.
Dans le domaine des probabilités, la dispersion d'une variable aléatoire réelle X autour de sa moyenne est caractérisée par la variance dont le calcul repose sur la notion d'espérance mathématique.
Pratiquement, c'est l'écart-type ou écart quadratique moyen, racine carrée de la variance, qui est utilisé car il possède les mêmes dimensions physiques que la variable. Cette notion apparaît aussi dans l'analyse des signaux, souvent en relation avec la notion de processus aléatoire, généralement sous le nom de moyenne quadratique.
En statistique descriptive qui porte sur une population finie parfaitement connue, les valeurs de dispersion, comme les valeurs centrales, peuvent être choisies arbitrairement (écart-type, écart moyen, étendue, ...).
La statistique mathématique porte au contraire sur une population infinie qui ne peut être connue qu'imparfaitement à travers un ensemble fini de données
![[x_1..x_n]\,](/pictures/frwiki/98/b933b64a30c027850a56555cc1607697.png) . Pour interpréter ces données imprécises, il faut faire appel à la notion de probabilité. Les données sont alors considérées comme une réalisation d'un échantillon constitué par les variables aléatoires
. Pour interpréter ces données imprécises, il faut faire appel à la notion de probabilité. Les données sont alors considérées comme une réalisation d'un échantillon constitué par les variables aléatoires ![[X_1..X_n]\,](/pictures/frwiki/54/694d2502368ae60a66ba113207b7f8e9.png) . Par des calculs arithmétiques analogues à ceux qui sont effectués en statistique descriptive, il est possible de déduire de la réalisation de l'échantillon des estimations de la moyenne empirique et de la variance empirique qui sont elles-mêmes des variables aléatoires. La moyenne empirique fournit une estimation sans biais de la moyenne de la loi de probabilité car son espérance est égale à cette dernière. Au contraire, la variance empirique fournit une estimation biaisée de la variance ; pour obtenir une estimation sans biais, il faut la multiplier par
. Par des calculs arithmétiques analogues à ceux qui sont effectués en statistique descriptive, il est possible de déduire de la réalisation de l'échantillon des estimations de la moyenne empirique et de la variance empirique qui sont elles-mêmes des variables aléatoires. La moyenne empirique fournit une estimation sans biais de la moyenne de la loi de probabilité car son espérance est égale à cette dernière. Au contraire, la variance empirique fournit une estimation biaisée de la variance ; pour obtenir une estimation sans biais, il faut la multiplier par 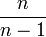 .
.Première approche
L'écart-type sert à mesurer la dispersion d'un ensemble de données, par exemple la répartition des notes d'une classe. Dans ce cas, plus l'écart-type est faible, plus la classe est homogène. À l'inverse, on peut souhaiter avoir un écart type le plus large possible pour éviter que les notes soient trop resserrées (exemple classique du professeur qui note de 8 à 13).
Dans le cas d'une notation de 0 à 20, l'écart type minimum est 0 (si tous les élèves/étudiants ont la même note), et jusqu'à environ 10 si la moitié a 0/20 et l'autre moitié 20/20.
En sciences humaines, il est fréquent de considérer que les valeurs se répartissent selon une courbe de Gauss (courbe en forme de cloche). Dans ce cas, la donnée de la moyenne et l'écart-type permet de déterminer l'intervalle dans lequel on trouve 95 % de la population. Si la moyenne est m et l'écart type est σ, on trouve 95 % de la population dans l'intervalle [m − 2σ;m + 2σ] et on trouve 68 % de la population dans l'intervalle [m − σ;m + σ].
En probabilité
Dans la formulation moderne des probabilités, suite aux travaux de Henri Lebesgue, une variable aléatoire X est une application à valeurs réelles ou vectorielles, dépendant d'un paramètre x suivant une loi de probabilité P. Si la compréhension du formalisme fait appel à la théorie de la mesure, son utilisation reste simple. L'application X ne joue pas un rôle fondamental ; seule sa loi, l'image de P par X, notée PX, importe. Il s'agit d'une mesure sur R ou sur Rn. Deux quantités lui sont associées :
- Sa moyenne, notée E[X], aussi appelée espérance :
- Son écart type, généralement noté σX, défini comme la racine carrée de l'espérance de (X-E[X])2 :
![\sigma_X^2=E[(X-E[X])^2]=E[X^2]-E[X]^2](/pictures/frwiki/55/7ab175454f1651c60ac95242def76551.png) .
.Ici, l'élévation au carré pour le membre de droite désigne implicitement la norme euclidienne au carré dans le cas où X est à valeurs vectorielles.
Cette identité se spécialise dans un grand nombre de cas particuliers. Entre autres :
Probabilité discrète
Si la variable X prend un nombre fini de valeurs réelles x1, ..., xn, avec des probabilités respectives p1, ..., pn (sous la condition
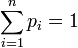 ), l'écart type est donné par :
), l'écart type est donné par :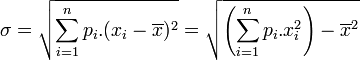 , où :
, où : 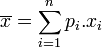 .
.En particulier, si la loi de X est uniforme sur un ensemble fini de valeurs, on a :
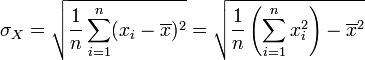 , où :
, où : 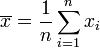 .
.Ces formules se généralisent immédiatement en dimension supérieure en remplaçant l'élévation au carré par la norme euclidienne au carré.
Probabilité uniformément continue
La loi PX est dite uniformément continue lorsque la probabilité que X appartienne au segment [a, b] est :
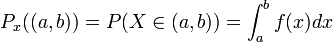
où f est une fonction localement intégrable pour la mesure de Lebesgue, par exemple mais pas nécessairement une fonction continue. Cette fonction f s'appelle la densité de la loi PX. Elle est globalement intégrable et de carré intégrable.
L'écart type de X est défini par :
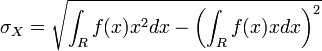 .
.Exemples d'écarts types
Le tableau suivant donne les écarts types pour les lois couramment rencontrées :
Nom de la loi Paramètre Description Ecart-type Loi de Bernoulli p Loi discrète de valeurs 0 avec probabilité 1-p et 1 avec probabilité p 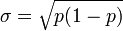
Loi binomiale p et n>1 Loi de la somme indépendantes de n variables suivant la loi de Bernoulli de paramètre p 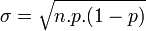
Loi géométrique p Loi discrète sur N telle que la probabilité d'obtenir l'entier n soit (1-p).pn σ = p / (1 − p)2 Loi uniforme sur un segment a<b Loi uniformément continue sur R de densité la fonction indicatrice de [a, b] à un coefficient près 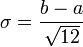
Loi exponentielle p Loi uniformément continue de support R+ de densité la fonction f(x)=p.exp(-p.x) σ = 1 / p Calculs...
Estimation
En statistiques, deux estimateurs de l'écart type sont généralement utilisés. Ces estimateurs sont simplement obtenus en prenant la racine des estimateurs de la variance, étant donné que l'écart-type est juste la racine de la variance.
On note très souvent les statistiques variance empirique
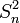 (S2) et variance empirique corrigée
(S2) et variance empirique corrigée 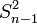 ( ou S'2) car l'écart type s'exprime comme la racine carrée de la variance.
( ou S'2) car l'écart type s'exprime comme la racine carrée de la variance.Ecart type empirique
Lorsqu'il s'agit d'estimer la dispersion autour de la moyenne d'un caractère statistique X quelconque dans une population de taille N à partir d'un échantillon (X1,X2,...,Xi,...,Xn) de taille n petite par rapport à N (où les Xi suivent une même loi que X), on peut utiliser l'écart type empirique défini par:
où
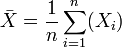 représente la moyenne empirique de l'échantilllon.
représente la moyenne empirique de l'échantilllon.Une réalisation de la statistique S est donnée par:
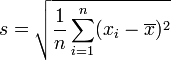 .
.
Ecart type empirique corrigé
Il est souvent plus commode de considérer la statistique définie par:
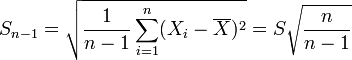 .
.
et dont une réalisation est
Propriétés des estimateurs
En général, l'estimateur Sn − 1 est préféré, étant donné que l'estimateur
est sans biais. Ces deux estimateurs sont cependant biaisés mais convergents.Biais
Pour établir les propriétés des estimateurs de l'écart-type, il est utile de rappeler les propriétés des estimateurs de la variance:
- est un estimateur non biaisé de σ2
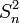 est un estimateur biaisé de σ2
est un estimateur biaisé de σ2
Il n'est cependant pas évident de trouver un estimateur non biaisé de l'écart type. En effet, on sait par l'inégalité de Jensen que:
Inégalité de Jensen — Soit f une fonction convexe sur ]a; b[ et X une variable aléatoire d'espérance finie, à valeurs dans ]a; b[. Alors l'inégalité suivante est vraie :
L'inégalité s'inverse avec des fonctions concaves. Comme la fonction racine carrée est concave, on a:
![\operatorname{E}[S^2_{n-1}]=\sigma^2](/pictures/frwiki/57/9fc2275bc7a8f1bc5100dcdb7d202c95.png) et donc:
et donc:![\operatorname{E}\left[\sqrt{S^2_{n-1}}\right]\leq \sqrt{\sigma^2}](/pictures/frwiki/53/5c89bd1949b3a29a264ba6f28f53d40b.png) .
.
L'estimateur Sn − 1 sera donc biaisé vers le bas.
Il est en fait très difficile d'obtenir un estimateur sans biais, et dans le cas où les données suivent une loi normale la formule est assez complexe, (voir la page anglaise: en:Unbiased estimation of standard deviation).
Convergence
Il est utile de rappeler que:
- et sont des estimateurs convergents de σ2
Par le théorème de continuité, on a que :
Théorème — Si g est continue: Si
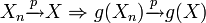
Comme la foncton racine carrée est une fonction continue, Sn − 1 et Sn sont des estimateurs convergents de l'écart-type, soit:
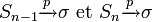
Aspect qualitatif
L'écart type caractérise la largeur de la distribution. Il est exprimé mathématiquement comme étant la racine carrée de la variance, celle-ci mesurant la distribution des valeurs autour du centre de la courbe.
Écart type σ = Racine carrée de la variance
- L'écart type est la mesure de dispersion, ou étalement, la plus couramment utilisée en statistique lorsqu'on emploie la moyenne pour calculer une tendance centrale. Il mesure donc la dispersion autour de la moyenne. En raison de ses liens étroits avec la moyenne, l'écart type peut être grandement influencé si cette dernière donne une mauvaise mesure de tendance centrale.
- Contrairement à l'étendue et aux quartiles, la variance permet de combiner toutes les valeurs à l'intérieur d'un ensemble de données afin d'obtenir la mesure de dispersion. La variance (symbolisée par S²) et l'écart type (la racine carrée de la variance, symbolisée par S) sont les mesures de dispersion les plus couramment utilisées.
La variance est définie comme étant la moyenne arithmétique des carrés des différences entre les valeurs observées et la moyenne. C'est une mesure du degré de dispersion d'un ensemble de données. On la calcule sous la forme de l'écart au carré moyen de chaque nombre par rapport à la moyenne d'un ensemble de données.
Répartition de la population
Lorsque la variable étudiée est gaussienne (répartition selon une courbe en cloche), l'écart type permet de déterminer la répartition de la population autour de la valeur moyenne.
Par exemple : Si par convention, l'écart-type par rapport à un échantillon équivaut à 15 points de QI de différence, cela signifie que les 2/3 environ de la population d'une classe d'âge ont un QI compris entre 85 et 115. Voir également à ce sujet l'intervalle de confiance d'une distribution normale gaussienne.
Interprétation d'un écart type élevé
Généralement, plus les valeurs sont largement distribuées, plus l'écart type est élevé. Imaginez, par exemple, que nous devions séparer deux ensembles différents de résultats d'examens de 30 élèves; les notes du premier examen varient de 31 % à 98 % et celles du second, de 82 % à 93 %. Compte tenu de ces étendues, l'écart type serait plus grand pour les résultats du premier examen.
Cependant, il n'est pas toujours facile d'évaluer l'importance que doit avoir l'écart type pour que les données soient largement dispersées.
L'importance de l'écart type dépend aussi de l'importance de la valeur moyenne de l'ensemble des données. Lorsque vous mesurez quelque chose en millions, le fait d'avoir des mesures qui se rapprochent de la valeur moyenne n'a pas la même signification que si vous mesurez le poids de deux personnes.
Par exemple, si après avoir mesuré les recettes annuelles de deux grandes entreprises, vous constatez un écart de 100 000 euros, la différence est considérée comme étant peu significative, alors que si vous mesurez le poids de deux personnes, dont l'écart est de 30 kilogrammes, la différence est considérée comme étant très significative.
Voilà pourquoi il est parfois utile de travailler, dans certains cas, sur l'écart type relatif (écart type quotienté par la moyenne).Voir aussi
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Statistique descriptive | Probabilités
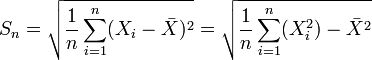
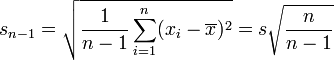
![f(\mathbb{E}(X)) \leq \mathbb{E}[f(X)]](/pictures/frwiki/49/137134a5624eee429c6948a190da22c6.png)
Wikimedia Foundation. 2010.