- Dépassement De Tampon
-
Dépassement de tampon
En informatique, un dépassement de tampon ou débordement de tampon (en anglais, buffer overflow) est un bogue causé par un processus qui, lors de l'écriture dans un tampon, écrit à l'extérieur de l'espace alloué au tampon, écrasant ainsi des informations nécessaires au processus.
Lorsque le bogue se produit non intentionnellement, le comportement de l'ordinateur devient imprévisible. Il en résulte souvent un blocage du programme, voire de tout le système.
Le bogue peut aussi être provoqué intentionnellement et être exploité pour violer la politique de sécurité d’un système. Cette technique est couramment utilisée par les pirates informatiques. La stratégie du pirate est alors de détourner le programme bogué en lui faisant exécuter des instructions qu'il a introduit dans le processus.
Sommaire
Utilisation malveillante et contre-mesures
Le principe de l'utilisation malveillante du dépassement de tampon est de profiter de l’accès à certaines variables du programme, souvent par le biais de fonctions telles que scanf() (analyse d'une chaîne de caractères) ou strcpy() (copie d'une chaîne de caractères) en langage C, qui ne contrôlent pas la taille de la chaîne à traiter, afin d’écraser la mémoire du processus jusqu’à l’adresse de retour de la fonction en cours d’exécution. Le pirate peut ainsi choisir quelles seront les prochaines instructions exécutées par le processus et faire exécuter un code malveillant qu'il aura introduit dans le programme.
Afin d’éviter ces dépassements, certaines fonctions ont été réécrites pour prendre en paramètre la taille du tampon dans lequel les données sont copiées, et éviter ainsi de copier des informations à l'extérieur du tampon. Ainsi strncpy() est une version de strcpy() qui tient compte de la taille du tampon. Dès que les techniques de dépassement de tampon ont commencé à se généraliser, l’équipe de développeurs de FreeBSD cessa tout nouveau développement pendant plusieurs mois afin de colmater toutes les brèches de ce genre dans leur code. L'équipe de Linux temporisa un peu plus.[réf. nécessaire]
La fonction strncpy présente l'inconvénient de remplir toute la fin du tampon de zéros, ce qui la rend moins efficace. Theo de Raadt et Todd C. Miller ont conçu les fonctions strlcpy et strlcat qui ne présentent pas ce défaut. Disponibles initialement sous OpenBSD, ces fonctions tendent à se répandre dans divers logiciels comme rsync et KDE.
Détails techniques sur architecture x86 (Intel)
Un programme en exécution (un processus) découpe la mémoire adressable en zones distinctes :
- la zone de code où sont stockées les instructions du programme en cours ;
- la zone des données où sont stockées certaines des données que manipule le programme ;
- la zone de la pile d'exécution ;
- la zone du tas.
Contrairement aux deux premières, les deux dernières zones sont dynamiques, c'est-à-dire que leur pourcentage d'utilisation et leur contenu varient tout au long de l’exécution d’un processus.
La zone de la pile d'exécution est utilisée par les fonctions (stockage des variables locales et passage des paramètres). Elle se comporte comme une pile, c'est-à-dire dernier entré, premier sorti. Les variables et les paramètres d’une fonction sont empilés avant le début de la fonction et dépilés à la fin de la fonction.
Une fonction est une suite d'instructions. Les instructions d'une fonction peuvent être exécutées (en informatique, on dit que la fonction est appelée) à partir de n'importe quel endroit d'un programme. À la fin de l'exécution des instructions de la fonction, l'exécution doit se continuer à l'instruction du programme qui suit l'instruction qui a appelé la fonction.
Pour permettre le retour au programme qui a appelé la fonction, l’instruction d'appel de la fonction (l'instruction call) enregistre l'adresse de retour dans la pile d'exécution. Lors de l’exécution de l’instruction ret qui marque la fin de la fonction, le processeur récupère l’adresse de retour qu’il a précédemment stockée dans la pile d'exécution et le processus peut continuer son exécution à cette adresse.
Plus précisément, le traitement d'une fonction inclut les étapes suivantes :
- l'empilage des paramètres de la fonction sur la pile d'exécution (avec l'instruction push) ;
- l'appel de la fonction (avec l'instruction call) ; cette étape déclenche la sauvegarde de l’adresse de retour de la fonction sur la pile d'exécution ;
- le début de la fonction qui inclut :
- la sauvegarde de l'adresse de la pile qui marque le début de l'enregistrement de l'état actuel du programme,
- l'allocation des variables locales dans la pile d'exécution ;
- l'exécution de la fonction ;
- la sortie de la fonction qui inclut la restauration du pointeur qui marquait le début de l'enregistrement de l'état du programme au moment de l'appel de la fonction,
- l'exécution de l’instruction ret qui indique la fin de la fonction et déclenche la récupération de l’adresse de retour et le branchement à cette adresse.
Illustration
Soit l’extrait de programme C suivant (volontairement simplifié) :
#include <string.h> void foo(char *str) { char buffer[32]; strcpy(buffer, str); /* ... */ } int main(int argc, char *argv[]) { if (argc > 1) { /* appel avec le premier argument de la ligne de commandes */ foo(argv[1]); } /* ... */ return 0; }
Ce qui est traduit ainsi par un compilateur C (ici le compilateur GCC avec architecture x86) :
push ebp ; entrée de la fonction mov ebp,esp ; sub esp,40 ; 40 octets sont « alloués » (32 + les 2 variables qui serviront ; à l'appel de strcpy) mov eax,[ebp+0x8] ; paramètre de la fonction (str) mov [esp+0x4],eax ; préparation de l'appel de fonction : 2{{e}} paramètre lea eax,[ebp-0x20] ; ebp-0x20 contient la variable locale 'buffer' mov [esp],eax ; 1{{er}} paramètre call strcpy ; sortie de la fonction leave ; équivalent à mov esp,ebp et pop ebp ret
Voici l'état de la pile d'exécution et des deux registres (ebp et esp) juste avant l'appel de la fonction strcpy :
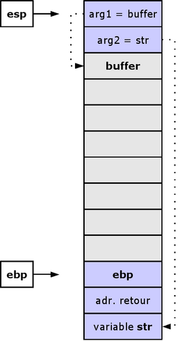 État de la pile avant l'appel à la fonction strcpy
État de la pile avant l'appel à la fonction strcpy
La fonction strcpy copiera le contenu de str dans buffer. La fonction strcpy ne fait aucune vérification : elle copiera le contenu de str jusqu'à ce qu'elle rencontre un caractère de fin de chaîne (caractère nul).
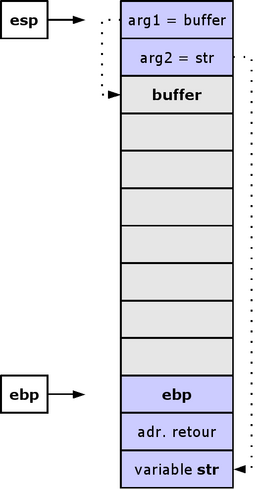
Si str contient plus de 32 octets avant le caractère nul, la fonction strcpy continuera à copier le contenu de la chaîne au-delà de la zone allouée par la variable locale buffer. C’est ainsi que les informations stockées dans la pile d'exécution (incluant l’adresse de retour de la fonction) pourront être écrasées comme indiqué dans l'illustration suivante :
 Dépassement de tampon : la fonction strcpy copie la chaîne vers la zone mémoire indiquée, dépasse la zone allouée et écrase l'adresse de retour de la fonction foo
Dépassement de tampon : la fonction strcpy copie la chaîne vers la zone mémoire indiquée, dépasse la zone allouée et écrase l'adresse de retour de la fonction fooDans l’exemple précédent, si str contient un code malveillant sur 32 octets suivi de l’adresse de buffer, au retour de la fonction, le processeur exécutera le code contenu dans str.
Pour que cette « technique » fonctionne, il faut deux conditions :
- le code malveillant ne doit contenir aucun caractère nul, sans quoi strcpy() arrêtera sans copier les octets suivants le caractère nul ;
- l'adresse de retour ne doit pas non plus contenir de caractère nul.
Le dépassement de tampon avec écrasement de l'adresse de retour est un bogue du programme. L’adresse de retour ayant été écrasée, à la fin de la fonction, le processeur ne peut brancher vers l'adresse de retour originale, car cette adresse a été modifiée par le dépassement de tampon. Dans le cas d'un bogue involontaire, l'adresse de retour a généralement été remplacée par une adresse en dehors de la plage adressable et le programme plante en affichant un message d’erreur (erreur de segmentation).
Un pirate informatique peut utiliser ce comportement à ses fins. Par exemple, en connaissant la taille du tampon (dans l’exemple précédent 32 octets), il peut écraser l’adresse de retour pour la remplacer par une adresse qui pointe vers un code à lui, de manière à prendre le contrôle du programme. De cette façon, il obtient les droits d’exécution associés au programme qu'il a détourné et peut dans certains cas accéder à des ressources critiques.
La forme d’attaque la plus simple consiste à inclure dans une chaîne de caractères copiée dans le tampon un programme malveillant et d'écraser l'adresse de retour par une adresse pointant vers ce code malveillant.
Pour arriver à ses fins, le pirate doit surmonter deux difficultés :
- trouver l'adresse de début de son code malveillant dans le programme attaqué ;
- construire son code d’exploitation en respectant les contraintes imposées par le type de variable dans lequel il place son code (dans l'exemple précédent, la variable est une chaîne de caractères).
Trouver l'adresse de début du code malveillant
La technique précédente nécessite généralement pour l’attaquant de connaître l’adresse de début du code malveillant. Ceci est assez complexe, car cela demande généralement des essais successifs, ce qui n’est pas une méthode très « discrète ». De plus, il y a de fortes chances que l’adresse de la pile change d’une version à l’autre du programme visé et d’un système d'exploitation à l’autre.
Le pirate veut généralement exploiter une faille sur le plus de versions possible du même programme (afin peut-être de concevoir un virus ou ver). Pour s’affranchir du besoin de connaître l'adresse du début du code malveillant, il doit trouver une méthode qui lui permette de brancher sur son code sans se préoccuper de la version du système d'exploitation et du programme visé tout en évitant de faire de multiples tentatives qui prendraient du temps et dévoileraient peut-être sa présence.
Il est possible dans certains cas de se servir du contexte d’exécution du système cible. Par exemple, sur des systèmes Windows, la plupart des programmes, même les plus simples contiennent un ensemble de primitives systèmes accessibles au programme (DLL). Il est possible de trouver des bibliothèques dont l’adresse mémoire lors de l’exécution change peu en fonction de la version du système. Le but pour l’attaquant est alors de trouver dans ces plages mémoires des instructions qui manipulent la pile d'exécution et lui permettront d’exécuter son code.
Par exemple, en supposant que la fonction strcpy manipule un registre processeur (eax) pour y stocker l’adresse source. Dans l’exemple précédent, eax contiendra une adresse proche de l’adresse de buffer au retour de strcpy. Le but de l’attaquant est donc de trouver dans la zone mémoire supposée « fixe » (la zone des DLL par exemple) un code qui permet de sauter vers le contenu de eax (call eax ou jmp eax). Il construira alors son buffer en plaçant son code suivi de l’adresse d’une instruction de saut (call eax ou jmp eax). Au retour de strcpy, le processeur branchera vers une zone mémoire contenant call eax ou jmp eax et puisque eax contient l’adresse du buffer, il branchera de nouveau vers le code et l’exécutera.
Construire son code d’exploitation
La deuxième difficulté pour l'attaquant est la construction du code d’exploitation appelé shellcode. Dans certains cas, le code doit être construit avec un jeu de caractères réduit : chaîne Unicode, chaîne alphanumérique, etc.
En pratique, ces limitations n'arrêtent pas un pirate déterminé. On recense des cas de piratage utilisant du code limité aux caractères légaux d'une chaîne Unicode (mais il faut pouvoir exécuter du code automodifiant).
Préventions
Pour se prémunir contre de telles attaques, plusieurs options sont offertes au programmeur. Quelques unes de ces options sont décrites dans les deux sections suivantes.
Protections logicielles
- Modifier le compilateur pour qu’il insère des instructions NOP de façon aléatoire dans le code du noyau et des applications (opérations de routine en Linux). Cela ralentit peu les programmes et complique énormément la tâche du pirate qui ne sait plus quelles adresses il doit viser.
- Utiliser un autre langage que C ou C++ qui ne dispose d'aucun mécanisme de vérification de dépassement de tampon.
- Utiliser des outils externes qui permettent, en mode développement, de tester les cas litigieux, par exemple la bibliothèque Electric Fence ou Valgrind.
- Bannir de son utilisation les fonctions dites « non protégées ». Préférer par exemple strncpy à strcpy ou alors fgets à scanf qui effectue un contrôle de taille. Les compilateurs récents peuvent prévenir le programmeur s’il utilise des fonctions à risque, même si leur utilisation demeure possible.
- Protéger, côté système, la pile d'exécution :
- Rendre la pile non exécutable,
- Mettre en place un mécanisme de vérification de la pile (technique du canari. Le principe est de stocker une clé de valeur aléatoire, générée à l’exécution, entre la fin de la pile et l'adresse de retour. Si cette clé est modifiée, l’exécution est avortée (disponible en option dans les compilateurs C récents - éventuellement avec recours à des patchs). La principale critique de cette méthode est que l’appel de fonction est ainsi ralenti.
Aucune de ces solutions logicielles ne s’est imposée (en 2008) dans le monde du développement industriel. Pourtant, les dépassements de tampon représentent une part encore importante des failles permettant le développement de vers, de virus et d'attaques manuelles.
Protections matérielles
- Les microprocesseurs récents, 64 bits notamment, implémentent des protections efficaces (technologies NX Bit et XD bit).
Cas particulier de dépassement de tampon : débordement de nombre entier
Il est fréquent d'allouer dynamiquement des tableaux de structure de données, ce qui implique le calcul de la taille totale du tableau : taille_d'un_élément * nombre_d'éléments. Un tel produit peut donner un nombre trop grand pour être enregistré dans l'espace normalement alloué à un nombre entier. On a alors un dépassement d'entiers et le produit est tronqué, ce qui donne un résultat erroné plus petit que le résultat attendu. La zone mémoire allouée au tableau est alors de taille inférieure à ce qu'on pense avoir allouée. C'est un cas très particulier de dépassement de tampon, qui peut être utilisé par un pirate.
Autres types de dépassement de tampon
Il existe plusieurs autres types de dépassements de tampon. Ces failles de sécurité ont été couramment exploitées depuis le début des années 2000, en particulier dans OpenSSH et dans les bibliothèques de lecture de pratiquement tous les types d'image.
Dépassement de tas
En plus des techniques de piratage basées sur les dépassement de tampon, il existe d'autres techniques de piratage qui exploite le débordement d'autres variables contenues dans d’autres parties de la mémoire. En particulier, plusieurs attaques exploitent le débordement des variables du tas. Ces dépassements sont appelés dépassement de tas (en anglais, heap overflow).
Voir aussi
Articles connexes
Liens externes
- (en) Smashing the stack for fun and profit (traduction), AlephOne, Phrack 49 - Article de référence
- (en) Windows NT Buffer Overruns, David Litchfield
- (en) [pdf] Defeating Microsoft Windows XP SP2 Heap protection
- (fr) [pdf] Exploitation avancée de buffer overflows
- (fr) Exploitation Avancée de Stack Overflow Vulnerabilities
- (en) [pdf] Introduction to Reverse Engineering Win32 Applications
 Portail de la programmation informatique
Portail de la programmation informatique Portail de la sécurité informatique
Portail de la sécurité informatique
Catégories : Programmation informatique | Développement logiciel | Exploit (informatique) | Bogue
Wikimedia Foundation. 2010.