- Double insu
-
Étude randomisée en double aveugle
L'étude avec répartition aléatoire (ou hasardisée[1]) à double insu (ou en double aveugle) est la démarche expérimentale utilisée en recherche médicale et pharmaceutique. Elle est notamment utilisée dans le développement de nouveaux médicaments, et pour évaluer l'efficacité d'une démarche, d'un traitement. Le rôle d'un tel protocole, relativement lourd à mettre en place, est de réduire au mieux l'influence sur la ou les variables mesurées que pourrait avoir la connaissance d'une information (utilisation d'un produit actif ou d'un placebo, par exemple) à la fois sur le patient (premier « aveugle ») et sur l'examinateur (deuxième « aveugle »). C'est la base de la médecine fondée sur les faits.
Sommaire
Historique
L'utilisation des statistiques pour montrer l'efficacité d'un traitement remonte au XIXe siècle : le physicien Pierre-Charles Alexandre Louis (1787—1872) montra que le traitement de la pneumonie par des sangsues n'était pas bénéfique mais délétère[2].
Les premières études en « simple aveugle », le patient ignorant s'il reçoit le vrai traitement ou un placebo, apparaissent dès la fin du XIXe siècle pour prouver la supercherie du magnétisme animal développé par Franz-Anton Mesmer, ainsi que d'autres techniques « magnétiques ». Armand Trousseau (1801-1867) invente les premières pilules placebos, faites à base de mie de pain et démontre ainsi leur équivalence au niveau efficacité avec les médicament homéopathiques[3].
Description : l'exemple de la recherche médicale
Un des problèmes de la recherche médicale est que l'on ne peut pas faire varier un paramètre en laissant les autres constants : la vie est constituée d'un équilibre et la variation d'un paramètre a une répercussion sur les autres (réaction d'équilibrage de l'organisme, homéostasie). Un autre problème est que les personnes réagissent de manières très différentes, et que la réaction d'une personne peut varier selon le moment où est faite l'étude ; certaines personnes guérissent spontanément d'une maladie, d'autres réagissent plus ou moins bien aux médicaments, et par ailleurs, le fait même de prendre un traitement peut parfois avoir des effets bénéfiques ou négatifs même si le traitement lui-même est sans effet (effet placebo). L'idée est de réduire l'influence de la subjectivité des intervenants.
Comme il est impossible de s'affranchir de la diversité humaine, il faut la prendre en compte dans l'étude. On constitue donc deux groupes de patients, l'un prenant un traitement contenant le principe actif (le médicament), l'autre prenant un placebo (traitement sans principe actif, présenté généralement sous la même forme galénique). La répartition principe actif/placebo se fait de manière aléatoire et ni la personne prenant le traitement, ni la personne l'administrant ne savent s'il y a du principe actif (double insu). La levée du voile n'est faite qu'après le traitement statistique.
On ne pourra dire qu'un traitement a de l'effet que si l'on observe une différence statistique significative entre les deux groupes, c'est-à-dire que la probabilité que la différence observée entre les deux traitements soit due uniquement au hasard, est inférieure à un certain seuil fixé. En médecine, ce seuil est très souvent fixé à 5%.
Traitement statistique
Aucun traitement n'est efficace à 100 % (sur tout le monde dans tous les cas). La guérison naturelle n'est pas non plus systématique. Il faut donc étudier un nombre de cas suffisamment important pour pouvoir écarter un biais statistique.
Cas binaire
Plaçons-nous dans un cas « binaire » : la personne guérit ou ne guérit pas. Nous avons donc deux groupes, le groupe « m » qui a reçu le médicament et le groupe « p » qui a reçu le placebo.
Groupes de taille identique
On supposera que chaque groupe comprend n personnes (ils sont de même taille).
Dans le groupe « m », le nombre de personnes ayant guéri est Om (O pour « observé »). Dans le groupe « p », le nombre de personnes ayant guéri est Op. Les taux de guérison respectifs pm et pp sont donc :
- pm = Om /n
- pp = Op /n
Le tableau de résultat est :
Résultats de l'essais en double insu Groupe « m » Groupe « p » Guéris Om Op Non guéris n - Om n - Op On utilise un test du χ² d'indépendance, ou test du χ² de Pearson : on a deux hypothèses
- l'hypothèse dite « nulle », H0 : le médicament n'a aucun effet, le taux de guérison est le même dans les deux groupes, l'écart constaté est dû à un biais statistique ;
- l'hypothèse dite « alternative », H1 : le médicament est efficace, le taux de guérison est supérieur dans le groupe « m » par rapport au groupe « p ».
Selon l'hypothèse nulle, on peut fusionner les deux groupes. On a donc un groupe de 2×n personnes, et un nombre de guérisons égal à Om + Op. Le taux de guérison p0 dans l'hypothèse nulle est donc
- p0 = (Om + Op)/(2×n)
Donc, dans l'hypothèse H0, le nombre de guérisons dans le groupe « m » comme dans le groupe « p » devrait être E (E pour « espéré », ou « expected » en anglais) :
- E = p0×n
On devrait donc avoir le tableau suivant.
Résultats théoriques sous l'hypothèse nulle Groupe « m » Groupe « p » Guéris E E Non guéris n - E n - E Le χ² est la somme, pour toutes les cases du tableau, des différences au carré entre la valeur théorique et la valeur observée, divisées par la valeur théorique :
soit en l'occurrence
Il faut comparer cette valeur à la valeur tabulée, en considérant un risque d'erreur, typiquement 5 %, et le nombre de degrés de liberté, qui est le produit
- (nombre de lignes du tableau - 1)×(nombre de colonnes du tableau - 1),
soit 1 degré de liberté ici. On se place dans le cas d'un test bilatéral, c'est-à-dire que l'on cherche juste à savoir si les valeurs sont différentes ou pas, sans préjuger du sens de la différence.
Loi du χ² à un degré de liberté pour un test bilatéral Erreur admissible (p) 50 %
(p = 0,5)10 %
(p = 0,1)5 %
(p = 0,05)2,5 %
(p = 0,025)1 %
(p = 0,01)0,1 %
(p = 0,001)χ² 0,45 2,71 3,84 5,02 6,63 10,83 Donc, pour un risque d'erreur de 5 % :
- si χ² ≤ 3,84, l'hypothèse H0 est acceptée, on estime que le médicament n'a pas d'effet propre ;
- si χ² > 3,84, l'hypothèse H0 est rejetée, on estime que le médicament a un effet propre (qui peut être bénéfique ou délétère…).
Groupes de tailles différentes
On a maintenant un groupe « m » de taille nm avec Om guérisons, et un groupe « p » de taille np avec Op guérisons. Le tableau des valeurs observées est :
Résultats de l'essais en double insu Groupe « m » Groupe « p » Guéris Om Op Non guéris nm-Om np-Op On a
- p0 = (Om + Op)/(nm + np).
Dans l'hypothèse H0, le nombre de guérisons dans le groupe « m » devrait être Em et le nombre de guérisons dans le groupe « p » devrait être Ep :
- Em = p0×nm
- Ep = p0×np
On devrait donc avoir le tableau suivant.
Résultats théoriques sous l'hypothèse nulle Groupe « m » Groupe « p » Guéris Em Ep Non guéris nm-Em np-Ep Le χ² est :
soit
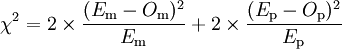 .
.
On compare de même cette valeur à la valeur tabulée pour valider ou invalider l'hypothèse nulle.
- Exemple
- Le groupe « m » a 98 personnes et 19 ont guéri ; le groupe « p » a 101 personnes et 8 ont guéri. On a donc les tableaux suivants :
Résultats de l'essais en double insu Groupe « m » Groupe « p » Guéris 19 8 Non guéris 79 93 - La probabilité dans l'hypothèse nulle est
- p0 = (19 + 8)/(98 + 101) ≅ 0,136
- et les espérances sont
- Em ≅ 13,3
- Ep ≅ 13,7
- le χ² vaut donc
- l'hypothèse nulle est donc rejetée avec un risque d'erreur inférieur à 1 % (p = 0,01), puisque χ² > 6,63 ; on peut estimer que le médicament est efficace.
Nombre de sujets nécessaires
Selon la règle classique, les effectifs théoriques Ei doivent être supérieurs ou égaux à 5 (cf. Test du χ² > Conditions du test). Cela signifie qu'il faut au moins vingt personnes, puisque l'on a quatre classes. Il en faut en fait plus puisque les fréquences sont rarement égales à 0,5.
Si p est la probabilité de l'événement auquel on s'intéresse et n la taille de la population étudiée, alors on estime que l'on doit avoir :
- n×p ≥ 5 et n×(1 - p) ≥ 5
puisque (1 - p) est la fréquence de l'événement complémentaire, soit
- n ≥ 5/p et n ≥ 5/(1 - p)
Paramètre chiffré
Dans certains cas, l'étude ne classe pas les patients dans des groupes guéris/non-guéris, mais mesure un paramètre chiffrable, par exemple la durée de la maladie (en jours), le taux de telle ou telle substance, la valeur de tel paramètre physiologique (par exemple fraction d'éjection ventriculaire gauche, glycémie, …). Cette quantification — ou numérisation — de la maladie est parfois difficile à faire, par exemple dans le cas de la douleur, de la dépression.
Dans ce cas-là, le paramètre est évalué patient par patient. Il en résulte deux ensembles de valeurs, un pour le groupe « m » et un pour le groupe « p ». Ces ensemble de valeurs est en général résumé par deux valeurs, la moyenne Ei et l'écart type σi :
- la moyenne représente la tendance générale du groupe i ;
- l'écart type représente l'étalement des valeurs.
La première question à se poser est la loi que suivent les valeurs au sein d'un groupe. La plupart du temps, on estime qu'elles suivent une loi normale, mais il faut penser à le vérifier.
Cela permet de déterminer les intervalles de confiance : pour chacun des groupes, on détermine les valeurs entre lesquelles on a « la plupart » des patients, par exemple 95 % des patients, ou 99 % des patients. La proportion α de patients incluse dans l'intervalle de confiance est appelée « niveau de confiance » (un niveau de confiance α = 0,99 correspond à 99 % de l'effectif). On utilise pour cela la loi de Student : l'intervalle de confiance est de la forme
- [E - tγni-1·σ ; E + tγni-1·σ]
où tγni-1 est le quantile de la loi de Student pour
- ni -1 degrés de liberté, ni étant l'effectif du groupe i ;
- γ est lié au niveau de confiance α par la formule suivante :
γ = (1-α)/2.
Pour que l'on puisse distinguer les deux groupes, il faut que les espérances Em et Ep soient suffisamment éloignées pour ne pas figurer dans l'intervalle de confiance de l'autre groupe.
Facteur de Student t Effectif (n) Niveau de confiance (α) 50 %
(α = 0,5 ; γ = 0,25)90 %
(α = 0,9 ; γ = 0,05)95 %
(α = 0,95 ; γ = 0,025)99 %
(α = 0,99 ; γ = 0,005)99,9 %
(α = 0,999 ; γ = 0,000 5)5 0,741 2,132 2,776 4,604 8,610 10 0,703 1,833 2,262 3,250 4,781 20 0,688 1,729 2,093 2,861 3,883 50 0,679 1,676 2,009 2,678 3,496 100 0,677 1,660 1,984 2,626 3,390 ∞ 0,674 1,645 1,960 2,576 3,291 - Exemple
- Dans le groupe placebo, on détermine que la maladie guérit en moyenne en dix jours, avec un écart type de 2 jours. Si le groupe comprend 100 personnes, alors l'intervalle de confiance pour un niveau de confiance de 95 % est de 6–14 jours (10 - 2×1,984 ≅ 6, 10 + 2×1,984 ≅ 14). Si la moyenne de la durée de la maladie avec le groupe médicament est inférieure à 6, on peut alors dire que le médicament est efficace avec un risque de 2,5 % d'erreur (puisque les 5 % de cas résiduels du groupe placebo sont répartis de part et d'autre de la moyenne, il y en a 2,5 % en dessous de 6). Il faudrait que la moyenne du groupe médicament soit inférieure à 3 jours pour être sûr avec 0,5 % d'erreur (10 - 2×3,390 ≅ 3).
Pertinence du test
risque alpha : risque de faux négatif
risque bêta : puissance du test (sélectivité entre les deux populations)
Autres champs d'application
Le test en double insu s'applique aussi lorsque l'on veut tester l'efficacité d'un nouveau traitement par rapport à un autre, ce dernier étant alors appelé « traitement de référence » : il s'agit de déterminer si le nouveau traitement proposé est significativement plus efficace que l'ancien.
Le test en double insu est également couramment utilisé en dehors du domaine médical dès lors que l'on souhaite réaliser une étude s'affranchissant des biais de perceptions conscients ou non du sujet testé (préjugés). C'est notamment le cas lors d'études comparatives en marketing ou pour des tests organoleptiques (mesure de la qualité gustative d'un aliment par un jury).
Surveillance
Dans le cadre de la recherche biomédicale, une étude en double aveugle peut amener des difficultés dans la détection d'uns sous-efficacité du traitement testé par rapport à son comparateur, ou d'une fréquence plus élevée des effets indésirables (l'aveugle empêchant de savoir si un groupe de traitement est significativement différent avant la levée d'insu). Dans des essais cliniques où la surveillance apparaît critique (essais multicentriques multinationaux par exemple, où la surveillance peut être complexe), il peut être décidé de constituer un Comité de Surveillance et de Suivi, indépendant du promoteur, qui examine les données (sans levée d'insu) lors d'analyses intermédiaires.
Voir aussi
Articles connexes
- Bonne pratique clinique
- Essai clinique
Notes et références
- ↑ Le terme « hasardisé » est un néologisme recommandé par le GDT de l'OQLF pour remplacer l'anglicisme « randomisé ». Parler d'étude « aléatoire » n'a par contre aucun sens - et même veut dire l'inverse de ce que cela signifie.
- ↑ Le Quotidien du Médecin : toute l'information et la formation médicale continue des médecins généralistes et spécialistes
- ↑ Chamayou G, L'essai « contre placebo » et le charlatanisme, Les génies de la science, février-avril 2009, p14-17
Liens externes
- Méthode et statistiques en médecine, Stéphane Schück, Université de Rennes
- Un problème d'effectif, Opimed
 Portail de la pharmacie
Portail de la pharmacie Portail de la médecine
Portail de la médecine
Catégories : Examen médical | Métrologie | Industrie pharmaceutique | Recherche médicale
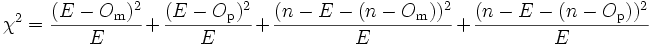
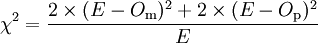
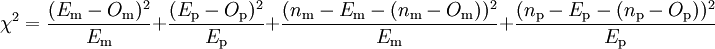
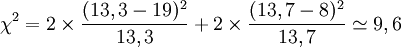
Wikimedia Foundation. 2010.