- Single Instruction Multiple Data
-
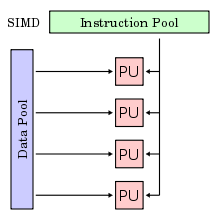 Principe du mode SIMD
Principe du mode SIMD
Single Instruction on Multiple Data, ou SIMD est un des quatre modes de fonctionnement défini par la taxinomie de Flynn et désigne un mode de fonctionnement des ordinateurs dotés de plusieurs unités de calcul fonctionnant en parallèle. Dans ce mode, la même instruction est appliquée simultanément à plusieurs données pour produire plusieurs résultats. On utilise cette abréviation par opposition à SISD (Single Instruction on Single Data), le fonctionnement traditionnel, et MIMD (Multiple Instructions on Multiple Data), le fonctionnement avec plusieurs processeurs indépendants. Le modèle SIMD convient particulièrement bien aux traitements dont la structure est très régulière, comme c'est le cas pour le calcul matriciel.
Les instructions SIMD ont été ajoutées aux processeurs modernes pour pouvoir améliorer la vitesse de traitement sur les calculs impliquant des nombres en virgule flottante. Les instructions SIMD sont composées notamment des jeux d'instructions :
- Sur processeur x86 : MMX, 3DNow!, SSE, SSE2, SSE3, SSSE3 et SSE4
- Sur processeur PowerPC : AltiVec
- Sur processeur ARM : NEON
- Sur processeur SPARC : VIS et VIS2
- Sur processeur MIPS : MDMX et MIPS-3D
Il existe deux types de SIMD :
- Vectorielles (relatif aux données) :
On traite les mêmes instructions en parallèle, puis on passe au calcul suivant lorsque les deux ont fini.
- Parallèles (en voie de disparition car faisait appel à des processeurs spécifiques) :
Dans le cas du SIMD parallèle, on traite une instruction en exécution asynchrone.
Leurs utilisations demandent beaucoup de travail et des connaissances approfondies en programmation, assembleur x86 ou PowerPC, et informatique.
En général, on commence par développer un code générique qui fonctionnera partout. Quand l'algorithme est correct et que le code fonctionne bien, on écrit une version spécialisée pour une extension d'un processeur donné. Les programmes qui sont optimisés avec ce genre d'instructions sont ceux qui demandent beaucoup de ressources processeur : compression de données, codec pour la lecture de son et/ou de vidéo, calcul sur de grands nombres entiers (cryptographie notamment), etc.
Certains compilateurs et certaines bibliothèques permettent de bénéficier de ces optimisations sans coder en assembleur. On peut noter que le projet Mono par exemple profite de ses optimisations processeur si l'on utilise les classes adaptées.
