- Pipeline (informatique)
-
 Cet article concerne l'élément d'un circuit électronique. Pour la conduite destinée à l'acheminement de matière, voir canalisation.
Cet article concerne l'élément d'un circuit électronique. Pour la conduite destinée à l'acheminement de matière, voir canalisation.Un pipeline est un élément d'un circuit électronique dans lequel les données avancent les unes derrière les autres, au rythme du signal d'horloge. Dans la microarchitecture d'un microprocesseur, c'est plus précisément l'élément dans lequel l'exécution des instructions est découpée en étages. Le premier ordinateur à utiliser cette technique est l'IBM Stretch, conçu en 1958.
Sommaire
Concept & Motivation
Le pipeline est un concept s'inspirant du fonctionnement d'une ligne de montage. Considérons que l'assemblage d'un véhicule se compose en trois étapes : Installation du Moteur - Installation du Capot - Dépose des Pneumatiques (dans cet ordre, avec éventuellement des étapes intermédiaires).
Un véhicule dans cette ligne de montage ne peut se trouver que dans une seule position à la fois. Une fois le moteur déposé, le véhicule Y continue pour une installation du capot, laissant le poste "dépose moteur" disponible pour un prochain véhicule X.
Le véhicule Z se fait installer sa pneumatique (Roues) tandis que le second (Y) est à l'étape d'installation du capot. Dans le même temps un véhicule X commence l'étape d'installation du moteur.
Si l'installation du moteur, du capot et des roues prennent respectivement 20, 5 et 10 minutes, alors la réalisation de trois véhicules prendra 105 minutes (1h45) = (20+5+10)x3 = 105.
À l'inverse, en utilisant la ligne de montage (pipeline), le temps total pour accomplir les trois étapes est de 75 minutes (1H15).
Définition
Soit un processeur où 5 cycles sont nécessaires pour accomplir une instruction[1] :
- IF (Instruction Fetch) charge l'instruction à exécuter dans le pipeline.
- ID (Instruction Decode) décode l'instruction et adresse les registres.
- EX (Execute) exécute l'instruction (par la ou les unités arithmétiques et logiques).
- MEM (Memory), dénote un transfert depuis un registre vers la mémoire dans le cas d'une instruction du type STORE (accès en écriture) et de la mémoire vers un registre dans le cas d'un LOAD (accès en lecture).
- WB (Write Back) stocke le résultat dans un registre. La source peut être la mémoire ou bien un registre.
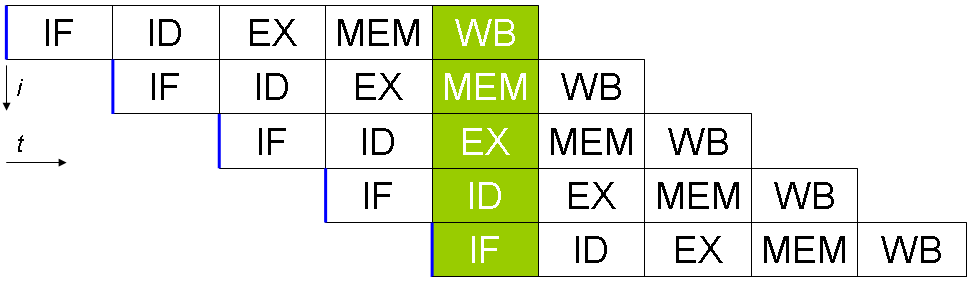
En supposant que chaque étape met 1 cycle d'horloge pour s'exécuter, il faut normalement 5 cycles pour exécuter une instruction, 15 pour 3 instructions :
 Séquençage des instructions dans un processeur sans pipeline. Il faut 15 cycles pour exécuter 3 instructions.
Séquençage des instructions dans un processeur sans pipeline. Il faut 15 cycles pour exécuter 3 instructions.
Si l'on insère des registres tampons (pipeline registers) entre chaque unité à l'intérieur du processeur, celui-ci peut alors contenir plusieurs instructions, chacune à une étape différente.
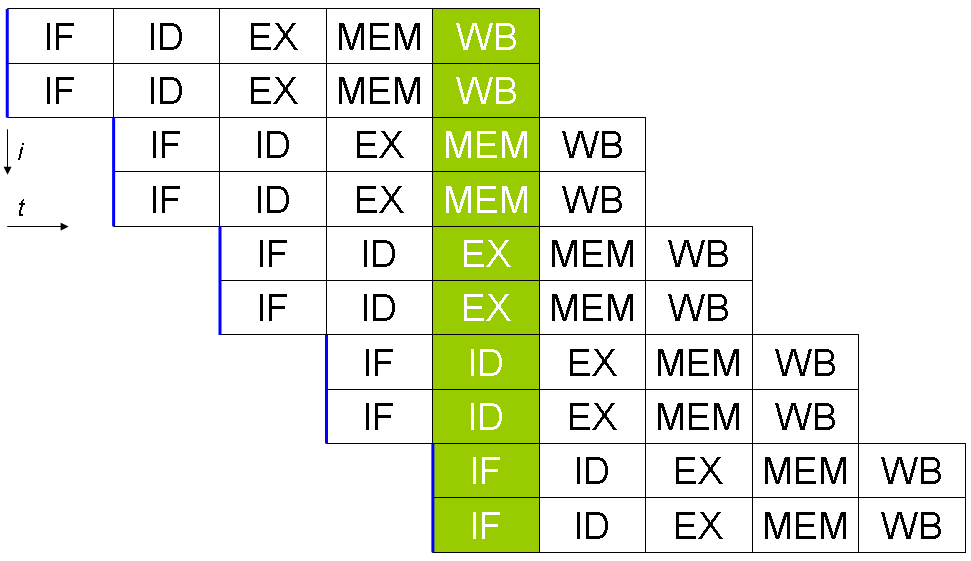
Les 5 instructions s'exécuteront en 9 cycles, et le processeur sera capable de terminer une instruction par cycle à partir de la cinquième, bien que chacune d'entre elles nécessite 5 cycles pour s'exécuter complètement.
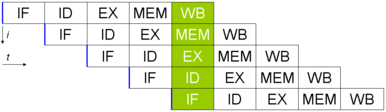 Séquençage des instructions dans un processeur doté d'un pipeline à 5 étages. Il faut 9 cycles pour exécuter 5 instructions. À t = 5, tous les étages du pipeline sont sollicités, et les 5 opérations ont lieu en même temps.
Séquençage des instructions dans un processeur doté d'un pipeline à 5 étages. Il faut 9 cycles pour exécuter 5 instructions. À t = 5, tous les étages du pipeline sont sollicités, et les 5 opérations ont lieu en même temps.Au 5e cycle, tous les étages sont en cours d'exécution.
Architecture superscalaire
Une architecture superscalaire contient plusieurs pipelines en parallèle. Il est possible d'exécuter plusieurs instructions simultanément. Sur un processeur superscalaire de degré 2, deux instructions sont chargées depuis la mémoire simultanément. C'est le cas des processeurs récents conçus pour maximiser la puissance de calcul. Notons toutefois qu'en général, chaque pipeline est spécialisé dans le traitement d'un certain type d'instruction : aussi seules des instructions de types compatibles peuvent être exécutées simultanément.
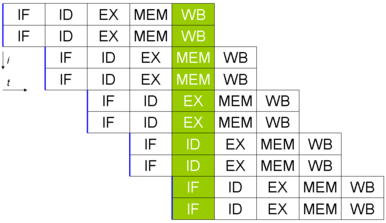 Séquençage des instructions dans un processeur superscalaire de degré 2. Il faut 9 cycles pour exécuter 10 instructions. A t = 5, toutes les unités du processeurs sont sollicitées.
Séquençage des instructions dans un processeur superscalaire de degré 2. Il faut 9 cycles pour exécuter 10 instructions. A t = 5, toutes les unités du processeurs sont sollicitées.Architecture superpipeline
Certaines architectures ont largement augmenté le nombre d'étages, celui-ci pouvant aller jusqu'à 31 pour la microarchitecture Prescott d'Intel. Une telle architecture sera appelée superpipelinée. Voici par exemple le pipeline des premiers Pentium 4, à 20 étages :
 Le Pentium 4 d'Intel est superpipeliné avec un pipeline à 20 étages.
Le Pentium 4 d'Intel est superpipeliné avec un pipeline à 20 étages.Architecture vectorielle
Sur de tels processeurs, une instruction va s'appliquer à un ensemble de données, appelé vecteur. Une seule instruction va donc exécuter la même opération de façon parallèle sur tout le vecteur. Ce genre d'architecture est efficace pour les applications de calcul scientifique et s'est notamment trouvée dans les superordinateurs comme les Cray.
Architecture VLIW
Dans les architectures VLIW (Very Long Instruction Word, ou Mot d'instruction très long), l'instruction va contenir les opérations pour chaque unité de calcul disponible dans le processeur. De ce fait chaque instruction peut être définie sur 256 bits, voire plus (512, 1024,...).
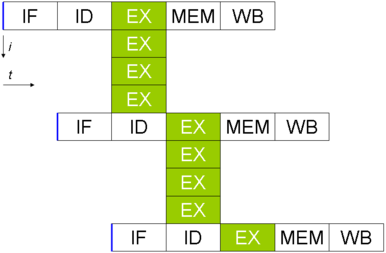 Sur les architectures à mot d'instruction très long, plusieurs unité de calcul sont sollicitées par des champs situés dans l'instruction.
Sur les architectures à mot d'instruction très long, plusieurs unité de calcul sont sollicitées par des champs situés dans l'instruction.Quelques profondeurs de pipeline
Aujourd'hui tous les microprocesseurs sont pipelinés :
Processeur Profondeur du pipeline Intel Pentium 4 Prescott 31 Intel Pentium 4 20 AMD K10 16 IBM POWER5 16 IBM PowerPC 970 16 Intel Core 2 Duo 14 Intel Pentium II 14 Sun UltraSPARC IV 14 Sun UltraSPARC IIi 14 AMD Opteron 1xx 12 AMD Athlon 12 IBM POWER4 12 Intel Pentium III 10 Intel Itanium 10 MIPS R4400 8 Motorola PowerPC G4 7 Problèmes
Les pipelines provoquent de nouveaux problèmes, en particulier d'interdépendance, ils ne sont pas tous listés ci dessous, juste deux cas simples sont abordés.
Interdépendance des données
Une instruction ne peut récupérer le résultat de la précédente car celui-ci n'est pas encore disponible. Ainsi, la séquence :
ADD R1, R2, R3 // R1 = R2 + R3 STORE R1, 1000 // C(1000) = R1
Ne stocke pas à l'emplacement mémoire 1000 la valeur de R1 contenant la somme R2 + R3, mais la valeur de R1 contenue avant l'instruction ADD. Pour résoudre ce problème particulier, il est parfois possible de créer des courts-circuits pour amener le résultat de l'étape précédente vers l'unité qui en a besoin directement, sans passer par les registres de pipeline.
Interdépendance procédurale
Se pose le même problème avec les sauts :
MOV R1, #1000 // R1 = 1000 JUMP R1 // Saut inconditionnel
R1 ne contient pas encore la valeur 1000 au moment où l'instruction de saut va s'exécuter.
Une solution possible à ces deux problèmes est d'insérer une instruction entre les deux qui sont interdépendantes. Prenons par exemple la séquence suivante :
1: A = B + C 2: D = A + C 3: E = F + B
qui comporte une dépendance directe simple, A ne pouvant être disponible pour la partie droite de la seconde instruction.
- la première solution, triviale, est d'insérer des NOP (No Operation), c'est ce que font les compilateurs quand on ne précise pas d'option d'optimisation du code :
1: A = B + C 1b: NOP 2: D = A + C 3: E = F + B
- la seconde solution consiste à réarranger les instructions. Dans cet exemple, l'opération de la ligne 3 n'a aucune interdépendance avec les deux précédentes. Le code modifié sera :
1: A = B + C 2: E = F + B 3: D = A + C
Notes et références
- Les étages IF, ID, EX, MEM et WB sont ceux de l'exemple classique du DLX présenté dans Computer Architecture, A Quantitative Approach
Voir aussi
Liens internes



Wikimedia Foundation. 2010.