- Processus de décision markovien
-
Un processus de décision markovien (MDP) est un modèle stochastique issu de la théorie de la décision et de la théorie des probabilités. Le modèle MDP peut être vu comme une chaîne de Markov à laquelle on ajoute une composante décisionnelle. Comme les autres modèles de sa famille, il est entre autres, utilisé en intelligence artificielle pour le contrôle de systèmes complexes comme des agents intelligents.
Un MDP permet de prendre des décisions dans un environnement
- lorsque l'on a une certitude sur l'état dans lequel on se trouve
- en présence d'incertitude sur l'effet des actions.
Sommaire
Définition
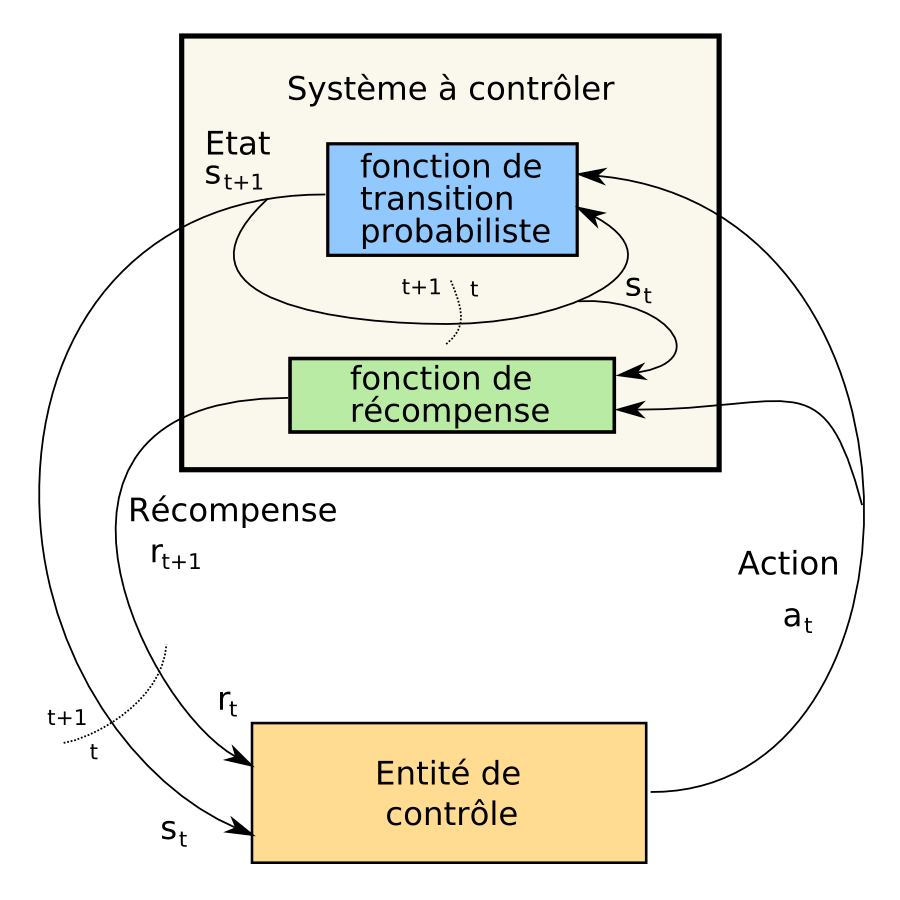
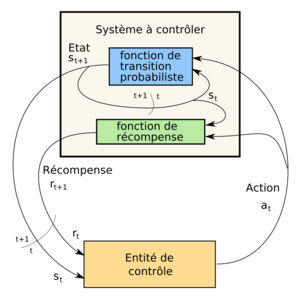 Cycle de contrôle d'un processus de décision markovien
Cycle de contrôle d'un processus de décision markovien
Définition intuitive
Afin de comprendre ce qu'est un MDP, supposons que l'on ait un système évoluant dans le temps comme un automate probabiliste. À chaque instant le système est dans un état donné et il existe une certaine probabilité pour que le système évolue vers tel ou tel autre état à l'instant suivant en effectuant une transition.
Supposons maintenant que l'on doive contrôler ce système boite noire de la meilleure façon possible. L'objectif est de l'amener dans un état considéré comme bénéfique, en évitant de lui faire traverser des états néfastes. Pour cela, on dispose d'un ensemble d'actions possibles sur le système. Pour compliquer la chose, on supposera que l'effet de ces actions sur le système est probabiliste : l'action entreprise peut avoir l'effet escompté ou un tout autre effet. L'efficacité du contrôle est mesurée relativement au gain ou à la pénalité reçue au long de l'expérience.
Ainsi, un raisonnement à base de MDP peut se ramener au discours suivant : étant dans tel cas et choisissant telle action, il y a tant de chance que je me retrouve dans tel nouveau cas avec tel gain.
Pour illustrer les MDP, on prend souvent des exemples issus de la robotique mobile (avec les positions pour états, les commandes comme actions, les mouvements comme transitions et l'accomplissement/échec de tâches comme gains/pénalités).
Hypothèse de Markov
Dans les MDP, l'évolution du système est supposée correspondre à un processus markovien. Autrement dit, le système suit une succession d'états distincts dans le temps et ceci en fonction de probabilités de transitions. L'hypothèse de Markov consiste à dire que les probabilités de transitions ne dépendent que des n états précédents. En général, on se place à l'ordre n = 1, ce qui permet de ne considérer que l'état courant et l'état suivant.
Définition formelle
Un MDP est un quadruplet
 où :
où : est l'ensemble fini discret des états possibles du système à contrôler
est l'ensemble fini discret des états possibles du système à contrôler est l'ensemble fini discret des actions que l'on peut effectuer pour contrôler le système
est l'ensemble fini discret des actions que l'on peut effectuer pour contrôler le système![T : S \times A \times S \to [ 0 ; 1 ]\,](c/64c38c1ee083ccc77479e8a038aa3c6b.png) est la fonction de transition du système en réaction aux actions de contrôle.
est la fonction de transition du système en réaction aux actions de contrôle.
Dans le cas général, la fonction T est probabiliste et donne la probabilité
 que le système passe de l'état s à l'état s' lorsque l'on choisit d'effectuer l'action a.
que le système passe de l'état s à l'état s' lorsque l'on choisit d'effectuer l'action a. est la fonction de récompense. Elle indique la valeur réelle obtenue lorsque l'on effectue l'action a dans l'état s pour arriver dans l'état s'.
est la fonction de récompense. Elle indique la valeur réelle obtenue lorsque l'on effectue l'action a dans l'état s pour arriver dans l'état s'.
Exemple de MDP
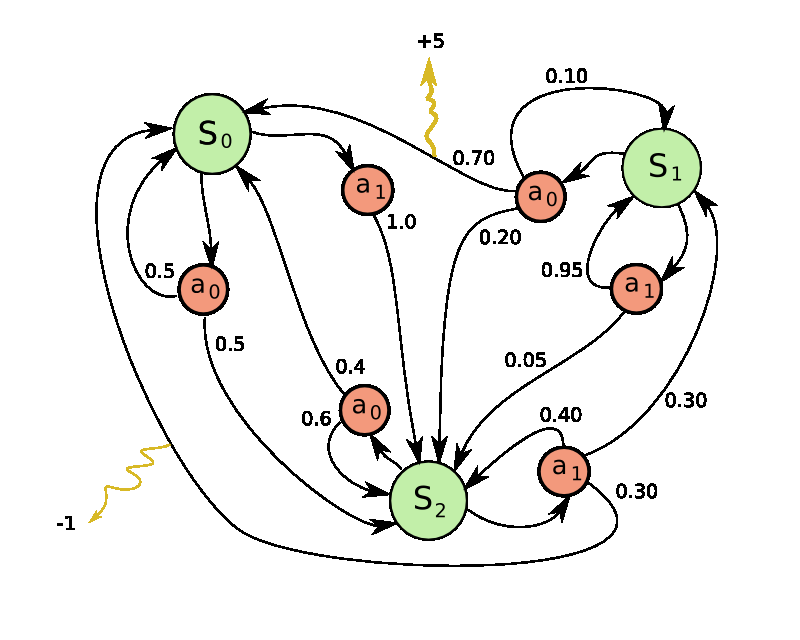
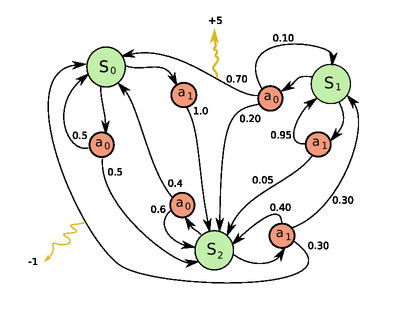 Exemple simple de Processus de Décision Markovien à trois états et à deux actions.
Exemple simple de Processus de Décision Markovien à trois états et à deux actions.L'exemple donné ci-contre représente un Processus de Décision Markovien à trois états distincts {S0,S1,S2} représentés en vert. Depuis chacun des états, on peut effectuer une action de l'ensemble {a0,a1}. Les nœuds rouges représentent donc une décision possible (le choix d'une action dans un état donné). Les nombres indiqués sur les flèches sont les probabilités d'effectuer la transition à partir du nœud de décision. Enfin, les transitions peuvent générer des récompenses (dessinées ici en jaune).
- La matrice de transition associée à l'action a0 est la suivante :

- La matrice de transition associée à l'action a1 est la suivante :

En ce qui concerne les récompenses,
- on perçoit une récompense de +5 lorsque l'on passe de l'état S1 à l'état S0 en accomplissant l'action a0
- on perçoit une récompense de -1 (aussi appelée pénalité) lorsque l'on passe de l'état S2 à l'état S0 en accomplissant l'action a1
Remarques
Le modèle MDP présenté ici est supposé stable dans le temps, c'est-à-dire que les composants du quadruplet sont supposés invariants. Il n'est donc pas applicable en l'état pour un système qui évolue, par exemple pour modéliser un système qui apprend contre un autre agent.
Notion de politique
Dans le cadre des MDP, la politique
 est une suite qui indique pour chaque état quelle est l'action à effectuer. Il s'agit là d'une politique déterministe, dans laquelle il n'y a pas d'ambiguïté sur l'action à effectuer. On note Π l'ensemble des politiques déterministes.
est une suite qui indique pour chaque état quelle est l'action à effectuer. Il s'agit là d'une politique déterministe, dans laquelle il n'y a pas d'ambiguïté sur l'action à effectuer. On note Π l'ensemble des politiques déterministes.Note : Il est possible d'introduire du hasard dans le choix de l'action, comme si on tirait aléatoirement l'action à effectuer. Dans ce cas, on parlera de politique stochastique
![\pi : S \times A \to [ 0 ; 1 ]](0/bf0970a3f4cd80cd61fda8c78d162aaf.png)
Problèmes possibles
- Planification : Il s'agit, étant donné un MDP {S,A,T,R} de trouver quelle est la politique π qui maximise la récompense,
- Améliorer une politique connue : Soit une politique π0, on souhaite trouver une meilleure politique,
- Apprentissage d'une politique sans connaitre le modèle
- à partir de traces d'exécution
- au cours d'expériences sur le modèle
Articles connexes
Voir aussi :
- Les chaînes de Markov, dont dérivent les MDP,
- Les processus de décision markoviens partiellement observables (POMDP), qui permettent de modéliser également l'incertitude sur l'état dans lequel on se trouve et
- Le calcul stochastique, qui est à la base les modèles stochastiques
- L'apprentissage par renforcement, méthode permettant de résoudre des processus de décision markoviens.
- Les métaheuristiques, méthodes utilisant parfois des processus markoviens.
Références
- (Putterman 1994) Putterman M. L., Markov Decision Proceses. Discrete stochastic dynamic programming. Wieley-Interscience, New York 1994.
- (Sutton et Barto 1998) Sutton R. S. et Barto A.G. Reinforcement Learning: An introduction. MIT Press, Cambridge, MA, 1998.
Wikimedia Foundation. 2010.