- POMDP
-
Processus de décision markovien partiellement observable
Un Processus de décision markovien partiellement observable (POMDP) est un modèle stochastique issu de la théorie de la décision et de la théorie des probabilités. Les modèles de cette famille sont, entre autres, utilisés en intelligence artificielle pour le contrôle de systèmes complexes comme des agents intelligents.
Ce modèle est dérivé des Processus de décision markoviens (MDP). La différence est que, dans un POMDP, l'incertitude est double. Non seulement l'effet des actions que l'on entreprend est incertain, mais de plus, on ne dispose que d'indices pour connaitre l'état dans lequel on se trouve, et donc pour décider. Ces indices sont appelés des observations et en ce sens, les POMDP sont des Modèles de Markov Cachés (HMM) particuliers, dans lesquels on dispose d'actions probabilistes.
Sommaire
Définition formelle
Un POMDP est un tuple
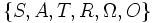 où :
où : est l'ensemble fini discret des états possibles du système à contrôler (il s'agit des états cachés du processus).
est l'ensemble fini discret des états possibles du système à contrôler (il s'agit des états cachés du processus). est l'ensemble fini discret des actions que l'on peut effectuer pour contrôler le système
est l'ensemble fini discret des actions que l'on peut effectuer pour contrôler le système![T : S \times A \times S \to [ 0 ; 1 ]\,](/pictures/frwiki/54/64c38c1ee083ccc77479e8a038aa3c6b.png) est la fonction de transition du système en réaction aux actions de contrôle. Dans le cas général, la fonction T est probabiliste et donne la probabilité
est la fonction de transition du système en réaction aux actions de contrôle. Dans le cas général, la fonction T est probabiliste et donne la probabilité 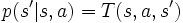 que le système passe de l'état s à l'état s' lorsque l'on choisit d'effectuer l'action a.
que le système passe de l'état s à l'état s' lorsque l'on choisit d'effectuer l'action a.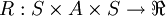 est la fonction de récompense. Elle indique la valeur réelle obtenue lorsque l'on effectue l'action a dans l'état s et que l'on arrive dans l'état s'.
est la fonction de récompense. Elle indique la valeur réelle obtenue lorsque l'on effectue l'action a dans l'état s et que l'on arrive dans l'état s'. est un ensemble de symboles que l'on peut observer.
est un ensemble de symboles que l'on peut observer.![O : S \times \Omega \to [0;1]](/pictures/frwiki/49/12a9ca4366b903cdc02acc6692f3abf7.png) est une fonction d'observation qui à un état donné associe la probabilité
est une fonction d'observation qui à un état donné associe la probabilité 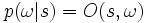 d'observer un symbole donné.
d'observer un symbole donné.
Note : Il existe des variantes dans les quelles les récompenses peuvent dépendre des actions ou des observations. Les observations peuvent également dépendre des actions effectuées.
Approches
Il existe deux grands types d'approches pour s'attaquer à un problème POMDP.
- On peut chercher à déterminer de la façon la plus certaine possible quel est l'état dans lequel on se trouve (en maintenant à jour une distribution de probabilité sur les états appelée belief-state)
- On peut travailler directement sur les observations [2] de Ω sans considérer l'état caché. Cela n'est pas sans poser de problèmes car des observations similaires peuvent être obtenues dans des états différents (par exemple, avec l'observation locale des carrefours dans un labyrinthe, on peut très bien tomber sur deux carrefours en forme de T). Une approche possible pour discriminer ces observations consiste à garder une mémoire des observations rencontrées par le passé (dans ce cas, on perd la propriété markovienne).
Articles connexes
- Les Processus de Décision Markoviens (MDP), dont dérivent les POMDP pour l'aspect décision,
- Modèle de Markov caché, dont dérivent les POMDP pour l'aspect observabilité partielle,
- Processus stochastique
Références
- Kaebling L. P., Littman M. L., Cassandra A. R., Planning and Acting in Partially Observable Stochastic Domains, Artificial Intelligence, vol. 101, num. 1–2, pp. 99-134, 1998.
- McCallum A. K., Reinforcement learning with selective perception and hidden state, PhD thesis, University of Rochester, Computer Science Dept., 1996.
Liens externes
- Tony's POMDP Page est une page de ressources d'Anthony R. Cassandra
- POMDP information page, la page de ressources de Michael L. Littman
Catégories : Intelligence artificielle | Processus stochastique
Wikimedia Foundation. 2010.