- Apprentissage Par Renforcement
-
Apprentissage par renforcement
L'apprentissage par renforcement fait référence à une classe de problèmes d'apprentissage automatique, dont le but est d'apprendre, à partir d'expériences, ce qu'il convient de faire en différentes situations, de façon à optimiser une récompense numérique au cours du temps.
Un paradigme classique pour présenter les problèmes d'apprentissage par renforcement consiste à considérer un agent autonome, plongé au sein d'un environnement, et qui doit prendre des décisions en fonction de son état courant. En retour, l'environnement procure à l'agent une récompense, qui peut être positive ou négative.
L'agent cherche, au travers d'expériences itérées, un comportement décisionnel (appelé stratégie ou politique, et qui est une fonction associant à l'état courant l'action à exécuter) optimal, en ce sens qu'il maximise la somme des récompenses au cours du temps.
Sommaire
Historique et lien avec la biologie
Parmi les premiers algorithmes d'apprentissage par renforcement, on compte le TD-learning, proposé par Richard Sutton en 1988[1], et le Q-learning[2] mis au point essentiellement lors d'une thèse soutenue en 1989 et publié réellement en 1992[3].
Toutefois, l'origine de l'apprentissage par renforcement est plus ancienne. Elle dérive de formalisations théoriques de méthodes de contrôle optimal, visant à mettre au point un contrôleur permettant de minimiser au cours du temps une mesure donnée du comportement d'un système dynamique. La version discrète et stochastique de ce problème est appelée un processus de décision markovien et fut introduite par Bellman en 1957[4].
D'autre part, la formalisation des problèmes d'apprentissage par renforcement s'est aussi beaucoup inspirée de théories de psychologie animale, comme celles analysant comment un animal peut apprendre par essais-erreurs à s'adapter à son environnement. Ces théories ont beaucoup inspiré le champ scientifique de l'intelligence artificielle et ont beaucoup contribué à l'émergence d'algorithmes d'apprentissage par renforcement au début des années 1980.
En retour, le raffinement actuel des algorithmes d'apprentissage par renforcement inspire les travaux des neurobiologistes et des psychologues pour la compréhension du fonctionnement du cerveau et du comportement animal. En effet, la collaboration entre neurobiologistes et chercheurs en intelligence artificielle a permis de découvrir qu'une partie du cerveau fonctionnait de façon très similaire aux algorithmes d'apprentissage par renforcement tels que le TD-learning[5]. Il semblerait ainsi que la nature ait découvert, au fil de l'évolution, une façon semblable à celles trouvées par des chercheurs pour optimiser la façon dont un agent ou organisme peut apprendre par essais-erreurs. Ou plutôt, les chercheurs en intelligence artificielle ont redécouvert en partie ce que la nature avait mis des millions d'années à mettre en place. En effet, la zone du cerveau qui montre des analogies avec les algorithmes d'apprentissage par renforcement s'appelle les ganglions de la base, dont une sous-partie appelée la substance noire émet un neuromodulateur, la dopamine, qui renforce chimiquement les connexions synaptiques entre les neurones. Ce fonctionnement des ganglions de la base a été identifié comme existant chez l'ensemble des vertébrés[6], et on retrouve le même genre de résultats en imagerie médicale chez l'homme[7].
Enfin, la boucle d'échange scientifique entre neurobiologistes, psychologues et chercheurs en intelligence artificielle n'est pas terminée puisque actuellement, des chercheurs prennent inspiration du cerveau pour raffiner les algorithmes d'apprentissage par renforcement et essayer ainsi de mettre au point des robots plus autonomes et adaptatifs que ceux existants[8]. En effet, même si la nature et les chercheurs semblent avoir trouvé séparément une même solution pour résoudre certains types de problèmes tels que ceux décrits au paragraphe précédent, on se rend bien compte que l'intelligence des robots actuels est encore bien loin de celle de l'homme ou même de celle de nombreux animaux tels que les singes ou les rongeurs. Une voie prometteuse pour pallier cela est d'analyser plus en détails comment le cerveau biologique paramétrise et structure anatomiquement des processus tels que l'apprentissage par renforcement, et comment il intègre ces processus avec d'autres fonctions cognitives telles que la perception, l'orientation spatiale, la planification, la mémoire, et d'autres afin de reproduire cette intégration dans le cerveau artificiel d'un robot[9].
Formalisme
Formellement, la base du modèle d'apprentissage par renforcement consiste en:
1. un ensemble d'états S de l'agent dans l'environnement;
2. un ensemble d'actions A que l'agent peut effectuer;
3. un ensemble de valeurs scalaires "récompenses" R que l'agent peut obtenir.À chaque pas de temps t de l'algorithme, l'agent perçoit son état
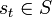 et l'ensemble des actions possibles A(st). Il choisit une action
et l'ensemble des actions possibles A(st). Il choisit une action 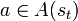 et reçoit de l'environnement un nouvel état st + 1 et une récompense rt + 1 (qui est nulle la plupart du temps et vaut classiquement 1 dans certains états clefs de l'environnement). Fondé sur ces interactions, l'algorithme d'apprentissage par renforcement doit permettre à l'agent de développer une politique
et reçoit de l'environnement un nouvel état st + 1 et une récompense rt + 1 (qui est nulle la plupart du temps et vaut classiquement 1 dans certains états clefs de l'environnement). Fondé sur ces interactions, l'algorithme d'apprentissage par renforcement doit permettre à l'agent de développer une politique 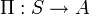 qui lui permette de maximiser la quantité de récompenses. Cette dernière s'écrit
qui lui permette de maximiser la quantité de récompenses. Cette dernière s'écrit 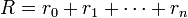 dans le cas des processus de décision markoviens (MDP) qui ont un état terminal, où R = Σt γt rt pour les MDPs sans état terminal (où γ est un facteur de dévaluation compris entre 0 et 1 et permettant, selon sa valeur, de prendre en compte les récompenses plus ou moins loin dans le futur pour le choix des actions de l'agent).
dans le cas des processus de décision markoviens (MDP) qui ont un état terminal, où R = Σt γt rt pour les MDPs sans état terminal (où γ est un facteur de dévaluation compris entre 0 et 1 et permettant, selon sa valeur, de prendre en compte les récompenses plus ou moins loin dans le futur pour le choix des actions de l'agent).Ainsi, la méthode de l'apprentissage par renforcement est particulièrement adapté aux problèmes nécessitant un compromis entre la quête de récompenses à court terme et celle de récompenses à long terme. Cette méthode a été appliquée avec succès à des problèmes variés, tels que le contrôle robotique, le pendule inversé, la planification de tâches, les télécommunications, le backgammon et les échecs.
Algorithme
On donne ici une version algorithmique basique de l'apprentissage par renforcement, particulièrement du TD-learning. Cette version a pour but de permettre au lecteur intéressé de faire une rapide implémentation informatique de l'algorithme afin d'en mieux comprendre le fonctionnement itératif. On se place ici dans le cas le plus simple où on ne cherche pas à améliorer le comportement (ou politique) de l'agent, mais on cherche à évaluer une politique donnée lorsqu'elle est mise en œuvre par un agent dans un environnement donné.
- On initialise V(s) aléatoirement, qui est la valeur que l'agent attribuera à chaque état s.
- On initialise la politique π à évaluer.
- On répète (pour chaque épisode) :
- On initialise s
- On répète (à chaque pas de temps de l'épisode) :
- a ← action donnée par π pour s
- L'agent effectue l'action a; on observe la récompense r et l'état suivant s'
- V(s) ← V(s) + α [r + γV(s') - V(s)]
- s ← s'
- Jusqu'à ce que s soit terminal
Pour plus de détails concernant l'implémentation de cet algorithme, ou concernant la version algorithmique du Q-learning, se référer au livre de Sutton et Barto publié en 1998[10], dont la totalité du contenu est disponible librement sur Internet (voir le lien externe à la fin de cet article).
Références
- ↑ Sutton, R.S. (1988). Learning to predict by the method of temporal differences. Machine Learning, 3:9-44.
- ↑ Voir Machine Learning, pp. 373-380
- ↑ Watkins, C.J.C.H. & Dayan, P. (1992). Q-learning. Machine Learning, 8:279-292.
- ↑ Bellman, R.E. (1957). A Markov decision process. Journal of Mathematical Mech., 6:679-684.
- ↑ Houk, J.C., Adams, J.L. & Barto, A.G. (1995). A Model of how the Basal Ganglia generate and Use Neural Signals That Predict Reinforcement. In Houk et al. (Eds), Models of Information Processing in the Basal Ganglia. The MIT Press, Cambridge, MA.
- ↑ Redgrave, P., Prescott, T.J. & Gurney, K. (1999). The basal ganglia: a vertebrate solution to the selection problem? Neuroscience, 89, 1009-1023.
- ↑ O’Doherty, J., Dayan, P., Schultz, J., Deichmann, R., Friston, K. & Dolan, R. (2004). Dissociable Roles of Dorsal and Ventral Striatum in Instrumental Conditioning. Science, 304:452-454.
- ↑ Khamassi, M., Lachèze, L., Girard, B., Berthoz, A. & Guillot, A. (2005). Actor-critic models of reinforcement learning in the basal ganglia: From natural to artificial rats. Adaptive Behavior, Special Issue Towards Artificial Rodents, 13(2):131-148.
- ↑ Meyer, J.-A., Guillot, A., Girard, B., Khamassi, M., Pirim, P. & Berthoz, A. (2005). The Psikharpax project: Towards building an artificial rat. Robotics and Autonomous Systems, 50(4):211-223.
- ↑ Sutton, R.S. & Barto, A.G. (1998). Reinforcement Learning:An Introduction. The MIT Press Cambridge, MA.
Bibliographie
- (en)Tom M. Mitchell, Machine Learning, 1997 [détail des éditions], chap. 13 Reinforcement Learning, p. 367-390
Liens externes
- Reinforcement Learning: An Introduction Version complète en HTML de l'ouvrage de référence de R.S. Sutton et A.G. Barto en 1998.
Catégorie : Apprentissage automatique - On initialise V(s) aléatoirement, qui est la valeur que l'agent attribuera à chaque état s.
Wikimedia Foundation. 2010.