- Indice de coincidence
-
Indice de coïncidence
L'indice de coïncidence est une technique de cryptanalyse inventée par William F. Friedman en 1920 et publiée dans The Index of Coincidence and its Applications in Cryptography.
L'indice permet de savoir si un texte a été chiffré avec un chiffre mono-alphabétique ou un chiffre poly-alphabétique en étudiant la probabilité de répétition des lettres du message chiffré. Il donne également une indication sur la longueur de la clé probable.
L'indice se calcule avec la formule suivante :
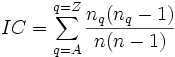 avec n le nombre de lettres total du message, nA le nombre de A, nB le nombre de B, etc.
avec n le nombre de lettres total du message, nA le nombre de A, nB le nombre de B, etc.En français, l'indice de coïncidence vaut environ 0,0746. Dans le cas de lettres uniformément distribuées (contenu aléatoire sans biais), l'indice se monte à 0,0385. L'indice ne varie pas si une substitution monoalphabétique des lettres a été opérée au préalable. C’est-à-dire que si l'on remplace par exemple 'a' par 'z' et 'z' par 'a', l'indice ne changera pas.
Sommaire
Indice de coïncidence pour les chiffrements polyalphabétiques
Dans le cas où plusieurs alphabets seraient utilisés mais que le nombre d'alphabets est inconnu, l'indice de coïncidence peut être un précieux allié pour déterminer ce nombre. On utilise alors la formule suivante :
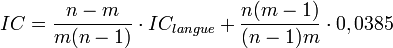 avec n le nombre total de lettres dans le message, m le nombre d'alphabets, IClangue l'indice pour la langue analysée et 0.0385 est un terme correspondant à un contenu uniformément distribué. En variant m, on peut comparer l'indice obtenu avec cette formule avec l'indice réel provenant de la formule classique.
avec n le nombre total de lettres dans le message, m le nombre d'alphabets, IClangue l'indice pour la langue analysée et 0.0385 est un terme correspondant à un contenu uniformément distribué. En variant m, on peut comparer l'indice obtenu avec cette formule avec l'indice réel provenant de la formule classique.Raisonnement mathématique
Soit un alphabet de 26 lettres, un texte de longueur infinie et un tirage au sort aléatoire, sans biais. La chance d'obtenir une lettre donnée est de 1/26. Obtenir deux lettres identiques se monte à une probabilité de (1/26)2. La probabilité d'obtenir une paire de deux lettres identiques est de l'ordre de : 26*(1/26)2 = (1/26) = 0,0385 (La première lettre est tirée au hasard, la seconde a une probablilité de 1/26 d'être identique). C'est l'indice de coïncidence pour un message avec des lettres uniformément distribuées.
Introduisons maintenant un biais dans la distribution et raisonnons sur un texte de longueur finie. Nous avons un texte de 100 lettres et le nombre d'unités pour chaque lettre n'est pas identique. Disons que nous avons 20 lettres « A », 5 lettres « B », 7 lettres « C », ..., et un seul « Z ». Dans ce cas, la chance de trouver une paire quelconque de lettres identiques est : (20/100)*(19/99) + (5/100)*(4/99) + (7/100)*(6/100) + ... + (1/100)*(0/99). Nous avons alors une approximation de l'indice de coïncidence pour un langage qui suit cette distribution.
Autres langues
On peut aussi obtenir une estimation de la langue utilisée dans un texte en regardant son indice de coïncidence, la distribution des lettres n'étant pas la même entre les langues. Les indices peuvent légèrement varier selon les sources et les textes considérés pour l'analyse. Friedman donne par exemple un indice de 0,0778 pour le français.
Langue Indice Français 0,0778 Anglais 0,0667 Allemand 0.0762 Espagnol 0,0770 Russe 0,0529 Italien 0,0738 Danois 0,0707 Néerlandais 0,0798 Finnois 0,0737 Grec 0,0691 Hébreu 0,0768 Japonais 0,0772 Malaysien 0,0852 Norvégien 0,0694 Portugais 0,0745 Serbe 0,0643 Suédois 0,0644 Arabe 0,0758 Esperanto 0,0690 Exemple d'utilisation
L'indice est très utile lors de la vérification automatique d'un déchiffrement, en particulier lors d'une recherche exhaustive de toutes les clés. Dans leur excellent dossier sur la machine Enigma, Guillaume Munch-Macagnoni et Julien Milli donnent un exemple concret d'utilisation de l'indice pour repérer la configuration de rotors la plus probable[1]. Les configurations incorrectes fournissent un indice d'environ 0,0386, ce qui est très proche de l'indice de données aléatoires uniformément distribuées. La configuration probable, quant à elle, donne un indice de 0,0648. On peut vraisemblablement supposer qu'il s'agit des bons paramètres. Cet exemple est d'autant plus intéressant qu'Enigma est en partie polyalphabétique via un tableau de substitution. L'indice trouvé est ainsi inférieur à celui d'une langue comme l'allemand ou le français. Avec une analyse un peu plus poussée soit manuelle ou automatique, on peut retrouver les substitutions les plus probables en tentant de maximiser l'indice de coïncidence et s'approcher de 0,075.
Un tel procédé peut être utilisé sur tous les types de chiffrement lors d'une attaque automatisée.
Voir aussi
Notes et références
- ↑ Dossier sur Enigma, chapitre 6
Liens externes
- (fr) http://jf.morreeuw.free.fr/vigenere/vigenere.html sur le déchiffrement du chiffre de Vigenère.
- (fr) http://www.apprendre-en-ligne.net/crypto/stat/ic.html
Articles connexes
 Portail de la cryptologie
Portail de la cryptologie
Catégorie : Cryptanalyse
Wikimedia Foundation. 2010.