- Index et distance de Jaccard
-
Indice et distance de Jaccard
L'indice et la distance de Jaccard sont deux métriques utilisées en statistiques pour comparer la similarité et la diversité entre des échantillons. Elles sont nommées d'après le botaniste suisse Paul Jaccard.
Sommaire
Description formelle
L'indice de Jaccard (ou coefficient de Jaccard) est le rapport entre la cardinalité (la taille) de l'intersection des ensembles considérés et la cardinalité de l'union des ensembles. Il permet d'évaluer la similarité entre les ensembles. Soit deux ensembles A et B, l'indice est :
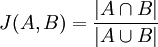 .
.
L'extension à n ensembles est triviale :
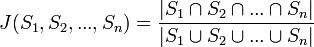 .
.
La distance de Jaccard mesure la dissimilarité entre les ensembles. Elle consiste simplement à soustraire l'indice de Jaccard à 1.
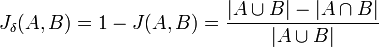 .
.
De la même manière que pour l'indice, la généralisation devient :
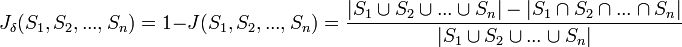 .
.
Similarité entre des ensembles binaires
L'indice de Jaccard est utile pour étudier la similarité entre des objets constitués d'attributs binaires.
Soit deux séquences A et B, chacune avec n attributs binaires. Chaque attribut peut être à 0 ou 1. On a ainsi :
On définit plusieurs quantités qui caractérisent les deux ensembles :
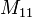 représente le nombre d'attributs qui valent 1 dans A et dans B
représente le nombre d'attributs qui valent 1 dans A et dans B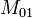 représente le nombre d'attributs qui valent 0 dans A et 1 dans B
représente le nombre d'attributs qui valent 0 dans A et 1 dans B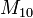 représente le nombre d'attributs qui valent 1 dans A et 0 dans B
représente le nombre d'attributs qui valent 1 dans A et 0 dans B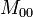 représente le nombre d'attributs qui valent 0 dans A et dans B
représente le nombre d'attributs qui valent 0 dans A et dans B
Chaque paire d'attributs doit nécessairement appartenir à l'une des quatre catégories, de telle sorte que :
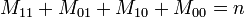 .
.
L'indice de Jaccard devient :
La distance de Jaccard devient:
Exemple
Voir aussi
Références
- Pang-Ning Tan, Michael Steinbach and Vipin Kumar, Introduction to Data Mining (2005), ISBN 0-321-32136-7
- Paul Jaccard (1901) Bulletin de la Société Vaudoise des Sciences Naturelles 37, 241-272.
- Tanimoto, T.T. (1957) IBM Internal Report 17th Nov. 1957.
Liens externes
- (en) indice de Jaccard et diversité entre espèces
- (en) Exemple de coefficient de Jaccard
- (en) Introduction à la fouille de données
- (en) SimMetrics, une implémentation des métriques de similarité
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Probabilités | Statistiques
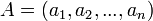
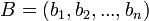
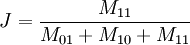
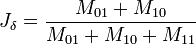
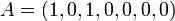
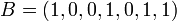
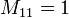
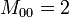
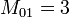
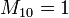
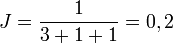
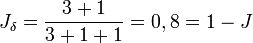
Wikimedia Foundation. 2010.