- Décodage Par Syndrome
-
Décodage par syndrome
 Pour les articles homonymes, voir syndrome (homonymie).
Pour les articles homonymes, voir syndrome (homonymie).Le décodage par syndrome est une méthode de décodage destinée aux codes linéaires. Il utilise une table, appelée tableau standard, pour effectuer le décodage. Il est utilisable lorsque la redondance du code n'est pas trop grande : la taille de la table est exponentielle en la redondance.
Le principe est le suivant : à la réception d'un mot x, la matrice de contrôle permet de déterminer si une altération a été commise. Si tel est le cas, la matrice de contrôle fournit une quantité appelée syndrome ; le tableau standard offre une correspondance entre ce syndrome et la correction e à apporter. Le message corrigé est alors égal à x - e.
Sommaire
Contexte
Code correcteur
Article détaillé : Code correcteur.Un code correcteur possède pour objectif la détection ou la correction d'erreurs après la transmission d'un message. Cette correction est permise grâce à l'ajout d'informations redondantes. Le message est plongé dans un ensemble plus grand, la différence de taille contient la redondance, l'image du message par le plongement est transmis. En cas d'altération du message, la redondance est conçue pour détecter ou corriger les erreurs. Un exemple simple est celui du code de répétition, le message est, par exemple, envoyé trois fois, le décodage se fait par vote. Ici, l'ensemble plus grand est de dimension triple à celle du message initial.
Code linéaire
Article détaillé : Code linéaire.Rappelons les éléments de base de la formalisation. Il existe un espace vectoriel E constitué de suites à valeurs dans un corps fini Fd et de longueur k, c’est-à-dire qu'à partir du rang k, toutes les valeurs de la suite sont nulles. Ces éléments sont l'espace des messages que l'on souhaite communiquer. Pour munir le message de la redondance souhaitée, il existe une application linéaire φ injective de E à valeurs dans F, l'espace des suites de longueur n à valeurs dans Fd. La fonction φ est appelée encodage, φ(E) aussi noté C est appelé le code, un élément de φ(E) mot du code, k la longueur du code et n la dimension du code. Ces notations sont utilisées dans tout l'article.
Capacité de correction
Distance de Hamming
Article détaillé : Distance de Hamming.La distance de Hamming est l'outil de base de la correction des erreurs. Elle s'exprime comme une distance issue d'une pseudo-norme. Le poids de Hamming, qui à un code associe le nombre de coordonnées non nulles, joue ici le rôle de pseudo-norme.
-
- Si ω désigne le poids de Hamming pour un code linéaire C, alors la distance de Hamming d est définie par la formule suivante:
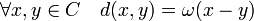
La linéarité de la structure sous-jacente introduit une propriété directe:
-
- La distance minimale δ entre deux points du code est égale au minimum du poids des mots du code non nuls.
Pour s'en convaincre, il suffit de remarquer que si x et y sont deux mots du code, alors leur différence est aussi un mot du code.
Ainsi, si un message reçu x n'est pas un mot de code, alors des altérations se sont produites durant la transmission. L'objectif est de trouver l'élément e de F de plus petit poids de Hamming, tel que x - e est un mot du code. Si la probabilité de recevoir p erreurs lors d'une transmission est une fonction décroissante de p, alors la correction est la plus probable.
Code parfait
Article détaillé : Code parfait.Le nombre maximum d'erreurs assurément corrigibles t découle directement de la distance minimale δ. En effet, t est le plus grand entier strictement inférieur à δ/2. La situation idéale est celle où les boules fermées de centre les mots du code et de rayon t forment une partition de F. On parle alors de parfait.
Si le message reçu contient plus de t erreurs, une alternative se présente :
-
- Dans la mesure du possible, par exemple pour la téléphonie mobile une demande de retransmission est faite en temps masqué.
- Sinon, par exemple dans le cas du disque compact, un mot du code proche et aléatoirement choisi est sélectionné.
Fonctionnement détaillé
Décodage et linéarité
La linéarité simplifie grandement le décodage. Pour s'en rendre compte, le plus simple est d'étudier un exemple. Considérons un code utilisé par le minitel, binaire de dimension 127 de longueur 120 et de distance minimale 3 et parfait. Si un message m est codé puis envoyé au récepteur, un élément x de F est reçu, susceptible d'erreur.
Le nombre t d'erreurs maximales assurément corrigibles est le plus grand entier strictement inférieur à 3/2 c’est-à-dire t = 1. Comme le code est parfait, les boules fermées de centre les mots du code et de rayon un forment une partition de F. En conséquence, x s'écrit de manière unique sous la forme c + e où c est un mot du code et e un élément de F de poids inférieur ou égal à un. Si la probabilité d'obtenir p erreurs durant la transmission est une fonction décroissante de p, c est probablement égal φ(m).
L'ensemble des valeurs possibles de e est relativement faible, ici comme le code est binaire, soit e est le vecteur nul, et aucune correction n'est à apporter, soit e est de poids un, c’est-à-dire que e est le message ne contenant que des zéros sauf sur une des 127 coordonnées qui vaut un. Il n'existe finalement que 128 cas d'erreurs dans un espace contenant 2127 éléments.
La linéarité permet de se limiter à la connaissance de l'unique boule fermée de centre zéro et de rayon t, soit dans l'exemple à une boule de 128 points. Dans le cas général, une boule fermée de rayon t à pour cardinal Vt (cf borne de Hamming):
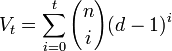
Implémentation
Article détaillé : Matrice de contrôle.La théorie des codes correcteurs affirme l'existence d'une application linéaire surjective de F dans un espace de dimension n - k dont la matrice H est appelée matrice de contrôle et dont le noyau est le code. En conséquence, on dispose des égalités suivantes :
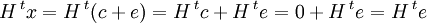
Dans le cas d'un code parfait, la restriction de H à la boule fermée de centre le vecteur nul et de rayon t est une bijection. Ici, la matrice H est identifiée à son application linéaire. Dans le cas du minitel, la boule unité contient 128 points, l'ensemble d'arrivée de H est un espace de dimension 7 et donc aussi de cardinal 128.
-
- L'élément H.tx est appelé syndrome du point x de F.
La donnée d'une table, dite tableau standard associant à chaque syndrome son unique antécédent par H dans la boule de centre le vecteur nul et de rayon t, permet le décodage. La correction d'erreurs consiste à soustraire l'antécédent e à l'élément de F reçu. Le mot du code recherché est c = x - e. L'implémentation informatique de cette méthode utilise une table de hachage et constitue une méthode rapide de décodage.
Dans le cas général, en plus de la valeur t du nombre maximal d'erreur assurément corrigibles, il est nécessaire de considérer la plus petite valeur s tel que les boules fermées de centre les points du code et de rayon s forment un recouvrement de F. Un code est parfait si et seulement si s est égal à t. H possède alors les propriétés suivantes :
-
- La restriction de H à la boule de centre le vecteur nul et de rayon t est injective, la restriction de H à la boule de centre le vecteur nul et de rayon t est surjective.
Il existe alors deux méthodes de décodages si H.tx n'admet pas d'antécédent dans la boule fermée de rayon t, soit une nouvelle demande de transmission est réalisée, soit un antécédent est choisi aléatoirement dans la boule fermée de rayon s, et la méthode reste la même. Dans tous les cas, le tableau standard contient dn-k entrées où d est le cardinal du corps fini.
Limite de l'approche
L'approche du décodage par syndrome est adapté aux petits codes, c’est-à-dire ceux où le nombre t d'erreurs assurément corrigibles n'est pas trop important. On peut citer par exemple certains protocoles utilisés par internet comme la TCP ou encore le minitel qui utilise un code parfait de dimension 127 distance minimale égale à 7.
En revanche, un code possédant une redondance forte, et capable de résister à des effacements importants, ne peut utiliser cette technique de décodage. La norme utilisée par la société Philips pour le code des disques compacts est à même de restituer 4096 bits manquants. La capacité de stockage d'un lecteur est largement trop faible pour stocker les syndromes. D'autres techniques, essentiellement fondées sur l'étude des polynômes formels à coefficients dans un corps fini représentent les approches les plus utilisées par l'industrie.
Notes et références
Liens externes
- (fr) Code Linéaire Université de Bordeaux
- (fr) Cours de code par Christine Bachoc Université de Bordeaux
- (fr) Code correcteur par M. Coste, A. Paugam, R. Quarez Université de Lille
Références
- FJ MacWilliams & JJA Sloane The Theory of Error-Correcting Codes North-Holland, 1977
- A Spataru Fondements de la Théorie de l'Information Presses Polytechniques Romandes, 1991
 Portail des mathématiques
Portail des mathématiques Portail de l’informatique
Portail de l’informatique Portail de la sécurité informatique
Portail de la sécurité informatique
Catégories : Détection et correction d'erreur | Algèbre linéaire -
Wikimedia Foundation. 2010.