- Niveau de confiance
-
Intervalle de confiance
En statistiques, et en particulier dans la théorie des sondages, lorsqu'on cherche à estimer la valeur d'un paramètre, on parle d'intervalle de confiance lorsque l'on donne un intervalle qui contient, avec un certain degré de confiance, la valeur à estimer. Le degré de confiance est en principe exprimé sous la forme d'une probabilité. Par exemple, un intervalle de confiance à 95% (ou au seuil de risque de 5%) a une probabilité égale à 0,95 de contenir la valeur du paramètre que l'on cherche à estimer.
Ainsi, lorsqu'on effectue un sondage (tirage au hasard d'un sous-ensemble d'une population), l'estimation d'une quantité d'intérêt donnée est soumise au hasard et correspond rarement exactement à la valeur de la quantité que l'on cherche à estimer. En présentant pour l'estimation non pas une valeur mais un encadrement, on quantifie d'une certaine manière l'incertitude sur la valeur estimée.
Plus l'intervalle de confiance est de taille petite, plus l'incertitude sur la valeur estimée est petite. L'un des objectifs de la théorie des sondages consiste à trouver des méthodes permettant de donner des intervalles de confiance de taille raisonnable.
Sommaire
Exemple I : Estimation d'une moyenne
L'usage le plus simple des intervalles de confiance concerne les populations à distribution normale (en forme de cloche) dont on cherche à estimer la moyenne
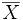 . Si on connait l'écart type σ(X) (ou si on en connait une estimation assez fiable) de cette distribution, et si on mesure la moyenne
. Si on connait l'écart type σ(X) (ou si on en connait une estimation assez fiable) de cette distribution, et si on mesure la moyenne 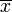 sur un échantillon de taille n pris au hasard, alors
sur un échantillon de taille n pris au hasard, alors- l'intervalle
![\left[\overline x - \frac{\sigma(X)}{\sqrt n}; \overline x + \frac{\sigma(X)}{\sqrt n}\right]](/pictures/frwiki/50/2a10ca00729be80b69eb2aaa07dcc1d3.png) est un intervalle de confiance de à environ 68 %
est un intervalle de confiance de à environ 68 % - l'intervalle
![\left[\overline x -2 \frac{\sigma(X)}{\sqrt n}; \overline x + 2\frac{\sigma(X)}{\sqrt n}\right]](/pictures/frwiki/98/be9036d9b9b6c6895e5a9e68cc86c908.png) est un intervalle de confiance de
est un intervalle de confiance de 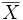 à environ 95 % [1]
à environ 95 % [1] - l'intervalle
![\left[\overline x - 3\frac{\sigma(X)}{\sqrt n}; \overline x + 3\frac{\sigma(X)}{\sqrt n}\right]](/pictures/frwiki/52/4fe12abecc737460fad31fc6a447dad2.png) est un intervalle de confiance de à environ 99,7%
est un intervalle de confiance de à environ 99,7%
Encore faut-il connaitre ou avoir une estimation de l'écart type σ(X). En pratique, on prend comme estimation de σ(X) la valeur
 où est l'écart-type de la série de mesures issues de l'échantillon.
où est l'écart-type de la série de mesures issues de l'échantillon.Ainsi l'on voit que pour augmenter la confiance, il faut élargir l'intervalle et pour obtenir un intervalle plus fin avec même degré de confiance, il faut augmenter la taille de l'échantillon.
Exemple II : le sondage d'opinion
On cherche à estimer le pourcentage de personnes ayant une voiture verte. Pour cela on effectue un sondage. Comme on ne sonde pas toute la population on a de bonnes chances de ne pas tomber exactement sur la bonne valeur mais de faire une erreur. On veut alors donner un intervalle qui a 95% de chances de contenir la vraie valeur.
Pour cela on effectue un sondage sur 1 000 personnes. Les résultats sont les suivants: 150 personnes ont une voiture verte, 850 n'en ont pas.
On appelle p la "vraie" proportion de personnes dans la population totale qui ont une voiture verte. On cherche à estimer p. On appelle N le nombre de personnes ayant été sondées, ici N=1 000. On appelle S le nombre de personnes ayant une voiture verte parmi les N personnes sondées. L'idée est de présenter comme estimation de p la valeur S/N.
On applique le théorème central limite à la variable aléatoire Xi qui vaut 1 si la i-ème personne sondée a une voiture verte et 0 sinon. Cette variable a une moyenne p et une variance p(1-p). Alors:
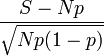 tend vers une loi normale de moyenne 0 et de variance 1.
tend vers une loi normale de moyenne 0 et de variance 1.Pour une loi normale de moyenne 0 et de variance 1 on a : P(−1,96 < Z < 1,96) = 0,95. La valeur 1,96 est le quantile d'ordre 1-2,5% de la loi normale. Ces valeurs peuvent se trouver dans des tables de quantiles ou être calculées à partir de la fonction d'erreur réciproque:
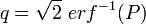 par exemple,
par exemple, 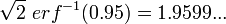 (voir par exemple les quantiles de la loi de Student pour un exemple de table de quantile.)
(voir par exemple les quantiles de la loi de Student pour un exemple de table de quantile.)Soit encore
En estimant
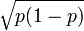 par
par 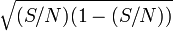 on peut alors encadrer p:Pourquoi l'on peut bien faire cette estimation
on peut alors encadrer p:Pourquoi l'on peut bien faire cette estimationEn fait si on appelle
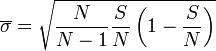 l'estimateur de la variance constatée, la variable
l'estimateur de la variance constatée, la variable 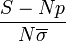 suis une loi de Student à N-1 degrés de libertés. Ici (N-1)=999 les quantiles d'ordre 999 de la loi de student sont les mêmes d'un point de vue numérique que celles d'ordre infini qui correspondent à la loi normale. On peut donc remplacer la variance par l'estimateur de la variance constatée.
suis une loi de Student à N-1 degrés de libertés. Ici (N-1)=999 les quantiles d'ordre 999 de la loi de student sont les mêmes d'un point de vue numérique que celles d'ordre infini qui correspondent à la loi normale. On peut donc remplacer la variance par l'estimateur de la variance constatée.Ensuite l'on peut remplacer
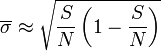 l'erreur en pourcentage sur la variance constatée en ommetant la normalisation N/(N-1) pour N = 1 000 est de l'ordre de 5/10000 que l'on néglige pour ne pas allourdir la présentation.
l'erreur en pourcentage sur la variance constatée en ommetant la normalisation N/(N-1) pour N = 1 000 est de l'ordre de 5/10000 que l'on néglige pour ne pas allourdir la présentation.L'intervalle de confiance à 95 % vaut alors [0,127;0,172]. On est sûr à 95% qu'entre 12,7% et 17,2% de personnes ont une voiture verte avec ce sondage.
Pour avoir une plus grande précision, il faudrait sonder plus de personnes. On remarque en effet l'existence d'un N apparaissant au dénominateur des deux racines carrées. Si on sonde plus de personnes (N plus grand), ces deux termes auront tendance à devenir plus petits et l'intervalle sera plus petit.
De façon plus générale
L'intervalle de confiance mesure le degré de précision que l'on a sur les estimations issues de l'échantillon. Il y a deux sources principales de variations sur les données qui peuvent être la cause d'un manque de précision dans l'estimation d'une grandeur.
- Un nombre insuffisant de données: par exemple, dans le cas d'un sondage, on ne sonde pas toute la population mais qu'une fraction de la population. De même, pour les mesures physiques, on n'effectue qu'un nombre fini de mesures alors qu'il faudrait souvent en théorie pouvoir en faire une infinité pour obtenir un résultat parfait.
- Il peut également y avoir du bruit dans la mesure des données ce qui est pratiquement toujours le cas pour la mesure des grandeurs physiques.
Parmi les méthodes d'estimation, nous pouvons citer l'estimation par intervalle de confiance. Il s'agit de trouver un intervalle contenant un paramètre (inconnu) à estimer avec une probabilité ou niveau de confiance de 1 − α. Pour p un paramètre (inconnu) à estimer on cherche par exemple a et b tels que:
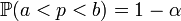
Si on appelle p la valeur exacte du paramètre , et que la valeur mesurée suit une loi de probabilité dépendant de p :
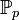 , l'intervalle de confiance I(x) (au « niveau de confiance » 1 − α) relatif à une observation x constatée, est l'intervalle dans lequel, pour toute valeur p,
, l'intervalle de confiance I(x) (au « niveau de confiance » 1 − α) relatif à une observation x constatée, est l'intervalle dans lequel, pour toute valeur p,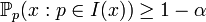 .
.
Pour un p donné, c'est la probabilité d'observer une valeur x pour laquelle le paramètre à estimer soit dans l'intervalle de confiance associé à cette observation x.
Ceci ne signifie pas que « la probabilité que la valeur réelle soit dans I(x) est 1 − α », ce qui n'aurait pas de sens puisque la valeur réelle n'est pas une variable aléatoire. Cela signifie que « si la valeur réelle n'est pas dans I(x), la probabilité a priori du résultat de l'observation que l'on a obtenu était inférieure à α ». Par exemple si le paramètre n'est pas dans l'intervalle, c'est que l'observation effectuée correspond à un phénomène "rare" dans lequel l'intervalle de confiance ne contient pas la vraie valeur.
Voir aussi
Notes et références
- ↑ l'intervalle de confiance à 95% est plus précisément
![\left]\overline x - 1,96\frac{\sigma(X)}{\sqrt n}; \overline x + 1,96\frac{\sigma(X)}{\sqrt n}\right[](/pictures/frwiki/98/b3c2a34883687088e9459095243a2c14.png)
Articles connexes
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Estimation (statistique) | Métrologie - l'intervalle
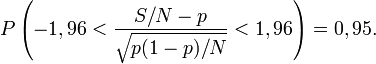
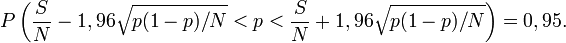
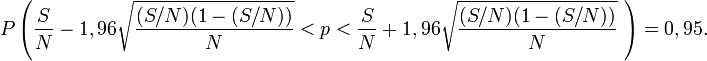
Wikimedia Foundation. 2010.