- Méthode de tri
-
Algorithme de tri
Un algorithme de tri est, en informatique ou en mathématiques, un algorithme qui permet d'organiser une collection d'objets selon un ordre déterminé. Les objets à trier font donc partie d'un ensemble muni d'une relation d'ordre (de manière générale un ordre total). Les ordres les plus utilisés sont l’ordre numérique et l'ordre lexicographique (dictionnaire).
Suivant la relation d'ordre considérée, une même collection d’objet peut donner lieu à divers arrangements, pourtant il est possible de définir un algorithme de tri indépendamment de la fonction d’ordre utilisée. Celui-ci ne fera qu'utiliser une certaine fonction d’ordre correspondant à une relation d’ordre qui doit permettre de comparer tout couple d'éléments de la collection.
Sommaire
Classification
La classification des algorithmes de tri est très importante, car elle permet de choisir l’algorithme le plus adapté au problème traité, tout en tenant compte des contraintes imposées par celui-ci.
On distingue, tout d'abord, les algorithmes de tri d'application générale, procédant par comparaisons entre des paires d'éléments, et les algorithmes plus spécialisés faisant des hypothèses restrictives sur la structure des données entrées (par exemple, le tri par comptage, applicable uniquement si les données sont prises parmi un petit ensemble connu à l'avance). Si l'on ne précise rien, on entend habituellement par algorithme de tri un algorithme général de tri par comparaison.
Les principales caractéristiques qui permettent de différencier les algorithmes de tri sont : la complexité algorithmique, les ressources nécessaires (notamment en termes d'espace mémoire utilisé) et le caractère stable.
Complexité algorithmique
- La complexité algorithmique temporelle dans le pire des cas permet de fixer une borne supérieure du nombre d'opérations qui seront nécessaires pour trier un ensemble de n éléments. On utilise pour symboliser cette complexité la notation de Landau : O.
- La complexité algorithmique temporelle en moyenne : c’est le nombre d'opérations élémentaires effectuées en moyenne pour trier une collection d’éléments. Elle permet de comparer les algorithmes de tris et donne une bonne idée du temps d'exécution qui sera nécessaire à l’algorithme ; on arrive à l'estimer avec une précision assez importante. Toutefois, si les ensembles à trier ont une forme particulière et ne sont pas représentatifs des n ! combinaisons possibles, alors les performances pourront être très inférieures ou très supérieures à la complexité « moyenne ».
- La complexité algorithmique spatiale (en moyenne ou dans le pire des cas) représente, quant à elle, l’utilisation mémoire que va nécessiter l'algorithme. Celle-ci peut dépendre, comme le temps d'exécution, du nombre d'éléments à trier.
Pour certains des algorithmes de tri les plus simples, T(n) = O(n2), pour les tris plus élaborés, T(n) = O(n·log(n)).
On peut montrer que la complexité temporelle en moyenne et dans le pire des cas d’un algorithme basé sur une fonction de comparaison ne peut pas être meilleure que n·log(n). Les tris qui ne demandent que n·log(n) comparaisons en moyenne sont alors dits optimaux.
Démonstration mathématiqueLe problème du tri consiste, étant donné une suite u = (u1, u2, ..., un) d’éléments d’un ensemble totalement ordonné (par exemple
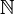 ), à déterminer une permutation σ de 1, ..., n telle que : y = (uσ(1), uσ(2), ..., uσ(n)) soit triée.
), à déterminer une permutation σ de 1, ..., n telle que : y = (uσ(1), uσ(2), ..., uσ(n)) soit triée.Un algorithme de tri par comparaisons successives se modélise comme un arbre binaire, chaque nœud de l'arbre correspondant à une comparaison entre deux éléments de l'ensemble. On compare deux éléments ui et uj, et en fonction du résultat, on passe à l'un des deux nœuds suivants, où l'on procède à une autre comparaison. Chaque feuille (nœud terminal) de l'arbre correspond à la suite totalement triée.
L'algorithme doit être en mesure de fournir toutes les possibilités de permutation des termes de la suite, car il est équivalent de fournir la permutation σ que la suite triée y. Le nombre de permutations de n éléments étant n ! (factorielle n) le nombre de feuilles de l'arbre doit être au moins n ! .
Notons h la profondeur maximale de l'arbre (nous parlons bien d'un nombre d'étapes dans le pire des cas). Le nombre maximal de feuilles dans un arbre binaire de profondeur maximale h est de 2h.
Il vient donc :
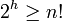 ; ainsi, asymptotiquement,
; ainsi, asymptotiquement, 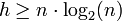 (par utilisation de la formule de Stirling).
(par utilisation de la formule de Stirling).Le fait qu'il existe des tris en
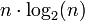 montre d'autre part qu'il est possible d'avoir asymptotiquement
montre d'autre part qu'il est possible d'avoir asymptotiquement 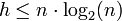 d'où la notion de minimum.
d'où la notion de minimum.Pour certains types de données (entiers, chaînes de caractères de taille bornée), il existe cependant des algorithmes plus efficaces au niveau du temps d'exécution, comme le tri comptage ou le tri radix. Ces algorithmes n'utilisent pas la comparaison entre éléments (la borne n·log(n) ne s'applique donc pas pour eux) mais nécessitent des hypothèses sur les objets à trier. Par exemple, le tri comptage et le tri radix s'appliquent à des entiers que l'on sait appartenir à l'ensemble [1, m] avec comme hypothèse supplémentaire pour le tri radix que m soit une puissance de 2 (c’est-à-dire de la forme 2k).
Caractère en place
Un algorithme est dit en place s'il n'utilise qu'un nombre très limité de variables et qu’il modifie directement la structure qu’il est en train de trier. Ceci nécessite l’utilisation d'une structure de donnée adaptée (un tableau par exemple). Ce caractère peut être très important si on ne dispose pas d'une grande quantité de mémoire utilisable.
Remarquons toutefois qu'en général, on ne trie pas directement les données elles-mêmes, mais seulement des références (ou pointeurs) sur ces dernières.
Caractère stable
Un algorithme est dit stable s'il garde l'ordre relatif des quantités égales pour la relation d'ordre.
Exemple, si on considère la suite d’éléments suivante :
(4, 1) (3, 1) (3, 7) (5, 6)
que l'on trie par rapport à leur première coordonnée (la clé), deux cas sont possibles, quand l’ordre relatif est respecté et quand il ne l'est pas :
(3, 1) (3, 7) (4, 1) (5, 6) (ordre relatif maintenu) (3, 7) (3, 1) (4, 1) (5, 6) (ordre relatif changé)
Lorsque deux éléments sont égaux pour la relation d'ordre (c’est-à-dire qu'ils ont la même clé), l'algorithme de tri conserve l'ordre dans lequel ces deux éléments se trouvaient avant son exécution. Les algorithmes de tri instables peuvent être retravaillés spécifiquement afin de les rendre stables, cependant cela peut être aux dépens de la rapidité et/ou peut nécessiter un espace mémoire supplémentaire.
Parmi les algorithmes listés plus bas, les tris étant stables sont : le tri à bulles, le tri par insertion et le tri fusion. Les autres algorithmes nécessitent O(n) mémoire supplémentaire pour stocker l'ordre initial des éléments.
Exemples d'algorithmes de tri
Tris par comparaison
Algorithmes lents
Ces algorithmes sont lents pour plus de 20 éléments parce qu'ils sont en O(n2).
- Tri à bulles : Algorithme quadratique, T(n) = O(n2), en moyenne et dans le pire des cas, stable et en place ; amusant mais pas efficace
- Tri par sélection : Algorithme quadratique, T(n) = O(n2), en moyenne et dans le pire des cas, pas stable si tri sur place ; rapide lorsque l'on a moins de 7 éléments
- Tri par insertion : Algorithme quadratique, T(n) = O(n2), en moyenne et dans le pire des cas, stable et en place. C'est le plus rapide et le plus utilisé pour des listes de moins de 15 éléments ;
Algorithmes plus rapides
- Tri de Shell (shell sort) : Amélioration du tri par insertion, mais pas stable. Complexité: au pire O(nlog2n) pour la série de pas 2p3q et
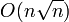 pour la série de pas 2k − 1. On ne connaît pas de série donnant O(nlogn).
pour la série de pas 2k − 1. On ne connaît pas de série donnant O(nlogn).
- Tri fusion (merge sort) : O(nlogn) en moyenne et dans le pire des cas, stable mais pas en place[1] ;
- Tri rapide (quick sort) : O(nlogn) en moyenne, mais en O(n2) (quadratique) au pire cas[2], en place mais pas stable
- Introsort : Amélioration du tri rapide, qui permet une exécution en O(nlogn) dans tous les cas.
- Tri par tas (heap sort) : O(nlogn) en moyenne et dans le pire des cas, en place mais pas stable. Toujours environ deux fois plus lent que le tri rapide, c'est-à-dire aux alentours de O(nlogn), il est donc intéressant de l'utiliser si l'on soupçonne que les données à trier seront souvent des cas quadratiques pour le tri rapide ;
- Tri par ABR : O(nlogn) en moyenne, O(n2) dans le pire des cas. Ce tri est un des plus lents (parmi les tris rapides) et des plus gourmands en mémoire à cause de la structure d'arbre binaire à manipuler. Il est possible de le rendre O(nlogn) dans tous les cas en maintenant un arbre équilibré (Arbre_AVL).
- Smoothsort : tri inspiré du tri par tas en utilisant un arbre non inversé, ce tri est très rapide pour les ensembles déjà presque triés, sinon, il est en O(nlogn). Tri en place mais pas stable
Note : on peut facilement obtenir la stabilité d'un tri si l'on associe à chaque élément sa position initiale. Pour cela, on peut créer un deuxième tableau de même taille pour stocker l'ordre initial (on renonce alors au caractère en place du tri).
- ↑ On peut faire du tri fusion un tri en place et toujours en O(nlogn) mais l'algorithme effectue plus de copies et est plus compliqué au niveau de la programmation
- ↑ On peut rendre sa complexité algorithmique quasi-indépendante des données d'entrée en utilisant un pivot aléatoire ou en appliquant au tableau une permutation aléatoire avant de le trier.
Comparaison des algorithmes de tris en place

Cette comparaison des algorithmes prend en compte le nombre d'accès en écriture dans le tableaux ainsi que le nombre de comparaison. Par exemple pour un tri simple avec 2 éléments, il y a une comparaison, et si échange il y a, deux accès en écriture. Les données à trier sont choisies aléatoirement et le temps moyen est calculé.
Avec ces critères, les algorithmes de tris en place les plus rapides sur des tableaux de moins de 40 éléments sont le tri de Shell et le tri rapide (quicksort). Si le tri par insertion est parmi les premiers pour moins de 10 éléments, sa complexité augmente rapidement au-delà. Le tri par tas est clairement le plus lent. Le smoothsort obtient une position intermédiaire.
Notes :
- le tri de Shell du test utilise les pas optimisés (1, 4, 10, 23...)
- pour le tri rapide, l'utilisation de l'optimisation de Sedgewick ou de l'introsort ne change que très peu la vitesse moyenne sur les petits tableaux.
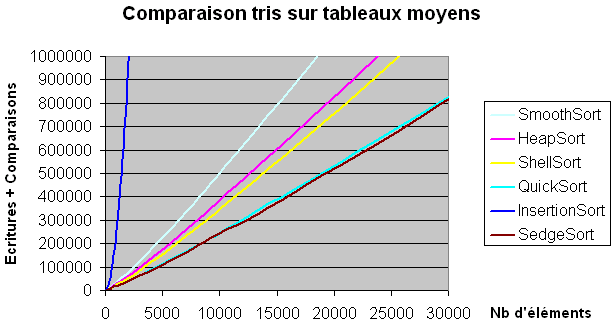
Lorsque l'on prend un nombre d'éléments moyen (entre 50 et 30 000), le tri en place le plus rapide est le tri rapide. La variante Sedgesort est légèrement plus rapide si l'on choisit bien la taille des petites listes, triées à la fin (ici au plus 8). Ensuite vient le tri de Shell qui n'est plus le plus rapide. Le smoothsort et le tri par tas changent de place. Enfin, la complexité du tri par insertion s'envole.
Comparaisons tris sur grands tableaux
Avec un nombre d'éléments entre 30 000 et 6 000 000 d'éléments, les résultats sont sensiblement les mêmes que pour les tableaux moyens. L'optimisation de Sedgewick est légèrement plus intéressante même si le gain reste marginal. D'autre part, le tri par insertion, de même que le tri à bulles et le tri par sélection, sont beaucoup trop lents pour être utilisés dans ce cas.
Rapport entre complexité mesurée et complexité optimale Sedgesort Quicksort simple Shellsort Heapsort Smoothsort Rapport 1,8 1,9 2,8 3 4,1 Tris utilisant la structure des données
- Tri comptage ou Tri par dénombrement (counting sort): Algorithme linéaire, T(n) = O(n), stable mais nécessite l'utilisation d'une seconde liste de même longueur que la liste à trier. Son utilisation relève de la condition que les valeurs à trier sont des entiers naturels dont on connaît les extrema ;
- Tri par base (radix sort) : c'est aussi un tri linéaire dans certaines conditions (moins restrictives que pour le tri par comptage), T(n) = O(n), stable mais nécessite aussi l'utilisation d'une seconde liste de même longueur que la liste à trier ;
- Tri par paquets (bucket sort) : Stable et en complexité linéaire -- T(n) = O(n), part de l'hypothèse que les données à trier sont réparties de manière uniforme sur l'ensemble [0,1[.
Tris volumineux
Les algorithmes de tri doivent aussi être adaptés en fonction des configurations informatiques sur lesquels ils sont utilisés. Dans les exemples cités plus haut, on suppose que toutes les données sont présentes en mémoire centrale (ou accessibles en mémoire virtuelle). La situation se complexifie si l'on veut trier des volumes de données supérieurs à la mémoire centrale disponible (ou si l'on cherche à améliorer le tri en optimisant l'utilisation de la hiérarchie de mémoire).
Ces algorithmes sont souvent basés sur une approche assez voisine de celle du tri fusion. Le principe est le suivant :
- On découpe le volume de données à trier en sous-ensembles de taille inférieure à la mémoire rapide disponible,
- On trie chaque sous-ensemble en mémoire centrale pour former des "monotonies" (sous-ensembles triés).
- On interclasse ces monotonies.
Tris bande
Dans les débuts de l'informatique, lorsque le coût des mémoires de type disques ou tambours magnétiques était très élévé, les algorithmes de tri pouvaient n'utiliser que la mémoire centrale et les dérouleurs de bandes magnétiques.
En l'absence de disque, il fallait au moins 4 dérouleurs de bandes pour pratiquer un tel tri. Avec 4 dérouleurs (b1, b2, b3, b4), les opérations étaient les suivantes :
- (1) montage (manuel) du fichier à trier sur le dérouleur b1, et de bandes de manœuvre sur b2, b3, b4 ;
- (2) lecture de b1 par paquets successifs qui sont triés en mémoire, pour générer des monotonies qui sont écrites en alternance sur les dérouleurs b3 et b4 ;
- (3) sur le dérouleur b1, démontage de la bande contenant le fichier initial pour le remplacer par une bande de manœuvre ;
- (4) fusion (interclassement) des bandes b3 et b4 pour générer en alternance sur b1 et b2 des monotonies dont le volume est doublé ;
- (5) fusion de b1 et b2 sur b3 b4, et itération de (4) et (5) jusqu'à ce que les monotonies atteignent 50 % du volume à trier ;
- fusion finale pour générer le résultat.
En pratique, compte tenu de la fiabilité moyenne des équipements, on rencontrait donc fréquemment des salles machines avec 8 dérouleurs de bandes.
Liens externes
- (fr) Mémoire de synthèse sur les algorithmes de tri
- (fr) Dossier sur les algorithmes de tri et leur complexité (et implémentation en divers langages)
- (fr) Illustration dynamique de plusieurs tris (nécessite Java)
- (fr) Sur le site Interstices, document sur les algorithmes de tri avec une applet Java
 Portail de l’informatique
Portail de l’informatique
Catégorie : Algorithme de tri
Wikimedia Foundation. 2010.