- Tri rapide
-
Le tri rapide (en anglais quicksort) est un algorithme de tri inventé par C.A.R. Hoare en 1961[1] et fondé sur la méthode de conception diviser pour régner. Il est généralement utilisé sur des tableaux, mais peut aussi être adapté aux listes. Dans le cas des tableaux, c'est un tri en place mais non stable.
La complexité moyenne du tri rapide pour n éléments est proportionnelle à n log n, ce qui est optimal pour un tri par comparaison, mais la complexité dans le pire des cas est quadratique. Malgré ce désavantage théorique, c'est en pratique un des tris les plus rapides, et donc un des plus utilisés. Le pire cas est en effet peu probable lorsque l'algorithme est correctement implémenté. Le tri rapide ne peut cependant pas tirer avantage du fait que l'entrée est déjà presque triée. Dans ce cas particulier, il est plus avantageux d'utiliser le tri par insertion ou l'algorithme Smoothsort.
 Quicksort en action sur une liste de nombre aléatoires Les lignes horizontales sont les valeurs des pivots.
Quicksort en action sur une liste de nombre aléatoires Les lignes horizontales sont les valeurs des pivots.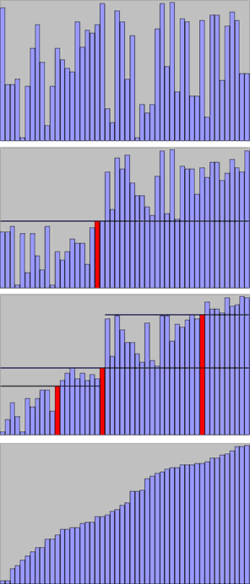 Autre illustration de l'algorithme de tri rapide (Quicksort).
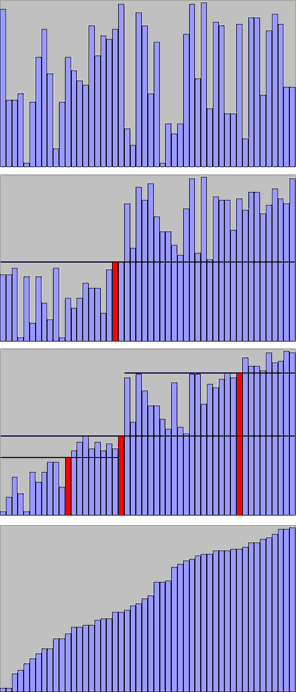
Autre illustration de l'algorithme de tri rapide (Quicksort).
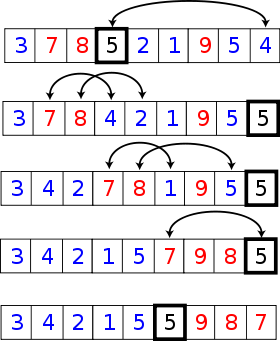 Exemple de tri d'une petite liste de nombres
Exemple de tri d'une petite liste de nombresSommaire
Description de l'algorithme
La méthode consiste à placer un élément du tableau (appelé pivot) à sa place définitive, en permutant tous les éléments de telle sorte que tous ceux qui sont inférieurs au pivot soient à sa gauche et que tous ceux qui sont supérieurs au pivot soient à sa droite. Cette opération s'appelle le partitionnement. Pour chacun des sous-tableaux, on définit un nouveau pivot et on répète l'opération de partitionnement. Ce processus est répété récursivement, jusqu'à ce que l'ensemble des éléments soit trié.
tri_rapide(tableau t, entier premier, entier dernier) début si premier < dernier alors pivot := choix_pivot(t,premier,dernier) pivot := partitionner(t,premier, dernier,pivot) tri_rapide(t,premier,pivot-1) tri_rapide(t,pivot+1,dernier) fin si finChoisir un pivot aléatoirement dans l'intervalle [premier, dernier] garantit l'efficacité de l'algorithme, mais il existe d'autres possibilités (voir la section « Choix du pivot et complexité »).
Le partitionnement peut être fait en temps linéaire, en place. La mise en œuvre la plus simple consiste à parcourir le tableau du premier au dernier élément, en formant la partition au fur et à mesure : à la i-ème étape de l'algorithme ci-dessous, les éléments T[0],…,T[j-1] sont inférieurs au pivot, tandis que T[j],…,T[i-1] sont supérieurs au pivot.
partitionner(tableau T, premier, dernier, pivot) échanger T[pivot] et T[dernier] j := premier pour i de premier à dernier - 1 si T[i] < T[dernier] alors échanger T[i] et T[j] j := j + 1 échanger T[dernier] et T[j] renvoyer jCet algorithme de partitionnement rend le tri rapide non stable : il ne préserve pas nécessairement l'ordre des éléments possédant une clef de tri identique. On peut résoudre ce problème en ajoutant l'information sur la position de départ à chaque élément et en ajoutant un test sur la position en cas d'égalité sur la clef de tri.
Le partitionnement peut poser problème si les éléments du tableau ne sont pas distincts. Dans le cas le plus dégénéré, c'est-à-dire un tableau de n éléments égaux, cette version de l'algorithme a une complexité quadratique. Plusieurs solutions sont possibles : par exemple se ramener au cas d'éléments distincts en utilisant la méthode décrite pour rendre le tri stable, ou bien utiliser un autre algorithme (voir la section « Algorithme de partitionnement alternatif »).
Choix du pivot et complexité
Pivot arbitraire
Une manière simple de choisir le pivot est de prendre toujours le premier élément du sous-tableau courant (ou le dernier). Lorsque toutes les permutations possibles des entrées sont équiprobables, la complexité moyenne du tri rapide en sélectionnant le pivot de cette façon est Θ(n log n). Cependant, la complexité dans le pire cas est Θ(n2), et celle-ci est atteinte lorsque l'entrée est déjà triée ou presque triée.
Si on prend comme pivot le milieu du tableau, le résultat est identique, bien que les entrées problématiques soient différentes.
Il est possible d'appliquer une permutation aléatoire au tableau pour éviter que l'algorithme soit systématiquement lent sur certaines entrées. Cependant, cette technique est généralement moins efficace que de choisir le pivot aléatoirement.
Pivot aléatoire
Si on utilise la méthode donnée dans la description de l'algorithme, c'est-à-dire choisir le pivot aléatoirement de manière uniforme parmi tous les éléments, alors la complexité moyenne du tri rapide est Θ(n log n) sur n'importe quelle entrée. Dans le pire cas, la complexité est Θ(n2). Néanmoins, l'écart type de la complexité est seulement Θ(n), ce qui signifie que l'algorithme s'écarte peu du temps d'exécution moyen[2].
Dans le meilleur cas, l'algorithme est en Θ(n log n).
Pivot optimal
En théorie, on pourrait faire en sorte que la complexité de l'algorithme soit Θ(n log n) dans le pire cas en prenant comme pivot la valeur médiane du sous-tableau. L'algorithme BFPRT ou médiane des médianes permet en effet de calculer cette médiane de façon déterministe en temps linéaire. Mais l'algorithme n'est pas suffisamment efficace dans la pratique, et cette variante est peu utilisée.
Variantes et optimisations
Algorithme de partitionnement alternatif
Il existe un algorithme de partitionnement plus complexe, qui réduit le nombre d'échanges effectués lors du partitionnement. De plus, les éléments égaux au pivot sont mieux répartis des deux côtés de celui-ci qu'avec l'algorithme précédent. Ainsi, l'algorithme reste en O(n log n) même sur un tableau dont tous les éléments sont identiques.
Le principe de l'algorithme est le suivant :
- Trouver le plus petit i tel que T[i] soit supérieur ou égal au pivot.
- Trouver le plus grand j tel que T[j] soit inférieur ou égal au pivot.
- Si i<j, échanger T[i] et T[j] puis recommencer.
Il est possible de formaliser cet algorithme de sorte qu'il soit linéaire :
partitionner(tableau T, premier, dernier, pivot) échanger T[pivot] et T[premier] i = premier + 1, j = dernier tant que i < j tant que i < j et T[i] < T[premier], faire i := i + 1 tant que i < j et T[j] > T[premier], faire j := j - 1 échanger T[i] et T[j] i := i + 1, j := j - 1 fin tant que // le tableau est à présent en 3 parties consécutives : pivot, partie gauche, partie droite // dans partie gauche, tous les éléments sont ⇐ pivot // dans partie droite, tous les éléments sont >= pivot // mais les deux parties peuvent se chevaucher : i-j peut être 0, 1 ou 2 // il faut replacer le pivot entre les 2 parties et retourner l'indice du pivot : c'est assez compliqué... // il vaut mieux laisser le pivot à sa place au départ et le déplacer en cas de chevauchement : // voir l'algorithme classique à Wikipedia Quicksort en anglaisCombinaison avec d'autres algorithmes de tri
Traitement spécial des petits sous-problèmes
Une optimisation utile consiste à changer d'algorithme lorsque le sous-ensemble de données non encore trié devient petit. La taille optimale des sous-listes dépend du matériel et des logiciels utilisés, mais est de l'ordre de 15 éléments. On peut alors utiliser le tri par sélection ou le tri par insertion. Le tri par sélection ne sera sûrement pas efficace pour un grand nombre de données, mais il est souvent plus rapide que le tri rapide sur des listes courtes, du fait de sa plus grande simplicité.
Robert Sedgewick suggère une amélioration (appelée Sedgesort) lorsqu'on utilise un tri simplifié pour les petites sous-listes[3] : on peut diminuer le nombre d'opérations nécessaires en différant le tri des petites sous-listes après la fin du tri rapide, après quoi on exécute un tri par insertion sur le tableau entier.
LaMarca et Ladner ont étudié « l'influence des caches sur les performances des tris »[4], un problème prépondérant sur les architectures récentes dotées de hiérarchies de caches avec des temps de latence élevés lors des échecs de recherche de données dans les caches. Ils concluent que, bien que l'optimisation de Sedgewick diminue le nombre d'instructions exécutées, elle diminue aussi le taux de succès des caches à cause de la plus large dispersion des accès à la mémoire (lorsque l'on fait le tri par insertion à la fin sur tout le tableau et non au fur et à mesure), ce qui entraine une dégradation des performances du tri. Toutefois l'effet n'est pas dramatique et ne devient significatif qu'avec des tableaux de plus de 4 millions d'éléments de 64 bits. Cette étude est citée par Musser.
Introsort
Article détaillé : Introsort.Une variante du tri rapide devenue largement utilisée[réf. nécessaire] est introsort alias introspective sort[5]. Elle démarre avec un tri rapide puis utilise un tri par tas lorsque la profondeur de récursivité dépasse une certaine limite prédéfinie. Ainsi, sa complexité dans le pire cas est O(n log n).
Espace mémoire
Une implémentation naïve du tri rapide utilise un espace mémoire proportionnel à la taille du tableau dans le pire cas. Il est possible de limiter la quantité de mémoire à O(log n) dans tous les cas en faisant le premier appel récursif sur la liste la plus petite. Le second appel récursif, situé à la fin de la procédure, est récursif terminal. Il peut donc être transformé en itération de la manière suivante :
tri_rapide(T, gauche, droite) tant que droite-gauche+1 > 1 sélectionner un pivot T[pivotIndex] pivotNewIndex := partition(a, gauche, droit, pivotIndex) si pivotNewIndex-1 - gauche < droit - (pivotNewIndex+1) tri_rapide(a, gauche, pivotNewIndex-1) gauche := pivotNewIndex+1 sinon tri_rapide(a, pivotNewIndex+1, droit) droit := pivotNewIndex-1 fin_si fin_tant_queVariante pour la sélection d'élément
Une variante du tri rapide, fonctionnant en temps linéaire en moyenne, permet de déterminer le k-ème plus petit élément dans un tableau. Un cas particulier notable est k=n/2, qui correspond à la recherche de la médiane.
Le principe de l'algorithme modifié est le suivant : à chaque étape, on réalise une partition selon un pivot choisi aléatoirement. Une fois la partition effectuée, il est possible de savoir de quel côté de la partition se trouve le k-ème élément (ou bien si c'est le pivot lui-même). Dans le cas où le pivot n'est pas le k-ème élément, on appelle récursivement l'algorithme, mais seulement du côté où se trouve l'élément. À la fin de l'algorithme, le k-ème élément du tableau est alors le k-ème plus petit élément du tableau.
Voir aussi
Autres pages
- Loi de Bernoulli, en particulier la section « Coût moyen de l'algorithme de tri rapide ».
Liens externes
Références
- Hoare, C. A. R. « Partition: Algorithm 63, » « Quicksort: Algorithm 64, » and « Find: Algorithm 65. » Comm. ACM 4, 321-322, 1961
- Donald E. Knuth, The Art of Computer Programming, Volume 3: Sorting and Searching, Addison-Wesley 1973, (ISBN 0-201-03803-X) (section 5.2.2, p. 121)
- R. Sedgewick. Implementing quicksort programs, Communications of the ACM, 21(10):847857, 1978.
- A. LaMarca and R. E. Ladner. « The Influence of Caches on the Performance of Sorting. » Proceedings of the Eighth Annual ACM-SIAM Symposium on Discrete Algorithms, 1997. pp. 370-379.
- David Musser. Introspective Sorting and Selection Algorithms, Software Practice and Experience vol 27, number 8, pages 983-993, 1997

Wikimedia Foundation. 2010.