- Latent Semantic Analysis
-
Analyse sémantique latente
L’analyse sémantique latente (LSA, de l'anglais : Latent semantic analysis) ou indexation sémantique latente (ou LSI, de l'anglais : Latent semantic indexation) est un procédé de traitement des langues naturelles, dans le cadre de la sémantique vectorielle. La LSA fut brevetée en 1988 [1] et publiée en 1990[2].
Elle permet d'établir des relations entre un ensemble de documents et les termes qu'ils contiennent, en construisant des « concepts » liés aux documents et aux termes.
Sommaire
Matrice des occurrences
La LSA utilise une matrice qui décrit l'occurrence de certains termes dans les documents. C'est une matrice creuse dont les lignes correspondent aux « termes » et dont les colonnes correspondent aux « documents ».
Les « termes » sont généralement des mots tronqués ou ramenés à leur radical, issus de l'ensemble du corpus. On a donc le nombre d'apparition d'un mot dans chaque document, et pour tous les mots. Ce nombre est normalisé en utilisant la pondération tf-idf (de l'anglais : term frequency – inverse document frequency), combinaison de deux techniques : un coefficient de la matrice est d'autant plus grand qu'il apparaît beaucoup dans un document, et qu'il est rare — pour les mettre en avant.
Cette matrice est courante dans les modèles sémantiques standards, comme le modèle vectoriel, quoique sa forme matricielle ne soit pas systématique, étant donné qu'on ne se sert que rarement des propriétés mathématiques des matrices.
La LSA transforme la matrice des occurrences en une « relation » entre les termes et des « concepts », et une relation entre ces concepts et les documents. On peut donc relier des documents entre eux.
Applications
Cette organisation entre termes et concepts est généralement employée pour :
- la comparaison de documents dans l'espace des concepts (classement et partitionnement de données) ;
- la recherche de documents similaires entre différentes langues, en ayant accès à un dictionnaire de documents multilingues ;
- la recherche de relations entre les termes (résolution de synonymie et de polysémie) ;
- étant donné une requête, traduire les termes de la requête dans l'espace des concepts, pour retrouver des documents liés sémantiquement (recherche d'information).
La résolution de la synonymie et de la polysémie est un enjeu majeur en traitement automatique des langues :
- deux synonymes décrivent une même idée, un moteur de recherche pourrait ainsi trouver des documents pertinents mais ne contenant pas le terme exact de la recherche ;
- la polysémie d'un mot fait qu'il a plusieurs sens selon le contexte — on pourrait de même éviter des documents contenant le mot recherché, mais dans une acception qui ne correspond pas à ce que l'on désire ou au domaine considéré.
Réduction du rang
Après avoir construit la matrice des occurrences, la LSA permet de trouver une matrice de rang plus faible, qui donne une approximation de cette matrice des occurrences. On peut justifier cette approximation par plusieurs aspects :
- la matrice d'origine pourrait être trop grande pour les capacités de calcul de la machine — on rend ainsi le procédé réalisable, et c'est un « mal nécessaire » ;
- la matrice d'origine peut être « bruitée » : des termes n'apparaissant que de manière anecdotique — on « nettoie » ainsi la matrice, c'est une opération qui améliore les résultats ;
- la matrice d'origine peut être présumée « trop creuse » : elle contient plutôt les mots propres à chaque documents que les termes liés à plusieurs documents — c'est également un problème de synonymie.
Cependant, la réduction du rang de la matrice des occurrences a pour effet la combinaison de certaines dimensions qui peuvent ne pas être pertinentes. On s'arrange en général pour — tant que c'est possible — fusionner les termes de sens proches. Ainsi, on pourra effectuer la transformation :
- {(Voiture), (Camion), (Fleur)} → {(1,3452 × Voiture + 0,2828 × Camion), (Fleur)}
La synonymie est résolue de cette manière. Mais quelques fois cela n'est pas possible. Dans ces cas, la LSA peut effectuer la transformation suivante :
- {(Voiture), (Bouteille), (Fleur)} -→ {(1,3452 × Voiture + 0,2828 × Bouteille), (Fleur)}
Ce regroupement est beaucoup plus difficile à interpréter — il est justifié d'un point de vue mathématique, mais n'est pas pertinent pour un locuteur humain.
Description
Construction de la matrice des occurrences
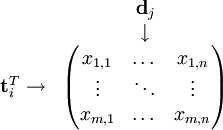
Soit X la matrice où l'élément (i, j) décrit les occurrences du terme i dans le document j — par exemple la fréquence. Alors X aura cette allure :
Une ligne de cette matrice est ainsi un vecteur qui correspond à un terme, et dont les composantes donnent sa présence (ou plutôt, son importance) dans chaque document :
De même, une colonne de cette matrice est un vecteur qui correspond à un document, et dont les composantes sont l'importance dans son propre contenu de chaque terme.
Corrélations
Le produit scalaire :
entre deux vecteurs « termes » donne la corrélation entre deux termes sur l'ensemble du corpus. Le produit matriciel XXT contient tous les produits scalaires de cette forme : l'élément (i, p) — qui est le même que l'élément (p, i) car la matrice est symétrique — est ainsi le produit scalaire :
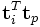 (
(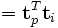 ).
).
De même, le produit XTX contient tous les produits scalaires entre les vecteurs « documents », qui donnent leurs corrélations sur l'ensemble du lexique :
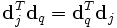 .
.
Décomposition en valeurs singulières
On effectue alors une décomposition en valeurs singulières sur X, qui donne deux matrices orthonormales U et V et une matrice diagonale Σ. On a alors :
- X = UΣVT
Les produits de matrice qui donnent les corrélations entre les termes d'une part et entre les documents d'autre part s'écrivent alors :
Puisque les matrices :
- ΣΣT et ΣTΣ
sont diagonales, U est faite des vecteurs propres de XXT, et V est faite des vecteurs propres de XTX. Les deux produits ont alors les mêmes valeurs propres non-nulles — qui correspondent aux coefficients diagonaux non-nuls de ΣΣT. La décomposition s'écrit alors :
Les valeurs
 sont les valeurs singulières de X. D'autre part, les vecteurs
sont les valeurs singulières de X. D'autre part, les vecteurs  et
et  sont respectivement singuliers à gauches et à droite.
sont respectivement singuliers à gauches et à droite.On remarque également que la seule partie de U qui contribue à
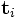 est la i ième ligne. On note désormais ce vecteur
est la i ième ligne. On note désormais ce vecteur 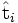 . De même la seule partie de VT qui contribue à
. De même la seule partie de VT qui contribue à 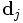 est la j ième colonne, que l'on note
est la j ième colonne, que l'on note 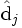 .
.Espace des concepts
Lorsqu'on sélectionne les k plus grandes valeurs singulières, ainsi que les vecteurs singuliers correspondants dans U et V, on obtient une approximation de rang k de la matrice des occurrences[3].
Le point important, c'est qu'en faisant cette approximation, les vecteurs « termes » et « documents » sont traduits dans l'espace des « concepts ».
Le vecteur
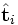 possède alors k composantes, qui chacune donne l'importance du terme i dans chacun des k différents « concepts ». De même, le vecteur
possède alors k composantes, qui chacune donne l'importance du terme i dans chacun des k différents « concepts ». De même, le vecteur 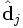 donne l'intensité des relations entre le document j et chaque concept. On écrit cette approximation sous la forme suivante :
donne l'intensité des relations entre le document j et chaque concept. On écrit cette approximation sous la forme suivante :On peut alors effectuer les opérations suivantes :
- voir dans quelle mesure les documents j et q sont liés, dans l'espace des concepts, en comparant les vecteurs et
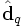 . On peut faire cela en évaluant la similarité cosinus, qui peut se calculer ainsi :
. On peut faire cela en évaluant la similarité cosinus, qui peut se calculer ainsi :
-
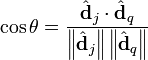 ;
;
- comparer les termes i et p en comparant les vecteurs et
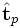 par la même méthode ;
par la même méthode ; - une requête étant donnée, on peut la traiter comme un « mini-document » et la comparer dans l'espace des concepts à un corpus pour construire une liste des documents les plus pertinents. Pour faire cela, il faut déjà traduire la requête dans l'espace des concepts, en la transformant de la même manière que les documents. Si la requête est q, il faut calculer :
-
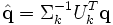 avant de comparer ce vecteur au corpus.
avant de comparer ce vecteur au corpus.
Implémentations
La décomposition en valeurs singulières est généralement calculée par des méthodes optimisées pour les matrices larges — par exemple l'algorithme de Lanczos — par des programmes itératifs, ou encore par des réseaux de neurones, cette dernière approche ne nécessitant pas que l'intégralité de la matrice soit gardée en mémoire [4].
Analyse sémantique latente probabiliste (PLSA)
Le modèle statistique de l'analyse sémantique latente ne correspond pas aux données observées : elle suppose que les mots et documents forment ensemble un modèle gaussien (c'est l'hypothèse ergodique), alors qu'on observe une distribution de Poisson.
Ainsi, une approche plus récente est l'analyse sémantique latente probabiliste, ou PLSA (de l'anglais : Probabilistic latent semantic analysis), basée sur un modèle multinomial.
Annexes
Bibliographie
- (en) The Latent Semantic Indexing home page, Université du Colorado ;
- (en) Thomas Landauer, P. W. Foltz, et D. Laham, « Introduction to Latent Semantic Analysis », dans Discourse Processes, vol. 25, 1998, p. 259-284 [texte intégral]
- (en)M.W. Berry, S.T. Dumais, G.W. O'Brien, « Using Linear Algebra for Intelligent Information Retrieval », dans {{{périodique}}}, 1995 [texte intégral] PDF.
- (en) Latent Semantic Analysis, InfoVis
- (en) T. Hofmann, Probabilistic Latent Semantic Analysis, Uncertainty in Artificial Intelligence, 1999.
- (en) G. Gorell et B. Webb, « Generalized Hebbian Algorithm for Latent Semantic Analysis », Interspeech, 2005.
- (en) Fridolin Wild, « An Open Source LSA Package for R », 23 novembre 2005, CRAN. Consulté le 20 novembre 2006
- (en) Dimitrios Zeimpekis and E. Gallopoulos, « A MATLAB Toolbox for generating term-document matrices from text collections », 11 septembre 2005. Consulté le 20 novembre 2006
Notes et références
- ↑ (en) Dépôt de brevet par Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landauer, Karen Lochbaum et Lynn Streeter
- ↑ (en) S. Deerwester, S. Dumais, G. W. Furnas, T. K. Landauer, R. Harshman, « Indexing by Latent Semantic Analysis », dans Journal of the Society for Information Science, vol. 41, no 6, 1990, p. 391-407 [texte intégral]
- ↑ On peut même montrer que c'est la meilleure approximation, au sens de la norme de Frobenius. Une preuve est donnée dans l'article sur la décomposition en valeurs singulières.
- ↑ (en) « Generalized Hebbian Algorithm for Incremental Latent Semantic Analysis » Geneviève Gorell et Brandyn Webb.
Source
- (en) Cet article est partiellement ou en totalité issu d’une traduction de l’article de Wikipédia en anglais intitulé « Latent semantic analysis ».
Voir aussi
Articles connexes
Liens externes
- (en) The Semantic Indexing Project, un projet Open Source d'indexation sémantique latente.
 Portail de l’informatique
Portail de l’informatique Portail de la linguistique
Portail de la linguistique
Catégories : Intelligence artificielle | Traitement automatique du langage naturel
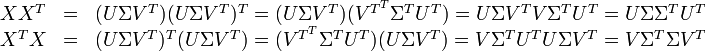
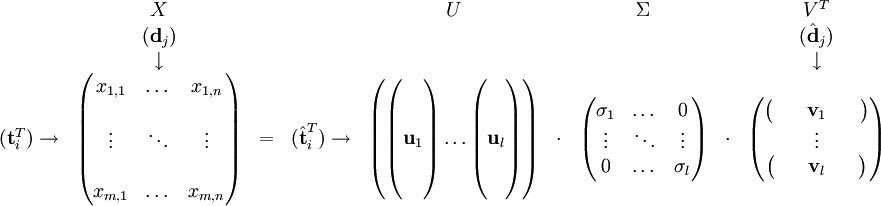
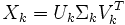
Wikimedia Foundation. 2010.