- Compute Unified Device Architecture
-
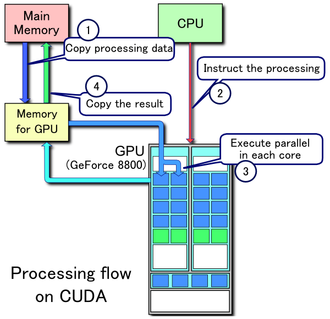 Schéma de principe de l'architecture CUDA
Schéma de principe de l'architecture CUDA
CUDA (Compute Unified Device Architecture) est une technologie de GPGPU (General-Purpose Computing on Graphics Processing Units), c'est-à-dire qu'on utilise un processeur graphique (GPU) pour exécuter des calculs généraux habituellement exécutés par le processeur central (CPU). CUDA permet de programmer des GPU en C. Cette technologie a été développée par NVIDIA pour leurs cartes graphiques GeForce 8 Series, et utilise un pilote unifié utilisant une technique de streaming (flux continu). NVIDIA s'engage à ce que ses futures cartes graphiques restent compatibles avec CUDA.
Le kit de développement pour CUDA a été publié le 15 février 2007[1].
Sommaire
Utilisations de CUDA
Architecture Tesla
L'architecture Tesla, qui offre selon NVidia le pouvoir de calcul d'un superordinateur (4 téraflops en simple précision, 80 gigaflops en double précision) pour une somme de 10 000 dollars, est construite sur CUDA.
Boîte à outils Pyrit
Pyrit est une boîte à outils Open Source utilisant le parallélisme massif de calcul de CUDA pour craquer des clés Wi-Fi WPA-PSK et WPA2-PSK en gagnant un facteur 20 sur le même calcul réalisé par le processeur seul. Cela ne signifie pas nécessairement « le crépuscule du Wi-Fi » comme cela a été parfois annoncé[2], mais diminue tout de même de trois ordres de grandeur[3] le degré de protection escompté pour les communications.
Exemples
Exemple avec émulation de carte
#include <stdio.h> #include <stdlib.h> #include <cuda.h> #include <cuda_runtime.h> __global__ void mykernel(float * A1, float * A2, float * R) { int p = threadIdx.x; R[p] = A1[p] + A2[p]; } int main() { float A1[]={1,2,3,4,5,6,7,8,9}; float A2[]={10,20,30,40,50,60,70,80,90}; float R[9]; //9 additions, aucune boucle ! mykernel<<<1,9>>>(A1,A2,R); //sortie à l'ecran for(int i=0; i<9 ; i++) printf("%f\n",R[i]); }
Cet exemple marche seulement si on émule la carte graphique car on ne recopie pas les données sur la carte.
Compilation par :
nvcc -deviceemu -o run prog.cu
Exemple avec une carte graphique NVidia
#include <stdio.h> #include <stdlib.h> #include <cuda.h> #include <cuda_runtime.h> __global__ void mykernel(float * A1, float * A2, float * R) { int p = threadIdx.x; R[p] = A1[p] + A2[p]; } int main() { float A1[]={1,2,3,4,5,6,7,8,9}; float A2[]={10,20,30,40,50,60,70,80,90}; float R[9]; int taille_mem=sizeof(float) * 9; // on alloue de la memoire sur la carte graphique float * a1_device; float * a2_device; float * r_device; cudaMalloc ( (void**) &a1_device, taille_mem); cudaMalloc ( (void**) &a2_device, taille_mem); cudaMalloc ( (void**) &r_device, taille_mem); // on copie les donnees sur la carte cudaMemcpy( a1_device,A1,taille_mem,cudaMemcpyHostToDevice); cudaMemcpy( a2_device,A2,taille_mem,cudaMemcpyHostToDevice); //9 additions, aucune boucle ! mykernel<<<1,9>>>(a1_device,a2_device,r_device); // on recupere le resultat cudaMemcpy(R,r_device,taille_mem,cudaMemcpyDeviceToHost); //sortie à l'ecran for(int i=0; i<9 ; i++) printf("%f\n",R[i]); }
Compilation par :
nvcc -o add_cuda add_cuda.cu
Voir aussi
installation de CUDA en fonction des systemes d'exploitation. points spécifiques
Produits concurrents
- OpenCL (logiciel libre créé à l'origine par Apple, sous licence BSD)
- Larrabee de Intel (encore en projet)
- ATI Stream.
- Compute Shaders de Direct3D 11
Articles connexes
Liens externes
- (en) Page sur CUDA du site de NVIDIA
- (fr) Article sur CUDA Tom's Hardware
- (fr) Explications sur CUDA du site Hardware.fr
- (fr) Introduction à CUDA sur le site Developpez.com
Références
Wikimedia Foundation. 2010.