- Regression logistique
-
Régression logistique
 Pour les articles homonymes, voir Régression.
Pour les articles homonymes, voir Régression.La régression logistique est une technique statistique qui a pour objectif, à partir d’un fichier d’observations, de produire un modèle permettant de prédire les valeurs prises par une variable catégorielle, le plus souvent binaire, à partir d’une série de variables explicatives continues et/ou binaires.
La régression logistique est largement répandue dans de nombreux domaines. On peut citer de façon non-exhaustive :
- En médecine, elle permet par exemple de trouver les facteurs qui caractérisent un groupe de sujets malades par rapport à des sujets sains.
- Dans le domaine des assurances, elle permet de cibler une fraction de la clientèle qui sera sensible à une police d’assurance sur tel ou tel risque particulier.
- Dans le domaine bancaire, pour détecter les groupes à risque lors de la souscription d’un crédit.
- En économétrie, pour expliquer une variable discrète. Par exemple, les intentions de vote aux élections.
Le succès de la régression logistique repose notamment sur les nombreux outils qui permettent d’interpréter de manière approfondie les résultats obtenus.
Par rapport aux techniques connues en régression, notamment la régression linéaire, la régression logistique se distingue essentiellement par le fait que la variable expliquée est catégorielle.
En tant que méthode de prédiction pour variable catégorielle, la régression logistique est tout à fait comparable aux techniques supervisées proposées en apprentissage automatique (arbre de décision, réseaux de neurones, etc.), ou encore l’analyse discriminante prédictive en statistique exploratoire. Il est notamment possible de les mettre en concurrence pour choisir le modèle le plus adapté pour un problème de prédiction à résoudre.
Sommaire
Notations, hypothèses et estimations
Notations
Dans ce qui suit, nous noterons
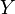 la variable à prédire (variable expliquée),
la variable à prédire (variable expliquée), 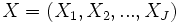 les variables prédictives (variables explicatives).
les variables prédictives (variables explicatives).Dans le cadre de la régression logistique binaire, la variable
prend deux modalités possibles 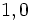 . Les variables
. Les variables 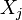 sont exclusivement continues ou binaires.
sont exclusivement continues ou binaires.- Pour effectuer l'estimation, nous disposons d'un échantillon
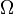 d'effectif
d'effectif 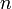 . Nous notons
. Nous notons 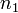 (resp.
(resp. 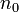 ) les observations correspondants à la modalité
) les observations correspondants à la modalité 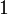 (resp.
(resp. 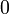 ) de .
) de .
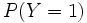 (resp.
(resp. 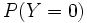 ) est la probabilité a priori pour que
) est la probabilité a priori pour que 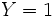 (resp.
(resp. 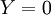 ). Pour simplifier, nous écrirons
). Pour simplifier, nous écrirons 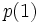 (resp.
(resp. 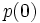 ).
).
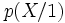 (resp.
(resp. 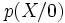 ) est la distribution conditionnelle des X sachant la valeur prise par
) est la distribution conditionnelle des X sachant la valeur prise par
- Enfin, la probabilité a posteriori d'obtenir la modalité de (resp. ) sachant la valeur prise par
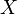 est représentée par
est représentée par 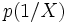 (resp.
(resp. 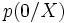 ).
).
Hypothèse fondamentale
La régression logistique repose sur l’hypothèse fondamentale suivante
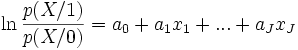
Une vaste classe de distributions répondent à cette spécification, la distribution multinormale déjà vue en analyse discriminante linéaire par exemple, mais également d’autres distributions, notamment celles où les variables explicatives sont booléennes (0/1).Par rapport à l’analyse discriminante toujours, ce ne sont plus les densités conditionnelles
et qui sont modélisées mais le rapport de ces densités. La restriction introduite par l'hypothèse est moins forte.Le modèle LOGIT
La spécification ci-dessus peut être écrite de manière différente. On désigne par le terme LOGIT de
l’expression suivante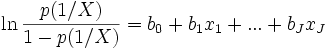
- Il s’agit bien d’une "régression" car on veut montrer une relation de dépendance entre une variable à expliquer et une série de variables explicatives.
- Il s’agit d’une régression "logistique" car la loi de probabilité est modélisée à partir d’une loi logistique.
En effet, après transformation de l’équation ci-dessus, nous obtenons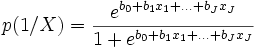
Remarque : Equivalence des expressions
Nous sommes partis de deux expressions différentes pour aboutir au modèle logistique. Nous observons ici la concordance entre les coefficients
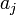 et
et 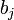 . Reprenons le LOGIT
. Reprenons le LOGIT
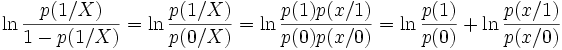
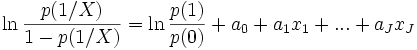
Nous constatons que
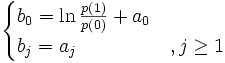
Estimation — Principe du maximum de vraisemblance
A partir d’un fichier de données, nous devons estimer les coefficients
de la fonction LOGIT. Il est très rare de disposer pour chaque combinaison possible des 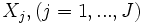 , même si ces variables sont toutes binaires, de suffisamment d’observations pour disposer d’une estimation fiable des probabilités
, même si ces variables sont toutes binaires, de suffisamment d’observations pour disposer d’une estimation fiable des probabilités 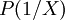 et
et 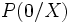 . La méthode des moindres carrés ordinaire est exclue. La solution passe par une autre approche : la maximisation de la vraisemblance.
. La méthode des moindres carrés ordinaire est exclue. La solution passe par une autre approche : la maximisation de la vraisemblance.
La probabilité d’appartenance d’un individu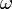 à un groupe, que nous pouvons également voir comme une contribution à la vraisemblance, peut être décrit de la manière suivante
à un groupe, que nous pouvons également voir comme une contribution à la vraisemblance, peut être décrit de la manière suivante![P(Y(\omega)=1/X(\omega))^{Y(\omega)} \times [1 - P(Y(\omega)=1/X(\omega))]^{1 - Y(\omega)}](/pictures/frwiki/52/4d9c4fbe6939161da15906752520ec6d.png)
La vraisemblance d’un échantillon s’écrit alors :![L = \prod_{\omega} P(Y(\omega)=1/X(\omega))^{Y(\omega)} \times [1 - P(Y(\omega)=1/X(\omega))]^{1 - Y(\omega)}](/pictures/frwiki/102/fc23b7abacc139a6a2f9ba2a15b838fb.png)
Les paramètres
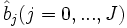 qui maximisent cette quantité sont les estimateurs du maximum de vraisemblance de la régression logistique.
qui maximisent cette quantité sont les estimateurs du maximum de vraisemblance de la régression logistique.L’estimation dans la pratique
Dans la pratique, les logiciels utilisent une procédure approchée pour obtenir une solution satisfaisante de la maximisation ci-dessus. Ce qui explique d’ailleurs pourquoi ils ne fournissent pas toujours des coefficients strictement identiques. Les résultats dépendent de l’algorithme utilisé et de la précision adoptée lors du paramétrage du calcul.
Dans ce qui suit, nous notons
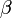 le vecteur des paramètres à estimer. La procédure la plus connue est la méthode Newton-Raphson qui est une méthode itérative du gradient (voir Algorithme d'optimisation. Elle s’appuie sur la relation suivante :
le vecteur des paramètres à estimer. La procédure la plus connue est la méthode Newton-Raphson qui est une méthode itérative du gradient (voir Algorithme d'optimisation. Elle s’appuie sur la relation suivante :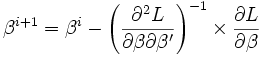
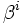 est la solution courante à l'étape
est la solution courante à l'étape 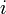 .
. 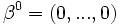 est une initialisation possible ;
est une initialisation possible ;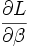 est le vecteur des dérivées partielles première de la vraisemblance ;
est le vecteur des dérivées partielles première de la vraisemblance ;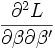 est la matrice des dérivées partielles secondes de la vraisemblance ;
est la matrice des dérivées partielles secondes de la vraisemblance ;- les itérations sont interrompues lorsque la différence entre deux vecteurs de solutions successifs sont négligeables.
Cette dernière matrice, dite Matrice hessienne, est intéressante car son inverse représente l’estimation de la matrice de variance co-variance de
. Elle sera mise en contribution dans les différents tests d’hypothèses pour évaluer la significativité des coefficients.Évaluation
Matrice de confusion
L’objectif étant de produire un modèle permettant de prédire avec le plus de précision possible les valeurs prises par une variable catégorielle
, une approche privilégiée pour évaluer la qualité du modèle serait de confronter les valeurs prédites avec les vraies valeurs prises par : c’est le rôle de la matrice de confusion. On en déduit alors un indicateur simple, le taux d’erreur ou le taux de mauvais classement, qui est le rapport entre le nombre de mauvaises prédictions et la taille de l’échantillon.Lorsque la matrice de confusion est construite sur les données qui ont servi à élaborer le modèle, le taux d’erreur est souvent trop optimiste, ne reflétant pas les performances réelles du modèle dans la population. Pour que l’évaluation ne soit pas biaisée, il est conseillé de construire cette matrice sur un échantillon à part, dit échantillon de test. Par opposition à l’échantillon d’apprentissage, il n’aura pas participé à la construction du modèle.
Le principal intérêt de cette méthode est qu’elle permet de comparer n’importe quelle méthode de classement et sélectionner ainsi celle qui s’avère être la plus performante face à un problème donné.
Évaluation statistique de la régression
Il est possible d’exploiter un schéma probabiliste pour effectuer des tests d’hypothèses sur la validité du modèle. Ces tests reposent sur la distribution asymptotique des estimateurs du maximum de vraisemblance.
Pour vérifier la significativité globale du modèle, nous pouvons introduire un test analogue à l’évaluation de la régression linéaire multiple. L’hypothèse nulle s’écrit
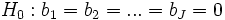 , que l’on oppose à l’hypothèse alternative
, que l’on oppose à l’hypothèse alternative 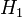 : un des coefficients au moins est non nul
: un des coefficients au moins est non nulLa statistique du rapport de vraisemblance s’écrit
![\Lambda = 2 \times [l(J+1)-l(1)]\,](/pictures/frwiki/55/7494fb54e8456a4e90ab6776948f8b36.png) , elle suit une loi du
, elle suit une loi du 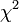 à
à 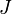 degrés de libertés.
degrés de libertés.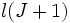 est le logarithme de la vraisemblance du modèle avec l’ensemble des variables (donc J+1 coefficients en comptant la constante) et,
est le logarithme de la vraisemblance du modèle avec l’ensemble des variables (donc J+1 coefficients en comptant la constante) et,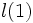 la log vraisemblance du modèle réduit à la seule constante.
la log vraisemblance du modèle réduit à la seule constante.
Si la probabilité critique (la p-value) est inférieure au niveau de signification que l’on s’est fixé, on peut considérer que le modèle est globalement significatif. Reste à savoir quelles sont variables qui jouent réellement un rôle dans cette relation.
Évaluation individuelle des coefficients
Dans le cas où l’on cherche à tester le rôle significatif d’une variable. Nous réalisons le test suivant
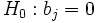 , contre
, contre 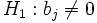 .
.La statistique de WALD répond à ce test, elle s’écrit
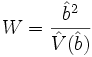 , elle suit une loi du à degré de liberté.
, elle suit une loi du à degré de liberté.N.B. : La variance estimée du coefficient
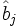 est lue dans l’inverse de la matrice hessienne vue précédemment.
est lue dans l’inverse de la matrice hessienne vue précédemment.Évaluation d'un bloc de coefficients
Les deux tests ci-dessus sont des cas particuliers du test de significativité d’un bloc de coefficients. Ils découlent du critère de la "déviance" qui compare la vraisemblance entre le modèle courant et le modèle saturé (le modèle dans lequel nous avons tous les paramètres).
L’hypothèse nulle s’écrit dans ce cas
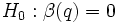 , où
, où 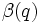 représente un ensemble de
représente un ensemble de 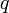 coefficients simultanément à zéro.
coefficients simultanément à zéro.La statistique du test
![W(q) = 2 \times [l(J+1)-l(J+1-q)]\,](/pictures/frwiki/102/faa769d9ce032dcda95781d0d781b70f.png) suit une loi du à degrés de libertés.
suit une loi du à degrés de libertés.
Ce test peut être très utile lorsque nous voulons tester le rôle d’une variable explicative catégorielle à q + 1 modalités dans le modèle. Après recodage, nous introduisons effectivement variables indicatrices dans le modèle. Pour évaluer le rôle de la variable catégorielle prise dans son ensemble, quelle que soit la modalité considérée, nous devons tester simultanément les coefficients associés aux variables indicatrices.Autres évaluations
D’autres procédures d’évaluation sont couramment citées s’agissant de la régression logistique. Nous noterons entre autres le test de Hosmer-Lemeshow qui s’appuie sur le « score » (la probabilité d’affectation à un groupe) pour ordonner les observations. En cela, elle se rapproche d’autres procédés d’évaluation de l’apprentissage telles que les courbes ROC qui sont nettement plus riches d’informations que la simple matrice de confusion et le taux d’erreur associé.
Un exemple
À partir des données disponibles sur le site du cours en ligne de Régression logistique (Paul-Marie Bernard, Université du Québec – Chapitre 5), nous avons construit un modèle de prédiction qui vise à expliquer le « Faible Poids (Oui/Non) » d’un bébé à la naissance. Les variables explicatives sont : FUME (le fait de fumer ou pas pendant la grossesse), PREM (historique de prématurés aux accouchements ultérieurs), HT (historique de l’hypertension), VISITE (nombre de visites chez le médecin durant le premier trimestre de grossesse), AGE (âge de la mère), PDSM (poids de la mère durant les périodes des dernières menstruations), SCOL (niveau de scolarité de la mère : =1: <12 ans, =2: 12-15 ans, =3: >15 ans).
Toutes les variables explicatives ont été considérées continues dans cette analyse. Dans certains cas, SCOL par exemple, il serait peut être plus judicieux de les coder en variables indicatrices.
Lecture des résultats
Les résultats sont consignés dans le tableau suivant.
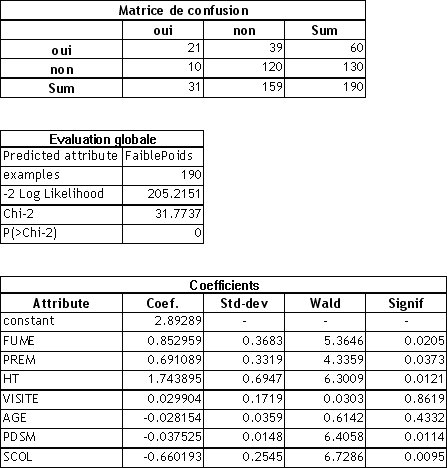
- Dans la matrice de confusion, nous lisons que sur les données en apprentissage, le modèle de prédiction réalise 10 + 39 = 49 mauvaises prédictions. Le taux d’erreur en resubstitution est de 49/190 = 25,78%
- La statistique du rapport de vraisemblance LAMBDA est égale à 31.77, la probabilité critique associée est 0. Le modèle est donc globalement très significatif, il existe bien une relation entre les variables explicatives et la variable expliquée.
- En étudiant individuellement les coefficients liés à chaque variable explicative, au risque de 5%, nous constatons que FUME, PREM et HT sont néfastes au poids du bébé à la naissance (entraînent un faible poids du bébé) ; PDSM et SCOL en revanche semblent jouer dans le sens d’un poids plus élevé du bébé. VISITE et AGE ne semblent pas jouer de rôle significatif dans cette analyse.
Cette première analyse peut être affinée en procédant à une sélection de variables, en étudiant le rôle concomittant de certaines variables, etc. Le succès de la régression logistique repose justement en grande partie sur la multiplicité des outils d’interprétations qu’elle propose. Avec les notions d’odds, d’odds ratios et de risque relatif, calculés sur les variables dichotomiques, continues ou sur des combinaisons de variables, le statisticien peut analyser finement les causalités et mettre en évidence les facteurs qui pèsent réellement sur la variable à expliquer.Déploiement
Pour classer un nouvel individu
, nous devons appliquer la règle de Bayes :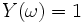 ssi
ssi 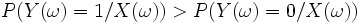
Qui est équivalent à
ssi 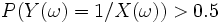
Si nous considérons la fonction LOGIT, cette procédure revient à s’appuyer sur la règle d’affectation :
ssi 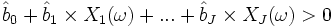
Prenons l’observation suivante = (FUME = 1 « oui » ; PREM = 1 « un prématuré dans l’historique de la mère » ; HT = 0 « non » ; VISITE = 0 « pas de visite chez le médecin pendant le premier trimestre de grossesse » ; AGE = 28 ; PDSM = 54.55 ; SCOL = 2 « entre 12 et 15 ans »).
= (FUME = 1 « oui » ; PREM = 1 « un prématuré dans l’historique de la mère » ; HT = 0 « non » ; VISITE = 0 « pas de visite chez le médecin pendant le premier trimestre de grossesse » ; AGE = 28 ; PDSM = 54.55 ; SCOL = 2 « entre 12 et 15 ans »).
En appliquant l’équation ci-dessus, nous trouvons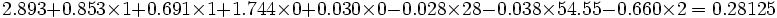 . Le modèle donc prédit un bébé de faible poids pour cette personne.
. Le modèle donc prédit un bébé de faible poids pour cette personne.Ce qui est justifié puisqu’il s’agit de l’observation n°131 de notre fichier, et elle a donné lieu effectivement à la naissance d’un enfant de faible poids.
Redressement
La règle d’affectation ci-dessus est valide si l’échantillon est issu d’un tirage au hasard dans la population. Ce n’est pas toujours le cas. Dans de nombreux domaines, nous fixons au préalable les effectifs des classes
et , puis nous procédons au recueil des données dans chacun des groupes. On parle alors de tirage rétrospectif. Il est dès lors nécessaire de procéder à un redressement. Si les coefficients associés aux variables de la fonction logit ne sont pas modifiés, la constante en revanche doit être corrigée en tenant compte des effectifs dans chaque classe ( et ) et des vraies probabilités a priori et (cf. les références ci-dessous).Variantes
La régression logistique s’applique directement lorsque les variables explicatives sont continues ou dichotomiques. Lorsqu’elles sont catégorielles, il est nécessaire de procéder à un recodage. Le plus simple est le codage binaire. Prenons l’exemple d’une variable habitat prenons trois modalités {ville, périphérie, autres}. Nous créerons alors deux variables binaires : « habitat_ville », « habitat_périphérie ». La dernière modalité se déduit des deux autres, lorsque les deux variables prennent simultanément la valeur 0, cela indique que l’observation correspond à « habitat = autres ».
Enfin, il est possible de réaliser une régression logistique pour prédire les valeurs d’une variable catégorielle comportant K (K > 2) modalités. On parle de régression logistique polytomique. La procédure repose sur la désignation d’un groupe de référence, elle produit alors (K-1) combinaisons linéaires pour la prédiction. L’interprétation des coefficients est moins évidente dans ce cas.Références
- M. Bardos, Analyse Discriminante - Application au risque et scoring financier, Dunod, 2001. (chapitre 3)
- Bernard, P.-M., "Analyse des tableaux de contingence en épidémiologie", Les Presses de l'Université du Québec, 2004
- Bouyer J., Hémon D., Cordier S., Derriennic F., Stücker I., Stengel B., Clavel J., Epidémiologie - Principes et méthodes quantitatives, Les Éditions INSERM, 1993
- Hosmer D.W., Lemeshow S., Applied logistic regression, Wiley Series in Probability and Mathematical Statistics, 2000
- Kleinbaum D.G., Logistic regression. A self-learning text, Springer-Verlag, 1994.
- Kleinbaum D.G., Kupper L.L., Muller E.M., Applied regression analysis and other multivariate methods, PWS-KENT Publishing Company, Boston, 1988.
- J.P. Nakache, J. Confais, Statistique Explicative Appliquée, Technip, 2003 (Partie 2)
- Pierre-François Verhulst, « Recherches mathématiques sur la loi d'accroissement de la population », dans Nouveaux Mémoires de l'Académie Royale des Sciences et Belles-Lettres de Bruxelles, no 18, 1845, p. 1-42 [[pdf] texte intégral (page consultée le 30/05/2009)]
- R. Rakotomalala, Pratique de la régression logistique - Régression logistique binaire et polytomique, Université Lumière Lyon 2.
Logiciels
- Tanagra, un logiciel gratuit pour l'enseignement et la recherche.
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégorie : Estimation (statistique)
Wikimedia Foundation. 2010.