- Extensible markup language
-
Extensible Markup Language
Extensible Markup Language .xmlapplication/xml, text/xmlDéveloppé par
World Wide Web Consortium Type de format
Langage de balisage Standard(s)
1.0 (5e édition) Spécification
Format ouvert XML (Extensible Markup Language (en)[note 1] « langage extensible de balisage ») est un langage informatique de balisage générique. Il sert essentiellement à stocker/transférer des données de type texte Unicode structurées en champs arborescents. Ce langage est qualifié d'extensible car il permet à l'utilisateur de définir les balises des éléments.[note 2] L'utilisateur peut multiplier les espaces de nommage des balises et emprunter les définitions d'autres utilisateurs.[1],[note 3]
Le World Wide Web Consortium (W3C), promoteur de standards favorisant l'échange d'informations sur Internet, recommande la syntaxe XML pour exprimer des langages de balisages spécifiques.
De nombreux langages respectent la syntaxe XML : SVG pour des données de graphique vectorisé, XHTML pour des données de page web, RSS pour des données de syndication de contenu, XSLT pour des données de transformation d'un document XML, etc. Cette syntaxe est reconnaissable par son usage des chevrons (
< >) pour les balises d'éléments et de la chaîne<!-- -->pour les commentaires du code.L'objectif initial est de faciliter l'échange automatisé de contenus entre systèmes d'informations hétérogènes (interopérabilité). XML est une simplification du Standard Generalized Markup Language (SGML) dont il retient les principes essentiels comme :
- la structure d'un document XML est définissable et validable par un schéma,
- un document XML est entièrement transformable dans un autre document XML.
Sommaire
Historique
Dan Connolly ajoute le Standard Generalized Markup Language à la liste des activités du World Wide Web Consortium quand il y rentre en 1995. Les travaux débutent à la mi-1996 lorsque l'ingénieur Jon Bosak de Sun Microsystems élabore une charte et recrute des collaborateurs. Bosak se fait connaître dans la petite communauté de personnes qui avaient de l'expérience à la fois dans le SGML et dans le Web.
XML est compilé par un groupe de travail de onze membres[note 4], soutenu par environ 150 membres de divers groupes d'intérêt. Le débat technique a eu lieu sur la liste commune et les questions ont été résolues par consensus ou, lorsque cela a échoué, à la majorité des voix du groupe de travail. Un compte rendu des décisions de conception et de leurs justifications ont été compilées par Michael Sperberg-McQueen de Chicago, le 4 Décembre, 1997[2]. James Clark servit comme responsable technique du groupe de travail, notamment en contribuant à l'élément vide " <empty/> " et au nom " XML ". Les co-rédacteurs du cahier des charges étaient à l'origine Tim Bray, qui a notamment conduit l'informatisation du Oxford English Dictionary, et Michael Sperberg-McQueen, de l'Université de l'Illinois, qui était éditeur en chef de la DTD TEI ; accompagnés ensuite de Jean Paoli, de Microsoft, comme troisième co-éditeur[3].
Le groupe de travail XML ne s'est jamais rencontré face-à-face, la conception a été réalisée en utilisant courrier électronique et téléconférences hebdomadaires. Les principales décisions de conception ont été prises en une vingtaine de semaines de travail intense entre Juillet et Novembre 1996, lorsque le premier travail de spécification XML a été publié[4]. D'autres travaux de conception sont poursuivis jusqu'en 1997, puis le XML 1.0 est devenu une recommandation W3C le 10 février 1998.
Objectif initial
L'objectif initial de XML est expliqué au début de la spécification du 10 février 1998, la phrase est toujours d'actualité : « Son but est de permettre à du SGML générique d'être transmis, reçu et traité sur le web de la même manière que l'est HTML aujourd'hui. »(fr)[5]. SGML est un langage de balisage, employé dans les industries de la documentation et de l'édition. En adoptant cette syntaxe pour HTML, Tim Berners-Lee confrontait une technologie complexe à de plus en plus d'utilisateurs. L'objectif d'XML était de définir un langage aussi générique, mais plus simple : « XML has been designed for ease of implementation »(en), « XML a été conçu pour une facilité de mise en œuvre »(fr).
Tim Bray, dans son Annotated XML Specification (en) « la spécification XML annotée », explique plus longuement le contexte qui a rendu possible ce standard, en mentionnant notamment les contributions décisives de James Clark. À la lumière des années passées, cette spécification a rempli l'objectif qu'elle se fixait, XML a été largement suivi et favorise l'interopérabilité. Plusieurs choix ont contribué à ce succès.
- Unicode - Par défaut, SGML était en ASCII (alphabet latin sans lettre accentuée). Il apportait un système d'encodage pour les autres signes, les entités caractères que l'on trouve encore parfois en HTML (exemple :
épour é). En 1996, apparaît la version 2.0 d'Unicode, XML adoptera cet encodage par défaut. - Délimitation explicite du contenu - SGML était orienté pour la saisie humaine de textes structurés, sur des machines moins puissantes qu'aujourd'hui. Il autorisait beaucoup de raccourcis. HTML conserve par exemple les balises à fermeture optionnelle (exemple : <li>). Ces possibilités compliquaient l'implémentation de la norme. En XML, toute balise ouverte doit être fermée.
- Espace de noms - SGML insistait surtout sur la validation, sur la conformité à un modèle contraignant. XML prévoyait un usage plus souple de l'information structurée, il spécifie un moyen de faire cohabiter plusieurs vocabulaires de balises dans un même document.
Au-delà de HTML, le W3C avait d'autres projets pour lesquels une syntaxe plus facilement extensible était nécessaire. Ces directions ont annoncé une très grande plasticité de XML pour de nombreux usages. SGML était une technologie de niche, sa simplification l'a universalisé avec Internet. Il pénètre désormais la plupart des secteurs de l'informatique. Mais avant de détailler ces utilisations, il peut être utile de préciser un peu ce que c'est.
Versions
La version 1.0 d'XML a été publiée le 10 février 1998.
La version 1.1 publiée le 4 février 2004 apporte des améliorations dans le support des différentes versions d'Unicode.
Le W3C recommande aux processeurs XML de reconnaître les deux versions, bien que la première version soit beaucoup plus répandue que la seconde.
Comparaison à d'autres formats
Pour savoir à quoi ressemble du XML, le mieux est certainement d'en voir. Commençons par un exemple simplifié. Il propose une transposition du début de cet article dans un langage XML appliqué à la documentation technique, DocBook.
<!-- Un petit document XML, utilisant les définitions de Docbook. Note : ceci est un commentaire. --> <article xmlns="http://docbook.org/ns/docbook"> <!-- l'information contenue entre les balises 'article' est un article utilisant l'espace de nom défini sur http://docbook.org/ns/docbook --> <title>Extensible Markup Language</title> <!-- l'information contenue entre les balises 'title' est un titre--> <para> <!-- l'information contenue entre les balises 'para' est un paragraphe --> <acronym><!-- l'information contenue entre les balises 'acronym' est un acronyme -->XML</acronym> (Extensible Markup Language, « langage de balisage extensible »)... </para> </article>
Dans ce code, chacun peut identifier des portions de texte (exemple : Extensible, XML…) et des mots clés encadrés de chevrons (<, >) : <article>, <title>, <para>… Ce document est ouvert par le mot clé <article>, et clos par </article>. Notez la barre oblique, elle signifie la fermeture de la balise article. En XML, une balise doit toujours être fermée. À l'intérieur de cet article, il y a un titre (<title/>), un paragraphe (<para/>), et un acronyme (<acronym/>).
Ce qui est spécifique à XML, c'est le choix des chevrons pour identifier les balises, et l'obligation de les fermer. Les mots clés ne sont pas définis par la norme XML, mais par le vocabulaire choisi. En XHTML, l'élément racine aurait été <html>, en XSLT, cela peut être <xsl:stylesheet> ou <xsl:transform>. Ceci illustre la nature extensible d'XML. Ce n'est pas un jeu de noms réservés (exemple : echo, for, public, function, class…), mais plutôt des caractères réservés permettant de définir un « langage ».
Cet exemple illustre une autre spécificité de ce format. À part SGML, peu d'autres syntaxes permettent de séparer la définition sémantique de l'information (qu'est-ce qui est titre, lien, section…), de l'apparence qu'on lui souhaite (aujourd'hui un titre est souligné, demain on le voudra peut-être en bleu). Cela fait d'XML un excellent format pour conserver des textes ou des données. Pour s'en convaincre, regardons ce que la même information donne dans d'autres formats.
Formats binaires (un exemple Microsoft Word)
Les logiciels, surtout pour le grand public, aboutissent généralement à des fichiers. Le format se soucie d'abord d'être fiable et performant, mais est-il échangeable ? Le format d'enregistrement natif du traitement de texte Word est l'exemple du format binaire le plus déployé[réf. nécessaire]. Il n'est pas lisible par l'humain. Le texte est difficile à extraire, le lien avec sa structuration (gras, italique…) est difficile à reconstruire. Dans la pratique, un document Word pose beaucoup de problèmes de conservation sur le long terme.
ÐÏ à¡± á > þÿ ! # þÿÿÿ ÿÿ% ð ¿ a bjbj%ç%ç Extensible Markup Language XML (Extensible Markup Language, « langage de balisage extensible ») i 8 @ñÿ 8 N o r m a l CJ _H aJ mH sH tH N @ N T i t r e 1 ÿ [… beaucoup d'informations binaires supprimées ] ÿ ÿÿÿÿ À F Document Microsoft Word MSWordDoc Word.Document.8 ô9²q
L'éditeur, Microsoft, propose désormais un format d'enregistrement en XML.
RTF (Rich Text Format)
Afin de favoriser l'échange avec d'autres traitements de texte, Microsoft proposa RTF Rich Text Format « format texte riche » (1987). Ce n'est pas un format binaire, les commandes sont inscrites en texte lisible, mais elles ne sont pas destinées à être écrites par un humain.
{\rtf {\f2\fs36\b Extensible Markup Language}\par {\b XML} (Extensible Markup Language, « langage de balisage extensible »)... \par }On retrouve le besoin d'encadrer du contenu avec un marqueur (ici les accolades {}), d'attacher des propriétés à ces groupes. Ainsi, {\b XML} indique que les lettres XML sont en gras, bold : \b. Pour le titre, humains comme logiciels ne peuvent pas l'identifier par "\f2\fs36\b", ce code indique en fait l'apparence du paragraphe (gras, gros…). Ce format a montré qu'il pouvait fonctionner dans des logiciels, mais sa croissante complexité nous instruit sur ses limites. Il est difficilement extensible, et en tous cas, inutilisable pour structurer la sémantique d'un texte.
TEX
Donald Knuth, auteur de The Art of Computer Programming « l'Art de la programmation » s'est interrompu en 1977, excédé par la mauvaise qualité d'impression de ses ouvrages. Il développa TEX, une syntaxe très élaborée destinée à l'écriture humaine, spécialement puissante pour les équations mathématiques. On remarquera que RTF lui a repris ses séparateurs (\, {, }), mais pas son système de macros pour factoriser les commandes.
\documentclass[a4paper, 11pt]{article} \title{Extensible Markup Language} \begin{document} \maketitle \end{document}
TEX reste le standard de l'édition scientifique de qualité, en particulier pour la mise en forme des équations complexes. Toutefois, cela reste un langage de programmation dédié à la mise en forme, davantage conçu pour l'apparence des documents que pour stocker/transférer des données.
wiki
Une syntaxe wiki sait aussi séparer le contenu de la présentation.
=={{lang|en|Extensible Markup Language}}== '''XML''' ({{lang|en|Extensible Markup Language}}, « langage de balisage extensible »)…Cependant, cette structuration repose ici sur des séquences de caractères particulières (
==, '''). Or, le nombre de caractères sans signification n'est pas indéfini. Un tel format peut être approprié pour un seul type de document, mais ce n'est pas une syntaxe générique et facilement extensible.XML, format textuel, structuré, et extensible
Comparé aux langages plus haut, XML est une syntaxe générique et extensible. Il permet de structurer une grande variété de contenus, car son « langage » (vocabulaire et grammaire) peut être redéfini.[note 2]
Composants et syntaxe d'un document XML
La plupart des composants d'un document XML[XML 1] peuvent être représentés par un arbre. Ce sont donc des nœuds. Ce modèle fait d'ailleurs l'objet d'une définition très précise (DOM Document Object Model « modèle objet de document (XML) »), afin de permettre à des langages de programmation de manipuler du XML. Nous nous limiterons à énumérer les types de nœuds fondamentaux, que l'on peut identifier dans l'exemple artificiel suivant.
<?xml version="1.0" encoding="UTF-8"?> <!-- '''Commentaire''' --> <élément-document xmlns="http://exemple.org/" xml:lang=";fr"> <élément>Texte</élément> <élément>élément répété</élément> <élément> <élément>Hiérarchie récursive</élément> </élément> <élément>Texte avec<élément>un élément</élément>inclus</élément> <élément/><!-- élément vide --> <élément attribut="valeur"></élément> </élément-document>
La racine du document
/En informatique, un arbre a généralement une et une seule racine (qui n'a pas d'ancêtre). La racine d'un document XML se situe donc derrière tous les nœuds (sauf le prologue, qui n'est pas un nœud). Dans un langage d'accès à un document XML, XPath, la racine du document est notée avec la barre oblique /, comme l'arbre d'un système de fichiers Unix.
Pour être bien formé, un document XML doit avoir un et un seul élément à la racine, parfois désigné par « élément document ». La racine accepte aussi les commentaires, et des instructions de traitement, mais surtout pas de texte .
Les éléments
<élément/>L'élément[XML 2] a un nom, précisément qualifié au sein d'un espace de noms (
<espace:élément/>), et peut porter tous les types de nœuds : attributs, texte, éléments… Le fait qu'un élément puisse avoir des enfants texte et des enfants éléments a beaucoup de conséquences pour en faire un format de données très souple (comparé par exemple à une table relationnelle). La qualification des noms contribue aussi à la précision sémantique des contenus balisés.Un exemple de notice bibliographique permettra de mieux montrer le potentiel de ce format, il utilise le vocabulaire Dublin Core.
<ex:collection xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns="http://www.w3.org/1999/xhtml" xmlns:ex="http://exemple.org"> <dc:title>[[Astérix le Gaulois]]</dc:title> <ex:livre> <dc:title>[[Astérix chez les Belges]]</dc:title> <dc:creator>[[René Goscinny]]</dc:creator> <dc:creator>[[Albert Uderzo]]</dc:creator> <dc:type>Text</dc:type> <dc:description> <b>Astérix chez les Belges</b> est un album de <a href="http://fr.wikipedia.org/wiki/Bande_dessinée">bande dessinée</a> de la série Astérix le Gaulois créée par René Goscinny et Albert Uderzo. Cet album publié en 1979 est le dernier de la série écrit par René Goscinny. </dc:description> </ex:livre> </ex:collection>
- répétable
- Une même propriété peut être répétée. L'exemple montre comment indiquer qu'un livre a plusieurs auteurs (dc:creator). Dans un format tabulaire, avec un nombre de colonnes défini, ce n'est pas impossible, mais moins spécifié.
- ordonné
- L'ordre des éléments est conservé. Quel que soit le langage employé, un outil XML doit permettre de distinguer le premier auteur du second (exemple : en XPath,
/ex:collection/ex:livre/dc:creator[1]= "[[René Goscinny]]",/ex:collection/ex:livre/dc:creator[2]= "[[Albert Uderzo]]"). - hiérarchique
- Les éléments XML sont imbricables. Ceci rend ce format particulièrement adapté à représenter des arbres. Ici, on s'est limité à 2 niveaux (
/ex:collection/ex:livre), une collection avec un titre (Astérix le Gaulois), et un exemple d'ouvrage de cette collection (Astérix chez les Belges). XML permet une récursivité complète. Par exemple, un livre, ou une thèse, peut être formaté très économiquement avec un élément <section>. La partie 2.3.5 correspondra à une structure d'imbrication XML/section[2]/section[3]/section[5]. - mélangeable
- Enfin, ce qui fait qu'XML est plus qu'un format de données, c'est la possibilité de mélanger du texte et des éléments. L'exemple montre comment le texte de la description (dc:description) est enrichi avec des balises XHTML (du gras <b> et un lien <a>).
Noms qualifiés - Cette souplesse, et l'eXtensibilité de XML est contrôlée par la qualification des noms. Vous aurez remarqué dans l'exemple de code que la plupart des éléments sont des liens. Comme il s'agit de standards, ils disposent d'une documentation officielle en ligne. Pour une notion commune comme un titre, cela ne semble pas nécessaire. Mais pour des noms beaucoup plus ambigus, comme type, il est très important de déterminer le vocabulaire dans lequel interpréter le mot. Ainsi, Dublin Core est un vocabulaire de métadonnées bibliographiques, type qualifiera des types de document : Text, Image, Sound… Dans un vocabulaire dédié à la documentation informatique comme Docbook, type a le sens de type de données.
xmlns="URI" - En XML, les noms d'éléments devraient toujours être identifiés par une URI. C'est l'objet des attributs xmlns:* sur l'élément racine de l'exemple (
xmlns:dc="http://purl.org/dc/elements/1.1/") et des préfixes sur certains noms (dc:type est identifié par l'URI de l'attribut xmlns:dc). Il n'est pas nécessaire ici de détailler plus cette syntaxe. L'essentiel est de retenir qu'en XML, le nom d'un élément ne se choisit pas au hasard, qu'il résulte d'un travail de modélisation, qu'il est précisément identifié.Le texte
Un nœud texte[XML 3] n'a pas d'enfants, il est toujours contenu dans un élément. Par défaut, il sera traité comme de l'Unicode en UTF-8 ou UTF-16. XML permet de spécifier d'autres encodages dans le prologue (ex. :
<?xml version="1.0" encoding="ISO-8859-1"?>). Ce simple choix a déjà apporté une énorme simplification aux problèmes d'encodages que l'on rencontre encore en informatique.Le traitement des espaces et sauts de lignes en XML[XML 4] peut apporter quelques surprises. Sous sa forme texte, un fichier XML sera probablement indenté par son auteur. La recommandation n'oblige pas un processeur XML à conserver ces espaces non significatifs, sauf instructions particulières (exemple : bloc préformaté <pre>). Il en résulte que le texte XML proposé à un processeur peut ne pas revenir à l'identique après traitement, ce qui cause des désagréments dans certaines applications.
texte mêlé - Dans le cas des textes mêlés (exemple :
<p> du texte en <b>gras</b> dans un paragraphe</p>), l'élément parent a plusieurs enfants texte et éléments qui se succèdent, ce n'est pas le texte qui contient un élément (exemple : p/node()[1]="du texte en ", p/node()[2]="<b>gras</b>", p/node()[3]=" dans un paragraphe"). Cette petite remarque n'a d'importance que dans certaines interfaces de manipulation XML (DOM), elle permet aussi de fixer la définition.Les attributs,
<élément attribut="valeur"/>Un attribut est un nom et une valeur, la valeur peut être vide <element attribut=""/>, mais pas nulle
<element attribut>(cette écriture était permise en SGML, on la rencontre encore parfois à propos d'HTML, mais elle n'est pas acceptée en XML). Un nom d'attribut a les mêmes possibilités de qualification qu'un nom d'élément.La valeur est un texte sans élément (ni autres nœuds). Un attribut est toujours porté par un élément. Un attribut est unique. La répétition d'un attribut de même nom sur le même élément provoquera une erreur du processeur XML. L'ordre des attributs n'est pas significatif, et peut ne pas être conservé dans certains traitements. <element attribut1="valeur1" attribut2="valeur2"/> et <element attribut2="valeur2" attribut1="valeur1"/> sont équivalents pour un processeur XML, même s'ils sont écrits différemment.
Les commentaires
<!-- -->En XML, les commentaires[XML 5] sont délimités par
<!--et-->. Le contenu d'un commentaire ne sera pas interprété.<!-- Cet <élément> est mal formé mais cela est autorisé dans un commentaire -->.La chaîne de caractères «
--», pour des raisons de compatibilité avec SGML, ne peut apparaître dans le contenu du commentaire.Style - Il est théoriquement possible de traiter le contenu des commentaires XML avec un processeur. Un exemple où cela peut être utile : transformer de la programmation en XML (exemple : XSLT) afin d'en fournir la documentation. Mais il s'agit d'un cas limite, une application XML ne doit pas s'appuyer sur le contenu des commentaires.
Le prologue
En XML, le prologue[XML 6] est constitué de la déclaration XML
<?xml version="1.0"?>, et de la déclaration de type de document (DOCTYPE). La déclaration XML est obligatoire à partir de la version 1.1. La déclaration DOCTYPE avait une grande importance en SGML. Elle attache le document traité par un processeur à son schéma ( DTD, Document Type Definition, « Définition de Type de Document »), afin de le valider, et d'interpréter certains raccourcis (les entités). Désormais, il existe plusieurs langages de validation, et parfois plusieurs manières de les attacher. La déclaration DOCTYPE n'a plus la même importance.Autres nœuds
Afin d'être complet on mentionnera aussi :
- Les instructions de traitement[XML 7],
<?xml-stylesheet href="transform.xsl" type="text/xsl"?> <?clé valeur?>, des nœuds destinés aux logiciels traitant le XML ; - Les sections d'échappement[XML 8],
<![CDATA[<ceci> ne sera pas considéré comme un élément ]]>.
Utilisations et langages dérivés
Article détaillé : catégorie:XML.SGML était une syntaxe générique, permettant de définir des langages spécialisés, comme HTML, mais il était surtout dédié au balisage de documents. En simplifiant SGML, les concepteurs d'XML prévoyaient d'élargir l'usage des chevrons (< >) à bien d'autres emplois, comme par exemple, la programmation. Les premiers langages basés sur XML par le W3C dessinent plusieurs directions d'utilisation.
- 1999, RDF Resource Description Framework(en) « cadre de description de ressource »(fr). Ce modèle abstrait vise à définir un réseau de métadonnées adapté au web, représentable en XML.
- 1999, XSLT eXtended Stylesheet Language Transformations « langage XML de feuilles de style, transformations ». Afin d'employer XML, il faut pouvoir le transformer. James Clark avait écrit un langage équivalent pour SGML (DSSSL, 1996), avec XSLT, il propose une syntaxe XML, permettant par exemple de transformer un contenu XML vers (x)HTML, ou XSL-FO.
- 2000, XSL-FO eXtended Stylesheet Language - Formatting Object « langage XML de feuilles de style - Formatage d'objets ». XSL-FO est un langage de description de document permettant de composer un livre, ou un document PDF. C'était un complément indispensable à XML pour les industries de l'édition.
- Enfin, il fallait une nouvelle syntaxe schéma tenant compte des espaces de noms pour remplacer les DTDs (ce qui deviendra XML Schema).
Quelques mois après sa sortie, XML est donc utilisé pour encoder des données, programmer des transformations, représenter un objet imprimable, et définir le schéma d'un document XML. Ceci annonce la variété des utilisations de cette syntaxe. Quelques années après, le catalogue est beaucoup plus important, couvrant des usages comme :
- langage de balisage de documents,
- format de données,
- langage de description de format de document (DSDL),
- langage de représentation (texte, image…),
- langage de programmation,
- protocole de communication.
Ces catégories permettent une classification approximative des langages à base XML (ou acceptant une expression XML). La liste des langages plus bas repère quelques spécifications marquantes. Elles ont fait date dans le monde XML. Les succès, ou les critiques, permettent aussi de montrer à quoi XML est bon, et là où il est parfois discuté.
Balisage de document
Le balisage de document est le métier initial d'XML. Les DTD SGML publiques comme TEI et Docbook l'ont adopté. XML aurait pu permettre l'apparition de nombreux autres schémas. On assiste plutôt à l'apparition de vocabulaires spécialisés, et combinables à l'exemple de la modularisation XHTML[6] :
- XHTML - eXtensible HyperText Markup Language, Langage de balisage hypertexte
- Docbook - documentation technique, 1991 à 1997 O'Reilly, 1998 à … OASIS, (Norman Walsh).
- TEI - Text Encoding Initiative, balisage de textes académiques, 1987, 1994, 1999, 2002, Text Encoding Initiative.
- EAD Encoded Archival Description, description archivistique, 1993, 2002, Bibliothèque du Congrès.
- NITF News Interchange Text Format, échange d'articles de presse, 2000, 2002, IPTC.
- NewsML News Markup Language, balisage de dépêche de presse, 2000, 2002, IPTC.
Format de données
XML s'est imposé comme format de référence pour l'échange de données, notamment de métadonnées. L'exemple d'un transfert d'informations entre base de données relationnelles permettra d'illustrer les avantages et limites de ce format pour cet usage.
L'exportation d'une table peut se faire en csv. Mais ce format comporte vite des limites à grande échelle (Internet). Il n'est pas auto-documenté (encodage du texte, séparateurs, ordre et nom des colonnes ?). Il demande une documentation externe rarement automatisée entre les partenaires. Que faire lorsque les tables source et destination n'ont pas des structures identiques ? Pour cette raison, on peut préférer des échanges en SQL (à la fois langage de définition de données et langage de manipulation de données). Cependant, malgré de nombreux efforts de normalisation, SQL comporte beaucoup de risques d'incompatibilité entre les implémentations [1]. XML est une solution plus robuste. On peut en constater l'efficacité sur Internet avec la syndication de contenu. Il n'y a pas d'exemple connu d'échange de métadonnées réparties sur autant de « clients » et de « serveurs ».
Verbosité ? - Comparé à l'export CSV d'une table, XML réplique le nom de la colonne pour chaque cellule (une fois pour un attribut, deux fois pour un élément). Le poids du fichier généré est supérieur à celui d'un fichier CSV. Dans des contextes où la bande passante est coûteuse (exemple : téléphonie mobile), cela n'a pas semblé poser de problème (WML), car ces répétitions se compressent très bien (zip).
Traitement lourd ? - Traiter du XML demande des bibliothèques dédiées (processeur XML). Cela n'ajoute pas vraiment du temps de développement supplémentaire, du moins pour des équipes formées. Pour des petites tâches, un parseur ligne à ligne est parfois plus simple. Mais si la donnée se destine à se complexifier, à s'échanger plus largement, il vaut mieux choisir XML dès le départ.
XML : données ou document ? - Cette section est l'occasion de marquer la distinction entre XML données et XML document. Il ne s'agit pas d'une différence dans la syntaxe, mais dans ses usages, ses outils et ses communautés d'utilisateurs. Par SGML, XML vient du document. On lui a reproché par exemple ne pas avoir (nativement) de typage fort. On rencontre un mouvement analogue mais contraire en SQL. C'est originalement un format de données, on lui demande de plus en plus de traiter du texte. (CMS LAMP). En ce qui concerne XML, cette opposition se traduit dans la direction des efforts de spécification (types de données XML Schema, XPath 2.0, XSLT 2.0) avec des réactions du monde documentaire (Relax NG).
- RDF - Resource Description Framework Réseaux de métadonnées, © 1997 à 2006 W3C.
- RSS Rich Site Summary, RDF Site Summary et Really Simple Syndication, 1999 à…, (principe plus que norme).
- Atom - syndication, 2003, IETF.
- OWL - Ontologies (W3C)
- GML - Données géographiques (Open Geospatial Consortium)
- Dublin Core - bibliographie (dublincore.org)
- MODS - bibliographie (Bibliothèque du Congrès, USA)
- METS - échange de collection de fichiers (Bibliothèque du Congrès, USA)
- BiblioML - bibliographie (Bibliothèque nationale de France)
- EbXML - commerce électronique (OASIS)
- XBRL - Données comptables
- XMI - XML Metadata Interchange
Langages de schéma
Un processus XML complet comporte une étape de validation des documents. C'est le rôle d'un schéma de définir ces règles de validité. Faut-il que ce schéma soit en XML ? La question ne se posait pas en SGML, qui connaissait surtout les DTDs, une syntaxe texte. Les limites rencontrées alors concernaient surtout la documentation des éléments et attributs déclarés(en). La documentation est très importante pour la réussite d'un standard XML. Celles de Docbook ou TEI constituent des livres complets, avec même des versions imprimées.
Ces communautés ont attendu avec impatience ce que donnerait XML Schema. Les nombreux outils de documentation automatiques qui sont apparus, avec un simple jeu d'XSLTs, prouvent l'intérêt d'XML comme langage de description de format de document. Cependant, pour des choses simples, XML Schema s'est avéré difficile. Est-ce l'effet de trop de concessions ? Toujours est-il que malgré le nombre d'éditeurs derrière le W3C, la communauté est très intéressée par Relax NG, de James Clark. Ce modèle accepte une syntaxe XML, et depuis 2003, propose aussi une forme compacte, textuelle, qui n'est pas XML.
Autrement dit, il n'y a plus de réponse unique. Un schéma XML peut se définir dans un vocabulaire XML, ou autrement. L'évolution actuelle est de pouvoir combiner plusieurs langages de schémas, notamment le typage fort d'XML Schema, avec des motifs XPath pour Schematron, dans du Relax NG[7].
- DTD Document Type Definition « définition de type de document », ISO.
- XML Schema langage de Schéma XML, W3C, 2001.
- Relax NG, DSDL acceptant une forme XML et une syntaxe compacte, ISO , 2001.
- Schematron, validation par motifs, ISO, 2001.
Langages de représentation
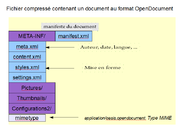 Organisation d'un document au format OpenDocument : content.xml (contenu), styles.xml (apparence), meta.xml (à propos du document)
Organisation d'un document au format OpenDocument : content.xml (contenu), styles.xml (apparence), meta.xml (à propos du document)
On vante souvent XML pour sa faculté de séparer contenu, présentation et traitement. Attention, XML rend cette séparation possible, mais il n'interdit pas de tout mélanger, comme dans certaines pages XHTML sur Internet. En tous cas, ce format extensible a prouvé qu'il pouvait conserver la présentation des documents pour les applications les plus exigeantes. La variété des applications l'utilisant en est la preuve.
- OpenDocument - tous les documents bureautiques, OpenOffice.org, 2001.
- Word - le format natif de Microsoft Word (traitement de texte) est en XML depuis sa version 2003.
- XSL-FO - eXtensible Stylesheet Language - Formatting Objects, langage extensible de stylage - formatage d'objets, W3C, 2001.
- SVG - Scalable Vector Graphics, graphiques vectoriels 2D, W3C, 2003.
- MathML - formules mathématiques, W3C, 1999, 2001, 2003.
- SMIL - Synchronized Multimedia Integration Language, Intégration multimédia, W3C, 1998, 2005.
- X3D - 3D multimédia, consortium Web3D.
Langages de programmation
Dans de nombreuses applications, il est parfois pratique de développer un langage spécialisé, à usage local. Avec un schéma, un dialecte XML dispose d'une grammaire (un peu comme BNF). En guise de compilateur, il suffit par exemple d'une transformation XSLT qui génère du code Java, comme pour une bibliothèque de balises (taglibs). Cet exemple montre comment la syntaxe XML permet de définir des langages de programmation.
En théorie, la structure en arbre d'XML permet de représenter la hiérarchie d'un programme objets, ou l'imbrication des instructions d'un langage impératif. En pratique, les boucles sont le cas limite à partir duquel XML devient trop verbeux. Par contre, cette écriture est remarquablement adaptée aux syntaxes déclaratives (configuration, définition d'interface), et même, popularise les algorithmes fonctionnels (XSLT, logique d'une application web).
Il en résulte que l'on trouve de plus en plus d'XML dans les logiciels. Dans certains frameworks de développement web, il est possible de monter une application complète et complexe, en n'éditant que du XML.
- XSLT - Extended Stylesheet Language Transformations, transformation de document XML, W3C, 1999.
- XML Query - requête et transformation XML, W3C, 2005.
- ANT - scripts de compilation, ASF.
- Servlet - serveur d'application Java, configuration et logique fonctionnelle, Sun Microsystems.
- Log4j - log for Java, configuration d'une bibliothèque d'historique, 1996, © 1999-2006, ASF.
- UIML - User Interface Markup Language, définition d'interface, OASIS, 1997.
- XUL - XML-based User interface Language, définition d'interface, Mozilla, 2000.
- XAML - définition d'interface, Windows Vista, 2006.
- MXML, Flex - définition d'interface, Macromedia.
Protocoles d'échanges
Un protocole spécifie l'échange de contenus et d'instructions, entre un client et un serveur. HTTP est un modèle de protocole (qui n'est pas XML mais textuel). XML permet de baliser des contenus et d'écrire des instructions de programmation. L'universalisation de la connexion HTTP comme des processeurs XML explique pourquoi XML devient une solution courante pour créer un nouveau protocole.
- XForms - formulaires web (W3C)
- OAI - Open Archive Initiative Protocole Archives ouvertes, 2000, 2002 (OAI)
- SOAP - RPC par HTTP (W3C)
- WSDL - Services web (W3C)
- WebDAV - Lecture/Écriture distante par HTTP (IETF)
- Jabber/XMPP - Messagerie instantanée et présence, multimédia (IETF)
Langages associés
Les langages associés à XML sont des syntaxes qui ne sont pas en XML mais très attachées à XML. CSS illustrera bien la notion. Il peut être contenu dans un attribut (@xhtml:style), dans un élément (<xhtml:style>), ou relié à un document XML par une instruction de traitement (<?xml-stylesheet href="common.css" type="text/css"?>). XPath fournit un autre exemple de spécification entièrement dédiée à XML, mais qui est justement sans éléments ou attributs, afin d'être associé à un langage XML (XSLT).
- CSS (Cascading Style Sheet)
- DTD (Document Type Definition)
- Espace de noms (Namespace)
- SGML
- XPath et XQuery, langages de requête. NB: XQuery possède aussi une syntaxe XML, XQueryX.
Conclusion, étape suivante ?
En 2001, on demandait à James Clark, un expert XML et SGML, What's the next step for XML? « Quelle est l'étape suivante pour XML » ? Il répondit d'abord que cela revenait à demander quelle est l'étape suivante pour le texte ASCII ou pour les fichiers à lignes délimitées. XML est en effet devenu un format aussi universel qu'Unicode pour structurer des contenus, comme un esperanto de l'informatique.
Qu'un arbre XML permette de représenter beaucoup de choses ne signifie pas que ce soit toujours la forme la plus adaptée, chaque utilisation a ses cas limites. Ainsi l'arbre bute sur un motif simple : l'intersection. Considérez ce texte tuilé : en gras et en italique. Le et appartient à deux zones, chose simulable mais pas native dans un arbre. On peut en faire une représentation XHTML comme ceci
<strong>en gras <em>et</em></strong> <em>en italique</em>, dont on voit d'ailleurs qu'elle n'est pas unique, car la notion d'intersection est perdue. Ce détail se démultiplie dans les applications WYSIWYG qui produisent du XML (traitement de texte, SVG), rendant la source générée de moins en moins lisible par un humain. Ce détail amènera peut-être un nouveau format.Selon James Clark en 2001, la nouveauté ne viendrait plus du format, mais de l'intégration applicative pour le traiter, c'est encore vrai en 2007.
Outils et processus XML
XML a désormais prouvé qu'il était une syntaxe très générique de balisage, propre à de nombreux usages. Cette réussite s'explique par des implémentations concurrentes de nombreuses interfaces de programmation (API) précisément spécifiées. Comment entre-t-il dans un processus applicatif ?
Pour détailler ces étapes, considérons le processus le plus simple, accessible depuis quelques années dans Internet Explorer ou Firefox. Ces navigateurs permettent de consulter des fichiers dans un XML sémantique (qui ne contient que des contenus, sans présentation), et de les voir comme des pages accompagnées de couleurs et de navigation. Ils sont transformés par le client, à l'aide d'une feuille XSLT. Prenons par exemple le site de Norman Walsh[note 5]. La source de la page servie ressemble à ceci :
<?xml version='1.0' encoding='utf-8'?> <?xml-stylesheet href="/style/browser.xsl" type="text/xsl"?> <essay xmlns="http://docbook.org/ns/docbook" xml:lang="en" version='5.0'> <info> <title>XProc: An XML Pipeline Language</title> <!-- ... --> </xml>
Ce n'est pas du XHTML (ou du HTML) mais du DocBook. Les navigateurs ne sont pas capables de lire cette grammaire pour lui donner de la présentation. La page apparente est le résultat d'une transformation, signalée au navigateur par l'écriture <?xml-stylesheet href="/style/browser.xsl" type="text/xsl"?>. Le fichier browser.xsl explique comment transformer du DocBook en HTML. Le processus est immédiat, il est intéressant de le détailler, car on le retrouve dans des applications XML plus complexes.
- produire : le document DocBook doit avoir été produit ou résulter d'un import ;
- entrée : dans le navigateur, un parser lit le fichier XML pour construire un objet informatique, et vérifie que le document est bien formé ;
- transformation : le document DocBook est transformé en XHTML ;
- inclusions : dans certains contextes, il est possible d'inclure des fichiers qui deviendront des nœuds ;
- validation : le document peut être validé, pour vérifier que sa structure est conforme au schéma docbook ;
- sortie : le navigateur s'occupe de rendre le résultat de la transformation en une page pour un utilisateur.
Cette succession canonique d'étapes illustre ce que peut être le tuyau d'un processus XML complet. Elles vont maintenant être expliquées pour montrer comment elles peuvent apparaître dans d'autres contextes applicatifs plus complexes.
Exporter et Produire
Une organisation qui a déjà son système d'informations qui n'est pas basée sur XML peut se demander comment produire du XML. Il existe de nombreuses manières d'exporter et de produire du XML, afin de rentrer dans une chaîne de processus XML.
- Traitement de texte, la plupart des logiciels bureautiques proposent un export XML, quand ils ne sont pas nativement XML (OpenOffice.org, Microsoft Word). Le plus simple est parfois d'enregistrer en HTML, récupérable moyennant un petit traitement. Il suffit de regarder les formats disponibles avec la fonctionnalité Enregistrer sous de son logiciel habituel.
- SQL, la plupart des SGBD proposent un export XML.
- Un éditeur XML est le meilleur moyen de faire produire par un humain un document correspondant exactement au schéma attendu.
Dans le cas en introduction, Norman Walsh utilise un simple éditeur de texte, emacs.
Parseurs et interfaces de programmation (API)
Avant d'entrer dans un processus XML, un contenu doit être « xmlisé ». Cette opération est effectuée par un processeur XML. Les parseurs les plus répandus sont :
- MSXML - Microsoft Core XML Services, le parseur XML Microsoft, 2000-2006, intégré au système d'exploitation Windows, accessible aux langages Microsoft, notamment en JavaScript sur le navigateur Internet Explorer.
- libxml2 - Le processeur XML libre du système d'exploitation linux, accessible en C , Python [2], PHP [3], et en Ruby [4]
- Xerces - XML Java Parser, le parseur XML par défaut d'une machine virtuelle Java, accessible en Java
- Expat - Le parseur XML de James Clark, notamment embarqué par les navigateurs mozilla (firefox).
- VTD-XML
Il en existe beaucoup d'autres, en particulier en Java, adaptés à différents cas particuliers : ouvrir une API plus simple, accepter des documents mal formés comme HTML, traitements plus simples (notamment pour les documents longs).
Une fois « xmlisé », un document est accessible à différents langages, selon des interfaces de programmation standardisées. On distingue généralement l'approche DOM, modèle objet en mémoire, et l'approche SAX, génération d'événements.
- DOM, Document Object Model, constitue un objet en mémoire de la totalité d'un document XML. Cette API permet l'accès direct à tous les nœuds de l'arbre (éléments, texte, attributs), pour les lire, ou les modifier. Il est par exemple très utilisé sur les navigateur web avec JavaScript. Cette norme est écrite par le W3C.
- SAX, Simple API for XML, est une alternative intéressante à DOM pour le traitement de documents longs. Quand un document entre dans un processeur XML, du code SAX peut capturer des événements, comme l'ouverture et la fermeture d'une balise, afin par exemple, d'écrire dans une base de données. À l'inverse, il est possible de générer des événements SAX, par exemple à partir de la lecture d'une base de données, afin de produire un document consommé par une autre étape d'un processus XML.
- VTD-XML
D'autres API existent, comme JDOM, dom4J (Java), ou StAX. Il n'est toutefois pas nécessaire de « programmer » pour traiter du XML, notamment avec des langages de transformation comme XSLT. Dans le cas en introduction, votre navigateur charge automatiquement le document docbook, et passe le contenu à une transformation xslt.
Transformation
Article détaillé : Langage de transformation XML.La transformation est l'étape d'un processus XML qui prend un document dans un certain schéma pour le transposer dans un autre espace de noms. L'exemple en introduction permet de bien comprendre l'opération. Soit un document textuel qui ne comporte que du contenu. Il sera nécessaire de lui ajouter au moins de la navigation avant de le diffuser sur Internet ; on en voudra aussi une version imprimée (pdf). La facilité de transformer un document XML, notamment avec XSLT, est une raison importante pour choisir ce format.
Inclusions
Un document XML peut être constitué de plusieurs fichiers. Il y a deux normes actuellement concurrentes.
- les entités externes[XML 9], issues de SGML, résolues a priori par un parseur validant, avant tout traitement du document.
xinclude[8], un élément XML dédié, pouvant être traité comme une étape séparée.
Les spécifications et les implémentations privilégient maintenant xinclude, bien que son adoption ait pu être discutée[9].
Considérons l'exemple d'un catalogue de produits pour voir les effets de l'un et de l'autre. On aura chaque produit sous la forme d'un document XML, et un document maître qui assemble toutes les références. En entités, cela s'explique ainsi.
<!DOCTYPE catalogue [ <!ENTITY article001 SYSTEM "articles/article001.xml"> <!ENTITY article002 SYSTEM "articles/article002.xml"> ]> <!-- Un exemple d'inclusion par résolution d'entité externe --> <catalogue xmlns="http://exemple.net/ns"> <titre>catalogue</titre> &article001; &article002; </catalogue>
On remarquera que les entités sont déclarées en entête de document, puis appelées par une écriture du type &entité;. Cette syntaxe est initialement prévue pour des raccourcis, afin de factoriser l'écriture de variables comme un nom de produit ou une société. Ce mécanisme a été étendu pour résoudre les problèmes d'encodage en ASCII avant l'Unicode. Ce sont les entités caractère comme é=&#E9;=é. Pour le cas d'une inclusion d'un fichier, cela demande deux déclarations, celle du lien, celle de son appel. Ce moyen reste massivement employé par les sociétés qui ont connu SGML, d'autant que son support est beaucoup plus généralisé que celui d'xinclude.
La résolution a priori des inclusions peut avoir des inconvénients, en particulier pour des documents maître très lourds que l'on peut vouloir travailler sans leur dépendances. Xinclude permet cela, ainsi que de générer ces relations automatiquement (XSLT).
<!-- Un exemple d'inclusion par xinclude --> <catalogue xmlns="http://exemple.net/ns" xmlns:xi="http://www.w3.org/2001/XInclude"> <titre>catalogue</titre> <xi:include href="articles/article001.xml"/> </catalogue>
On retrouve cette évolution vers la modularisation d'XML où l'inclusion devient une étape optionnelle d'un processus.
Validation
La validation est l'opération automatique qui vérifie la conformité d'un document XML à son schéma. Elle a pour but de délivrer des messages comme il n'y a pas de titre au chapitre 5, ou bien, la date de fabrication est dans le futur. La précision et la convivialité de cette vérification dépendent de la syntaxe utilisée.
En SGML, la validation s'effectuait toujours avant l'entrée d'un document XML dans un processus. On parlait de parser validant. Il n'y avait alors qu'un seul langage de validation (les DTDs) déclarés d'une seule manière à l'intérieur du document XML (la déclaration DOCTYPE, Type de document). La pratique a montré que la validation n'est pas toujours nécessaire, et même, contre performante. Dans d'autres cas, plusieurs étapes de validation peuvent être utiles, par exemple, une pour vérifier la structure de l'arbre XML, une autre pour vérifier les liens. L'évolution va vers une étape de validation distincte, déclarée à l'extérieur du document, et gérée selon les besoins du logiciel.
Les parseurs XML gardent l'ancien usage de conserver les bibliothèques logicielles de validation. Cependant la fonctionnalité peut être débranchée, ou appelée séparément. Il existe aussi des bibliothèques uniquement dédiées à la validation. Le déploiement actuel rend la validation XML nativement accessible à la plupart des systèmes, et dans la plupart des langages de programmation.
- MSXML - Microsoft Core XML Services, validation DTD et XML Schema.
- libxml2 - Validation DTD et Relax NG (le support XML Schema est partiel, surtout pour le typage de données au sein de Relax NG).
- Xerces - XML Java Parser, validation DTD et XML Schema.
- Jing - a Relax NG validator in Java, un validateur qui n'est pas un parseur pour Relax NG et Schematron.
- XSLT - Une transformation XSLT permet une validation très précise sur un type de document, c'est couramment utilisé dans une application web pour rendre à l'utilisateur des messages plus conviviaux, cet outil suffit aussi pour utiliser une implémentation Schematron.
Sorties
Dans le cas en introduction, le navigateur est le consommateur final de XML, sous la forme de xhtml. Chaque langage XML de représentation (XSL-FO, SVG…) peut être consommé par une application utile à l'utilisateur. Certains formats peuvent être traités par plusieurs bibliothèques logicielles.
- (en) Apache Batik, API Java traitant des documents SVG (exemple : export JPG, PNG).
- (en) FOP, le sérialiseur XSL-FO d'Apache
- (en) XEP, processeur XSL-FO et SVG commercial, RenderX.
« Tuyaux » (XML Pipeline)
Les étapes décrites plus haut sont en cours de normalisation par le W3C (XML Processing Model Working Group). La terminologie est officialisée. Ces idées ont déjà des implémentations concurrentes dans plusieurs frameworks (Apache Cocoon, Orbeon Presentation Server…). L'idée de tuyaux XML existe avant d'avoir été spécifiée.
Un tuyau est une entrée (Input Document), une sortie (Output Document), et une chaîne d'étapes (Step). Ces étapes traitent un flux XML (XML Information Set, Infoset [5]). La notion de flux d'information n'est pas spécifique à XML, on la retrouve à grande échelle dans l'informatique réseau, ou très simplement en ligne de commande Unix, avec la barre verticale, pipe en anglais). L'originalité réside dans la structuration propre à XML. Les octets traités par ces tuyaux sont des documents structurés. Les étapes sont standardisées et combinables. Elles sont définies par des composants (components) paramétrables (parameter), le tout en XML.
Conclusion
Les principes de la syntaxe XML s'acquièrent en quelques heures, avec un simple éditeur de texte. Tout utilisateur de traitement de texte gagne à y être sensibilisé, afin de comprendre les principes de la rédaction structurée. Connaître ce formalisme peut motiver à utiliser les styles (exemple : les titres hiérarchiques), afin de produire des documents récupérables, par exemple pour HTML et Internet. Un développeur web ne peut plus ignorer XML. Il en manipule pour rendre son HTML dynamique, sous la forme d'un DOM. Avec le web 2.0 et AJAX, ces standards pénètrent sa pratique quotidienne. Le développement serveur est lui aussi confronté de plus en plus souvent à des composants configurables en XML, particulièrement en Java. Enfin, ce formalisme s'accompagne de pratiques, de motifs de conception (design patterns), complètement adaptés aux architectures MVC (Modèle Vue Contrôleur). XML et les standards attachés pénètrent tous les secteurs de l'informatique. Il y a quelques années, on pouvait se demander, pourquoi XML ? Maintenant, la charge de la preuve est de l'autre côté, il faut de sérieux arguments pour y échapper.
Notes et références
Notes :
- ↑ Ce nom est une idée de James Clark, elle est très bien expliquée par Tim Bray dans sa spécification annotée. Comme en anglais la lettre X se prononce « eks », elle peut être utilisée dans les sigles pour abréger un ou plusieurs mots commençant par ce même son comme eXtensible ou eXperience (XP). Un bon nombre de langages ont également affiché leur parenté avec XML en s'adjoignant un X, comme XHTML.
- ↑ a et b À la différence des balises statiques du html où par exemple
<p>balise un paragraphe et<li>un item d'une liste. - ↑ Par exemple le contenu d'un ensemble de pages de Wikipédia s'exporte en un fichier XML utilisant les définitions des balises
page,title,contributor,revision,text... de ce schéma XML disponible sur mediawiki.org/xml/export. Autre exemple, les données de l'INSEE sont signifiantes en utilisant les définitions disponibles sur xml.insee.fr - ↑ Le groupe de travail a été à l'origine appelé le «Editorial Review Board." Les membres à la première édition sont énumérés à la fin de la première recommandation XML, W3C 1998.
- ↑ Ou celui de Jeni Tennison et de plusieurs autres.
Références :
- (en) Extensible Markup Language (XML) 1.0, W3C Recommendation 16 August 2006 :
- (mul) Autres :
- ↑ (fr)XML expliqué aux débutants, Emmanuel Lazinier, 1999
- ↑ (en)Rapports du W3C SGML ERB pour le SGML WG Et du W3C XML au XML ERB SIG, rapport compilé par C. M. Sperberg-McQueen, 4 décembre 1997
- ↑ (fr)interview, journal du net, septembre 2004
- ↑ (en)W3C Working Draft 14-Nov-96
- ↑ (en) « Its goal is to enable generic SGML to be served, received, and processed on the web in the way that is now possible with HTML. »(en)
- ↑ (en) XHTML Modularization 1.1, W3C Working Draft 5 July 2006
- ↑ (en)Eric van der Vlist, RELAX NG, « W3C XML Schema Type Library », O'Reilly & Associates, 2003 (ISBN 0596004214) [lire en ligne]
- ↑ (en)xinclude
- ↑ (en)Norman Walsh, XInclude, xml:base, and validation.
Voir aussi
Articles connexes
Autres technologies et théories intéressant XML :
Liens externes
Références
- W3C Recommendation: Extensible Markup Language (XML) 1.0 (Fifth Edition) (en)
- W3C Recommendation: Namespaces in XML 1.0 (Second Edition) (en)
- W3C Recommendation: xml:id Version 1.0 (en)
- W3C Recommendation: Extensible Markup Language (XML) 1.1 (Second Edition) (en)
Divers
 Portail de l’informatique
Portail de l’informatique Portail de l’écriture
Portail de l’écriture
Catégories : Format ouvert | XML | Normes et standards informatiques | Standard du web | Codage des données | Format de sérialisation de données
Wikimedia Foundation. 2010.