- Connaissances A Priori
-
Connaissances a priori
Voir a priori pour le concept philosophique.
La reconnaissance de formes est un domaine de recherche très actif et intimement lié à l'apprentissage machine. Aussi connue sous le nom de classification, son but est de construire un classifieur qui peut déterminer la classe (sortie du classifieur) d'une forme (entrée du classifieur). Cette procédure, aussi appelée entraînement ("training"), correspond à apprendre une fonction de décision inconnue à partir de données d'apprentissage sous la forme de couples entrée-sortie
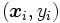 appelés exemples. Néanmoins, dans les applications réelles, comme la reconnaissance des caractères, une certaine quantité d'information sur le problème est souvent connue a priori (ou à priori). L'incorporation de cette connaissance a priori dans l'apprentissage est la clé qui permettra une augmentation des performances du classifieur dans beaucoup d'applications.
appelés exemples. Néanmoins, dans les applications réelles, comme la reconnaissance des caractères, une certaine quantité d'information sur le problème est souvent connue a priori (ou à priori). L'incorporation de cette connaissance a priori dans l'apprentissage est la clé qui permettra une augmentation des performances du classifieur dans beaucoup d'applications.Sommaire
Définition
La connaissance a priori, comme définie par [Scholkopf02], fait référence à toute l'information disponible sur le problème en plus des données d'apprentissage. Cependant, sous cette forme la plus générale, déterminer un modèle à partir d'un jeu fini d'exemples sans connaissance a priori est un problème mal posé, dans le sens où un modèle unique ne peut exister. Beaucoup de classifieurs incorporent l'a priori de douceur de la fonction ("smoothness") qui implique qu'une forme similaire à une forme de la base d'apprentissage tend à être assignée à la même classe.
En apprentissage machine, l'importance des connaissances a priori peut se voir par le théorème du No Free Lunch qui établi que tous les algorithmes ont les mêmes performances en moyenne sur tous les problèmes et qui implique donc qu'un gain de performance ne peut s'obtenir qu'en développant un algorithme spécialisé et donc en utilisant des connaissances a priori.
Les différent types de connaissances a priori rencontrés en reconnaissance des formes sont regroupés dans deux catégories principales : invariance de classe et connaissances sur les données.
Invariance de classe
Un type de connaissances a priori très commun en reconnaissance des formes est l'invariance de la classe (ou de la sortie de classifieur) par rapport à une transformation de la forme d'entrée. Ce type de connaissance est connue sous le nom de invariance par transformation (ou "transformation-invariance"). Les transformations les plus utilisées sont :
- translation;
- rotation;
- redressement ("skewing");
- changement d'échelle.
L'incorporation d'une invariance à une transformation
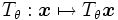 paramètrée par θ dans un classifieur de sortie
paramètrée par θ dans un classifieur de sortie 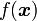 pour une forme d'entrée
pour une forme d'entrée 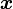 correspond à imposer l'égalité
correspond à imposer l'égalité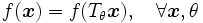
L'invariance locale peut aussi être considérée pour une transformation centrée en θ = 0, qui donne
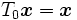 , par la contrainte
, par la contrainte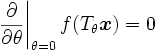
Dans ces équations, f peut aussi bien être la fonction de décision ou la sortie à valeur réelle du classifieur.
Une autre approche consiste à considérer l'invariance de classe par rapport à un "domaine de l'espace d'entrée" au lieu d'une transformation. Dans ce cas, le problème devient: trouver f qui permet d'avoir
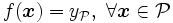
où
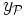 est la classe d'appartenance de la région
est la classe d'appartenance de la région 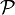 de l'espace d'entrée.
de l'espace d'entrée.Un type différent d'invariance de classe est l' invariance aux permutations, i.e. l'invariance de la classe aux permutations des éléments dans une entrée structurée. Une application typique de ce type de connaissance a priori est un classifieur invariant aux permutations de lignes dans des entrées matricielles.
Connaissances sur les données
D'autres formes de connaissance a priori que l'invariance de classe sont concernées par les données plus spécifiquement et sont ainsi d'un intérêt particulier pour les applications réelles. Les trois cas particuliers qui se produisent le plus souvent quand on rassemble des données d'observation sont :
- Des exemples non-labélisés sont disponibles avec des classes d'appartenance supposées ;
- Un déséquilibre de la base d'apprentissage due à une forte proportion d'exemples d'une même classe;
- La qualité des données peut varier d'un exemple à l'autre.
Si elle est incluse dans l'apprentissage, une connaissance a priori sur ces derniers peut améliorier la qualité de la reconnaissance. De plus, ne pas prendre en compte la mauvaise qualité des données ou un grand déséquilibre entre les classes peut induire un classifieur en erreur.
Références
- [Scholkopf02], B. Scholkopf et A. Smola, "Learning with Kernels", MIT Press 2002.
Catégorie : Automatisme
Wikimedia Foundation. 2010.