- Case Based Reasoning
-
Raisonnement par cas
 Pour les articles homonymes, voir CBR.
Pour les articles homonymes, voir CBR.Pour résoudre les problèmes de la vie quotidienne, nous faisons naturellement appel à notre expérience. Nous nous remémorons les situations semblables déjà rencontrées. Puis nous les comparons à la situation actuelle pour construire une nouvelle solution qui, à son tour, s’ajoutera à notre expérience.
Le raisonnement par cas ou Case Based Reasoning (CBR), copie ce comportement humain. Il résout les problèmes en retrouvant des cas analogues dans sa base de connaissances et en les adaptant au cas considéré. Cette technologie est apparue il y a une quinzaine d’années mais les travaux initiaux sur le sujet remontent cependant aux expériences de Schank et Abelson en 1977 à l’Université Yale. Elle reste pourtant encore assez méconnue par rapport à d’autres technologies appartenant au domaine des sciences cognitives comme le data mining. Elle diffère de cette dernière par son approche. En effet, ici, on n’utilise qu’indirectement les données pour retrouver les cas proches, à partir desquels on va générer une solution.
Sommaire
Etapes du processus
Un système CBR dispose d’une base de cas. Chaque cas possède une description et une solution. Pour utiliser ces informations, un moteur est aussi présent. Celui-ci va retrouver les cas similaires au problème posé. Après analyse, le moteur fournit une solution adaptée qui doit être validée. Enfin le moteur ajoute le problème et sa solution dans la base de cas.
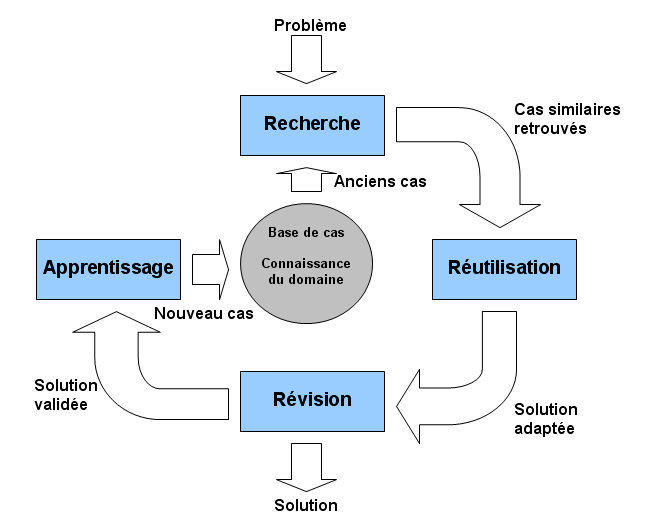
Ce schéma présente bien les principales étapes dans le processus d’un système de raisonnement par cas. De ces étapes se dégagent trois problèmes majeurs :
- La représentation des cas
- La recherche des cas
- La création de la fonction d’adaptation
Pour développer un système de raisonnement par cas digne de ce nom, il est donc nécessaire de trouver une solution efficace à chacun de ces problèmes. La révision et l’apprentissage sont deux autres problèmes qui découlent des trois premiers.
Représentation des cas
La représentation des cas prend une place importante dans la réalisation d’un système CBR. En effet cette représentation va déterminer l’efficacité et la rapidité de la recherche des cas dans la base. Il est donc nécessaire de choisir les informations à stocker dans chaque cas et de trouver sous quelle forme.
Structure d'un cas
Un cas est décrit par de nombreuses caractéristiques représentant différents types d’informations :
- La description du problème
- La solution et les étapes qui y ont mené
- Le résultat de l’évaluation
- L’explication des échecs
Tous les CBR n’utilisent pas forcément chacun des types d’informations. La description du problème et la solution apportée sont des éléments indispensables. Certaines caractéristiques (les plus discriminantes) seront utilisées en tant qu’index lors de la recherche et l’ajout de cas. Les index doivent être suffisamment concret et abstrait à la fois pour qu’ils concernent un maximum de cas et qu’ils soient réutilisables dans les raisonnements futurs. Ils doivent aussi permettre de déduire rapidement les cas.
Généralement on considère les cas comme une liste de couples attribut-valeur. Chaque couple correspondant à une caractéristique. Les attributs sont typés, voici par exemple les types utilisés dans ReMind :
- Types classiques : texte, entier, réel, booléen, date.
- Type symbole : il permet d’énumérer une liste de symboles qui seront stockés dans un arbre. La racine de l’arbre contiendra le symbole le plus général et les feuilles les symboles les plus spécifiques.
- Type cas : il permet de référencer des cas qui sont des sous parties du cas considéré.
- Type formule : la valeur de cet attribut est le résultat du calcul d’une formule.
- Type liste : ce type est une liste d’objets utilisant les types précédents.
Organisation de la mémoire
Ensuite il faut construire un modèle d’organisation et d’indexation pour relier les cas entre eux. Ce modèle doit posséder certaines qualités. Tout d’abord il est nécessaire que l’ajout assure l’accessibilité aux anciens cas. La recherche de cas similaires doit conserver une complexité constante au fur et à mesure que la base de cas se remplit. Un système de CBR n’étant intéressant qu’avec une base importante de cas, il faut évidemment envisager une solution permettant de retrouver rapidement les cas similaires. Généralement on utilise l’indexation pour cette raison.
Il existe de nombreuses façons d’ordonner les cas, nous allons étudier rapidement l’ensemble des modèles existants. Nous nous attarderons sur deux modèles en particulier :
- Le modèle à mémoire dynamique
- Le modèle à base de catégories
Modèle simple
Commençons tout d’abord par le modèle le plus simpliste : l’organisation linéaire. Cette organisation n’est pas utilisée pour gérer l’ensemble de la mémoire des cas. Cependant elle peut être implicitement combinée à d’autres modèles plus complexes au niveau de petits sous ensembles de cas.
Il est possible d’organiser la mémoire sous la forme d’un arbre de décision : chaque nœud correspond à une question sur l’un des index et les fils correspondent aux différentes réponses. Pour être le plus efficace possible l’arbre doit poser les questions dans le bon ordre et être le moins profond possible. Cet arbre doit être construit dynamiquement. La meilleure méthode pour le construire est d’utiliser le data mining.
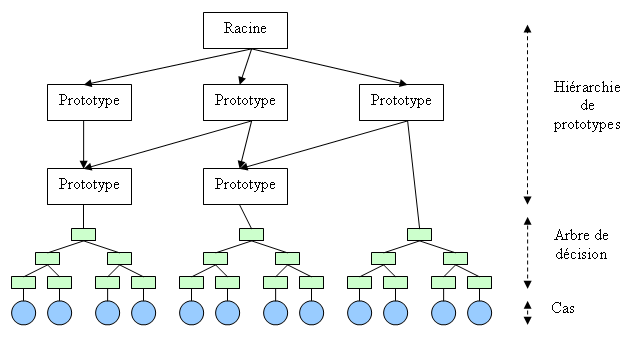
Un autre modèle consiste à construire la mémoire sous la forme d’une hiérarchie de prototypes. Un prototype permet de décrire des conditions sur des caractéristiques des cas. Tous les cas vérifiant ces conditions sont associés à ce prototype. Les prototypes sont organisés dans une hiérarchie d’héritage. On peut ainsi spécifier des prototypes généraux desquels héritent des prototypes plus spécifiques. En combinant les arbres de décision à cette hiérarchie de prototypes, on obtient une structure intéressante. Les prototypes « terminaux » ne stockent alors plus leurs cas dans une liste mais dans un arbre de décision. La hiérarchie de prototype représente la connaissance a priori du système et les arbres de décision générés dynamiquement permettent une structure assez flexible.
Modèle à mémoire dynamique
Le modèle à mémoire dynamique a été introduit par Roger Schank et Janet Kolodner. Dans ce modèle, les cas sont stockés dans une structure hiérarchique appelée épisode généralisé. On parle aussi de MOP pour Memory Organisation Packets. Les différents cas ayant des propriétés similaires sont regroupés dans une structure plus générale, un épisode généralisé. Ils contiennent trois types objets :
- Les normes : Les caractéristiques communes à chacun des cas indexés sous l’épisode généralisé.
- Les index : Les éléments discriminant les cas contenus dans l’épisode généralisé. Un index possède deux champs : son nom et sa valeur. Il peut pointer vers un autre épisode ou simplement vers un cas.
- Les cas : La connaissance du système. On y accède donc par l’intermédiaire d’index.
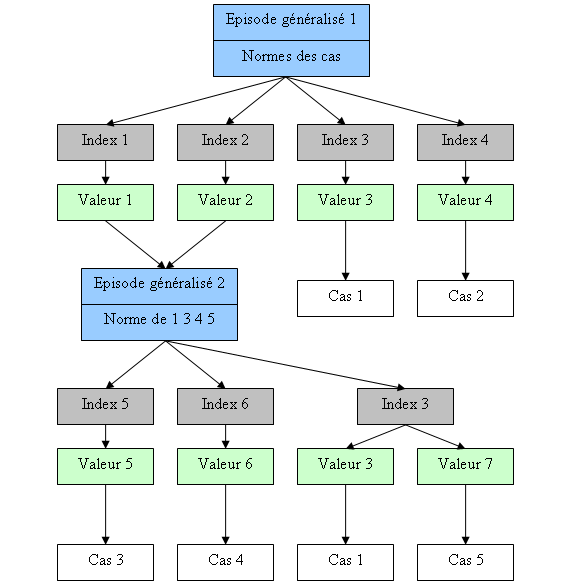
Le schéma donne une idée du modèle à mémoire dynamique. Il possède une structure proche d’un arbre. On retrouve bien les trois types d’objets énoncés, à la différence près qu’une distinction est faite entre les index et les valeurs. On peut remarquer aussi qu’il est possible d’atteindre certains cas de différentes manières. Ce modèle est donc redondant.
La recherche des cas similaires s’effectue à partir du nœud racine. On va chercher l’épisode généralisé possédant le plus de caractéristiques en commun avec le problème courant. Ensuite on parcoure les index, qui représentent les caractéristiques absentes de la norme de l’épisode généralisé sur lequel on travaille. Le couple index-valeur sélectionné est celui qui est le plus similaire avec le problème. À partir de celui-ci, soit on arrive à un autre épisode généralisé, dans ce cas, on recommence le processus, soit on obtient un cas similaire au problème posé.
La procédure d’ajout de nouveaux cas fonctionne d’une manière proche à la recherche de cas similaires. En effet le parcourt du graphe est identique. Lorsque l’on a trouvé l’épisode généralisé ayant le plus de normes en commun avec le cas courant, on effectue l’ajout. Pour cela, il faut générer un couple index-valeur distinguant le nouveau cas aux autres fils de l’épisode généralisé. S’il existe déjà un cas possédant le même couple, on crée un nouvel épisode généralisé contenant ces deux cas.
On obtient donc un réseau discriminant à l’aide des index qui permettent de retrouver les cas. Les épisodes généralisés sont principalement des structures d’indexation. Les normes permettent de représenter une connaissance générale des cas sous-jacents alors que les couples index-valeur définissent les spécificités.
Cependant, ce processus d’indexation peut mener à une croissance exponentielle du nombre d’index par rapport au nombre de cas. On adjoint donc généralement certaines limites dans le choix des index même si cela entraîne une baisse de performances.
Modèle à base de catégories
Ce modèle est une alternative au modèle précédent. Ici, un cas est aussi appelé exemple. L’idée directrice est que la réalité devrait être définie de manière extensive par des cas. Les caractéristiques décrites généralement par un nom et une valeur, possèdent un niveau d’importance fonction de l’adhésion d’un cas à une catégorie.
Dans ce modèle, la base de cas est un réseau de catégories et de cas. Les index sont des liens qui peuvent être de trois sortes :
- De rappel : reliant une caractéristique à une catégorie ou un cas.
- D’exemple : reliant une catégorie aux cas auxquels elle est associée.
- De différence : reliant deux cas ne différant que d’un nombre restreint de caractéristiques.
Le schéma ci-dessous illustre les différents types de liens disponibles. Cependant il ne représente qu’une seule catégorie. Il faut donc ajouter que les exemples peuvent appartenir à plusieurs catégories.
La recherche des cas similaires consiste à retrouver la catégorie qui possède les caractéristiques les plus proches du nouveau problème. Lorsqu’elle est trouvée, on retourne les cas les plus prototypiques.
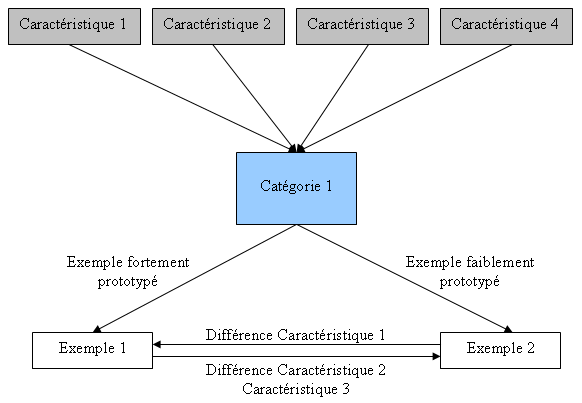
Recherche de cas similaire
Avant la recherche des cas similaires, il est nécessaire d’étudier le problème posé. Il faut identifier ses caractéristiques mais aussi son contexte si cela est possible. Si certaines informations sont manquantes, il est possible de négliger certaines caractéristiques ou d’interroger l’utilisateur. C’est au cours de cette étape, préambule à la recherche à proprement parler, que le système CBR doit essayer de déterminer et corriger les données bruitées ou incohérentes. Pour cela, on peut faire appel à des outils de datacleaning. Il est aussi possible d’essayer de déduire des caractéristiques à partir d’autres à l’aide d’un modèle de connaissance. Toutes ces opérations requièrent généralement l’approbation de l’utilisateur avant de passer à l’étape suivante.
La recherche se décompose en deux phases : le filtrage et la sélection. Au cours de ces deux étapes, on fait appel à des index statiques et dynamiques. Il existe différentes façons de déterminer quelles caractéristiques seront choisies en tant qu’index. On peut utiliser :
- Toutes les caractéristiques
- Certaines caractéristiques
- Les caractéristiques déterminantes dans le passé
- Les caractéristiques les plus discriminantes
Il est possible de choisir les index lors de la réalisation du système CBR, on parle alors d’index statiques. Lorsqu’ils sont sélectionnés automatiquement ou par l’intermédiaires d’une interface homme-machine, ils sont qualifiés de dynamiques. Enfin certains CBR donnent une importance aux différents index.
Filtrage
L’étape de filtrage consiste à réduire au préalable le nombre de cas utilisés dans la recherche. Cette étape peut être sautée pour passer directement à la sélection. Il existe différents algorithmes mais ceux-ci sont souvent liés à un type de représentation des cas. Par exemple pour la représentation en MOP, c'est-à-dire la représentation à mémoire dynamique, le filtrage va consister à réduire l’ensemble de cas à un MOP proche du problème. On va l’atteindre en descendant successivement les index.
Sélection
A partir de l’ensemble de cas obtenus lors de l’étape de filtrage, on va construire un nouvel ensemble de cas similaires. Pour cela, on peut utiliser l’algorithme des plus proches voisins (Nearest Neighbour) ou d’autres heuristiques qui vont nous permettre de mesurer la similarité entre le problème posé et les cas candidats. En fait, on ne va comparer le nouveau cas aux autres que par l’intermédiaire des index. À partir de la similarité sur chaque index, on obtiendra la similarité globale.
Il faut donc que chaque index dispose d’une fonction mesurant la similarité entre deux valeurs de son ensemble de recherche. Ceci peut poser problème si les cas sont constitués de types complexes symboliques. Mais ce problème n’est pas spécifique au CBR, il est caractéristique des recherches en analogie. Il existe donc souvent déjà une méthode pour calculer la similarité pour chaque type de données. Généralement la fonction de calcul retourne une valeur appartenant à un intervalle.
Il est possible d’enrichir cette méthode des plus proches voisins par l’utilisation d’heuristiques de sélection. Pour que la sélection soit la plus optimale, il n’est pas nécessaire de découvrir les cas les plus similaires au problème mais plutôt ceux qui sont le plus utiles à sa résolution. Les heuristiques doivent sélectionner :
- Les cas qui résolvent une partie des buts du problème
- Les cas qui partagent le plus de caractéristiques importantes
- Les cas les plus spécifiques
- Les cas les plus utilisés
- Les cas les plus récents
- Les cas les plus faciles à adapter
Réutilisation de cas et adaptation
Dans les systèmes CBR simples, lorsque l’on a retrouvé un cas similaire, on réutilise directement la solution qu’il propose pour le problème courant. Dans ce type de systèmes, on considère que les similarités sont suffisantes et que l’on peut négliger les différences entre le cas trouvé et le problème.
Cette façon de procéder est quand même peu satisfaisante. Il est rare que l’on trouve un cas identique au problème, il est alors souvent nécessaire d’adapter les solutions préexistantes. L’adaptation consiste donc à construire une nouvelle solution à partir du problème courant et des cas similaires trouvés. Cette phase met l’accent sur les différences entre les cas trouvés et le problème et sur l’information utile à transférer à la nouvelle solution.
Il existe deux types d’adaptation :
- L’adaptation transformationnelle
- L’adaptation dérivative
Adaptation transformationnelle
L’adaptation transformationnelle consiste à réutiliser directement les solutions des cas passés. Ce type d’adaptation ne prend pas en compte la manière dont les solutions des cas similaires ont été générées. On utilise des lois d’adaptation pour transformer les anciennes solutions. Ces lois sont dépendantes du domaine d’application du système CBR.
Adaptation dérivative
On peut utiliser ce type d’adaptation lorsque l’on dispose pour chaque cas stocké dans la base des étapes du raisonnement menant aux solutions. L’adaptation dérivative consiste à appliquer le même raisonnement au nouveau problème. Lors de la construction de la nouvelle solution, on va privilégier les chemins pris par les anciennes solutions sélectionnés et éviter les chemins infructueux. Cependant le nouveau cas est différent, de nouveaux sous-objectifs seront poursuivis.
Autres adaptations possibles
Il existe d’autres types d’adaptations possibles. On peut par exemple faire appel à des cas d’adaptation. Cela revient à considérer un système CBR dédié à l’adaptation en général. Il ne serait spécialisé vers aucun domaine en particulier et contiendrait des cas assez abstraits d’adaptation.
Une autre approche est de classifier les cas dans une hiérarchie. Cette approche permet à des cas d’être réutilisés avec un niveau d’abstraction le plus élevé possible, ce qui les rend facilement applicable à une nouvelle situation. Pour adapter les sous parties d’une solution, le système se référera au contexte de la solution générale.
Révision
Après sa génération par le système, la solution du problème est testée. Cette étape est généralement externe au CBR. Suivant le domaine, on peut faire appel à un logiciel de simulation ou à un expert. N’oublions pas que la durée d’une évaluation peut être très longue, notamment dans le domaine médical pour le test de traitements. Si cette évaluation est concluante, on va retenir cette nouvelle expérience. C’est la phase d’apprentissage que nous étudierons par la suite. Cependant si la solution n’est pas satisfaisante, il faut la réparer ou tout au moins expliquer les raisons de l’échec. C’est la phase de révision.
La phase de révision va donc en premier lieu essayer de déterminer les raisons de l’échec. Pour cela, on peut essayer d’expliquer pourquoi certains buts n’ont pas été atteints. Les informations collectées vont enrichir une mémoire d’échec utilisée lors de la phase d’adaptation. Ainsi lors des prochaines générations de solutions, le système ne répétera pas ses erreurs.
Lorsque le système a déterminé les raisons de l’échec de la solution, il est possible d’essayer de la réparer. Cette étape de réparation peut être vue comme une autre fonction d’adaptation. La seule différence est que dans la réparation, on travaille à partir d’une solution incorrecte mais adaptée au problème au lieu de solutions correctes inadaptées. On va s’appuyer sur les explications de l’échec pour réaliser les modifications.
Apprentissage
C’est la dernière étape du cycle du CBR. Au cours de cette phase, le nouveau cas et sa solution validée vont être ajoutés à la base de cas. Il faut donc déterminer quelles informations doivent être sauvegardées et sous quelle forme, et comment indexer ce nouveau cas dans la base.
Si le cas a été résolu sans l’aide des cas préexistants, par exemple à l’aide des connaissances d’un expert, il faut à coup sûr l’ajouter dans la base. Par contre, si la solution a été générée à partir d’anciens cas, la procédure est plus complexe. En effet il ne sera alors pas forcément nécessaire de rajouter directement le nouveau cas. On peut par exemple généraliser le cas antérieur, origine de la nouvelle solution. D’une autre manière, ce nouveau cas peut être intégré à une catégorie ou un épisode généralisé.
En ce qui concerne les informations à sauvegarder, il est évident que l’on doit sauvegarder les caractéristiques et la solution du problème. Dans certains domaines, on peut tout de même faire l’impasse sur les caractéristiques qui sont facilement déductibles ou sans intérêt pour le problème. Il est aussi possible d’enregistrer les explications du raisonnement ayant mené à la solution. Ceci va nous permettre d’utiliser l’adaptation dérivative comme nous l’avons vu précédemment. Il est aussi possible de sauvegarder les échecs comme nous l’avons vu dans le paragraphe précédent. On peut ajouter à la base les cas d’échecs ou les raisonnements incorrects.
Il s’agit ensuite de décider quel type d’index le système utilisera pour retrouver ce cas. La plupart des logiciels existants emploient la totalité des caractéristiques. D’autres méthodes vont parcourir la base pour trouver les caractéristiques les plus discriminantes avec le cas à ajouter.
Enfin il faut intégrer le nouveau cas dans la base. Au cours de cette phase, on va modifier l’indexation des cas existants pour que le système détecte plus facilement les similitudes lors de la recherche des cas similaires. Pratiquement on va augmenter le poids d’un index menant à un cas qui a permis d’atteindre un cas utile dans la construction de la solution. À l’inverse, le système va diminuer le poids d’un index menant à un cas qui conduit à un échec. En fin de compte, on privilégie certaines caractéristiques.
Il peut être intéressant à la fin de l’apprentissage de tester le système en lui reposant le problème qu’il vient de traiter. Ainsi on peut voir si le système se comporte comme on l’attend.
Technologies utilisées
Data mining
L'utilisation du data mining se révèle avantageuse dans l'indexation des données. L'indexation est un point très important pour le CBR. C'est grâce à elle que le calcul de similarité est effectué. Les index font référence à différents critères et le datamining va permettre d'indiquer les critères les plus discriminants et donc les plus représentatifs pour la construction des index.
De plus, le calcul de la distance entre les cas, effectué par la fonction de similarité intervient logiquement entre le nouveau cas et tous les anciens cas de la base. Grâce au datamining, des classes vont être constituées pour ainsi directement exclure les cas qui n'ont aucun rapport avec le cas actuel. Le calcul des distances grâce à la fonction de similarité s'effectuera ainsi uniquement à l'intérieur d'une même classe, ce qui réduira considérablement le temps d'exécution.
Datacleaning
Le datacleaning permet également d'augmenter les performances d'un système CBR. Il va faire en sorte que les données enregistrées dans le CBR soient justes et qu'il n'y ait pas de cas inexact qui pourrait entraîner des raisonnements totalement faux. Néanmoins, il peut arriver qu'un CBR possède dans sa base des cas contradictoires mais il ne doit pas pour autant ne plus être en mesure de tirer des conclusions, des expériences contradictoires existant dans la vie réelle.
Logique floue
La logique floue est utilisée dans les domaines où il est difficile de classifier des objets dans un ensemble ou un autre. Utiliser cette technologie apporte de nombreux avantages aux systèmes CBR :
- Une meilleure gestion de l’imprécision : avec la logique classique, une imprécision peut conduire à ruiner un raisonnement, elle sera en revanche bien tolérée si on utilise la logique floue.
- La traduction des quantificateurs linguistiques en informations numériques utilisables par le système : si la description de cas est textuelle, il y a de fortes chances pour que des caractéristiques soient qualifiées par des quantificateurs tel que « très », « un peu », « environ », etc. Ils seront facilement traduits par une valeur entre 0 et 1.
- La gestion des valeurs continues et réelles facilitées : l’indexation et la recherche de cas sera plus facile à mettre en œuvre.
- L’introduction des notions de confiance et de pertinence : pour chaque information stockée, ou pour chaque caractéristique du nouveau cas, on va utiliser le degré de confiance qu’on a dans l’information et la pertinence. Par exemple, si les informations proviennent d’une source peu fiable, la confiance sera faible. D’une autre manière, la pertinence va représenter l’importance d’une information pour le problème.
Certains systèmes CBR utilisent la logique floue dès le stockage des cas. Ils gèrent des degrés de pertinence et de confiance pour chaque cas. Mais la principale utilisation de la logique floue est faite au niveau de la recherche de cas similaires. Là aussi, les systèmes usent les degrés de confiance et de pertinence pour calculer les similarités. Enfin il est aussi possible d’optimiser l’adaptation à l’aide de cette technique.
Projets à base de raisonnement par cas
- CHEF : Ce logiciel se propose de réaliser des recettes de cuisine en utilisant la technique du CBR. L'utilisateur indique au programme les aliments dont il dispose et CHEF cherche à élaborer une recette à partir de ces ingrédients. Pour ce faire, il opère comme tout il CBR : il possède une très grosse base de données de "cas" de recettes valides et cherche à créer, par mimétisme, une nouvelle recette contenant les ingrédients choisis. CHEF a la particularité de tenir compte des échecs et de les sauvegarder afin d'éviter de les reproduire. Lorsque les contraintes imposées par l'utilisateur sont trop fortes et qu'aucune solution n'a été trouvée, CHEF donne une explication indiquant les raisons de l'échec.
- SWALE : Le projet SWALE cherche à fournir des explications à des situations anormales. Il apporte notamment des explications sur les causes de la mort des animaux ou des hommes. Le programme va par exemple comparer la mort inattendue d'un cheval de course très connu en pleine force de l'âge à la mort d'un cycliste due à une consommation excessive de produits dopants.
- PERSUADER : PERSUADER est un outil de gestion de conflits basé sur le raisonnement par cas. Il fonctionne sur le principe de négociation/médiation. Il est capable de fournir des solutions documentées pour la résolution de problèmes de groupe. PERSUADER fait en sorte de pouvoir construire un règlement mutuellement convenu entre les différents acteurs de la dispute.
 Portail de l’informatique
Portail de l’informatique
Catégories : Programmation informatique | Intelligence artificielle | Méthode d'analyse
Wikimedia Foundation. 2010.