- Inter-trame
-
Une inter-trame ou inter frame ou image inter désigne dans la compression vidéo une image ou une trame appartenant à un flux qui a été encodée à partir d'un algorithme de prédiction inter-trame. Elle dépend des images précédemment encodées afin de prédire la position des macroblocs d'origine. L'objectif de cet algorithme est de définir un vecteur de mouvement qui traduit le déplacement d'un bloc dans une image déjà encodée dite de référence et sa position dans l'image courante. Cette prédiction est aussi appelée prédiction temporelle. Elle a pour but de profiter des redondances temporelles entre les images ou trames voisines et ainsi obtenir un meilleur taux de compression. Elle se différencie de l'intra-trame qui est encodée à partir d'un algorithme de prédiction spatiale. L'avantage de la prédiction inter est que pour encoder un objet en mouvement, il suffit de trouver un bloc existant dans une image déjà encodée qui ressemble au bloc courant et d'encoder la différence des valeurs des composantes entre ces deux blocs ainsi que son vecteur alors que pour la prédiction intra, chaque macrobloc de l'image courante doit être encodée à partir de la texture de leurs voisins qui peut varier assez facilement.
Sommaire
Prédiction Inter-trame
Pour être encodée, une image est divisée en macroblocs (blocs de taille 16x16 pixels). Afin d'éviter d'encoder directement la valeur des pixels en brut, chaque macrobloc est prédit à partir soit de leur voisinage comme c'est le cas des prédictions intra-trames, soit à partir des images de références (cas de l'inter-trame). Le codage en inter consiste à trouver un bloc similaire au bloc courant sur une image de référence. Ce processus est réalisé par un algorithme de Block-matching. Si l'encodeur réussit à trouver un tel bloc, le vecteur reliant les deux blocs que l'on appelle vecteur de mouvement ((en)motion vector) sera enregistré et la différence entre ce vecteur et le vecteur prédit sera encodée. Ce vecteur prédit est défini par la norme et est fonction des vecteur des macroblocs voisins déjà encodés. Le processus calcule ensuite l'erreur de prédiction c'est-à-dire la différence de valeur des composantes de luminance et de chrominance entre le bloc prédit dans l'image de référence et le bloc d'origine, aussi appelée bloc résiduel. Ce dernier sera encodé dans le flux binaire après des étapes de transformée et de quantification. En codage vidéo, cette étape de recherche de vecteur est appelée estimation de mouvement et celle du calcul des différences est la compensation de mouvement.
D'une façon schématique:
Vecteur de mouvement - Vecteur prédit ⇒ Vecteur différentiel qui sera encodé.
Bloc ciblé - Bloc courant ⇒ Bloc résiduel qui sera transformé, quantifié et encodé.
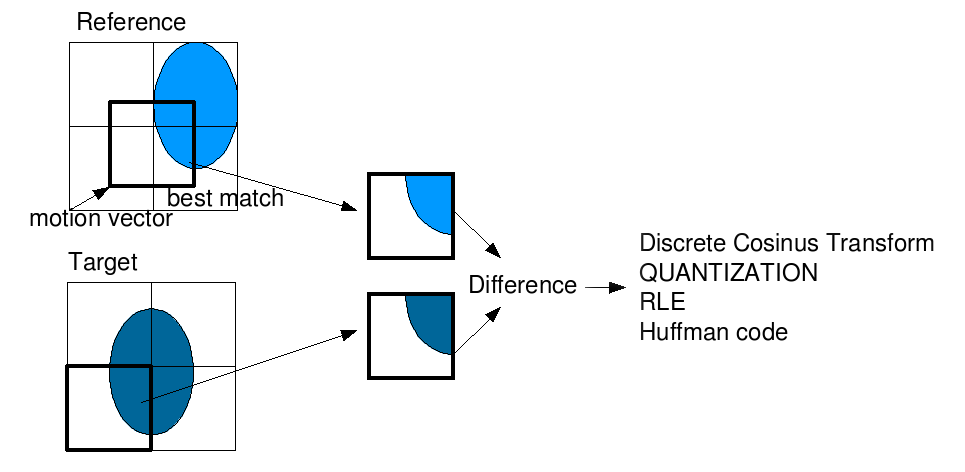
L'image suivant permet d'illustrer le processus de prédiction inter:
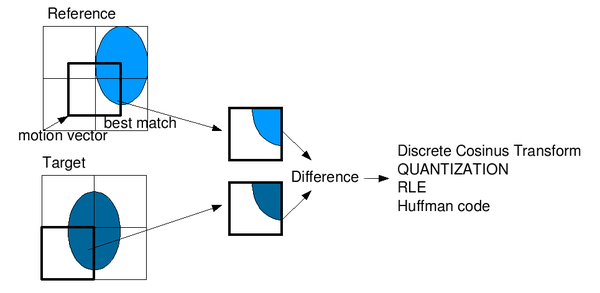 Processus de prédiction Inter-trame. Dans ce cas, il y a un changement de luminance entre le bloc de référence et le bloc à encoder : il s'agit de l'erreur de prédiction de ce bloc.
Processus de prédiction Inter-trame. Dans ce cas, il y a un changement de luminance entre le bloc de référence et le bloc à encoder : il s'agit de l'erreur de prédiction de ce bloc.
Du point de vue du décodeur, le processus n'a besoin que du bloc résiduel et du vecteur afin de rétablir les valeurs du macrobloc. En effet, les images de référence sont également décodées antérieurement et le vecteur prédit est connu puisque sa définition est connue par la norme. Le bloc décodé obtenu est différent du bloc d'origine étant donné qu'il s'agit d'une compression avec perte due à la quantification.
D'une façon schématique:Vecteur prédit + Vecteur différentiel ⇒ Vecteur de mouvement à appliquer dans l'image de référence.
Bloc ciblé + Bloc résiduel ⇒ Bloc décodé.
Ce type de prédiction a des avantages et des inconvénients. Si l'algorithme est capable de trouver un bloc avec des valeurs de composantes très proches du bloc courant, l'erreur de prédiction sera petite et donc une fois transformé et compressé, la taille de l'ensemble "vecteur de mouvement et bloc résiduel" sera plus faible que celle du bloc courant non compressé. A l'inverse, si l'estimation de mouvement ne trouve pas de bloc convenable, l'erreur de prédiction sera importante et le flux encodé prendra une taille plus significative que celle du bloc courant non compressé. Dans ce dernier cas, l'encodeur choisit un encodage brut de ce bloc. Pour résumer, plus la prédiction est bonne, plus la différence est minimale et donc meilleure sera la compression.
Cette technique de prédiction est limitée car elle ne peut pas servir à compresser toute une vidéo à elle seule. Si le bloc pointé par le vecteur de mouvement dans une trame de référence a été aussi encodé à partir d'un mode de prédiction inter-trame, les erreurs faites concernant son encodage seront également propagées sur le prochain bloc. En d'autres termes, si toutes les images étaient encodées avec seulement cette technique, il n'y aurait aucun moyen pour le décodeur de synchroniser le flux vidéo car il serait impossible d'obtenir les images de référence. C'est pourquoi, il est nécessaire de coder certaines images indépendamment du temps comme c'est le cas des images I appelées aussi intra frames ou I-trames qui ne sont encodées qu'à partir de leur contenu avec un algorithme de prédiction spatiale et qui n'ont pas besoin de données complémentaires pour être décodées. À partir de ces images fiables, il sera alors possible de décoder les images de référence.
Structure d'un Group Of Pictures (GOP)
Dans plusieurs codecs, il est défini deux types de trame inter: images P (P-frames) et images B (B-frames). Avec les I-frames, ces trois types d'images composent un groupe d'image, alias GOP ((en)Group Of Pictures), qui est répété périodiquement lors d'un encodage. Un GOP est composé d'une image I et contient généralement plusieurs images P et B, ce qui signifie qu'une seule image I permet de décoder tout un GOP. La synchronisation du décodage est réalisée grâce à la périodicité des images I dans le flux.
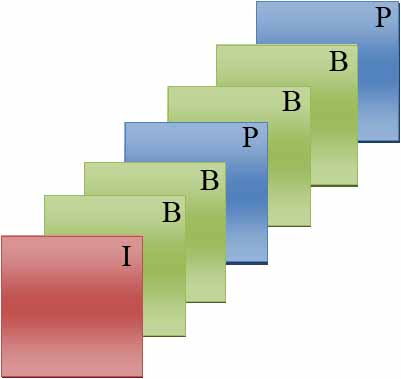
Une des structure typique d'un GOP est IBBPBBP...L'image I est utilisée pour prédire la première image P puis à partir de ces deux images, le processus prédit les deux premières images B. La seconde image P est prédite à partir de la première P-frame et les deux images B comprises entre ces deux images seront les suivantes. L'image suivante illustre ce type de GOP:
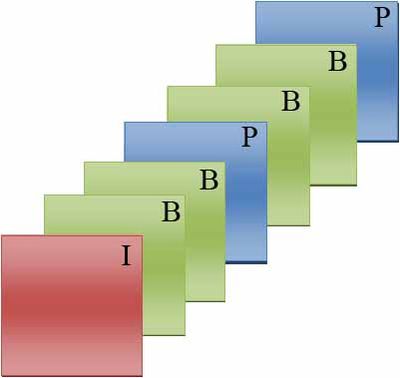 Exemple d'une structure de Group of Pictures
Exemple d'une structure de Group of PicturesAfin de pouvoir prédire les images, il est nécessaire de changer l'ordre des images à encoder. C'est pourquoi durant un encodage, un séquenceur établit à l'avance le type des images en connaissant la structure du GOP et change l'ordre des images à encoder afin d'obtenir toutes les images de référence. Dans cet exemple, l'ordre de visualisation est I B1 B2 P1 B3 B4 P2 mais l'ordre d'encodage est I P1 B1 B2 P2 B3 B4. Étant donné que le GOP a besoin d'être totalement décodé pour être visible, il est nécessaire de prévoir un temps de retard entre le décodage et la sortie d'une image à l'écran.
Types de trames inter
Les trames inter sont des types d'images ou de trame qui sont dépendantes d'images dites de référence pour être décodées. La différence entre les P-frames et les B-frames peuvent se résumer aux images de référence utilisées par l'algorithme de prédiction composé de l'estimation de mouvement et de la compensation de mouvement.
 Une séquence en image, constitués de deux images clés, une image P prédite à partir d'une image passée et une image prédite de façon bidirectionnelle (image B).
Une séquence en image, constitués de deux images clés, une image P prédite à partir d'une image passée et une image prédite de façon bidirectionnelle (image B).P-frame
Les P-frames sont des images prédites en avant (forward), à partir d'une image passée. La prédiction est réalisée à partir d'une image située plus tôt dans le temps, principalement une image I, et qui nécessite moins d'informations de codage (environ 50% de gain comparé à la taille d'une image I). Les informations à encoder concernent les vecteurs de mouvement et la correction de prédiction traduite par les coefficients transformés du bloc résiduel.
B-frame
Les B-frames sont définies comme des images prédites de façon bidirectionnelles, c'est-à-dire qu'elles sont prédites à partir d'une image future et d'une image passée. Ce type de prédiction nécessite également moins d'informations de codage que les P-frames car elles peuvent être prédites et interpolées à partir de deux images de référence qui l'encadrent temporellement. Tout comme les P-frames, les B-frames ont besoin des informations du vecteur de mouvement et du bloc résiduel ainsi que des images de référence pour être décodées. Afin d'éviter une trop grande propagation d'erreur, les images B ne sont généralement pas utilisées en tant qu'image de référence.
Améliorations de prédiction dans la norme H.264
L'une des améliorations majeures de la norme H.264 concerne la prédiction inter-trame. Elle permet:
- Un partitionnement de bloc plus flexible pour l'estimation de mouvement.
- Une compensation de mouvement avec une résolution jusq'au quart de pixel
- Un plus grand nombre d'image de référence (Multiple references)
- L'amélioration du mode de codage Direct/Skip pour macrobloc.
Partitionnement de bloc de H.264
Pour réaliser une compensation de mouvement précise et efficace, chaque macrobloc de luminance peut être divisé en sous-blocs (voir figure ci-dessous). Dans la norme MPEG-2, les partitionnements sont au nombre de 4: 1 bloc de 16x16 pixels, 2 blocs de 16x8 pixels, 2 blocs de 8x16 pixels ou 4 blocs de 8x8 pixels. Chaque partitionnement est associé à un mode d'encodage inter. Pour chaque mode, l'estimation de mouvement trouve le meilleur de vecteur de mouvement pour le sous-bloc qui pointe sur un bloc de même taille dans l'image de référence et la compensation calcule une approximation du coût de codage du macrobloc pour le mode donné. Une fois tous les modes réalisés, l'algorithme choisit le mode de partitionnement qui a donné le coût le plus faible et effectue l'encodage définitif du macrobloc.
Fichier:Block division.jpg Partitionnement de bloc de H.264
Dans la norme H.264, le nombre de modes de partitionnement augmentent avec la possibilité de diviser un bloc 8x8 en sous-blocs de dimension 4x8 pixels, 8x4 pixels ou 4x4 pixels.
Précision au quart de pixel
Afin d'être plus précis dans la recherche du vecteur de mouvement, l'image de référence est agrandie pour avoir une résolution plus importante. Au lieu de travailler avec une résolution au pixel près, les coordonnées du vecteur peuvent être définies à un nombre décimal de pixel. La probabilité d'obtenir un bloc similaire au bloc courant est plus grande et donc la recherche est beaucoup plus efficace. Dans la norme MPEG-2, la précision du vecteur peut atteindre le demi-pixel. En H.264, la précision au quart de pixel peut être choisie pour chaque mode de prédiction inter. Pour utiliser des valeurs de sous-pixels qui n'existent pas, des techniques d'interpolation sont utilisées. L'interpolation pour obtenir des demi-pixels consiste à appliquer un filtre de longueur 6 sur le voisinage du pixel courant. Cette première opération permet le calcul des valeurs au quart de pixel qui est réalisé par interpolation bilinéaire dans la norme H.264. La figure ci-dessous montre les différents pixels qui doivent calculés afin d'avoir une précision au quart de pixel.

Les références multiples
Ces références multiples concernent l'étape d'estimation de mouvement. Elle permet de trouver quelle est la meilleure image de référence parmi les images précédemment encodées pour chaque partition ou sous-partition. Il peut donc y avoir plusieurs images de référence utilisées pour encoder un macrobloc. S'il s'agit d'une image P, le nombre d'images de référence passées peut aller jusqu'à 4, c'est-à-dire que l'algorithme de recherche enregistre un vecteur pour chaque image de référence pour un bloc courant et calcule le coût d'encodage. Après avoir bouclé sur toutes les références, il compare et choisit le coût le plus faible. L'information concernant l'image de référence est alors encodée. En ce qui concerne les images B, le nombre de références peut aussi augmenter mais seulement dans les images passées, donc si on choisit deux images de référence, le processus utilisera l'image passée et l'image future les plus proches. Si on choisit quatre images, l'image future sera utilisée ainsi que les trois images 'passées les plus proche de l'image courante. Dans la norme, les images de référence sont gardées dans des buffers appelés List0 pour les images passées et List1 pour les images futures. Même s'il existe un coût d'encodage du aux images de références, cette technique permet d'augmenter la qualité de l'image et une meilleure compression, l'erreur de prédiction étant généralement moins importante.

Amélioration du mode Direct/Skip
Les modes Skip et Direct sont fréquemment utilisés spécialement avec les images B. Ils réduisent significativement le nombre de bits à coder. Si ce mode est choisi par l'algorithme, aucune information complémentaire ne sera encodé, aucun vecteur de mouvement et aucun bloc de résidus. Dans ce cas, le décodeur déduit le vecteur de prédiction défini à partir des macroblocs voisins déjà encodés. L'encodeur enregistre seulement l'information du mode de prédiction correspondant au macrobloc skip.
Dans la norme H.264, il existe deux manières de déduire le mouvement:
- Mode direct temporel:
Il utilise le vecteur de mouvement du bloc à partir de l'image de la List1, situé à la même position pour déduire le vecteur de mouvement du bloc courant. Le bloc du buffer List1 utilise le bloc de List0 comme référence.

- Mode direct spatial:
Il prédit le mouvement à partir des macroblocs voisins dans l'image courante. Le critère possible pourrait être de copier le vecteur de mouvement à partir du bloc voisin. Ces modes sont utilisés dans des zones uniformes de l'image où il n'y a pas beaucoup de mouvement.

Dans la figure ci-dessus, les blocs roses sont des blocs skippés, utilisant le mode Direct/Skip. Dans cet exemple, la plupart des macroblocs de l'image B ont été encodés avec ce mode.
Informations supplémentaires
Bien que l'utilisation du terme frame (trame) est commun dans l'usage informel, un concept plus général est employé avec le mot picture (image) plutôt que trame car l'image peut aussi bien être une trame complète ou un simple field (champ) entrelacé.
Les codecs vidéos tels que MPEG-2, H.264 ou Ogg Theora réduit la quantité de données dans un flux en suivant les images clés avec une ou plusieurs inter-trames. Ces trames peuvent être typiquement encodées en utilisant un plus faible débit binaire que ce qu'elles nécessiteraient car une grand partie de l'image est habituellement similaire, donc seulement les parties en mouvement ont besoin d'être codées.
Références
- (en) Cet article est partiellement ou en totalité issu de l’article de Wikipédia en anglais intitulé « Inter frame » (voir la liste des auteurs)
- Software H.264: http://iphome.hhi.de/suehring/tml/download/
- T.Wiegand, G.J. Sullivan, G. Bjøntegaard, A.Luthra: Overview of the H.264/AVC Video Coding Standard. IEEE Transactions on Circuits and Systems for Video Technology, Vol. 13, No. 7, July 2003
- ThomasWiegand, Gary J. Sullivan, « “Overview of the H.264/AVC Video Coding Standard » sur http://ip.hhi.de, IEEE, 2003. Consulté le 19 janvier 2011
- Serkan Oktem et Ilker Hamzaoglu, « An Efficient Hardware Architecture for Quarter-Pixel Accurate H.264 Motion Estimation » sur http://people.sabanciuniv.edu. Consulté le 19 janvier 2011
- Jeremiah Golston et Dr. Ajit Rao, « Video codecs tutorial: Trade-offs with H.264, VC-1 and other advanced codecs » sur http://www.eetimes.com, 2006. Consulté le 19 janvier 2011
Annexes
Articles connexes
Liens externes
- (en) tutoriels H.264
- (en) H.264 and Video Compression

Wikimedia Foundation. 2010.