- C10k problem
-
Le c10k problem[note 1] que l'on pourrait traduire en français par le problème des dix mille connexions simultanées, est un code numérique utilisé pour exprimer la limitation que la plupart des serveurs ont en termes de connexions réseaux. Cette limite repose sur le constat que dans les différentes configurations matérielles et logicielles possibles des grands serveurs actuels ne semblent pas capables de supporter plus de dix milles connexions simultanées. Cette limitation est partiellement imputable à des contraintes liées aux systèmes d'exploitation et à la conception des applications clients-serveurs auxquelles ils prennent part[1].
Dans le contexte particulier des serveurs web, depuis l'identification de ce problème, quelques solutions ont été proposées, mais la plupart des serveurs utilisés ne parviennent pas à dépasser cette limite.
Sommaire
Problématique
La démocratisation de l'Internet depuis le début des années 1990 et les millions d'internautes qui l'accompagnent[2], pose aux serveurs gérant ces services, le problème de leur capacité à prendre en charge cette fréquentation, notamment pour les services à forte fréquentation (moteur de recherche, site de réseaux sociaux, jeux en ligne, etc.), qui est leur capacité à prendre en charge un nombre important de clients et donc de requêtes simultanées - Microsoft comptabilisait 300 millions de hits par jours sur ses sites web pour 4.1 millions d'utilisateurs[3].
Cette problématique s'est accélérée avec les réseaux haut débit notamment l'ATM transmettant toujours plus rapidement des requêtes aux serveurs frontaux lesquels devant prendre en charge ces requêtes sans générer de goulots d'étranglements. Les infrastructures réseaux ayant apporté des solutions notamment des fonctions de cache afin d'améliorer les performances, le cœur du problème s'est focalisé sur les serveurs eux-mêmes[4].
Si aujourd'hui les limites physiques liées au matériel sont repoussées, plusieurs éléments de l'architecture d'un système d'exploitation dont la gestion des entrées-sorties et le modèle de communication concurrente peuvent influer et sont, à ce titre, déterminants voire structurants pour la performance de la gestion des accès concurrents[1].
Modèle de communication concurrente
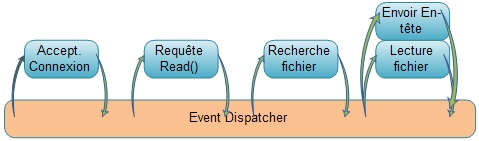
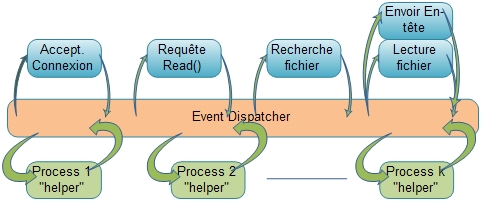
Lorsqu'un serveur web traite une requête HTTP pour laquelle il retourne un simple fichier proposant un contenu HTML, différentes étapes nécessaires à la fourniture de cette réponse vont s’enchaîner successivement[5] :
- accepter la connexion entrante du client et créer la socket associée ;
- lire la requête et l' entête HTTP ;
- rechercher le fichier demandé dans le système de fichier avec contrôle des droits de lecture ;
- transmettre l'entête de réponse sur la socket client ;
- lire le fichier ;
- et transmettre son contenu sur la socket ouverte.
Chacune de ces étapes inclue des opérations de lecture et d'écriture, mais aussi d'ouverture de socket de connexion et de fichier. Et chacune de ces opérations peut générer le blocage (ou du moins la suspension) du processus lorsque les données attendues ne sont pas présentes[5]. Le système d'exploitation des serveurs intercale (entrelace) ces différentes étapes pour les différentes requêtes qu'il reçoit, afin d'optimiser l'utilisation des ressources[5].
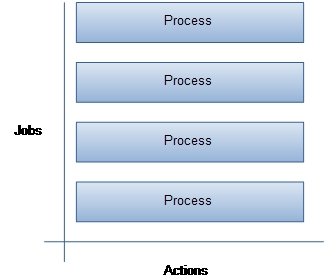
La stratégie mise en œuvre pour gérer cet entrelacement est donc déterminante. On distingue 2 principaux modèles de communication pour la gestion des accès concurrents formalisés pour la première fois en 1978 par Lauer et Needham[6]. Le débat récurrent qui oppose ces 2 modèles sévit depuis des décennies[7].
Modèle thread-driven (thread-based)
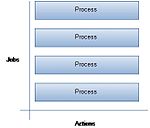 Modèle thread-driven ou Système orienté process.
Modèle thread-driven ou Système orienté process.
Alors qu'un processus est un programme en exécution, l’unité de travail dans un système en temps partagé, un thread, également appelé processus léger, est quant à lui l'unité de base d’utilisation du processeur. Il utilise les mêmes ressources et le même espace mémoire que le programme dans lequel il est exécuté, mais possède son propre pointeur d’instructions et sa propre pile d’exécution [8].
Le modèle thread-driven[note 2] s'appuie donc sur un ensemble de threads de contrôle qui vont prendre en charge les différentes tâches d'exécution [9]. Dès lors qu'un thread est bloqué sur une opération d'entrée-sortie, il passera la main à un autre thread éligible au sein du même espace d'adressage. Jusqu'à ce que l'entrée-sortie soit terminée, après quoi, le thread redevient prêt à utiliser[10]. La coopération entre les threads est assurée par des mécanismes de synchronisation matérialisés sous forme de verrous, sémaphores ou autre mutex et qui permettent de gérer les accès à des ressources partagées.
Une optimisation a été apportée en mettant en œuvre un pool de threads qui distribue les tâches d'exécution sur des threads créés, initialisés par avance. Ainsi, le gain se situe au niveau du temps inhérent à la création et à la suppression des threads[10][11]. Ce modèle est proposé dans les langages de programmation tel que Java[12].
Par ailleurs, la surcharge due à l'overhead[note 3] lié à la synchronisation des threads peut être contournée par la mise en œuvre de threads coopératifs comme cela a été implémenté dans le paquetage Capriccio[13].
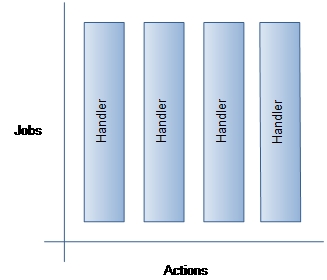
Modèle event-driven
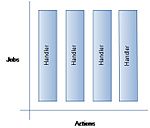 Modèle Event-driven ou Système orienté message
Modèle Event-driven ou Système orienté messageLe modèle event-driven[note 4], qui repose sur un mécanisme de multiplexage des entrées-sorties[14], est organisé autour de l'exécution d’événements (par exemple arrivée d'une requête pour une page web) et permet ainsi de gérer la concurrence grâce à une boucle à événements qui va répartir l’événement sur un ou plusieurs gestionnaires qui vont prendre en charge cet événement[15]. Ces gestionnaires peuvent à leur tour solliciter un autre gestionnaire d’événements (pour gérer par exemple une demande de lecture sur disque). Les gestionnaires communiquent entre eux par messages ou par événements. Les fonctions devront être courtes afin de rendre la main à la boucle à événements et de ne pas laisser les événements s'accumuler[réf. nécessaire].
Les systèmes event-driven sont organisés autour d'un seul thread (SPED - Single Process Event-Driven) qui gère donc des événements. Quand un programme ne peut terminer une opération car en attente d'un événement, il enregistre un rappel de service au niveau de la boucle à événements qui inspecte les événements en entrées et qui exécutera le rappel de service lorsque l’événement se produira[16].
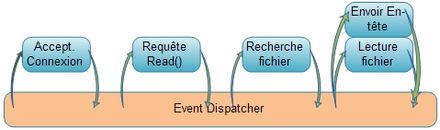 Single Process Event Driven - SPED
Single Process Event Driven - SPEDLe modèle event-driven est adapté pour les applications hautement concurrentes[15]. Les raisons sont que les systèmes event-driven permettent des optimisations qu'il est difficile de mettre en place dans les modèles threads-driven, des messages peuvent être traités en traitement par lots[15], un meilleur ordonnancement est possible, le contrôle de flux est plus flexible, et il n'y a pas de basculement de contexte[15].
Modèle hybride
Les deux modèles thread-driven et event-driven présentent cependant l'un et l'autre des limitations.
Le modèle par threads présente quelques difficultés relatives notamment à la gestion de la synchronisation des threads (utilisation de verrou, sémaphore, mutex, variables de condition, waitable timer – la contention de verrou peut engendrer des problèmes de performances en cas d'augmentation du nombre de threads) et des limitations relatives aux nombres de threads gérés par un système[17].
Le modèle par événements ne prend pas en charge le Multiprocessing (en), ne tirant ainsi pas avantage des architectures multiprocesseurs[18]. D'autre part, la gestion par événements est dépendante de mécanismes pas forcément correctement supportés par le système d'exploitation ou le langage. Enfin les programmes sont souvent plus complexes à développer et à debugger[19].
Pour essayer de tirer partie des deux modèles, un modèle hybride a été conçu. SEDA[note 5] est un framework s'appuyant sur les trois composants qui font la force des modèles Event Driven et Thread Driven que sont les tâches, queues et pool de threads. Ce framework utilise également une queue d’événements, un pool de threads et un gestionnaire d’événements[20] (cf « SEDA (Staged event-driven architecture) »).
Par ailleurs, la librairie de programmation libasync[note 6] supporte le multi-processeurs et permet de s'affranchir de la gestion des verrous et de la coordination des exécutions de threads propre à une gestion par thread[21].
Le modèle AMPED (Asymmetric Multi-Process Event Driven, en français : modèle piloté par événements asymétriques à processus multiple)[note 7] met en œuvre un processus principal (event dispatcher) pour le traitement des requêtes et d'autres processus ou threads pour gérer les entrées-sorties disques. Ces threads sont sollicités via un canal IPC de communication interprocess. Cette architecture est utilisée pour le web server Flash[22].
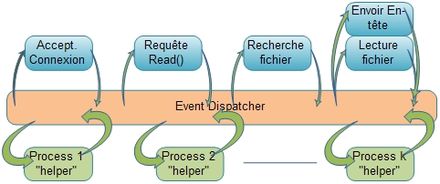 Asymmetric Multi-Process Event Driven - AMPED
Asymmetric Multi-Process Event Driven - AMPEDLa gestion des entrées-sorties
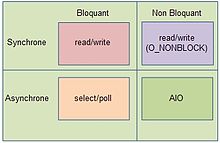 Matrice simplifiée des modèles d'Entrée-Sorties basique
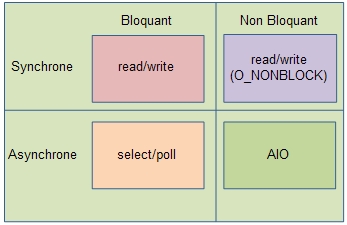
Matrice simplifiée des modèles d'Entrée-Sorties basiqueVu d’un processus, les communications sont gérées comme des fichiers, les entrées-sorties reposant sur des descripteurs de fichiers (en Anglais : Filehandler). Ainsi une émission est assimilée à une écriture sur un fichier tandis qu'une réception est assimilée à une lecture sur un fichier. À chaque processus est associé une table des descripteurs de fichiers. Il s’agit d’un tableau de pointeurs, chaque pointeur pointant indirectement sur un fichier (v-node) ou sur une communication (socket). Un serveur, web par exemple, devant gérer simultanément un très grand nombre de flux d’entrée et de flux de sortie, le problèmatique est les attentes actives sur plusieurs descripteurs. Quatre modèles de gestion coexistent sous Linux en fonction de leur caractère bloquant ou non-bloquant et synchrone ou asynchrone (voir Figure «Matrice simplifiée des modèles d'Entrée-Sorties basique»)[23].
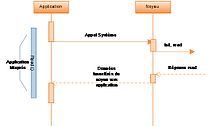 Séquence de lecture d'Entrée-Sorties Synchrone Bloquante
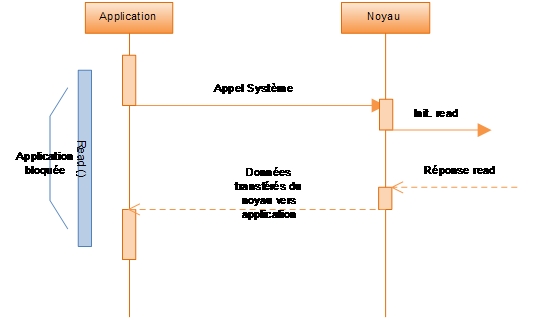
Séquence de lecture d'Entrée-Sorties Synchrone Bloquante- Entrées/Sorties bloquantes synchrones
- Lorsqu'une application effectue un appel système
read(), celle-ci se bloque, le contexte bascule au niveau du noyau. Tant que la réponse auread()n'est pas retournée, l'application est en attente de la réponse (fin d'exécution ou erreur). Une fois celle-ci retournée, l'application se débloque[24]. Ce modèle reste encore le modèle le plus répandu dans les applications mais il est efficace d'un point de vue performance unitaire uniquement[réf. nécessaire]. - Entrées/Sorties non-bloquantes synchrones
- Dans ce modèle, la différence est que le noyau répond immédiatement afin de ne pas bloquer ; la réponse consiste en un code erreur indiquant que la commande est en attente[23]. Cela nécessitera des appels systèmes supplémentaires de l'application pour une lecture de la réponse seulement une fois celle-ci disponible[23]. Cette variante est moins efficace (notamment en raison de la latence entrées/sorties)[25].
- Entrées/Sorties bloquantes asynchrones
- Un thread initialise une entrée-sortie via un appel système
read()et délègue ensuite la tâche à un sélecteur pouvant ainsi basculer à une nouvelle tâche. Le sélecteur vérifie alors l'arrivée d'événement entrées-sorties sur le descripteur de connexions[26]. L'intérêt étant que le sélecteur gère la notification d'un ensemble de descripteurs de connexions[26].
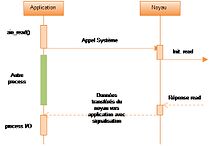 Séquence de lecture d'Entrée-Sorties ASynchrone Non-Bloquante
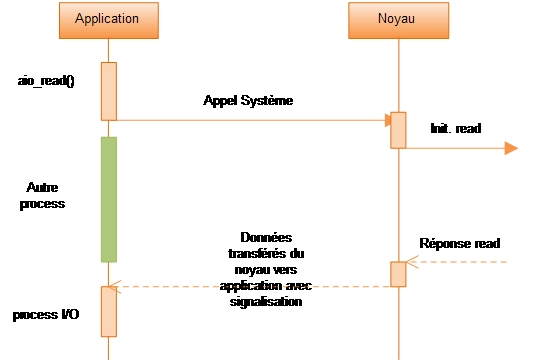
Séquence de lecture d'Entrée-Sorties ASynchrone Non-Bloquante- Entrées/Sorties non-bloquantes asynchrones (AIO)
- Une réponse est immédiatement apportée à l'appel
read(), celle-ci indique que le read est initialisé avec succès. L'application exécute alors d'autres tâches. Quand la réponse est prête, un signal ou un process de rappel est généré pour finaliser l'entrée-sortie[23]. Ce modèle est une addition récente au noyau Linux puisqu'il est ajouté au standard de la version 2.6 de Linux[27] (était un patch pour 2.4[27]).
En pratique, les mécanismes asynchrones sont les modèles utilisés pour le développement de serveurs à haute performance car cette approche permet d'économiser des ressources en termes d'utilisation du microprocesseur[24].
Pour la gestion des entrées-sorties (en mode asynchrone), les premiers systèmes Unix ont implémenté des mécanismes de notification par événements tels que
select()oupoll(). Ils permettent de notifier lorsque les descripteurs de fichiers sont prêts.Un processus utilisateur qui effectue un appel système
select()indique en paramètre (via des bit-maps) son intérêt dans 3 types d'événements/état d'un descripteur : readable (i.e. qui peut être lu) sans blocage, writable (i.e. qui peut être écrit) avec blocage, exception/erreur. Le noyau va alors envoyer en retour l'ensemble des descripteurs ready pour le type de descripteur demandé[28].L'appel
poll()a la même fonction que l'appelselect()mais l'interface est différente en cela que les intérêts ne sont pas décrits avec des bit-maps mais dans un tableau de structures d'objetpollfd. Cela permet de modifier le mécanisme en attendant que l'un des descripteurs de fichier parmi un ensemble soit prêt pour effectuer des entrées-sorties. Quand le processus exécute un appel systèmepoll(), le système d'exploitation examine si l'objet descripteur de fichier remplit les conditions définies dans le champ «event». Si c'est le cas, il remplit alors le champ «revent» avec les résultats. Si par contre le champ «revent» est vide, l'appel est bloqué jusqu'à la fin du time-out ou jusqu'au changement d'état suite au remplissage du champ par exemple[29].Historique
Comme Dan Kegel l'a écrit dans son article « The C10K Problem », dont la première publication date de 1999, les serveurs sont matériellement suffisamment puissants pour gérer 10k connexions simultanées. Le problème réside donc dans la mise en œuvre des systèmes d'exploitation[1].
- août 1983
- la fonction
select()est introduite dans la version 4.2BSD d'Unix. Cette fonction permet de gérer les entrées-sorties non bloquantes en scrutant les arrivées des requêtes client afin de pouvoir y répondre. Elle a été ajoutée pour permettre de gérer un plus grand nombre de connexion que le modèle de flux d'Unix, read()/write() [30]. - 1986
- L'arrivée de la fonction
poll()pour Unix permet de réduire davantage la consommation des ressources. - 1997
- La fonction
poll()est implémentée dans le noyau Linux[31]. - 1999
-
- en mai, SUN implémente une nouvelle alternative à la fonction
poll()à travers le descripteur de fichier/dev/poll[32] sur Solaris 7 qui complète la fonctionpoll(). L'utilisation de ce descripteur permet de mieux tenir la montée en charge lors de l'ouverture d'un grand nombre de descripteurs en simultanés[33]. En effet, il rassemble tous les descripteurs de fichiers, les surveille, et renvoie ceux qui sont prêts à travailler. L'équivalent pour linux estepoll()[31] et pour FreeBSD et NetBSDkqueue()[34]. - Silicon Graphics, Inc. (SGI) implémente une gestion des entrées/sorties asynchrones pris en charge par le noyau (KAIO), qui fonctionne aussi bien avec les entrées/sorties disque qu'avec les sockets[1]. L'implémentation des AIO Linux par Ben LaHaise est introduite dans la version 2.5.32 du noyau Linux, mais ne supporte pas les sockets[35].
- en mai, SUN implémente une nouvelle alternative à la fonction
- 2001
-
- en mai, Vitaly Luban implémente un patch signal-per-fd, solution proposée par A. Chandra and D. Mosberger[36].
- 2002
-
- Ulrich Drepper, annonce la disponibilité de la nouvelle librairie de threads Linux, POSIX, basée sur le modèle 1:1, qui doit amener une meilleure performance en termes de connexions simultanées[37]. Pour Solaris les modèles 1:1 et M:N étaient utilisés jusqu'à la version 8. Mais seul le modèle 1:1, est disponible avec la version 9[38].
- en octobre, FreeBSD 4.3 et versions postérieures ainsi que NetBSD implémentent kqueue()/kevent(). kqueue()/kevent() supporte à la fois des notifications d’événements de type edge-triggered et level-triggered[39].
- plusieurs serveurs web ont vu le jour, permettant de dépasser les 10k connexions simultanées. Parmi eux Nginx (2002), Lighttpd (2003) et Yaws (2002).
- 2003
-
- en mai, JDK 1.3 implémenté par de nombreux fournisseurs permet de gérer 10 000 connexions en simultanées. Le micro benchmark de Volano blog[40] liste les JVM pouvant supporter 10 000 connexions.
- 2006
-
- en juillet, Evgeniy Polyakov publie un patch qui unifie epoll et AIO[41]. Son objectif est de supporter AIO réseau.
- en juillet, Robert Watson propose que le modèle 1:1 thread soit par défaut dans freeBsd 7.x[42].
- en septembre Dan Kegel remet à jour son article de 1999, qui n'a plus évolué depuis[1].
Limites des mécanismes standards
Certaines limitations, rendant la mise à l'échelle peu performante dès que le nombre de descripteurs de fichiers à gérer augmente - et faisant que plus ce nombre de descripteurs augmente, plus le temps nécessaire à l'application pour configurer le sélecteur et interpréter les résultats et au système d'exploitation pour fournir les résultats augmente lui aussi - sont à noter :
- mécanismes sans mémoire
- Entre deux appels, ils ne mémorisent pas les descripteurs qui intéressent les applications – cela est dû au fait que les deux tâches, correspondant à l'attachement à un événement et à la recherche d'un événement, sont imbriquées dans le même appel système.
- mécanismes à états plutôt qu'à mécanismes à événements
- c'est-à-dire qu'ils fournissent toutes les informations sur tous ses descripteurs avec chaque notification, alors qu'il faudrait uniquement remonter les changements depuis la dernière notification. Cela génère une quantité de données importante à copier entre le noyau et l'application[43].
- manque d'optimisation
- pas plus de 512 descripteurs ouverts en même temps.
- limites du
select() - En effet, cette fonction utilise un algorithme qui opère un parcourt intégral de la table des descripteurs même si peu de sockets sont dans l'état ready[44] Il est ainsi constaté que le coût est plus proportionnel au nombre de descripteurs de fichier impliqués dans l'appel plutôt qu'au nombre de résultats utiles c'est-à-dire d'événements découverts par l'appel[28].
Les sous-systèmes Entrées/Sorties de Linux ont subi plusieurs évolutions majeures pour leur permettre d'être plus réactifs quelle que soit la charge :
- RT signal qui est une extension du traditionnel signal UNIX permet de remonter des événements via la queue signal lorsque le descripteur est prêt. Cette approche ne contient pas de notion d'intérêt comme cela existait pour l'appel
select()[45] ; - Signal-per-fd permettant de réduire le nombre d'événements fournis par le noyau et d'éviter ainsi un dépassement de capacité de la queue empilant les signaux ce qui pouvait se produire avec la solution RT signals précédente[45] ;
/dev/pollsimilaire àpoll()mais apporte la mémoire qui lui manquait, en ce sens où le jeu de descripteurs qui intéresse le processus utilisateur est re-mémorisé par le système d'exploitation entre les requêtes de l'application[46] ;epoll()sépare les mécanismes pour obtenir un événement (epoll_wait()) et celui pour déclarer un attachement à un événement (epoll_ctl()) [47].
Solutions existantes
Solutions identifiées par Kegel
Stratégies Entrées/Sorties
La stratégie Entrées-Sorties [note 8], c'est-à-dire la combinaison entre la gestion des Entrées/Sorties et le modèle de communication concurrente est déterminante pour répondre aux problèmes des 10K connexions simultanées.
Kegel aborde les cinq approches suivantes sur ce sujet[1]:
- Servir plusieurs clients dans un thread avec des appels Entrées/Sorties non bloquantes et des notifications de type Interrupt#Level-triggered (en)
- Cette approche (la plus ancienne) utilise des appels Entrées/Sorties du type
select()[31] oupoll()[31], mais elle a montré ses limites (voir Section Problématique) en termes de gestion de la concurrence ; - Servir plusieurs clients par thread avec Entrées/Sorties non bloquantes et notifications Interrupt#Edge-triggered (en)
- La principale évolution réside dans l’utilisation d’une méthode de notification d’événements de type edge-triggered, c'est-à-dire détection de transitions, qui répondent mieux à la problématique en présentant une meilleure résistance pour la montée en charge. Suivant les OS, ces implémentations se nomment :
kqueue[48] : sur les systèmes FreeBSD et NetBSDepoll()[31] sur les systèmes Linux à partir de la version 2.6Kevent[49] pour Linux 2.6 également, qui reprend la philosophie dekqueueSignal-per-fd: qui reprend le concept des signaux temps réels. Dans l'article de A.Chandra [50], celui-ci le compare aux appelspoll()etselect()sans toutefois aller jusqu’à la limite des 10k.- Servir plusieurs clients par thread avec des appels Entrées/Sorties asynchrones (AIO)[note 9]
- Les appels asynchrones sont en fait une surcouche aux opérations Entrées/Sorties standards, qui offre une interface de soumission d’une ou plusieurs requêtes Entrées/Sorties dans un seul appel système (
io_submit()) sans en attendre la fin. Une seconde interface (io_getevents()) permet de recueillir les opérations associées. - En 2006, lorsque Kegel publie son étude, peu de systèmes d'exploitation supportaient les appels asynchrones. Mais une étude sur la performance et la robustesse des AIO[51] montre que celles-ci ne sont pas adaptées à tous les cas d’utilisations.
- Coté Linux la version 2.6 supporte également les AIO[52] et notamment les distributions RedHat et Suse. Toutefois, les appels asynchrones ne peuvent ouvrir une ressource Entrée/Sortie disque sans blocage, Linus Torvalds explique cela et préconise de gérer les appels Entrées/Sorties disque dans un thread différent et de façon standard (
open())[53] - Coté Windows, les AIO sont appelés « I/O Completion Port[54]
- Servir 1 client par thread
- Le problème dans cette approche est l'utilisation d’une stack entière par client, ce qui coûte beaucoup de mémoire (certaines stacks peuvent avoir 2 Mégaoctet)... La plupart des OS ne peuvent gérer plus de quelques centaines de threads, notamment les OS 32bits avec un espace d'adressage mémoire limité à 4 Gigaoctet. L'arrivée des OS 64 bits repousse cette limite jusqu’à 64 Gigaoctet d'adressage mémoire, ce qui permet une gestion d'un bien plus grand nombre de threads. Von Behren, Condit and Brewer sont des ardents défenseurs de cette approche et mettent en avant une plus grande simplicité de programmation par rapport à l’approche event-based programming[55]
- Introduire du code applicatif dans le noyau
- deux implémentations sont largement documentées :
- De nombreux débats ont ont eu lieu dans la liste linux-kernel, autour de ces solutions[58]. La décision a finalement été de privilégier la limitation d'ajout au noyau pour augmenter la performance des serveurs web, plutôt que d’introduire les serveurs web dans les noyaux.
Implémentation des threads dans les OS
Comparatif du modèle 1 :1 versus modèle M :N
Il y a deux façons d'implémenter les threads dans un système d'exploitation :
- Le modèle 1:1 Thread_(computer_science)#Models (en) ;
- Le modèle M:N Thread_(computer_science)#Models (en).
Rob von Behren et ses partenaires, sur le contexte Capriccio, indiquent que le modèle 1:1, qui est plus facile à implémenter que le modèle M:N, est aussi bien plus performant[59]. Par ailleurs, Capriccio a fait le choix d'une implémentation de thread utilisateur et non de thread noyau, ce qui offre l'avantage d'éliminer l'overhead[note 10] de synchronisation [60].
Linux : LinuxThreads est le nom de la bibliothèque standard des threads Linux. Il s'agit d'une implémentation partielle des POSIX_Threads#Models (en) pour Linux[61]. Deux nouvelles implémentations ont vu le jour:
- Next Generation Posix Threads for Linux (NGPT) : uniquement sur le noyau Linux 2.5
- Native Posix Threads Library for Linux (NPTL) : cette implémentation a pris le pas sur NGPT. Déjà identifiée par Kegel comme étant une solution au C10K problem, Ulrich Drepper a rectifié son article en indiquant qu'il s'était trompé et qu'il s'agirait d'une fausse piste[62]
FreeBSD : Les versions les plus anciennes supportent les LinuxThreads vus plus haut. Le modèle d'implémentation M:N a été introduit à partir de la version 5.0 sous le nom de KSE[63]. En 2006, Robert Watson propose une implémentation du modèle 1:1 [64] qui va devenir le modèle par défaut à partir de la version FreeBSD 7.X
NetBSD Un exemple d'implémentation sur NetBSD a été présenté à la conférence annuel FREENIX de 2002[65],[66].
SUN Solaris Les versions 2 à 8 de Solaris repose sur le modèle M:N, mais dès la version 9, Solaris migre vers le modèle 1:1[67].
Côté Framework Java, il ne peut gérer que le modèle 1 client par thread. En 2003 quelques produits permettent de gérer les c10k (BEA Weblogic), les autres rencontrent des problèmes de OutOfMemory[note 11] ou Segmentation fault [note 12],[68].
Approches récentes
Asynchrone par transmission de message: Erlang
On peut citer les implémentations de serveurs Web basés sur Erlang, le langage d’Ericsson dédié aux développements d’application concurrente et temps réel. Ce langage propose une distribution nommée Open Telecom Platform (en) (Open Telecom Plaform) constituée de plusieurs bibliothèques offrant des fonctionnalités de distribution très avancées des traitements et de supervision des nœuds, ainsi qu'une base de données répartie. Erlang peut s’interfacer avec Java et C/C++.
La principale force d’Erlang est son architecture mémoire. Chaque thread possède son propre espace mémoire à contrario de java où tous les threads partagent un même espace. Les transmissions de données se font par échange de message via leur propre espace mémoire. Les messages sont déposés et le destinataire vient les récupérer quand il en a besoin. Jesper Wilhelmsson dans sa thèse[69] explique que ce mode de gestion de la mémoire est très efficace pour les applications concurrentes.
Plusieurs serveurs web légers ont été développés avec Erlang dont Mochiweb[70], Yaws(Yet another web server), inets[71]. Facebook Chat Application est également développée avec Erlang[72].
1. Implémentation de Mochiweb Richard Jones, sur son blog[73] explique comment développer une application Comet pouvant traiter 1 million de connexions en simultanées en se basant sur Mochiweb. Le modèle d’application Web Comet permet au serveur Web de faire du push vers le navigateur. Dans cette approche, chaque connexion Mochiweb est référencée par un routeur qui distribue (push) les messages à chaque utilisateur connecté en simultané. Les observations sur cette application basée sur Mochiweb montrent que pour 10 000 utilisateurs connectés en simultané pendant 24 heures, avec un taux d’émission de 1000 messages/sec (soit 1 utilisateur recevant 1 message toutes les 10 secondes), la ressource mémoire consommée est de 80MB soit 8KB par utilisateur.
En optimisant avec une base de données de souscription telle que Mnesia (en) à la place du routeur d’origine, le serveur Mochiweb peut gérer 1 million de connexions simultanées présentant toutefois une forte consommation de mémoire 40GB, soit 40kB par connexion. Ce qui n’est pas déraisonnable vu que la mémoire est très bon marché actuellement.
2. Implémentation de Yaws Yaws est un server http très performant adapté particulièrement au contenu dynamique des applications Web. Les mesures comparatives réalisées par Ali Ghodsi[74] montre qu' Apache s’écroule totalement avec 4000 requêtes en simultanées alors que Yaws continue à fonctionner avec 90000 requêtes. Le comparatif est réalisé avec un serveur Yaws sur file system NFS, un serveur Apache sur NFS également, et un serveur Apache sur un file système local. Les serveurs reçoivent en boucle une requête 20 Kbits. Dès qu’ils répondent, une nouvelle requête arrive.
SEDA (Staged event-driven architecture)
SEDA[75], acronyme de Staged event-driven architecture (en), est le sujet de thèse de Matt Wesh qui présente une nouvelle approche de développement d’une plateforme de service internet robuste, pouvant supporter de massives concurrences et plus de 10 000 connexions en simultanées[76]. La philosophie dans SEDA[77] est de décomposer une application événementielle complexe en un ensemble d’étapes connectées à une file d’attente. Ainsi, un traitement complexe se décompose en une suite d'opérations. Ces opérations sont elles-mêmes décomposées en un ensemble de messages à traiter. Ces messages sont ensuite aiguillés vers un ou plusieurs « workers ». Toutes ces étapes et dispatching sont gérés par un Framework. Le développeur n’aura qu’à se concentrer sur l’implémentation du code métier et laisser le Framework gérer la complexité technique. Cette conception permet d’éviter les overheads associés aux modèles un thread par requête (thead-based concurrency). Elle découple les événements et l’ordonnancement des threads de la logique applicative. En effectuant le contrôle d’admission à chaque file d’attente d’événements, le service peut être bien conditionné ("well conditionned") pour charger, évitant ainsi que les ressources soient surexploitées lorsque la demande dépasse la capacité du service. L'architecture Staged event-driven emploie un contrôle dynamique pour adapter automatiquement des paramètres d'exécution (telles que les paramètres d'ordonnancement de chaque étape), comme pour gérer la charge, par exemple. Décomposer les services en une série d'étapes permet également la réutilisation et la modularité du code. Un benchmark montrant que Haboob (serveur Web SEDA)[78] est plus performant que Apache est présenté en page[79].
Les implémentations open source des architectures Staged event-driven sont : Apache ServiceMix (en), JCyclone[80], Haboob et Mule (software) (en).
Node.js, un moteur de javascript serveur
Node.js est un framework Javascript server utilisé au-dessus de Google V8, le très performant moteur Javascript open source implémenté dans le navigateur Google Chrome. Sur les mêmes principes que le serveur web lighttpd, Node.js n’utilise qu’un seul thread pour gérer des entrées/sorties non bloquantes. Node.js propose dans ses APIs uniquement des fonctions non-bloquantes. La gestion des I/O non-bloquants permet de rendre tout le code asynchrone et donc d'optimiser la gestion de la concurrence. De plus, il est très peu consommateur en mémoire car n’utilise qu’un seul thread à l’inverse d’ Apache qui utilise un thread par requête. Toutes les fonctions dans Node.js fournissent en paramètre un callback. Le callback est appelé en fin de traitement de la fonction avec le résultat en paramètre et une éventuelle erreur[81] . Ainsi, pendant le traitement d’une fonction, le thread peut être libéré pour traiter une nouvelle requête entrante. Node.js est très adapté pour la programmation évènementielle[82]. Les spécificités de Node.js en font une excellente plate-forme de développement d’applications temps réel orientées réseau (messagerie instantanée, systèmes de notification temps réel, etc.) performantes et scalables. Ryan Dahl, le créateur de Node.js présente dans cette vidéo[83] le moteur javascript. dans Linux Journal, Reuven M. Lerner présente un article[84] comment implémenter un serveur d'application réseau haute performance avec Node.js pouvant gérer 10 000 requêtes en simultanées.
Bien que node.js soit encore un peu jeune, Yammer, Bocoup, Proxlet et Yahoo sont des compagnies qui l'implémentent déjà en production[85].
Architecture des infrastructures Web
Implémentation des serveurs web
Quelques serveurs web "légers" (Open source) ont été développés pour contrer la problématique des 10k connexions simultanées. Ces serveurs web ont une architecture asynchrone, non bloquante:
- nginx[86]
- nginx (à prononcer en anglais « engine x ») a été développé par Igor Sysoev en 2002, pour les besoins d’un site russe à très fort trafic (rambler.ru[87]). Il a été connu, hors Russie, qu'à partir de 2006, après avoir été traduit du Russe par Aleksandar Lazic. Ses performances[88] en termes de répondant, de stabilité et de consommation mémoire, lui valent rapidement une certaine renommée et son utilisation de par le web ne cesse d’augmenter depuis. La dernière étude de Netcraft (mai 2011) sur les serveurs web les plus utilisés, place nginx en 4e position[89]. L'architecture logicielle asynchrone de Nginx lui permet de s’adapter à la fois aux petits serveurs et aux sites gérant un nombre important de requêtes. Nginx est très modulaire, il dispose d’un noyau minimal gérant les requêtes HTTP et tout le reste est fourni par des modules. Il fait également office de proxy HTTP inverse et de proxy pour le courrier électronique. Il est utilisé par WordPress.com, FastMail.FM, Yellow Pages.
- Lighttpd[90]
- Lighttpd (à prononcer en anglais « lighty »), développé en 2003 par un étudiant allemand Jan Kneschke, est l'un des serveurs ayant la plus faible trace mémoire et le plus faible usage du processeur, tout en étant très rapide pour servir les documents statiques comme dynamiques. Le module FastCGI est inclus par défaut, ce qui le rend très intéressant pour les langages comme PHP, Python ou Ruby. Lighttpd utilise un seul thread pour gérer des entrées/sorties non bloquantes. Il est d'ailleurs utilisé par de gros sites comme YouTube, SourceForge.net, ou le serveur d'image de Wikipédia. Il est en 7e position des serveurs web les plus utilisés d'après l'étude de Netcraft[89]. Il fait partie des logiciels fournis avec la distribution Fedora[91].
- Cherokee[92]
- Cherokee a été développé en 2001 par Alvaro López Ortega. Il est maintenant développé et maintenu par une communauté de contributeurs[93]. Cherokee est très rapide, flexible et rapide à configurer grâce à son interface d'administration graphique[94].
- Tornado[95]
- Tornado est la version open source du serveur web utilisé pour l'application FriendFeed et racheté par Facebook en 2009. Son architecture asynchrone-non bloquante et l'utilisation de
epoll(), lui permet de dépasser les 10k connexions simultanées, et de garder les connexions utilisateurs ouvertes pendant une longue période[96]. - G-WAN[97] (pour Global Wide Area Network)
- G-WAN n'est pas un serveur web open source mais un serveur d'application/web gratuit à sources fermées. G-WAN a été développé par la société TrustLeap en juillet 2009 , sa particularité est d'utiliser uniquement des scripts en ANSI-C pour servir les pages Web.
 Différence de performance entre NGINX, Lighttpd, Cherokee et Apache[note 13]
Différence de performance entre NGINX, Lighttpd, Cherokee et Apache[note 13]Architecture classique Client-Serveur
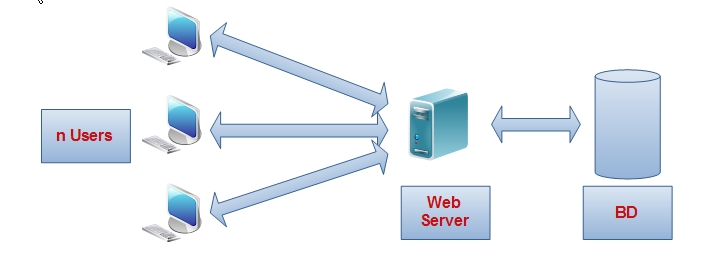
Le modèle d’architecture classique client-serveur et son extension, le modèle multi-tiers, sur lequel repose la plupart des architectures des applications web actuelles, montre des limites quant à la capacité d’absortion de la charge en termes de connexions simultanées, le C10K problem !
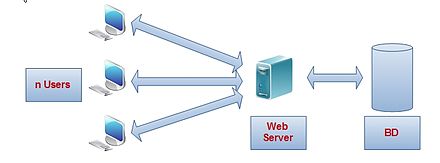 Architecture 3-tiers simple
Architecture 3-tiers simpleLe serveur web, qui est l'élément central dans l'architecture doit pouvoir gérer simultanément:
- la réception des requêtes
- la vérification des requêtes
- la répartition vers BdD, autres services…
- l'agrégation des résultats
- la gestion des erreurs
- la création de la page de retour
- l'envoi de la réponse au client.
Si aujourd'hui les limites physiques liées au matériel sont repoussées, comme le soulignait déjà Kegel dans son introduction[98], la problématique de la gestion des entrées-sorties et la gestion des ressources CPU et RAM reste le principal point de contention (en anglais : Bottleneck).
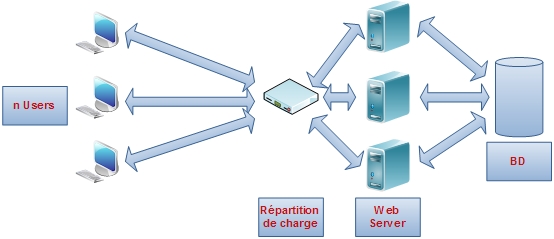
Scalabilité
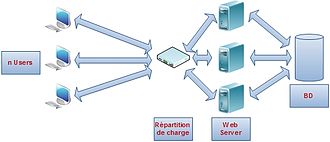 Répartition de la charge entre n serveurs web
Répartition de la charge entre n serveurs webUne autre approche du C10K problem consiste à « diluer » la charge entre plusieurs serveurs via un équipement de répartition de charge. Cela se nomme la scalabilité horizontale. Ainsi, même si un serveur web ne peut absorber qu'un certain nombre de connexions simultanées, en augmentant le nombre de serveurs, l'architecture de la plate-forme permettra d'obtenir le nombre de connexions simultanées désiré.
L'exemple de la figure ci-contre est relativement simple, le répartiteur de charge, qui est un élément réseau de la plate-forme, donc extrêmement rapide en termes de gestion de connexion, va répartir la charge entre les serveurs web via un algorithme prédéfini. De plus, si la charge venait à augmenter, celle-ci peut être prise en compte en rajoutant de nouveaux serveurs à l'infrastructure existante.
- Un bel exemple de mise en œuvre de la scalabilité est l'architecture de la plate-forme du site ebay présentée par Randy Shoup[99]. Cette architecture permettait de gérer jusqu'à 3 milliards de connexions par mois en 2006[100].
Notes et références
Notes
- dans C10k, C abrège le mot connexion et 10k fait référence au système métrique : 10 Kilos, c'est-à-dire 10 000.
- modèle thread-driven que l'on pourrait traduire en français par modèle piloté par les tâches.
- l'overhead désigne le temps passé par un système à ne rien faire d'autre que se gérer
- modèle event-driven que l'on pourrait traduire en français par modèle piloté par les événements.
- proposé par Matt Welsh de l'Université de Berkeley
- développé par Frank Dabek du Laboratoire d'Informatique du MIT
- proposé par Vivek S; Pai et Peter Druschel de l'Université Rice de Houston
- en anglais I/O pour Input/Ouput, On identifie par ce sigle les échanges d'informations entre le processeur et les périphériques qui lui sont associés tels que les accès disque ou les accès réseau.
- AIO signifie Asynchronous Input/Ouput, en français Entrée-sorties asynchrones
- l'overhead désigne le temps passé par un système à ne rien faire d'autre que se gérer.
- En français, plus de mémoire, signifie que tout l'espace mémoire RAM alloué a été utilisé.
- En français, Erreur de segmentation
- Ce diagramme a été effectué en prenant les données du benchmark effectué par S.Dmitrij, sur le site http://whisperdale.net/11-nginx-vs-cherokee-vs-apache-vs-lighttpd.html
Références
- D. Kegel 2006, Introduction
- Internet World Stats - Usage and population statistics
- M. Welsh et Al. 2000, p. 1
- C. Hu et Al. 1997, p. 1
- V. S. Pai et Al. 1999, p. 2
- H. C. Lauer et Al. 1979, p. 2
- R. Von Behren et Al. 2003, p. 1
- Base Definitions volume of IEEE Std 1003.1-2001, Section 3.393
- V. S. Pai et Al. 1999, p. 3
- M. Welsh et Al. 2000, p. 2
- J. C. Hu et Al. 1997, p. 5
- J. Gosling et Al. 2005, p. 553
- R. Von Behren et Al. 2003, p. 3
- A. Chandra et Al. 2000, p. 4
- F. Reiss et Al. 2001, p. 2
- V. S. Pai et Al. 1999, p. 3
- D. Liu et Al. 2009, p. 4
- A. Chandra et Al. 2000, p. 5
- M. Welsh et Al. 2000, p. 1
- M. Welsh et Al. 2000, p. 5
- F. Dabek et Al. 2002, p. 1
- V. S. Pai et Al. 1999
- T. Jones 2006
- D. Liu et Al. 2009
- D. Liu et Al. 2002, p. 2
- D. Liu et Al. 2009, p. 3
- S. Bhattacharya, IBM
- Gaurav Banga et Al. 1998, p. 2
- Hao-Ran Liu et Al. 2002, p. 4
- Waiting for Input or Output
- aide en ligne des commandes linux
- « Nouvelle alternative pour l'interface poll() » sur Site officiel Oracle
- D. Kegel 2000, Discussion
- « kqueue() » sur Site officiel FreeBSD
- « [http://lse.sourceforge.net/io/aio.html Kernel Asynchronous I/O (AIO) Support for Linux » sur Site Linux Scalability Effort Homepage
- « Linux-Kernel Archive: Re: [PATCH[RFC] Signal-per-fd for RT sig» sur http://lkml.indiana.edu
- « Native POSIX Thread Library » sur Site officiel lwn.net
- Threading
- « [http://people.freebsd.org/~jlemon/papers/kqueue.pdf BSDCon 2000 paper on kqueue()» sur http://people.freebsd.org
- «[http://www.volano.org/articles/volano-report-2003-05-30/ The Volano Report, May 2003 - volano.org» sur http://www.volano.org
- « LKML: Evgeniy Polyakov: [RFC 0/4 kevent: generic kernel event processing subsystem.» sur http://lkml.org
- « [http://marc.info/?l=freebsd-threads&m=115191979412894&w=2 'Strawman proposal: making libthr default thread implementation?' - MARC» sur http://marc.info
- Gaurav et Al. 1999, p. 4
- Gaurav Banga et Al. 1998, p. 4
- Abhishek Chandra et Al. 2000, p. 11
- Niels Provos et Al. et 2000 p. 3
- Louay Gammo et Al. 2004, p. 2
- J. Lemon, Introduction
- Linux Foundation 2009, Introduction
- A. Chandra 2004, Introduction
- SourceForge.net
- S. Bhatttacharya 2004, p. 1
- L. Torvalds 2001, p. 1
- P. Barila 2010, p. 1
- R. Von Behren 2003, Conclusion
- Demon Fenrus, p. 1
- V. Gite 2008, p. 1
- Liste linux kernel
- R. Von Behren 2004, p. 5
- R. Von Behren 2003, p. 2
- The LinuxThreads library
- U. Drepper, Introduction
- Bryan K. Ogawa
- R. Watson
- « Usenix Annual Technical Conference » sur Site officiel USENIX, the Advanced Computing Systems Association
- Nathan J. Williams
- SUN Documentation
- J. Neffenger 2003, p. 1
- Jesper Wilhelmsson 2006, p. 120
- « Mochiweb » sur Site officiel de github
- Dave Bryson 2009, p. 94
- Kenji Rikitake 2008, p. 2
- « [http://www.metabrew.com/article/a-million-user-comet-application-with-mochiweb-part-1 A Million-user Comet Application with Mochiweb » sur http://www.metabrew.com
- « [http://www.sics.se/~joe/apachevsyaws.html Apache vs. Yaws » sur http://www.sics.se
- « [http://sourceforge.net/projects/seda/ SEDA » sur http://sourceforge.net
- Matt Welsh et Al. 2001, p. 237
- Matt Welsh et Al. 2001, p. 231
- « [http://sourceforge.net/projects/seda/files/haboob/ Haboob » sur http://sourceforge.net
- Matt Welsh et Al. 2001, p. 239
- « [http://jcyclone.sourceforge.net JCyclone » sur site officiel JCyclone
- Stefan Tilkov et Al. 2010, p. 81
- Mixu's tech blog
- « [http://developer.yahoo.com/yui/theater/video.php?v=dahl-node Video: Ryan Dahl - Introduction to NodeJS (YUI Theater » sur http://developer.yahoo.com/
- « [http://delivery.acm.org/10.1145/1980000/1972995/11014.html At the forge: Node.JS sur http://delivery.acm.org/
- « [http://bostinnovation.com/2011/01/15/who-is-using-node-js-and-why-yammer-bocoup-proxlet-and-yahoo Who is Using Node.js And Why? Yammer, Bocoup, Proxlet and Yahoo » sur http://bostinnovation.com
- site officiel de nginx
- Site officiel de rambler
- W. Reese
- Site officiel de Netcraft
- Site officiel de lighttpd
- « Installation et configuration de lighttpd » sur Site officiel de Fedora
- Site officiel de Cherokee
- « Liste des contributeurs » sur Site officiel de Cherokee
- Carl Chenet, 2010
- Site officiel de Tornado
- T. Roden 2010, Chapitre 5
- Site officiel de G-WAN
- D. Kegel 2006, Introduction
- R. Shoup 2006, Introduction
- R. Shoup 2006, p. 2
Bibliographie
Bibliographie référencée
- (en) Dank Kegel, « c10k problem », dans sans (white paper), 2 septembre 2006 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Jonathan Lemon, « Kqueue: A generic and scalable event notification facility », dans Linux Foundation [texte intégral]
- (en) « The Proposed Linux kevent API », dans Linux Foundation, 19 novembre 2009 [texte intégral]
- (en) Abhishek Chandra et David Mosberger, « Scalability of Linux Event-Dispatch Mechanisms », dans Publication Hewlett Packard, 14 décembre 2000 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) « kernel Asynchronous I/O (AIO) Support for Linux », dans SourceForge.net [texte intégral]
- (en) Linus Torvalds, « kernel mechanism: Compound event wait », dans Liste Linux-kernel, 8 février 2001 [texte intégral]
- (en) Phil Barila, « I/O Completion Ports », dans MSDN Library (Microsoft), 12 janvier 2010 [texte intégral]
- (en) Suparna Bhatttacharya, Mike Tran, Sullivan et Chris Mason, « Linux AIO Performance and Robustness for Enterprise Workloads », dans Linux Symposium 2004, 2004, p. 1 [texte intégral]
- (en) James Gosling, Guy Joy, Steele et Gilad Bracha, « The Java™ Language Specification Third Edition », dans Sun Microsystems, 2005, p. 684 [texte intégral]
- (en) Rob Von Behren, Jeremy Condit et Eric Brewer, « Why Events Are A Bad Idea (for high-concurrency servers) », dans sans, 26 août 2003, p. 6 [texte intégral]
- (en) Rob Von Behren, Jeremy Condit, Feng Zhou, George C. Necula et Eric Brewer, « Scalable Threads for Internet Services », dans Computational Systems Seminar, SS 2004, 1er juillet 2004, p. 17 [texte intégral]
- (en) Ulrich Drepper, « Design of the New GNU Thread Library », dans sans, 13 avril 2004 [texte intégral]
- (en) Bryan K. Ogawa, « A programmer's guide to thread programming on FreeBSD », dans sans, 15 juillet 2003 [texte intégral]
- (en) Robert Watson, « making libthr default thread implementation? », dans Liste freebsd-threads, 3 juillet 2006 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Nathan J. Williams, « An Implementation of Scheduler Activations on the NetBSD Operating System », dans sans ('White paper') [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) « Threading », dans Documentation officiel SUN [texte intégral]
- (en) John Neffenger, « The Volano Report », dans Volano Blog, 30 mai 2003 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) « kHTTPd Linux HTTP Accelerator », dans sans (White paper) [texte intégral]
- (en) Vivek Gite, « What Is Tux Web Server and How do I Use it? », dans FAQ nixCraft, 30 avril 2008 [texte intégral]
- (en) Matt Welsh, Steven D. Gribble, Eric A. Brewer et David Culler, « A Design Framework for Highly Concurrent Systems », dans Technical Report No. UCB/CSD-00-1108, 2000, p. 14 [texte intégral]
- (en) Gaurav Banga et Jeffrey C. Mogul, « Scalable kernel performance for Internet servers under realistic loads », dans Proceedings of the USENIX Annual Technical Conference (NO 98), juin 1998, p. 12 [texte intégral]
- (en) Niels Provos et Chuck Lever, « Scalable Network I/O in Linux », dans CITI Technical Report 00-4, 2000, p. 11 [texte intégral]
- (en) Hugh C. Lauer et Roger M. Needham, « On the Duality of Operating Systems Structures », dans Proc. Second International Symposium on Operating Systems, octobre 1978, p. 19 [texte intégral]
- (en) Louay Gammo, Tim Brecht, Amol Shukla et David Pariag, « Comparing and Evaluating epoll, select, and poll Event Mechanisms », dans Proceedings of the Ottawa Linux Symposium, juillet 2004, p. 11 [texte intégral]
- (en) Dong Liu et Ralph Deters, « The Reverse C10K Problem for Server-side Mashups », dans Service-Oriented Computing Workshops, 2009, p. 12 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Fred Reiss et Elaine Cheong, « Debugger Support for Single-Threaded Event-Driven Applications », dans , mai 2001, p. 9 [texte intégral]
- (en) Vivek S. Pai, Peter Druschel et Willy Zwaenepoel, « Flash: An efficient and portable Web server », dans Proc. of the 1999 Annual Usenix Technical Conference, juin 1999, p. 13 [texte intégral]
- (en) Will Reese, « Nginx: the High-Performance Web Server and Reverse Proxy », dans Linux Journal, 1er septembre 2008, p. 26 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Ted Roden, « Building the Realtime User Experience », dans , juillet 2010, p. 79 [texte intégral]
- (en) Carl Chenet, « Cherokee, la nouvelle tribu des serveurs Web », dans Linux Magasine, mars 2010, p. 24 [texte intégral]
- (en) Randy Shoup et Dan Pritchett, « The Ebay Architecture », dans SD Forum 2006, 29 novembre 2006, p. 36 [texte intégral]
- (en) Jesper Wilhelmsson et Konstantinos Sagonas, « Efficient memory management for concurrent programs that use message passing », dans Science of Computer Programming, vol. 62, mai 2005, p. 120 [texte intégral, lien DOI]
- (en) Dave Bryson et Steve Vinoski, « Build Your Next Web Application with Erlang », dans IEEE Computer Society, vol. 13, juillet 2009, p. 94 (ISSN 1089-7801) [texte intégral, lien DOI]
- (en) Kenji RIKITAKE et Koji NAKAO, « Application Security of Erlang Concurrent System », dans SOSP '01 Proceedings of the eighteenth ACM symposium on Operating systems principles, 2001, p. 2 [texte intégral]
- (en) Matt Welsh, David Culler et Eric Brewer, « Application Security of Erlang Concurrent System », dans ACM SIGOPS Operating Systems Review, 5 décembre 2001, p. 231 (ISBN 1-58113-389-8) [texte intégral, lien DOI]
- (en) Stefan Tilkov et Steve Vinoski, « Node.js: Using JavaScript to Build High-Performance Network Programs », dans Internet Computing, IEEE, vol. 14, décembre 2010, p. 81 (ISSN 1089-7801) [texte intégral, lien DOI]
- (en) Nickolai Zeldovich, Alexander Yip, Frank Dabek, Robert T. Morris, David Mazières et Frans Kaashoek, « Multiprocessor Support for Event-Driven Programs », dans Technical Conference USENIX, 2003, p. 14 [texte intégral]
- (en) Frank Dabek, Nickolai Zeldovich, Frans Kaashoek, David Mazières† et Robert Morris, « Event-driven Programming for Robust Software », dans SIGOPS European Workshop, 2002, p. 4 [texte intégral]
- (en) Gaurav Banga, Jeffrey C. Mogul et Peter Druschel, « A Scalable and Explicit Event Delivery Mechanism for UNIX », dans Proceedings of the USENIX Annual Technical Conference, 1999, p. 4 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Hao-Ran Liu et Tien-Fu Chen, « A Scalable Event Dispatching Library for Linux Network Servers », dans , 2002, p. 24 [texte intégral]
- (en) Rob von Behren, Jeremy Condit, Feng Zhou, GeorgeC. Necula et Eric Brewer, « Capriccio: Scalable Threads for Internet Services », dans Proceedings of the 19th ACM Symposium on Operating Systems Principles, 2003, p. 15 [texte intégral]
- (en) James C. Hu, Irfan Pyarali et Douglas C. Schmidt, « Measuring the Impact of Event Dispatching and Concurrency Models on Web Server Performance Over High-spedd Networks », dans Proceedings of the 2 nd Global Internet Conference, IEEE, 1997, p. 12 [texte intégral]
- (en) Tim Jones, « Boost application performance using asynchronous I/O », dans IBM developerWorks, août 2006 [texte intégral]
- (en) Dank Kegel, « Microbenchmark comparing poll, kqueue, and /dev/poll », dans sans (white paper), 24 octobre 2000 [texte intégral]
Autres éléments bibliographiques
- (en) Felix Von Leitner, « Scalable Network Programming », dans sans (white paper), 16 octobre 2003 [texte intégral]
- (en) Matt Welsh, David Culler et Eric Brewer, « SEDA: An Architecture for WellConditioned, Scalable Internet Services », dans sans (white paper), 16 octobre 2003 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Matt Welsh, « An Architecture for Highly Concurrent,Well-Conditioned Internet Services », dans sans (white paper) [texte intégral]
- (en) Fabien Gaud, Sylvain Genevès, Renaud Lachaize, Baptiste Lepers, Fabien Mottet, Gilles Muller et Vivien Quéma, « Mely: Efficient Workstealing for Multicore Event-Driven Systems », dans Publication INRIA, 24 janvier 2010, p. 26 [texte intégral]
- (en) Holger Kälberer, « Threaded Architectures for Internet Servers », dans RBG-Seminar WS 2008/2009, 09 décembre 2008, p. 33 [texte intégral]
- Erreur dans la syntaxe du modèle Article(en) Ulrich Drepper, « The Need for Asynchronous, Zero-Copy Network I/O », dans sans (white paper), p. 14 [texte intégral]
Liens externes
- Internet World Stats. Consulté le 19 mai 2011
- Suparna Bhattacharya, IBM, « Linux Asynchronous I/O Design: Evolution & Challenges ». Consulté le 21 mai 2011
- Igor Sysoev, « Site officiel de nginx ». Consulté le 13 mai 2011
- Alvaro Lopez Ortega, « Site officiel de cherokee ». Consulté le 13 mai 2011
- Site officiel de rambler, Рамблер Интернет Холдинг. Consulté le 13 mai 2011
- Jan Kneschke, « Site officiel de lighttpd ». Consulté le 13 mai 2011
- FriendFeed, « Site officiel de tornadoweb », Facebook's open source technologies. Consulté le 13 mai 2011
- Site officiel de G-WAN, trustleap. Consulté le 13 mai 2011
- site officiel de la communauté fedora, Fedora. Consulté le 16 mai 2011
- site officiel de Netcraft. Consulté le 17 mai 2011
- site d'aide en ligne des commandes linux, Man Linux Magique. Consulté le 17 mai 2011
- Xavier Leroy, « The LinuxThreads library ». Consulté le 17 mai 2011
- Site officiel USENIX, the Advanced Computing Systems Association. Consulté le 17 mai 2011
- Site officiel Oracle, Oracle. Consulté le 17 mai 2011
- Site officiel FreeBSD, FreeBSD. Consulté le 19 mai 2011
- Site officiel lwn.net, Linux info from the source, Lwn.net. Consulté le 17 mai 2011
- Threading, Java Sun. Consulté le 17 mai 2011
- Liste linux-kernel. Consulté le 17 mai 2011
- Mixu's tech blog. Consulté le 17 mai 2011
- Secure source code hosting and collaborative development - GitHub. Consulté le 17 mai 2011
- Richard Jones, « Richard Jones », www.metabrew.com, 2008. Consulté le 17 mai 2011
- SICS, www.sics.se. Consulté le 17 mai 2011
- Yahoo! Developer Network. Consulté le 17 mai 2011
- Test Page for the Apache HTTP Server on Red Hat Enterprise Linux, Apache. Consulté le 17 mai 2011
- JCyclone. Consulté le 17 mai 2011
- Bostinnovation: Boston Innovation, Start-ups and Tech News Blog, bostinnovation.com. Consulté le 17 mai 2011
- SourceForge.net: Find, Create, and Publish Open Source software for free. Consulté le 17 mai 2011
- Site Linux Scalability Effort Homepage. Consulté le 20 mai 2011
- Mailing List Archives: Core Services: Indiana University. Consulté le 19 mai 2011
- FreeBSD Homepages. Consulté le 19 mai 2011
- VOLANO Blog - stats on Java technology since 1997 - volano.org. Consulté le 19 mai 2011
- LKML.ORG - the Linux Kernel Mailing List Archive. Consulté le 19 mai 2011
- MARC: Mailing list ARChives. Consulté le 19 mai 2011
- Waiting for Input or Output, www.gnu.org. Consulté le 20 mai 2011
Catégorie :- Sécurité du réseau informatique
Wikimedia Foundation. 2010.