- Virus de l'hépatite C
-
 Virus de l'hépatite C
Virus de l'hépatite C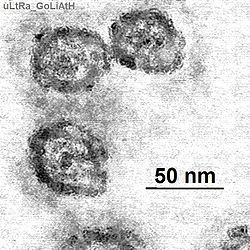
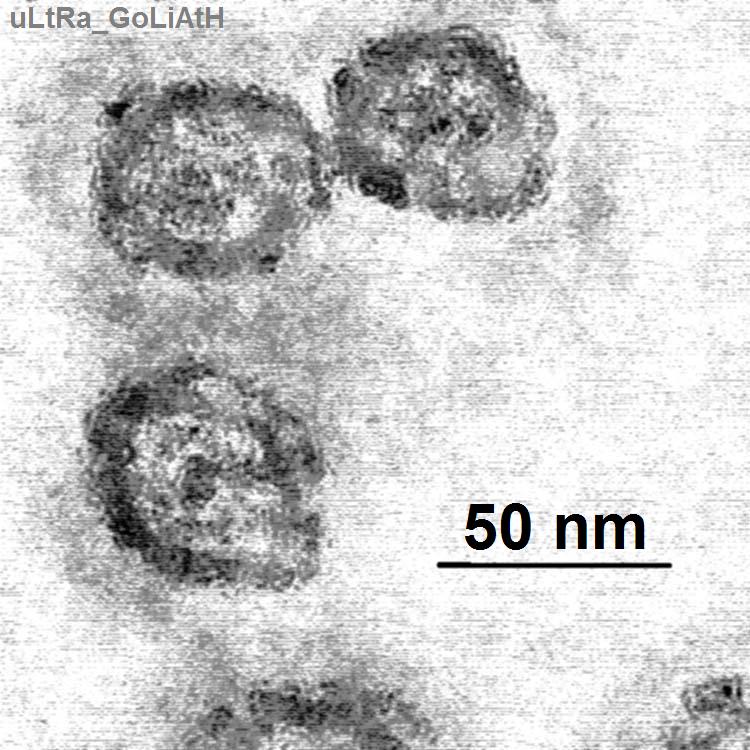
Légende Classification des virus Type Virus Groupe Groupe IV Famille Flaviviridae Genre Hepacivirus Espèce Virus de l'hépatite C Le virus de l'hépatite C est un petit virus enveloppé, d'environ 60 nm de diamètre, dont le génome est un ARN monocaténaire linéaire de polarité positive contenu dans une capside protéique icosaèdrique. Il présente une grande variabilité génétique : sept génotypes différents ont été identifiés. Sa prévalence en France et en Belgique est de 1 % ; elle monte jusqu'à plus de 10 % dans certaines régions d'Afrique (Égypte par exemple). Son mode de transmission est essentiellement parentéral (piqûre, écorchure, ...) et dans une moindre mesure sexuel.
Ses co-récepteurs connus sont des glycosaminoglycanes, SR-B1, CD81 et la claudine 1.
Il est le seul représentant du genre Hepacivirus, au sein de la famille des Flaviviridae qui compte deux autres genre les Pestivirus et les Flavivirus.
En 1999, l'hépatite C infectait environ 170 millions de personnes dans le monde[1].
Sommaire
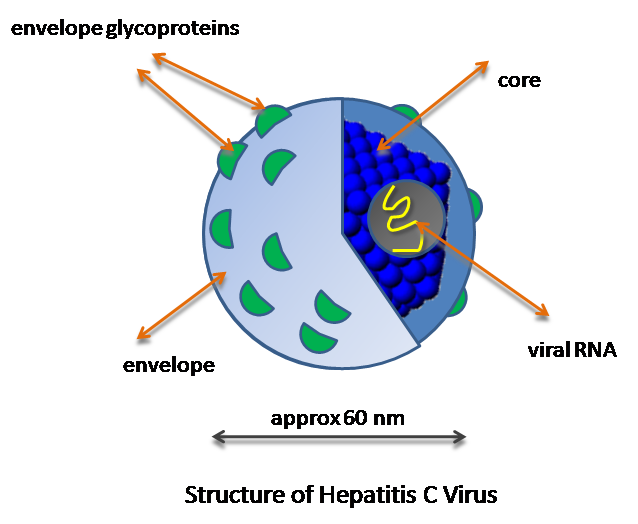
Structure
 Diagramme simplifiée de la structure du virus de l'hépatite C
Diagramme simplifiée de la structure du virus de l'hépatite C
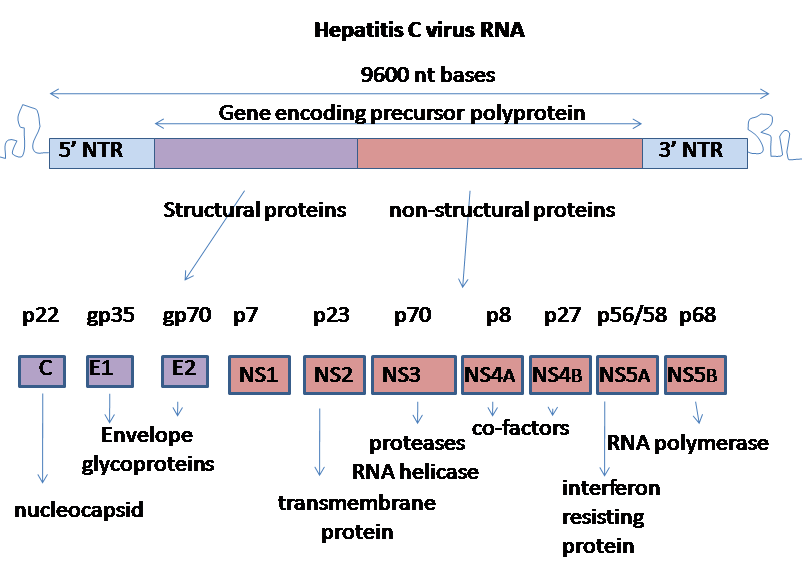
Génome
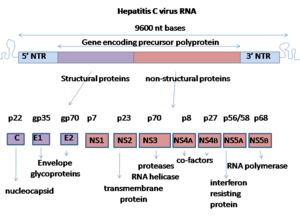
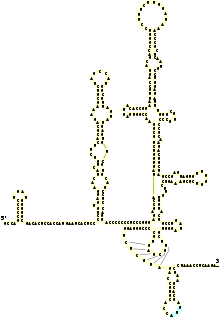
Le génome du virus de l'hépatite C est composé d'un ARN simple brin à polarité positive, long de 9600 nucléotides, qui code pour une polyprotéine unique d'environ 3000 acides aminés. Le génome du VHC se compose de trois parties. La région 5’ non codante, qui es constituée de 341 à 344 nucléotides, est structurée en quatre domaines tige boucle. C’est une région est très organisée et hautement conservée avec une similarité qui atteint au minimum 90% pour les souches de VHC entre elles. Cette region permet la fixation de la sous-unité 40S du ribosome au niveau de l’IRES (Internal Ribosome Entry Site) rendant ainsi possible l’initiation de la traduction (de manière coiffe indépendante), enfin la région 5’ NC porte le signal d’encapsidation nécessaire à la formation de la nucléocapside. La région 3’ non codante présente une longueur variable de 200 à 235 nt, elle est constituée (de 5’ en 3’) d’une région non traduite directement en aval de la protéine NS5B d’une longueur comprise entre 20 nt et 70 (de composition est variable en fonction des isolats mais fortement conservée de manière intra génotypique), d’une région polyuridylée de longueur variable (30 à 150 pb) puis de la région X comprenant 98 nucléotides et qui est hautement conservée. La région X et la région polyuridylée semble dans l’infectivité du VHC. Enfin l’ORF (Open Reading Frame) ou phase de lecture ouverte est de taille variable (9024 à 9111 nt) selon les isolats. Elle code pour une polyprotéine qui est clivée co et post-traductionnellement en dix protéines, en suivant la séquence suivante NH2-Capside-E1-E2-p7-NS2-NS3-NS4A-NS4B-NS5A- NS5B-COOH. Deux types de protéines sont alors produites, les protéines structurales et les protéines non structurales. Les protéines structurales comportent la Capside et les deux glycoprotéines d’enveloppe (E1 et E2). On trouve ensuite une viroporine la protéine p7 (Statut indéfini). Et les protéines non structurales qui assurent les fonctions enzymatiques utiles au cycle viral. On trouve alors NS2,qui est protéine hydrophobe attachée à la membrane cellulaire NS3, qui est une protéase virale NS4A, qui est une protéine trans-membranaire co-facteur de NS3, NS4B qui est une protéine trans-membranaire responsable du réseau membranaire, NS5A une phosphoprotéine virale, et enfin la polymérase virale NS5B.
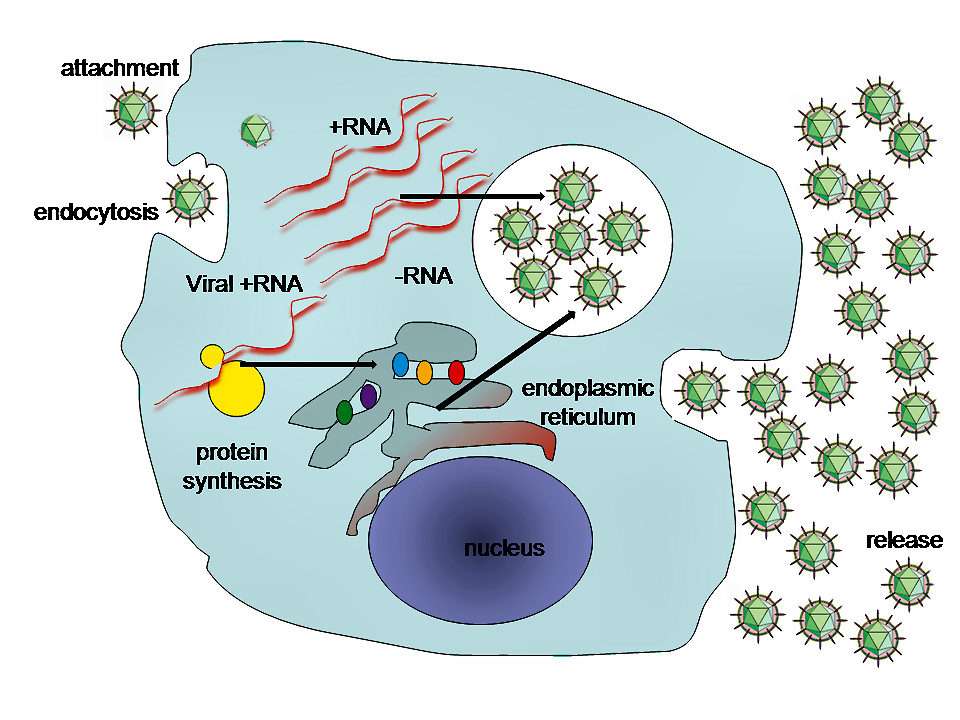
Réplication
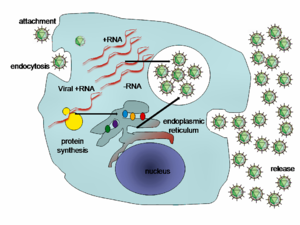 Diagramme simplifié du cycle de réplication du virus de l'hépatite C
Diagramme simplifié du cycle de réplication du virus de l'hépatite CLa particule infectieuse se lie aux récepteurs cellulaires via les glycoprotéines d'enveloppes E1 et E2. Différents récepteurs cellulaires impliqués dans cette reconnaissance ce sont , récepteur CD81, appartient à la famille des tétraspanines, SR-BI (Human Scavenger Receptor class B type 1) est une glycoprotéine exprimée principalement dans le foie, CLDN-1 est une protéine de la famille des claudines également fortement exprimée dans le foie elle interviendrait après les SR-BI et CD81. Les CLDN-6 et 9 pourraient également participer à l’entrée du VHC. Enfin les OCLDN et le récepteur à l’EGF jouerait un rôle lors du processus d’entrée du virus dans la cellule. Une fois la reconnaissance entre la particule virale et son récepteur établie, il y a fusion entre l’enveloppe virale et la membrane cellulaire à pH acide, ce qui induisant un changement de conformationnel de l’enveloppe virale, la décapsidation de la particule virale, et la libération de l’ARN positif du génome viral. L’ ARN (+) est libéré est traduit grâce à la machinerie cellulaire (ribosomes, protéines cellulaires) au niveau du réticulum endoplasmique (RE). Les protéines virales synthétisées alors sont nécessaires à la réplication du virus. Elles sont associées dans le complexe de réplication au niveau des membrane du RE à proximité des gouttelettes lipidiques. Ensuite l'ARN (+) sert de brin matriciel pour la synthèse de l'intermédiaire de réplication, l’ARN (-), permettant la synthèse d’un grand nombre de brins positifs. Enfin internalisation des brins positifs dans les futures particules virales composées des protéines de capside et de E1 et E2 puis bourgeonnent à partir du RE. Le relargage extracellulaire des particules virales s’opère ensuite grâce à des vésicules d’exocytose vers la membrane cellulaire.
Références
- Nature 446, 801-805 (12 April 2007)
Notes et références
- WHO. Hepatitis C—global prevalence (update). Wkly Epidemiol Rec 1999;49:421-428
Voir aussi
Articles connexes

Wikimedia Foundation. 2010.