- Test du khi-2
-
Test du χ²
 Pour la loi de probabilité, voir Loi du χ².
Pour la loi de probabilité, voir Loi du χ².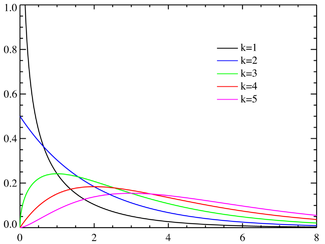 Densité du χ² en fonction du nombre de degrés de liberté
Densité du χ² en fonction du nombre de degrés de liberté
Le test du χ² (prononcer « khi-deux » ou « khi carré », qu'on écrit également à l'anglaise « chi-deux » ou « chi carré ») permet, partant d'une hypothèse et d'un risque supposé au départ, de rejeter l'hypothèse si la distance entre deux ensembles d'informations est jugée excessive.
Il est particulièrement utilisé comme test d'adéquation d'une loi de probabilité à un échantillon d'observations supposées indépendantes et de même loi de probabilité. Un test d'homogénéité concerne un problème voisin, la comparaison d'échantillons issus de populations différentes. De manière assez différente, un test d'indépendance porte sur des données qualitatives.
Son usage est très répandu notamment en génétique où il permet de déterminer, à un seuil donné, la validité d'une hypothèse.
Sommaire
- 1 Vulgarisation
- 2 Principe
- 3 Utilisations possibles
- 4 Remarque
- 5 Notes et références
- 6 Voir aussi
Vulgarisation
En sciences, on essaie souvent de représenter un phénomène par une formule mathématique la plus simple possible — à condition bien sûr que l'on ait des paramètres chiffrés mesurables. On appelle cette formule « loi théorique ». Ceci permet de comparer les phénomènes, de prédire leur tendance… Dès lors se pose une question fondamentale : la formule que j'utilise représente-t-elle bien la réalité ?
Pour cela, on compare les mesures faites à la loi théorique.
Par exemple, on veut représenter la stature des personnes de sexe masculin, et on formule la loi simple : « la masse est égale au nombre de centimètres de taille au-dessus de un mètre » (par exemple, une personne de 1,60 m pèse 60 kg). Cette loi correspond-elle à la réalité ? Pour cela, on prend plusieurs personnes, on les pèse et on les mesure, et on regarde si cela correspond.
Mais on n'obtient jamais une adéquation parfaite. Il faut donc trouver un critère quantitatif, qui permette de dire si la loi convient bien, moyennement bien, assez mal ou pas du tout à la réalité.
On peut, par exemple, pour une taille donnée, faire la différence entre la masse mesurée et la masse donnée par la loi théorique, et faire la somme des différences pour toutes les personnes. Cependant, dans certains cas, la différence sera positive, dans d'autres cas elle sera négative, et deux écarts pourront se compenser. Pour éviter ce problème, on peut faire la somme des valeurs absolues des différences entre masse mesurée et masse théorique. On préfère généralement minimiser la somme des carrés des différences, qui présente les mêmes avantages tandis qu'elle se manipule plus facilement, ce qui conduit à la méthode des moindres carrés au début du XIXe siècle.
Le test du χ² a pour origine un problème essentiellement différent, la comparaison de données, non à une loi physique, mais à une loi de probabilité. En 1900, un mathématicien britannique, Karl Pearson, eut l'idée de diviser ces carrés par les valeurs attendues. Ainsi, une grande différence entre la loi théorique et la mesure réelle a plus d'importance que plusieurs petites différences. Cela a donné le test du χ² qui est un cas particulier de test statistique d'hypothèse. Celui-ci a été ensuite étendu à d'autres problèmes.
Dans certains problèmes, on a des valeurs chiffrées discrètes et non pas continues. Par exemple, si l'on regarde le nombre d'enfants par famille, on a un nombre entier pour chaque famille. Dans ce cas-là, on regarde le nombre d'événements ayant la même valeur discrète, et c'est la fréquence d'apparition d'une valeur qui constitue la mesure (lorsque le nombre de valeurs possibles est élevé, on est généralement amené à regrouper plusieurs valeurs dans une même classe, comme pour les valeurs continues, de manière à satisfaire la règle indiquée ci-dessous).
Dans d'autres problèmes, on se contente de mettre les événements dans une catégorie, appelée « classe ». On se retrouve dans le même cas que pour les valeurs discrètes : on regarde le nombre d'événements dans chaque classe, et c'est la fréquence des occurrences d'une classe qui constitue la mesure.
Un des problèmes importants est de savoir combien de mesures au minimum il faut faire pour bien comparer la loi théorique à la réalité. Une règle empirique couramment utilisée consiste à dire que chaque classe doit contenir au moins cinq événements. Si l'on est en dessous, cela signifie qu'il faut regrouper les classes, à condition que leur nombre initial et le nombre total d'observations soient suffisants. Si la classe contient entre 5 à 10 événements, alors nous appliquerons la correction de Yates[réf. nécessaire] afin de gommer ou de neutraliser la différence d'effectifs.
Principe
À la base d'un test statistique il y a la formulation d'une hypothèse appelée hypothèse zéro. Dans le cas présent, elle suppose que toutes les données considérées dérivent de la même loi de probabilité.
Ces données ayant été réparties en classes, il faut
- déterminer le nombre de degrés de liberté du problème à partir du nombre de classes ;
- se donner a priori un risque de se tromper (la valeur 5 % est souvent choisie mais il s'agit plus souvent d'une coutume que du résultat d'une réflexion) ;
- à l'aide d'une table de χ², déduire en tenant compte du nombre de degrés de liberté la distance critique qui a une probabilité de dépassement égale à ce risque ;
- calculer algébriquement la distance entre les ensembles d'informations à comparer.
Si cette distance est supérieure à la distance critique, on conclut que le résultat n'est pas dû seulement aux fluctuations d'échantillonnage et que l'hypothèse nulle doit donc être rejetée. Le risque choisi au départ est celui de donner une réponse fausse lorsque les fluctuations d'échantillonnage sont seules en cause. Le rejet est évidemment une réponse négative dans les tests d'adéquation et d'homogénéité mais il apporte une information positive dans les tests d'indépendance. Pour ceux-ci, il montre le caractère significatif de la différence, ce qui est intéressant en particulier dans les tests de traitement d'une maladie.
Utilisations possibles
Test du χ² d'adéquation
Généralités
Il s'agit de juger de l'adéquation entre une série de données statistiques et une loi de probabilité définie a priori (comme une loi uniforme ou une loi de Poisson par exemple).
Exemple concret : Soit un nombre donné de cultures cellulaires rigoureusement identiques. Chacune comporte un certain nombre de colonies. Toutes les cultures sont en fait des cultures de cellules cancéreuses et on cherche à déterminer dans quelle mesure l'action d'un produit empêche leur division. Précisément on veut savoir si le nombre de colonies dont la croissance sera interrompue par le produit suit une loi de Poisson de paramètre λ.
Après avoir exposé les cellules au produit, on obtient des résultats précis: X1 colonies de la première culture ont subi l'influence du produit, X2 pour la deuxième culture... Xn pour la n-ième culture. On effectuera un test du χ² sur ces valeurs pour juger l'hypothèse selon laquelle leur distribution suit une loi de Poisson.
Description
La statistique mathématique a pour but la description d'une population dont on ne connaît qu'un nombre relativement petit d'individus. Pour cela on associe une loi de probabilité à cette population. Mis à part certains problèmes de physique fondamentale et, à l'opposé, certains problèmes élémentaires (jeux de hasard équitables, par exemple), cette loi de probabilité est en toute rigueur inconnue. L'hypothèse selon laquelle la population suit une loi de probabilité donnée a priori peut être testée par la méthode décrite ci-après.
Lorsqu'on découvre un élément de la population, celui-ci est considéré comme une réalisation d'une variable aléatoire correspondant à la loi de probabilité choisie. Plus généralement, un ensemble d'éléments est une réalisation de ce qu'on appelle un échantillon aléatoire.
Les valeurs connues doivent être réparties entre diverses classes. En supposant l'indépendance des
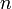 valeurs considérées regroupées dans
valeurs considérées regroupées dans 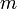 classes, l'effectif de chaque classe
classes, l'effectif de chaque classe 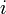 est une variable aléatoire définie par la loi multinomiale. La loi de probabilité testée permet de définir également pour chaque classe la probabilité
est une variable aléatoire définie par la loi multinomiale. La loi de probabilité testée permet de définir également pour chaque classe la probabilité 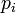 .
.Les effectifs mesurés étant
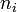 , la quantité
, la quantité 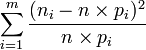 représente, d'une certaine manière, la distance entre les données et la loi de probabilité supposée. C'est une réalisation d'une variable aléatoire qui dérive d'une loi du χ² à (m-1) degrés de liberté. La probabilité donnée par les tables de dépassement de la valeur calculée donne alors une indication sur le réalisme de l'hypothèse.
représente, d'une certaine manière, la distance entre les données et la loi de probabilité supposée. C'est une réalisation d'une variable aléatoire qui dérive d'une loi du χ² à (m-1) degrés de liberté. La probabilité donnée par les tables de dépassement de la valeur calculée donne alors une indication sur le réalisme de l'hypothèse.Il est peu vraisemblable que les paramètres qui caractérisent la loi de probabilité (moyenne, variance, ...) soient connus au moment du test. Les données sont donc utilisées pour estimer ceux-ci, ce qui facilite l'adéquation. Il faut alors diminuer le nombre de degrés de liberté du nombre de paramètres estimé.
Choix des classes
Celles-ci doivent être assez nombreuses pour ne pas perdre trop d'information mais, à l'inverse, pour satisfaire les conditions requises par la méthode, elles ne doivent pas être trop petites. En théorie, il faudrait que les effectifs soient infinis pour que la loi normale s'applique mais il est généralement admis qu'il faut 5 éléments dans chaque classe. Cette règle a été très discutée et celle qui semble recueillir le plus de suffrages est due à Cochran : 80 % des classes doivent satisfaire la règle des cinq éléments tandis que les autres doivent être non vides.
Le critère porte sur les
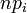 déduits de la distribution de référence et non sur les des données analysées. Il est souvent satisfait sans difficulté car, à la différence de la construction d'un histogramme, il est possible de jouer sur la largeur des classes.
déduits de la distribution de référence et non sur les des données analysées. Il est souvent satisfait sans difficulté car, à la différence de la construction d'un histogramme, il est possible de jouer sur la largeur des classes.Test du χ² d'homogénéité
Il s'agit alors de se demander si deux listes de nombres de même effectif peuvent dériver de la même loi de probabilité. La méthode précédente s'applique en remplaçant le terme
relatif à la loi de probabilité par 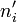 relatif à la seconde liste et le
relatif à la seconde liste et le 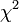 est donné par
est donné par 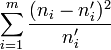 .
.Cette notation s'inspire de celle utilisée pour le test d'adéquation, elle-même déduite de la notation classique de la loi multinomiale. Ici, comme dans le test d'indépendance, la notion de probabilité n'apparaît plus de manière explicite. De nombreux utilisateurs préfèrent donc adopter la notation qui utilise les symboles
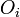 pour les valeurs observées et
pour les valeurs observées et 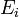 pour les valeurs espérées, ce qui conduit à l'expression
pour les valeurs espérées, ce qui conduit à l'expression 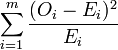 .
.Test du χ² d'indépendance
Exemple
Problème
Lorsqu'on considère plusieurs populations auxquelles on associe le même ensemble de critères qualitatifs, l'hypothèse à tester est l'indépendance de ces populations.
Pour ce problème, il est commode de partir d'un exemple concret, comme la relation entre le revenu et le sexe d'un individu. La distribution du revenu des hommes est-elle différente de celui des femmes ? Une représentation sur une table de contingence des occurrences des variables permet d'illustrer la question.
Salaire 1000-2000 2000-3000 3000-4000 4000-5000 Total Hommes 50 70 110 60 290 Femmes 60 75 100 50 285 Total 110 145 210 110 575 Dans cet exemple fictif on remarque que les femmes sont plus nombreuses dans les classes à bas salaires et moins nombreuses dans celles à haut salaire que les hommes. Cette différence (c’est-à-dire cette dépendance entre les variables) est-elle statistiquement significative ? Le test du χ² aide à répondre à cette question.
Préparation
On peut constater que l'effectif total de chaque colonne correspond à 4-1 = 3 variables indépendantes tandis que celui de chaque ligne correspond à 2-1 = 1 variable indépendante, ce qui conduit à 3 x 1 = 3 degrés de liberté.
Si on se donne un risque de se tromper égal à 5 %, la valeur critique trouvée dans les tables est 7,18.
Hypothèse
Il faut bâtir l'hypothèse nulle qui, dans ce cas, ne dépend ni d'une loi de probabilité, ni d'une distribution de référence. On suppose qu'il n'y a pas de différence entre les salaires des hommes et ceux des femmes, les proportions des différentes catégories de salaires étant donc conservées d'une ligne à l'autre.
Les données correspondantes sont obtenues en remplaçant la valeur de chaque cellule par le produit du total de sa ligne par le total de sa colonne divisé par le total général. On vérifie que les totaux sont inchangés.
Hypothèse 1000-2000 2000-3000 3000-4000 4000-5000 Total Hommes 55,5 73,1 105,9 55,5 290,0 Femmes 54,5 71,9 104,1 54,5 285,0 Total 110,0 145,0 210,0 110,0 575,0 Calcul
Le calcul du χ² des données s'effectue en remplaçant le terme relatif à chaque cellule par la quantité
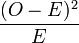 indiquée pour le test d'homogénéité et calculée à partir des deux tableaux précédents.
indiquée pour le test d'homogénéité et calculée à partir des deux tableaux précédents.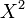
1000-2000 2000-3000 3000-4000 4000-5000 Total Hommes 0,54 0,13 0,16 0,37 1,20 Femmes 0,55 0,14 0,16 0,38 1,22 Total 1,09 0,27 0,32 0,74 2,42 Conclusion
La distance calculée (2,42) étant inférieure à la distance critique (7,18), il n'y a pas lieu de mettre en cause l'égalité des salaires, avec un risque de se tromper égal à 5%.
Il convient de rappeler que ce résultat repose sur des données choisies arbitrairement qui ont... peu de chance de représenter une réalité quelconque. D'autre part, si on disposait d'un échantillon 10 fois plus grand sans modification de la répartition de population, le χ² serait multiplié par 10, soit (24,2) et on pourrait rejeter l'hypothèse d'égalité avec moins de 5% de risque de se tromper.
De manière plus profonde, les classes choisies, à la différence de ce qui se passait dans les tests d'adéquation et d'homogénéité, bien que présentant ici un aspect numérique, pourraient fort bien être associées à des notions qualitatives sans que le raisonnement soit modifié.
Test utilisé
Le test utilisé, le Chi-carré de Pearson, s'intéresse à la différence entre la valeur observée Oij (ou valeur empirique) et la valeur attendue s'il y avait indépendance Eij; (ou valeur théorique).
avec
- Oij la valeur observée
- Eij la valeur attendue sous l'hypothèse d'indépendance.
On a :
où
et
Formulation du test
H0 :
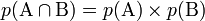 : les variables sont indépendantes (Hypothèse nulle).
: les variables sont indépendantes (Hypothèse nulle).H1 :
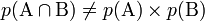 : les variables ne sont pas indépendantes, l'écart entre valeur observée et attendue n'est pas dû au hasard).
: les variables ne sont pas indépendantes, l'écart entre valeur observée et attendue n'est pas dû au hasard).Distribution du test
Cette statistique suit asymptotiquement une Loi du χ² à (I-1)(J-1) degrés de liberté, avec I le nombre de modalités de la première variable et J les nombre de modalités de la seconde variable.
Conditions du test
Plusieurs auteurs proposent des critères pour savoir si un test est valide, voir par exemple [pdf] The Power of Categoriel Goodness-Of-Fit Test Statistics p. 19 (p. 11 du ch. 2), Michael C. Steele. On utilise en général le critère de Cochran de 1954 selon lequel toutes les classes i, j doivent avoir une valeur théorique non nulle (E i, j ≥ 1), et que 80 % des classes doivent avoir une valeur théorique supérieure ou égal à 5 :
- E i,j ≥ 5
Lorsque le nombre de classes est petit, cela revient à dire que toutes les classes doivent contenir un effectif théorique supérieur ou égal à 5.
D'autres valeurs ont été proposées pour l'effectif théorique minimal : 5 ou 10 pour tous (Cochran, 1952), 10 (Cramér, 1946) ou 20 (Kendall, 1952). Dans tous les cas, ces valeurs sont arbitraires.
Certains auteurs ont proposé des critères basés sur des simulations, par exemple :
- effectif théorique supérieur à 5r/k pour chaque classe, où r est le nombre de classes ayant un effectif supérieur ou égal à 5 et k est le nombre de catégories (Yarnold, 1970) ;
- N²/k ≥ 10, où N est l'effectif total et k est toujours le nombre de catégories (Koehler et Larntz, 1980). Pour voir recommedations plus récentes on peut regarder, par exemple, P. Greenwood and M. Nikulin "A Guide to Chi-Squared Testing", (1996), John Wiley and Sons.
Tests apparentés
Il existe un test asymptotique très semblable, le test du rapport de vraisemblance (likelihood ratio test), ainsi qu'un test exact, le test de Fisher.
Justification
Le développement des méthodes bayésiennes - seules utilisables lorsqu'on n'a que peu de données sous la main - a dégagé un test de vraisemblance nommé le psi-test, dont Myron Tribus fait remarquer qu'il devient asymptotiquement identique au χ² à mesure que le nombre de données augmente[1].
Indépendance
Soient A et B les deux variables dont on souhaite tester l'indépendance.
Pour rappel, si A et B sont indépendantes on a la relation suivante :
ou pour la fonction de densité conjointe :
Soit ici
Estimation des valeurs attendues (théoriques)
Que vaut p(A=i ) ?
À partir de la table de contingence, on prendra simplement la somme de toutes les valeurs où A = 1, soit, dans notre notation
- O1+
Ainsi
Distribution du test
Pour la preuve que le test suit une loi Chi-carré, on en donnera ici que quelques « pistes ».
Si on suppose que chaque xij suit une loi de Poisson, on peut montrer que les valeurs standardisées
suivent asymptotiquement une loi normale. Alors
suit asymptotiquement une loi Chi-carré à IJ-1 degrés de liberté
Quant aux degrés de libertés, comme on doit estimer les
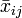 , on perd (I-1)+(J-1) degrés de liberté (et non pas I+J car
, on perd (I-1)+(J-1) degrés de liberté (et non pas I+J car 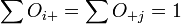 : le dernier paramètre se déduit des autres). On a alors au final
: le dernier paramètre se déduit des autres). On a alors au final- IJ-1-(I-1)-(J-1) = I(J-1)-(J-1) = (I-1)×(J-1)
Remarque
Les phénomènes quantifiables au sein d'une population sont soumis à des fluctuations statistiques. Considérons par exemple le taux de chômage dans un état donné, ou bien le taux de croissance.
D'une année sur l'autre, des variations dans ces taux sont systématiquement enregistrées (baisse ou hausse) pour autant elles ne signifient pas en elle-même, contrairement à une croyance trop répandue, que la variable considérée (taux de croissance ou de chômage) a bel et bien changé (rigoureusement qu'elle a changé de loi, c’est-à-dire que des procédés mis en place sont venus influencer sa distribution). Lorsque l'on considère une variable, il faut distinguer l'impact causal de la fluctuation statistique aléatoire. Ainsi, une baisse du taux de chômage de 2% d'une année à l'autre peut très bien n'être imputable qu'au caractère aléatoire de la variable « taux de chômage » et ne rien signifier sur le plan causal. Cette baisse ne signifie pas d'elle-même que des mesures efficaces ont influencé la loi de distribution du chômage. Seuls les tests statistiques sont connus actuellement pour faire foi et déterminer (à un seuil donné) si cette variation est le fruit du hasard ou non. À cet égard les tests du χ² sont exceptionnellement utiles.
Notes et références
- ↑ Myron Tribus, Décisions rationnelles dans l'incertain, Traduction française de Jacques Pézier, Masson, 1974
Voir aussi
Articles connexes
Liens externes
- Valeurs tabulées du χ²
- Document d'introduction au test du χ² (format PDF)
- Calculateur en ligne de χ²
 Portail des probabilités et des statistiques
Portail des probabilités et des statistiques
Catégories : Test statistique | Méthode d'analyse

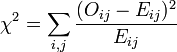
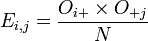
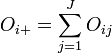
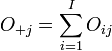
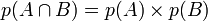
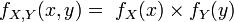
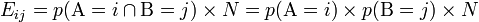
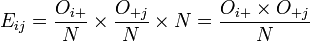
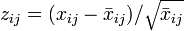
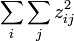
Wikimedia Foundation. 2010.