- Skip liste
-
Skip-list
Une Skip-list (liste à enjambements) est une structure de données probabiliste, à base de listes chaînées parallèles. La plupart de ses opérations s'effectuent en O(log n)[1] avec une grande probabilité.
Sommaire
Description
Une skip-list se présente comme une amélioration d'une liste chaînée triée. Elle contient des pointeurs supplémentaires vers l'avant, ajoutés de façon aléatoire, de sorte que la recherche dans la liste puisse "sauter" (skip) de nombreux éléments.
La skip-list est organisée en couches. La couche la plus basse est simplement une liste chaînée standard. Chaque couche supérieure est une "voie rapide" pour parcourir les couches inférieures. Un élément présent sur la couche i a une probabilité fixée p de faire partie de la couche i+1. En moyenne, chaque élément apparaît dans 1/(1-p) listes, et l'élément le plus haut (souvent un élément factice[2] plus petit que tous les autres) apparaît dans O(log1/p n) couches.
1 1-----4---6 1---3-4---6-----9 1-2-3-4-5-6-7-8-9-10
Opération de recherche
La recherche commence par le plus petit élément, sur la couche la plus haute. Pour chaque couche visitée, on parcourt les chaînons jusqu'à atteindre le dernier élément inférieur ou égal à l'élément recherché. L'espérance du nombre de pas dans chaque couche est 1/p. Le coût total de la recherche est en
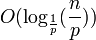 ; ce qui revient à O(log(n)) si l'on considère p comme fixé. En jouant sur la valeur de ce paramètre p, on obtient un compromis entre temps de recherche et espace mémoire consommé.
; ce qui revient à O(log(n)) si l'on considère p comme fixé. En jouant sur la valeur de ce paramètre p, on obtient un compromis entre temps de recherche et espace mémoire consommé.Autres opérations
L'insertion et la suppression s'implémentent comme dans une liste chaînée, sauf que les éléments "hauts"[3] doivent être insérés et supprimés dans plusieurs couches.
Performances
De par sa nature probabiliste, cette structure de données ne donne pas les mêmes garanties sur les pires cas que, par exemple, les arbres équilibrés. En effet, il est très peu probable mais néanmoins possible que l'agencement aléatoire ait pu produire une structure très déséquilibrée[4].
En fait, ces listes fonctionnent très bien en pratique, et sont réputées plus faciles à implémenter que leur équivalent déterministe à base de rééquilibrage d'arbres.
Un bémol cependant: dans les implémentations réelles, on a mesuré que leurs performances en temps et en espace sont inférieures à celles des B-trees. Cela est dû à des problématiques telles que la proximité des données dans les mémoires cache.
Histoire
Les skip-lists ont été inventées par William Pugh en 1990. Il explique leur fonctionnement dans Skip lists: a probabilistic alternative to balanced trees in Communications of the ACM, June 1990, 33(6) 668-676.
- ↑ n est le nombre d'éléments contenus dans la liste.
- ↑ cet élément factice est physiquement présent en mémoire mais ne fait pas partie fonctionnellement de la liste, dans la mesure où l'utilisateur ne l'y a pas inséré et ne désire pas le consulter
- ↑ un élément haut est un élément présent dans plusieurs couches (voir la figure); ce n'est pas forcément un grand élément.
- ↑ par exemple, si les couches supérieures ne contiennent que des éléments de la première moitié de la liste, alors la recherche d'un grand élément est catastrophique.
Catégorie : Structure de données
Wikimedia Foundation. 2010.