- Rétropropagation
-
Rétropropagation du gradient
La technique de rétropropagation du gradient (Backpropagation en anglais) est une méthode qui permet de calculer le gradient de l'erreur pour chaque neurone du réseau, de la dernière couche vers la première. De façon abusive, on appelle souvent technique de rétropropagation du gradient l'algorithme classique de correction des erreurs basé sur le calcul du gradient grâce à la rétropropagation et c'est cette méthode qui est présentée ici. En vérité, la correction des erreurs peut se faire selon d'autres méthodes, en particulier le calcul de la dérivée seconde. Cette technique consiste à corriger les erreurs selon l'importance des éléments qui ont justement participé à la réalisation de ces erreurs. Dans le cas des réseaux de neurones, les poids synaptiques qui contribuent à engendrer une erreur importante se verront modifiés de manière plus significative que les poids qui ont engendré une erreur marginale.
Ce principe fonde les méthodes de type descente de gradient, qui sont efficacement utilisées dans des réseaux de neurones multicouches comme les perceptrons multicouches (MLP pour « multi-layers perceptrons »). Les descentes de gradient ont pour but de converger de manière itérative vers une configuration optimisée des poids synaptiques. Cet état peut être un minimum local de la fonction à optimiser et idéalement, un minimum global de cette fonction (dite fonction de coût).
Normalement, la fonction de coût est non-linéaire au regard des poids synaptiques. Elle dispose également d'une borne inférieure et moyennant quelques précautions lors de l'apprentissage, les procédures d'optimisation finissent par aboutir à une configuration stable au sein du réseau de neurones.
Sommaire
Historique
Les méthodes de rétropropagation du gradient firent l'objet de communications dès 1975 (Werbos), puis 1985 (Parker et Cun), mais ce sont les travaux de Rumelhart, Hinton & Williams en 1986 qui suscitèrent le véritable début de l'engouement pour cette méthode[1]
Utilisation au sein d'un apprentissage supervisé
Dans le cas d'un apprentissage supervisé, des données sont présentées à l'entrée du réseau de neurones et celui-ci produit des sorties. La valeur des sorties dépend des paramètres liés à la structure du réseau de neurones : connectique entre neurones, fonctions d'agrégation et d'activation ainsi que les poids synaptiques.
Les différences entre ces sorties et les sorties désirées forment des erreurs qui sont corrigées via la rétropropagation, les poids du réseau de neurones sont alors changés. La manière de quantifier cette erreur peut varier selon le type d'apprentissage à effectuer. En appliquant cette étape plusieurs fois, l'erreur tend à diminuer et le réseau offre une meilleure prédiction. Il se peut toutefois qu'il ne parvienne pas à échapper à un minimum local, c'est pourquoi on ajoute en général un terme d'inertie (momentum) à la formule de la rétropropagation pour aider la descente de gradient à sortir de ces minimums locaux.
Algorithme
Les poids dans le réseau de neurones sont au préalable initialisés avec des valeurs aléatoires(val a). On considère ensuite un ensemble de données qui vont servir à l'apprentissage. Chaque échantillon possède ses valeurs cibles qui sont celles que le réseau de neurones doit à terme prédire lorsque on lui présente le même échantillon. L'algorithme se présente comme ceci :
- Soit un échantillon
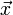 que l'on met à l'entrée du réseau de neurones et la sortie recherchée pour cet échantillon
que l'on met à l'entrée du réseau de neurones et la sortie recherchée pour cet échantillon 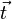
- On propage le signal en avant dans les couches du réseau de neurones :
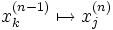
- La propagation vers l'avant se calcule à l'aide de la fonction d'activation g, de la fonction d'agrégation h (souvent un produit scalaire entre les poids et les entrées du neurone) et des poids synaptiques
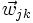 entre le neurone
entre le neurone 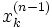 et le neurone
et le neurone 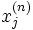 . Attention au passage à cette notation qui est inversée, indique bien un poids de k vers j.
. Attention au passage à cette notation qui est inversée, indique bien un poids de k vers j.
- Lorsque la propagation vers l'avant est terminée, on obtient à la sortie le résultat
- On calcule alors l'erreur entre la sortie donnée par le réseau et le vecteur désiré à la sortie pour cet échantillon. Pour chaque neurone i dans la couche de sortie, on calcule :
- On propage l'erreur vers l'arrière
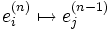 grâce à la formule suivante :
grâce à la formule suivante :
note:
![e_j^{(n)} = \sum_i [t_i - y_i] \frac{\partial y_i}{\partial h_j^{(n)}}](/pictures/frwiki/54/6e592d486e0323d04a0d11bd05a7c01b.png)
- On met à jour les poids dans toutes les couches :
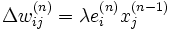 où λ représente le taux d'apprentissage (de faible magnitude et inférieur à 1.0)
où λ représente le taux d'apprentissage (de faible magnitude et inférieur à 1.0)
Implémentation
L'algorithme présenté ici est de type « online », c'est à dit que l'on met à jour les poids pour chaque échantillon d'apprentissage présenté dans le réseau de neurones. Une autre méthode est dite en « batch », c'est-à-dire que l'on calcule d'abord les erreurs pour tous les échantillons sans mettre à jour les poids (on additionne les erreurs) et lorsque l'ensemble des données est passé une fois dans le réseau, on applique la rétropropagation en utilisant l'erreur totale. Cette façon de faire est préférée pour des raisons de rapidité et de convergence.
L'algorithme est itératif et la correction s'applique autant de fois que nécessaire pour obtenir une bonne prédiction. Il faut cependant veiller aux problèmes de surapprentissage liés à un mauvais dimensionnement du réseau ou un apprentissage trop poussé.
Ajout d'inertie
Pour éviter les problèmes liés à une stabilisation dans un minimum local, on ajoute un terme d'inertie (momentum). Celui-ci permet de sortir des minimums locaux dans la mesure du possible et de poursuivre la descente de la fonction d'erreur. À chaque itération, le changement de poids conserve les informations des changements précédents. Cet effet de mémoire permet d'éviter les oscillations et accélère l'optimisation du réseau. Par rapport à la formule de modification des poids présentée auparavant, le changement des poids avec inertie au temps t se traduit par :
avec α un paramètre compris entre 0 et 1.0.
Notes et références
- ↑ Patrick van den Smagt, An Introduction to Neural Networks, 1996, page 33.
Catégories : Apprentissage automatique | Algorithme - Soit un échantillon
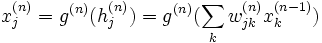
![e_i^{sortie} = g'(h_i^{sortie})[t_i - y_i]](/pictures/frwiki/102/ff2f092e25d93fb9ebe38a2468e023db.png)
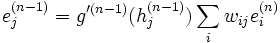
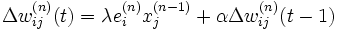
Wikimedia Foundation. 2010.